“多元算力”推理生态的观察和思考
作者:JMX、TZY、ZSL、YFC from DeepLink Group @ Shanghai AI Lab。
作者:JMX、TZY、ZSL、YFC from DeepLink Group @ Shanghai AI Lab
“多元算力”推理综述
从 2022 年的大模型爆发开始,多元算力厂商立即从传统模型转到了大模型的浪潮中。经过 2 年多的发展,多元算力厂商在大语言模型训练与推理领域取得了显著进展。其通过技术创新和生态构建,正逐步缩小与国际领先企业的差距,并在这个过程中于特定领域形成了独特优势。
目前国内有 10+家多元算力厂商在蓬勃发展,在国际贸易环境变化的背景下,特别是美国对高端 GPU 出口的限制,多元算力芯片产业面临着更大的发展压力和机遇。一方面,高端训练芯片的短缺使得多元算力芯片在训练端的短板愈发凸显;另一方面,这也促使多元算力芯片厂商在推理端发力,与 DeepSeek 等国产大模型形成协同发展。
1. 硬件指标与大语言模型推理
大语言模型推理对硬件提出了多维度挑战,多元算力芯片通过算力、显存、互联等关键指标的协同优化,逐步构建起面向不同场景的推理解决方案。
1.1 基础算力
算力作为 AI 芯片的核心性能指标,与大模型推理的性能直接相关。数据类型方面,大模型推理普遍使用 BF16/FP16,以及基于他们所量化出来的 INT8/INT4 等整型。另外,DeepSeek 等前沿模型已将 FP8 应用于训练和推理全流程,标志着低精度计算在大模型全生命周期中的应用正加速普及。
由于大模型推理的 Prefill 阶段多是计算瓶颈的计算,所以算力直接影响到首字延迟的速度。多元算力芯片 FP16 算力区间为 200-500 TFLOPS,与国际高端产品(300-2000 TFLOPS)仍存在差距。但是,多家多元算力距离已经逼近甚至超过对标的 A100/A800 的算力,有望在下一代产品中追上国际高端产品。另外,多元算力厂商已在 INT8 计算单元实现成熟支持,能够弥补一部分算力的劣势。
1.2 显存与显存带宽
显存规格直接决定可加载模型规模和推理吞吐量。英伟达的显存容量 64-140GB,而多元算力的显存在 32~96G 之间。在大显存的芯片中,我们可以通过增大 Batch Size 提升计算利用率,也可以有更多空间来容纳 kv-cache,使整个推理系统支持更长的上下文长度,命中 kv-cache 的概率也变高。另外,140G 的显存,可以在单机 8 卡上部署满血版 DeepSeekV3 的 fp8 版本,这是多元算力现阶段无法实现的。
显存带宽方面,英伟达的带宽 1.5-8.0TB/s,多元算力的的带宽在 0.8-3.0 之间。由于大语言模型推理的 Decode 阶段多为访存瓶颈,所以,显存带宽在 Decode 阶段对性能起着非常大的作用。
1.3 卡间、机间互联
另一个关键硬件指标是互联的速度,目前 32B 以上的模型基本都会采用多卡甚至多机部署。无论是 Dense 模型还是 MoE 模型,都需要进行卡间的通信,所以卡间的互联速度直接影响了整体端到端的推理速度。虽然大多数多元算力在互联上落后于英伟达(被限制在 A100 的 70%以下),但也有多元算力厂商达到了 H100 的水平,所以在卡间互联这一块,头部多元算力厂商已经与其他厂商拉开了差距,并且追赶上了国际先进水平。
下表是多元算力产品与英伟达芯片对比,可以看出目前多元算力已经全面赶上甚至超过了 A100 系列的水平,但是距离 H 系列还是有一定的差距。
表1:多元算力产品与英伟达芯片对比
1.4 CPU-加速器协同
在整个端到端的推理性能中,CPU 也起到了非常重要的职责。CPU 负责 tokenization、数据预处理、任务调度以及 Kernel 发射等工作。多元算力会使用除了 Intel 之外其他的 CPU,这对优化 CPU-加速器协作机制提出了非常大的挑战。所以,提升端到端推理效率,同样需要能够高效执行 tokenization 等工作的 CPU 的协助。
2. 软件适配现状
2.1 大语言模型推理关键算子
大语言模型推理性能很大程度上取决于底层算子的实现效率。与传统深度学习模型相比,Transformer 架构的大模型在推理阶段有其独特的计算特性,尤其是自回归生成过程中的注意力计算和 KV 缓存管理成为性能瓶颈。多元算力厂商都已经支持了以下几类主要大模型推理算子:
-
Attention计算:Prefill 阶段的 Attention 计算(包括带有 kv-cache 和不带 kv-cache)。Decode 阶段的带有 kv-cache 的 PagedAttention。
-
KV 缓存管理:保存 kv-cache 的 fill_kv_cache 算子在线 KV 缓存量化
-
混合专家机制(MoE) :路由计算(router)专家选择(top_k_gating)GroupGEMM 和其前后的处理
-
其他旋转位置编码(rotary_embedding)各种激活函数Rmsnorm动态量化算子multinomial 等后处理算子
2.2 算子库
针对大模型推理中的性能瓶颈,业界已开发多种专用算子库,多元算力厂商正积极适配这些库以提升推理效率。多元算力厂商中,非 GPGPU 的多元算力厂商比较偏好独立开发自己算子库,而 GPGPU 架构的多元算力厂商较多主动适配开源算子库(比如,FlashAttention,FlashInfer 等)。
另外,随着 triton 在 PyTorch 的生态中占据越来越重要的地位,绝大多数的多元算力厂商在过去的一年中完成了 triton 的适配,并在多个推理框架中应用了 triton kernel,特别是 MLA 等 Attention 相关算子。
DeepSeek 在开源周的工作聚焦大模型训练推理全流程加速,特别是其中的 FlashMla/DeepGEMM/DeepEP 是与算子强相关的部分,多元算力厂商也正在适配这些最前沿的算子库。
这些开源算子库的适配为多元算力芯片提供了性能优化的基础,但要实现端到端的高效推理,还需要与上层推理框架深度集成。下面将介绍多元算力生态在推理框架适配方面的进展。
2.3 开源推理框架适配
推理框架是连接模型与硬件的关键环节,决定了大模型在实际部署中的性能表现。多元算力厂商正积极适配主流开源推理框架,以构建完整的推理生态。以下是几个关键推理框架及其在多元算力生态中的适配状态:
vLLM 是专为大型语言模型推理设计的高性能开源库,其核心创新在于引入类操作系统的虚拟内存管理机制和 PagedAttention 算法,通过分页管理注意力键值缓存,显著提升显存利用率并减少碎片化问题。特别是 0.6.0 之后,vLLM 的性能又提升了一个档次。目前在多元算力生态中,vLLM 已成为适配最广泛的推理框架,大部分多元算力芯片都完成了对其的基础适配。其中也不乏有将自己的适配做了开源的多元算力厂商。
SGLang
SGLang 特别适用于高并发 Agent 控制、长文本生成等场景,支持主流模型及多模态扩展。目前也有少部分多元算力厂商已开始 SGLang 的适配工作,重点优化其 RadixAttention 机制在多元算力架构上的实现效率,以支持更复杂的智能体应用场景。
LMDeploy 是上海人工智能实验室的一个面向大语言模型的高效部署工具包,专注于轻量化推理与服务优化。其核心功能包括基于高性能推理引擎的持续批处理、动态 KV 缓存管理与张量并行加速技术,有效提升多并发场景的吞吐效率。
在多元算力生态中,LMDeploy 通过接入 DLInfer 库,已完成对头部多元算力芯片的支持。这种适配模式代表了一种高效的生态融合路径:通过标准化的中间件接口,推理框架可以快速支持多种硬件后端,而硬件厂商则可以专注于底层算子优化,形成良性的协同发展态势。
DLInfer 是一套专为国产硬件适配大模型推理场景设计的中间件解决方案,其核心功能在于通过标准化的融合算子接口,打通上层大模型推理框架与底层硬件厂商的异构计算能力。该库通过分层设计,在 eager 模式下直接调用各厂商优化后的融合算子,在 graph 模式下则对接硬件厂商的图编译引擎,实现端到端性能优化。其接口设计不仅将框架与硬件适配工程解耦,降低多平台开发成本,还能在图模式下通过精确的算子匹配提升推理效率。同时,DLInfer 兼顾了 LLM(大语言模型)与 VLM(视觉语言模型)两类主流多模态模型的推理需求,为国产硬件生态融入大模型技术栈提供了统一的中间层支持。
3. 多元算力与英伟达芯片的性价比
大语言模型的推理终究会与成本强绑定。而英伟达芯片的高价格以及获取的高门槛,也为多元算力提供了非常好的发展机会。从综合的推理性能上来说,英伟达依然是领先于其他多元算力,但是,在一些特定领域中,两方还是可以有一些比较。目前端到端的推理性能方面,多数多元算力约为对标的英伟达芯片的 70%左右;而价格方面,大约为对标芯片的 30%~70%。
自从 mooncake 发表了 PD 分离架构之后,在大厂以及开源社区都开始进行对 PD 分离的研究与运用。所以,我们可以从 P 和 D 两方面来看多元算力与英伟达的比较。目前多元算力的算力并不落后于同年代的英伟达芯片,这使其在推理中的预填充阶段性能不落后于英伟达芯片。而在解码阶段,多元算力也可以通过本身算力的价格优势,与英伟达展开较量。
另外,芯片的制造工艺也影响到了整体的性价比,英伟达拥有完整稳定的供应链以及大规模的生产能力,而多元算力在供应链方面依然面临着巨大挑战。这也使得整体的性价比进一步下降。
话题又要回到 DeepSeek 上来,DeepSeek 证明了在极致的优化可以使成本大幅降低。而多元算力的软件生态上的劣势,使得极致的优化变得困难。另一方面,满血版本的 DeepSeek-R1 使得多元算力的一体机在企业级部署的市场上又获得了在性价比上超越英伟达的机会。
综上所述,性价比是一个综合的话题,包含了性能,制造规模,软件生态等等因素。目前,英伟达依靠成熟的 CUDA 生态系统和生产规模优势,在通用性、生态完善度和成本结构上仍具备竞争优势。然而,随着 DeepSeek 等国产大模型的崛起,多元算力厂商通过与模型开发者的深度协同,有望快速提升自身在 LLM 推理领域的性价比。
4. 多元算力和英伟达在推理上的性能实测比较
在 2024 年一整年中,大语言模型的推理在商业上都迎来了爆发的一年。我们与多家多元算力厂商合作,在这一整年中追踪了多元算力在大语言模型推理上的进步。
下图展现了多元算力和英伟达 A800 在静态推理性能上的比较。我们对在 1~8 卡的规模上测试了 7B~70B 的大语言模型,并进行了一年的性能追踪。多家多元算力在大语言模型的静态推理性能在 2024 年平均提升了 10%,发展最快的多元算力厂商提升了近 40%性能,头部最高算力性能已经达到了 A800 的 135%。
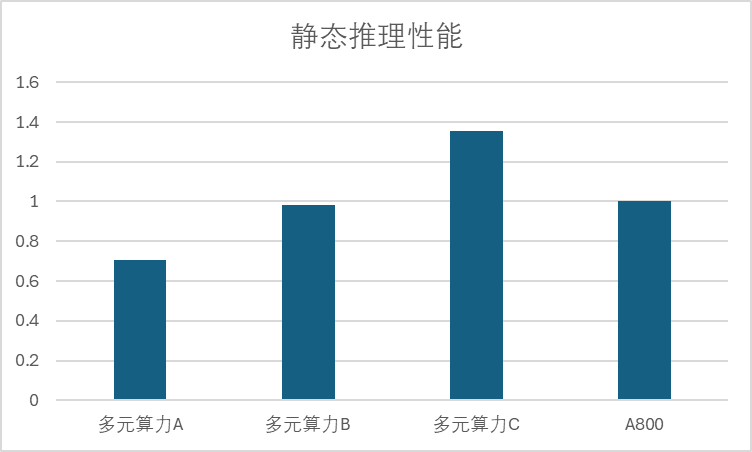
图 1:多元算力和 A800 静态推理性能对比
除了静态推理性能,我们也对多家头部多元算力厂商在动态场景下的性能表现进行了一年的追踪。图 2 展现了多元算力和英伟达 A800 在动态场景推理性能上的比较。多家头部多元算力在大语言模型的动态场景推理性能在 2024 年平均提升了 37%,发展最快的多元算力厂商提升了 160%的动态场景性能,头部最高算力性能已经达到了 A800 的 116%。
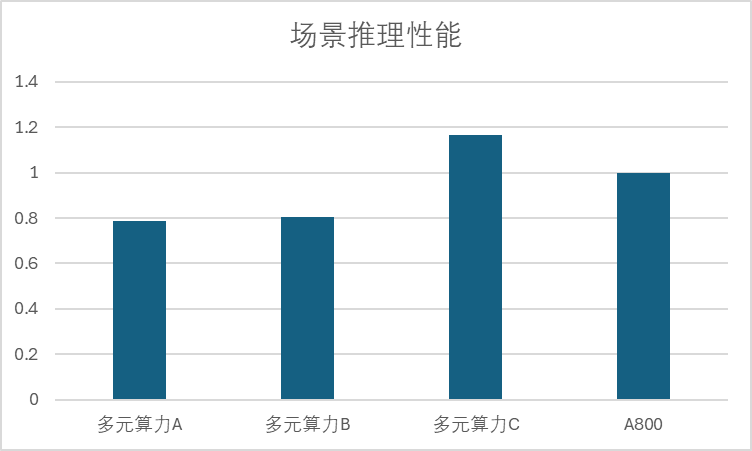
图 2:多元算力和 A800 动态场景推理性能对比
5. 多元算力的挑战与机遇
本文总结了硬件指标,软件适配现状,推理性价比以及在过去一年中多元算力的性能进步。从中可以看出,在美国对高性能计算卡的限制越来越严厉的今天,多元算力已经在对标 A800 的竞争中逐渐做出了突破,在一些场景下产生了优势。而在 2025 年,多家多元算力厂商将发布最新的芯片,对标英伟达的 H800,进一步提升多元算力的竞争力。在生态建设方面,除了少数头部厂商有开源的项目之外,绝大多数厂商仍然没有能够形成生态,生态建设方面将是多元算力面临的一大挑战。另一方面,芯片制造工艺的限制也是一个挑战。头部多元算力的芯片对制造工艺的要求较高,而国内在先进制程方面面临一定的限制,这也影响了目前多元算力芯片的性能和能效。
如果你喜欢我们的内容,欢迎赞同∆、收藏⭐️、关注➕我们!
也可以在我们的知乎官号【浦算DeepLink】上找到更多技术内容
欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)