AI基础概念之十:多层感知机的基本原理
x1x2ytrue000011101110对比维度单层感知机多层感知机网络结构输入层 + 输出层(无隐藏层)输入层 + 隐藏层 + 输出层激活函数阶跃函数(硬非线性、不可导)Sigmoid/ReLU 等(软非线性、可导)优化算法感知机学习规则(局部更新)反向传播 + 梯度下降(全局优化)解决问题仅线性可分问题(与门、或门)线性 / 非线性可分问题(异或门、复杂分类)核心能力简单线性分类特征提
多层感知机(Multilayer Perceptron,MLP)是在单层感知机基础上引入隐藏层的神经网络模型,核心改进是解决了单层感知机无法处理的非线性分类问题,同时具备更强的特征提取和复杂映射能力。
1986 年:反向传播算法(BP 算法)鲁梅哈特(Rumelhart)等人提出反向传播算法,解决了多层感知机(MLP)的权重更新问题,通过计算输出层的误差,反向传递到各层并调整权重,终于让多层神经网络能够训练。基于 BP 算法的多层感知机(MLP) 成为主流模型,可解决异或等非线性问题,神经网络研究短暂复苏。
一. 多层感知机核心结构:三层及以上的层级连接
MLP 的结构突破了单层感知机 “输入层 + 输出层” 的限制,引入至少一层隐藏层,各层神经元之间全连接(即上一层的每个神经元都与下一层的所有神经元相连)。
| 层级 | 功能 | 特点 |
|---|---|---|
| 输入层 | 接收原始特征数据 | 神经元数量 = 特征维度(如手写数字识别输入 28×28 像素,输入层 784 个神经元) |
| 隐藏层 | 提取和整合特征 | 层数可灵活设置(1 层→浅层 MLP,≥2 层→深层 MLP);神经元数量决定模型容量 |
| 输出层 | 输出分类 / 回归结果 | 分类任务:神经元数量 = 类别数(如二分类 1 个,多分类 n 个);回归任务:1 个神经元 |
关键区别:单层感知机无隐藏层,只能做线性映射;MLP 的隐藏层是 “特征加工工厂”,负责将原始输入转化为高维特征。
二、 多层感知机核心流程:非线性激活 + 层间传递
MLP 的信号传递分为前向传播和反向传播两步,核心是通过非线性激活函数和权重参数调整实现复杂规律的学习。
(1) 前向传播:逐层计算输出
对于每一层的神经元,计算逻辑分为两步:加权求和 + 非线性激活。
-
隐藏层输入:z1=w1⋅x+b1,隐藏层输出:a1=f(z1)(f 为 ReLU/Sigmoid,可导);
-
输出层输入:z2=w2⋅a1+b2,输出层预测:a2=g(z2)(g 为激活函数);
-
计算损失:L=Loss(a2,ytrue)(如交叉熵损失)。
(2) 激活函数:从 “阶跃” 到 “平滑非线性”
单层感知机用阶跃函数作为激活函数,只能产生 0/1 的离散输出,是硬非线性;MLP 引入平滑非线性激活函数,让隐藏层输出连续值,从而实现对非线性规律的拟合,常用激活函数包括:
| 激活函数 | 公式 | 优势 |
|---|---|---|
|
Sigmoid |
|
将任意实数输入映射到 (0,1) 区间,适合二分类输出层 |
| ReLU | f(z) = max(0, z) |
ReLU 函数是 Rectified Linear Unit(修正线性单元) 的缩写,是目前深度学习中最主流的隐藏层激活函数,核心特点是简单高效、解决梯度消失问题。 |
| Tanh | |
输出映射到 (-1,1),比 Sigmoid 收敛更快 |
(3) 反向传播:参数优化的核心
MLP 的参数(权重w、偏置b)通过反向传播算法优化,目标是更新每一层的权重和偏置,保障在前向传播时输出层通过损失函数计算得到的损失值逐渐收敛。其核心流程是从输出层往输入层反向计算每一层的梯度(损失函数对权重 / 偏置的偏导数),用梯度下降法更新参数:w = w − η⋅∇w,b = b − η⋅∇b(η为学习率),重复迭代。
-
第一步:更新输出层权重(w2)计算损失对w2的梯度:
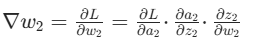 ,用梯度下降更新:w2=w2−η⋅∇w2。
,用梯度下降更新:w2=w2−η⋅∇w2。
这一步和单层感知机类似,但梯度是 “精准计算” 而非 “试错调整”。
-
第二步:更新隐藏层权重(w1)这是 BP 的核心突破。通过链式法则,把输出层的误差传递到隐藏层:
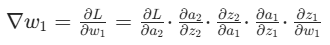 ,用梯度下降更新:w1=w1−η⋅∇w1。
,用梯度下降更新:w1=w1−η⋅∇w1。关键:隐藏层虽然没有 “真实标签”,但通过链式法则,能精准计算 “隐藏层权重的微小变化,会如何影响最终的输出误差”,从而知道该往哪个方向、改多少权重。
三、 多层感知机的工作流程举例(以异或门分类为例)
1. 问题定义
异或门(XOR)的输入输出规则:两个输入不同则输出 1,相同则输出 0,样本如下:
| x1 | x2 | ytrue |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
2. 模型结构
我们设计一个极简的 MLP:
-
输入层:2 个神经元(对应x1, x2);
-
隐藏层:2 个神经元(激活函数用 Sigmoid,引入非线性);
-
输出层:1 个神经元(激活函数用 Sigmoid,输出 0~1 的概率);
-
损失函数:二元交叉熵(BCE),衡量预测值与真实标签的差距;
-
优化算法:梯度下降(手动推导用批量梯度下降,代码用随机梯度下降)。
模型的数学结构:

3. 训练过程
-
初始化:给权重w、偏置b赋随机小值;(这里选便于计算的初始值)。权重的数学形似与各层的神经元个数相关。

-
前向传播:对每个样本计算隐藏层输出a1和输出层预测ypred;有了参数和数学公式,计算不在这里详细列明。
-
计算损失:用交叉熵损失计算ypred与ytrue的误差,交叉熵损失(Cross-Entropy Loss)是深度学习分类任务的首选损失函数,核心好处是梯度特性友好、契合概率输出、惩罚机制合理,尤其适配 Sigmoid/Softmax 激活的输出层。梯度平滑且无饱和,解决梯度消失问题,能保证训练时对参数更新的有效性;输出层用 Sigmoid 将输出映射为(0,1)之间的概率分布,交叉熵的本质是衡量两个概率分布的 “距离”,值越小表示两个分布越接近,完全匹配时交叉熵为 0。同时,交叉熵基于对数函数设计,惩罚力度随预测误差的增大而非线性递增,符合分类任务的需求。
假设前一步计算输出值ypred ≈ 0.377,真实输出为ytrue = 1。损失计算如下:
![]()
-
反向传播:计算梯度并更新所有层的w和b;
-
迭代优化:重复 1-4 步,直到损失值趋近于 0。
4. 预测过程
输入新样本(如x1=0,x2=1),通过前向传播计算,输出ypred≈1,实现正确分类。
总结:MLP 与单层感知机的核心差异
| 对比维度 | 单层感知机 | 多层感知机 |
|---|---|---|
| 网络结构 | 输入层 + 输出层(无隐藏层) | 输入层 + 隐藏层 + 输出层 |
| 激活函数 | 阶跃函数(硬非线性、不可导) | Sigmoid/ReLU 等(软非线性、可导) |
| 优化算法 | 感知机学习规则(局部更新) | 反向传播 + 梯度下降(全局优化) |
| 解决问题 | 仅线性可分问题(与门、或门) | 线性 / 非线性可分问题(异或门、复杂分类) |
| 核心能力 | 简单线性分类 | 特征提取 + 复杂非线性映射 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)