ai学习笔记(二)
机器学习是研究“学习算法”的学科。其核心定义包含任务T、性能度量P和经验B三个关键要素。系统需要解决的具体问题。(识别图片中的猫)用于评估算法能力如准确率。(识别的准确率):提供给系统学习的数据。(一万张标记好“这是猫”的图片)三要素关系:任务T决定学习目标,性能度量P量化学习效果,经验E提供学习素材。三者共同构成机器学习系统的完整闭环,缺一不可。计算机程序通过经验E在任务T上实现以P衡量的性能提
1. 机器学习基础定义
1.1 机器学习定义
机器学习是研究“学习算法”的学科。其核心定义包含任务T、性能度量P和经验B三个关键要素。
-
任务T:系统需要解决的具体问题。(识别图片中的猫)
-
性能度量P:用于评估算法能力如准确率。(识别的准确率)
-
经验B:提供给系统学习的数据。(一万张标记好“这是猫”的图片)
三要素关系:任务T决定学习目标,性能度量P量化学习效果,经验E提供学习素材。三者共同构成机器学习系统的完整闭环,缺一不可。计算机程序通过经验E在任务T上实现以P衡量的性能提升,这种自我完善过程即为机器学习的核心特征。
1.2 机器学习与深度学习的关系
机器学习与深度学习是包含与被包含的关系。
1.层级关系 (Hierarchy)
-
人工智能 (AI):最宽泛的概念,指任何让机器展现智慧的技术。
-
机器学习 (ML):AI 的一个子集,指通过数据训练模型的算法。
-
深度学习 (DL):ML 的一个子集,指利用多层神经网络来解决复杂问题的算法。
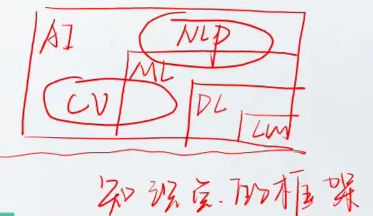
2. 核心区别:特征工程 (Feature Engineering)
这是两者最本质的区别——谁来提取数据的特征?
机器学习:
- 做法:程序员需要先告诉计算机关注什么。比如识别猫,人要先写代码定义“尖耳朵”、“圆眼睛”是特征,然后给计算机处理。
- 局限:非常依赖专家的经验,而且太复杂的东西人描述不出来。
深度学习:实现特征自动提取。
- 做法:直接把图片扔给神经网络,它自己通过多层网络“悟”出哪些是关键特征(甚至人类都看不懂它关注了什么)。
通俗理解:
-
传统 ML(像手工做菜):你需要自己洗菜、切菜、配佐料(人工提取特征),然后丢进锅里炒(模型训练)。菜好不好吃,很大程度取决于你切得好不好。
-
深度 DL(像全自动料理机):你直接把整颗蔬菜和肉扔进去(原始数据),机器内部自动清洗、切割、烹饪(自动提取特征 + 训练),最后直接吐出成品。
AI的上进心:
自己小范围拓展数据,提高泛化能力(模型适应新样本的能力),泛化能力越好,模型越优秀。
2. 与传统规则区别
传统规则:依赖人工显式指定规则,利用if-else去完成业务流程
机器学习:从数据中总结规律
前者需要完整领域知识,后者能从数据中发现潜在规律。传统方法规则变更需人工修改代码,机器学习模型可通过新数据自动更新,后者在动态环境中有显著的优势。
工作流程对比
传统流程:输入数据 -> 人工规则 (代码 if/else) -> 结果输出
逻辑:线性结构,类似于计算器。
机器学习流程:输入数据 -> 训练 (Training) -> 模型 (Model) -> 预测结果
逻辑:数据驱动的闭环系统,模型可以通过反馈不断迭代优化(V1.0, V2.0...)。
3. 适用场景
机器学习相比于传统规则更偏向于解决复杂问题,但是简单的线性场景中利用传统规则能够更加高效地完成功能,需要因地制宜去选择技术。
传统规则常用于规则明确且简单问题,如计算器程序,传统算法开发。
机器学习(ML)的常用于以下场景:
- 复杂问题 (Complex Problems)
涉及海量数据且没有明确的数学公式分布。
例子:语音识别。声波和语义之间的映射关系太复杂,无法用几行代码写清楚。
- 动态环境 (Dynamic Environments)
规则随时间是会不断变化的。
例子:垃圾邮件过滤、推荐系统。新的垃圾邮件词汇层出不穷,用户的兴趣也在变,机器学习可以增量学习适应变化。
- 隐性规则 (Implicit Rules)
人类能做但说不清楚怎么做的问题。
例子:人脸识别、图像风格提取。你能一眼认出这是梵高的画,但很难向计算机描述“什么是梵高风格”,机器学习可以自己从画作中提取特征。
4. 核心任务类型
根据输出结果的不同,机器学习任务主要分为三类:
4.1 分类任务(监督学习)
- 定义:将输入样本分配到预定义的离散类别中。
- 目标:预测一个类别标签(如“是/否”、“猫/狗/鸟”等)。
- 学习方式:属于监督学习,即训练数据包含输入特征和对应的正确标签。
- 典型例子:判断一封邮件是否为垃圾邮件(二分类)、手写数字识别(0–9,多分类)
- 常用算法:逻辑回归(Logistic Regression)、支持向量机(SVM)、决策树、随机森林、K近邻(KNN)、神经网络(如CNN用于图像分类)
- 评估重点:关注分类准确率、召回率等指标,需处理类别不平衡问题,混淆矩阵是分析模型错误模式的重要工具。
4.2 回归任务(监督学习)
- 定义:预测一个连续数值型输出。
- 目标:根据输入特征估计一个实数(如价格、温度、分数等)。
- 学习方式:也属于监督学习,训练数据包含输入和对应的连续目标值。
- 典型例子:预测房价、预测股票价格、预测气温或降雨量
- 常用算法:线性回归(Linear Regression)、岭回归(Ridge)、Lasso回归、决策树回归、梯度提升树(如XGBoost)、神经网络(用于非线性回归)
- 评估方法:采用MAE、MSE等误差指标,R²系数反映模型解释方差的比例。需特别注意异常值对模型的影响
4.3 聚类任务(无监督学习)
- 定义:将未标记的数据分组(簇),使得组内相似度高,组间相似度低。
- 目标:发现数据中的内在结构或模式,无需预先知道类别标签。
- 学习方式:属于无监督学习,训练数据只有输入特征,没有标签。
- 典型例子:客户细分(根据购买行为划分用户群体)、图像分割(将图像中相似像素聚在一起)、文档主题聚类(自动发现新闻文章的主题群)
- 常用算法:K均值聚类(K-Means)、层次聚类(Hierarchical Clustering)、DBSCAN(基于密度的聚类)、高斯混合模型(GMM)
- 评估方法:需合理定义相似度度量,确定最佳聚类数量。评估常使用轮廓系数等内部指标。
5. 学习范式
根据“经验”(数据)的类型不同,学习方式分为:
5.1 监督学习
- 核心思想:从带有标签的训练数据中学习输入到输出的映射关系。
- 数据形式:每条样本包含 输入特征 x 和 真实标签 y ,即 (x,y)(x,y) 。
- 目标:训练一个模型 f(x) ,使得对新输入 x能准确预测其标签 y 。
- 典型任务:分类、回归
- 常用算法:线性/逻辑回归、支持向量机(SVM)、决策树、随机森林、神经网络等
- 评估方式:准确率、精确率、F1分数(分类);均方误差(MSE)、R²(回归)
5.2 无监督学习
- 核心思想:从未标注的数据中发现隐藏结构或模式。
- 数据形式:只有输入特征 x ,没有标签 y。
- 目标:探索数据的内在分布、分组、降维或生成新样本。
- 典型任务:聚类、降维、异常检测。
- 常用算法:K-Means、DBSCAN(聚类);PCA、Autoencoder(降维)
5.3 半监督学习
- 核心思想:结合少量标注数据 + 大量未标注数据进行学习。
- 动机:标注数据昂贵,但未标注数据易得(如网页文本、图像)。
- 基本假设:
- 平滑性假设:相近的样本更可能有相同标签
- 聚类假设:数据倾向于形成离散簇,同一簇内标签相同
- 流形假设:数据分布在低维流形上
- 典型方法:
- 自训练(Self-training):用模型预测未标注数据的伪标签,再加入训练
- 图半监督学习(Label Propagation)
- 一致性正则化(如Mean Teacher、FixMatch)
- 基于生成模型的方法(如使用VAE)
- 应用场景:医学影像分析(标注需专家)、语音识别、自然语言处理(大量文本无标签)
5.4 强化学习
- 核心思想:强化学习模仿生物的学习过程。智能体(Agent)在环境(Environment)中通过“试错”来学习,通过获得奖励(Reward)或惩罚来调整策略,目标是获得最大化累计奖励。
- 机制:智能体(Agent)通过与环境交互,根据奖励(Reward)或惩罚来优化策略。
- 例子:AlphaGo 下围棋、自动驾驶。下赢了给糖吃,撞车了扣分。
6. 整体流程
一个完整的机器学习项目不仅仅是“训练模型”,通常包含以下 7 个步骤:
-
数据收集 (Data Collection):爬虫、数据库、API、传感器。
-
数据准备与清洗 (Data Preparation):处理缺失值、异常值(如年龄 -5 岁)、去重。 注意:脏数据进,垃圾结果出 (Garbage In, Garbage Out)。
-
数据标注 (Labeling):如果是监督学习,需要人工打标签。
-
特征工程 (Feature Engineering):核心步骤。将原始数据转换为模型能理解的数值特征。 例子:把“上午、下午”转换成“0, 1”;提取文本的关键词频率。
-
模型训练与选择 (Training & Selection):选择算法(如决策树、神经网络),调整超参数,训练模型。
-
评估与部署 (Evaluation & Deployment):评估:用测试集验证模型准不准。部署:上线成为 API 或应用。
-
迭代:根据线上反馈数据持续更新模型。
7. 数据集概念
数据集是机器学习任务中使用的一组数据样本集合。
数据的结构
- 样本 (Sample):表格中的一行,代表一个具体的对象(如一个人、一套房)。
- 特征 (Feature):表格中的列,对象的属性(如身高、面积)。
- 标签 (Label):我们要预测的目标(如体重、价格)
数据划分
| 子集 | 比例(常见) | 用途 | 是否参与训练 |
|---|---|---|---|
| 训练集(Training Set) | 60%–80% | 用于模型参数学习(拟合) | 是 |
| 验证集(Validation Set) | 10%–20% | 调整超参数、选择模型、早停等 | 否(但用于模型选择) |
| 测试集(Test Set) | 10%–20% | 最终评估模型泛化能力 | 否(完全隔离) |
数据集样式
- 结构化样式:以表格形式组织,每行代表一个样本,列代表特征。如房价预测中的面积、朝向等结构化特征
- 非结构化数据:包括图像、文本、音频等,需通过特征提取转换为数值表示。如CNN处理图像,NLP模型处理文本序列。
8. 数据处理
重要性:数据质量决定模型性能的上限,特征工程能够将原始数据转化为模型可理解的形式,好的特征工程减少无关特征可降低过拟合风险,提高模型泛化能力。特征过多会导致维度灾难,增加计算成本。数据分步会随时间变化,需要持续监控和更新数据,模型性能下降往往源于数据分步偏移而非算法本身。
预处理:
1. 数据清洗 (Cleaning):处理缺失值(删除或填充)、平滑噪声数据、识别并处理异常值。例如用中位数填充年龄缺失值,用3σ原则(去掉离群较远的点)检测异常点。
2. 数据集成 (Integration):把多个来源的数据表合在一起,解决命名冲突(如一个表叫 user_id,一个叫 uid)。
3. 数据规约 (Reduction):通过聚合、抽样或降维减少数据量但保持完整性。如使用PCA降低特征维度,或对大数据集进行分层抽样。
脏数据:
1. 不完整数据:包含缺失值或属性不全的记录,如用户画像中缺少关键行为数据。需分析缺失机制后选择适当处理方式。
2. 噪声数据:测量误差或随机波动导致的错误值,如传感器异常读数。可通过平滑技术或统计方法识别处理。白噪声:无关的数据。
3. 不一致数据:数据矛盾或格式不统一,如日期格式混用。需建立数据清洗规则,统一数据表示形式。
数据转换方法:
1. 标准化处理:将不同量纲的特征转换到相同尺度(单位),如Z-score标准化。避免数值范围大的特征主导模型训练。
2. 离散化处理:将连续值分段为离散区间,如将年龄分为儿童、青年等。可简化模型并增强鲁棒性。
3. 特征构造:通过现有特征组合生成新特征,如计算BMI指数。需结合领域知识创造有意义的衍生特征。
特征工程:旨在从原始特征集中筛选出最相关、最有信息量的子集,以提升模型性能、降低过拟合风险、加快训练速度并增强可解释性。分为以下3种方法:
1. 过滤法:计算高效、独立评估、通用性强。特征ABCD独立评估权重
-
计算每个特征与目标变量的统计分数
-
按分数降序排序
-
选择前 k 个或分数高于阈值的特征
2. 包装法:计算量大、考虑交互、针对模型。
将特征子集的选择视为一个搜索问题,通过反复训练和评估特定模型来寻找最优特征组合。特征选择过程“包裹”在模型训练外部,特征ABCD穷举组合来评判权重。
3. 嵌入法:
在模型训练过程中自动完成特征选择,将特征选择嵌入到模型(树、线性)的优化目标中。兼具过滤法的效率和包装法的性能,深度学习中常用的是嵌入法。
9. 模型评估知识
泛化能力:模型在新数据上的预测准确度是首要标准,需通过交叉验证等方法确保模型不只在训练集上表现良好。
可解释性:业务场景中常需理解模型决策逻辑,如金融风控需解释拒贷原因。简单模型通常更易解释但可能牺牲准确率。
预测效率:实时系统要求单条预测耗时短,如推荐系统需在毫秒级响应。模型复杂度与预测速度需平衡。
误差分类:训练误差反映模型拟合训练数据的能力,泛化误差衡量在新数据上的表现。两者差异反映模型过拟合程度。
拟合问题:欠拟合表现为高偏差,模型过于简单;过拟合表现为高方差,模型过于复杂。需通过验证曲线诊断。
模型容量:指模型拟合复杂函数的能力,需与问题复杂度匹配。容量不足导致欠拟合,过高导致过拟合。
泛化误差
对于回归任务(均方误差 MSE),总泛化误差可分解为三部分:
泛化误差=偏差^2+方差+不可约误差
1. 偏差(Bias)
- 定义:模型预测的期望值与真实值之间的系统性偏离。
- 高偏差表现:
- 模型过于简单(如用线性模型拟合非线性数据)
- 欠拟合(Underfitting):训练误差和测试误差都高
- 降低方法:
- 增加模型复杂度(如用多项式回归、深度网络)
- 添加更多相关特征
2. 方差(Variance)
- 定义:模型对训练数据微小扰动的敏感程度(即预测结果的波动性)。
- 高方差表现:
- 模型过于复杂(如高阶多项式、深度过大的树)
- 过拟合(Overfitting):训练误差低,但测试误差高
- 降低方法:
- 正则化(L1/L2)
- 增加训练数据
- 早停(Early Stopping)
- 集成方法(如随机森林、Bagging)
3. 不可约误差(Irreducible Error)
- 来源:数据本身的噪声(如测量误差、随机因素)
- 特点:无法通过改进模型消除,是误差的理论下限
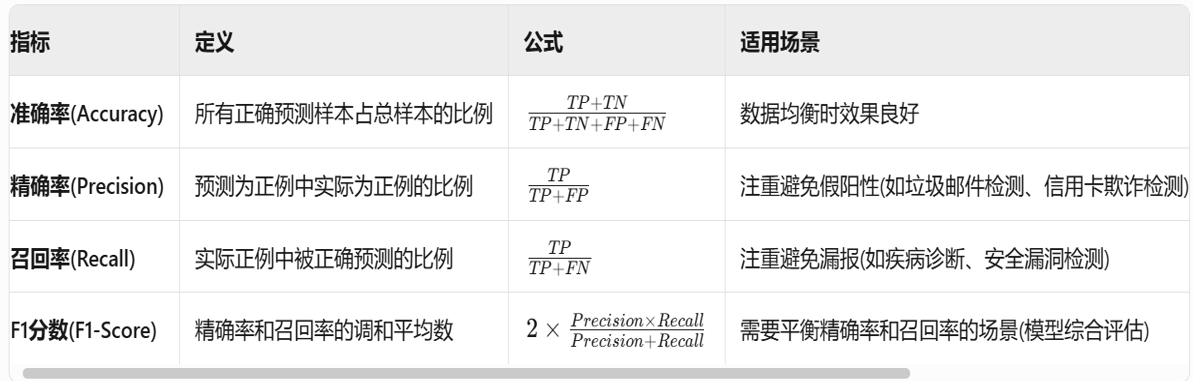
混淆矩阵:

四个关键术语的通俗解释:
- TP (True Positive, 真阳性):
- 情况:本来是正的,模型也说是正的。
- 例子:本来是癌症,模型预测是癌症。(正确)
- TN (True Negative, 真阴性):
- 情况:本来是负的,模型也说是负的。
- 例子:本来是健康,模型预测是健康。(正确)
- FP (False Positive, 假阳性) —— 第一类错误:
- 情况:本来是负的,模型误判为正的。
- 例子:本来是健康,模型预测是癌症。(误诊)
- 别名:Type I Error
- FN (False Negative, 假阴性) —— 第二类错误:
- 情况:本来是正的,模型漏判为负的。
- 例子:本来是癌症,模型预测是健康。(漏诊)
评估指标:
正则化:
用来防止模型过拟合的技术。你可以把正则化理解为一种"惩罚机制",让模型在学习数据的同时,也要保持自身的简单和稳定。

效果:去掉不重要的特征
- 特征选择:L1正则化有一种神奇的能力,它会使模型中一些不重要的特征的权重变成0。这意味着它帮你自动筛选掉了无关的特征,只保留重要的特征。最终得到的模型是"稀疏"的。
- 解释性强:由于只保留了少数几个非零特征,模型更易于解释。

效果:把权重平均化
-
权重衰减:L2正则化会使模型的权重无限趋近于0,但不会等于0。它让所有特征都对最终结果贡献一点,但每个特征的贡献都不太大,把影响力均匀地分散开。
-
防止过拟合:当特征很多且存在多重共线性时,L2正则化能有效地限制权重的大小,从而让模型变得更平滑、更稳定。
如何选择?
-
如果你想做特征选择,减少特征数量,或者你的模型特征非常多且你认为很多特征是噪声,可以选择 L1 正则化。
-
如果你只是想防止过拟合,且所有特征都有一定作用,或者特征之间存在多重共线性,可以选择 L2 正则化。
-
如果你想结合两者的优点,比如希望既能特征选择又能防止过拟合,可以考虑 Elastic Net(弹性网络),它就是 L1 和 L2 惩罚的线性组合。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)