AgentScope AutoContextMemory:告别 Agent 上下文焦虑
AgentScope推出的AutoContextMemory组件解决了智能Agent在长对话场景中面临的成本激增、性能下降等问题。该组件通过自动压缩、卸载和摘要对话历史,提供6种渐进式压缩策略,在保留关键信息的同时降低70%的API调用成本。采用多存储架构确保信息可追溯,支持跨会话持久化。实测显示,在代码分析等长对话场景中能显著提升响应速度并控制成本。
作者:翼严
一.前言
你是否遇到过这样的场景:构建了一个智能 Agent,能够与用户进行多轮对话,处理复杂的任务。但随着对话的深入,你发现了一个严重的问题——
对话进行到第 100 轮时,每次 API 调用需要发送 10 万 tokens,成本是初始对话的 10 倍!
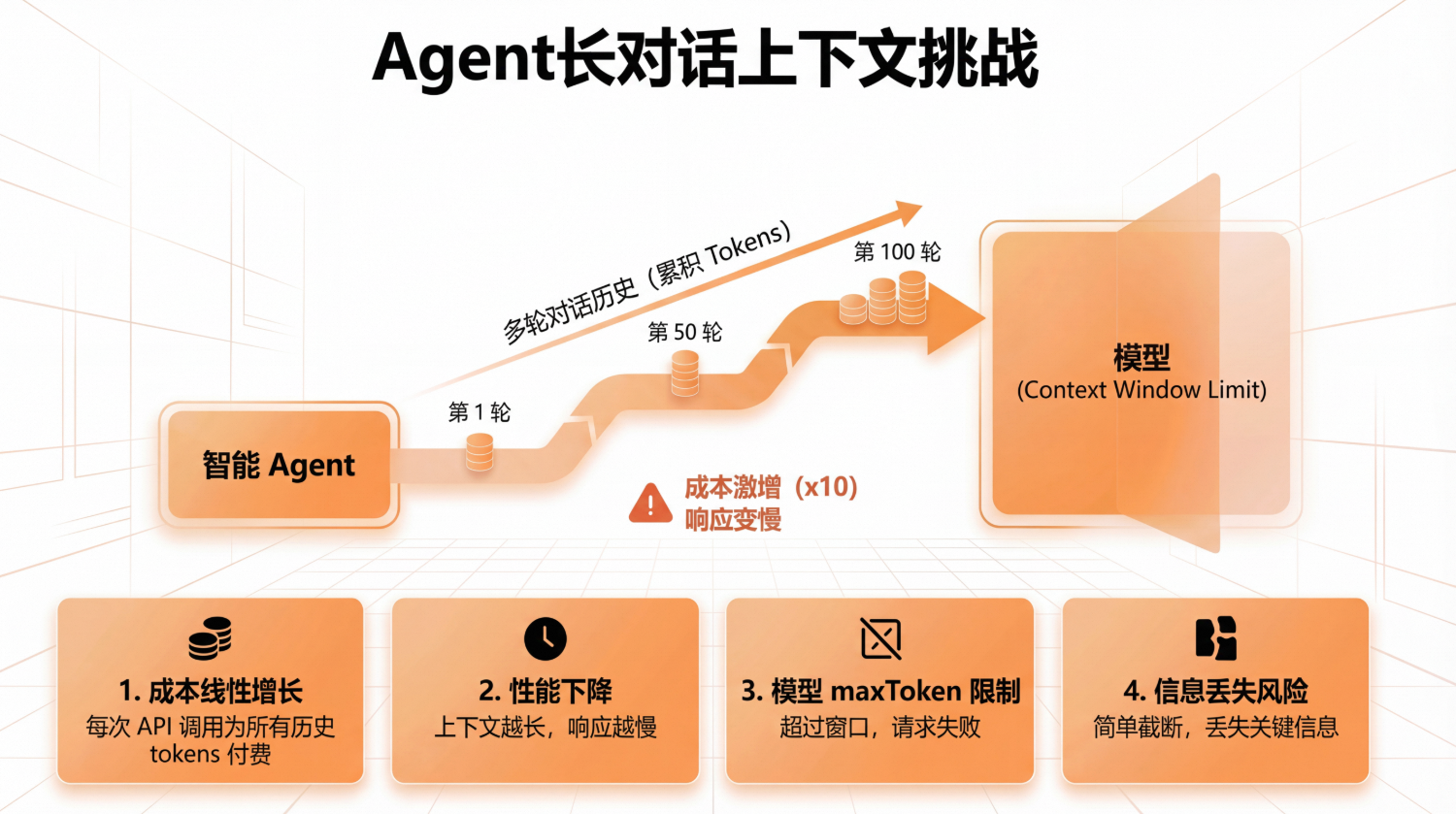
在长对话场景中,随着对话历史的不断累积,你会面临以下困境:
- 成本线性增长:每次 API 调用需要为所有历史 tokens 付费,成本随对话增长而线性上升
- 性能下降:上下文越长,模型处理时间越长,响应变慢
- 模型 maxToken 限制:当对话历史超过模型的最大上下文窗口(如 128K tokens)时,模型无法处理完整的上下文,导致请求失败
- 信息丢失风险:简单上下文截断会丢失关键历史信息,影响 Agent 决策质量
AutoContextMemory:智能上下文管理
面对这些挑战,AgentScope推出了AutoContextMemory ,它是 AgentScope Java 框架提供的智能上下文内存管理组件,通过自动压缩、卸载和摘要对话历史,在成本控制和信息保留之间找到最佳平衡。
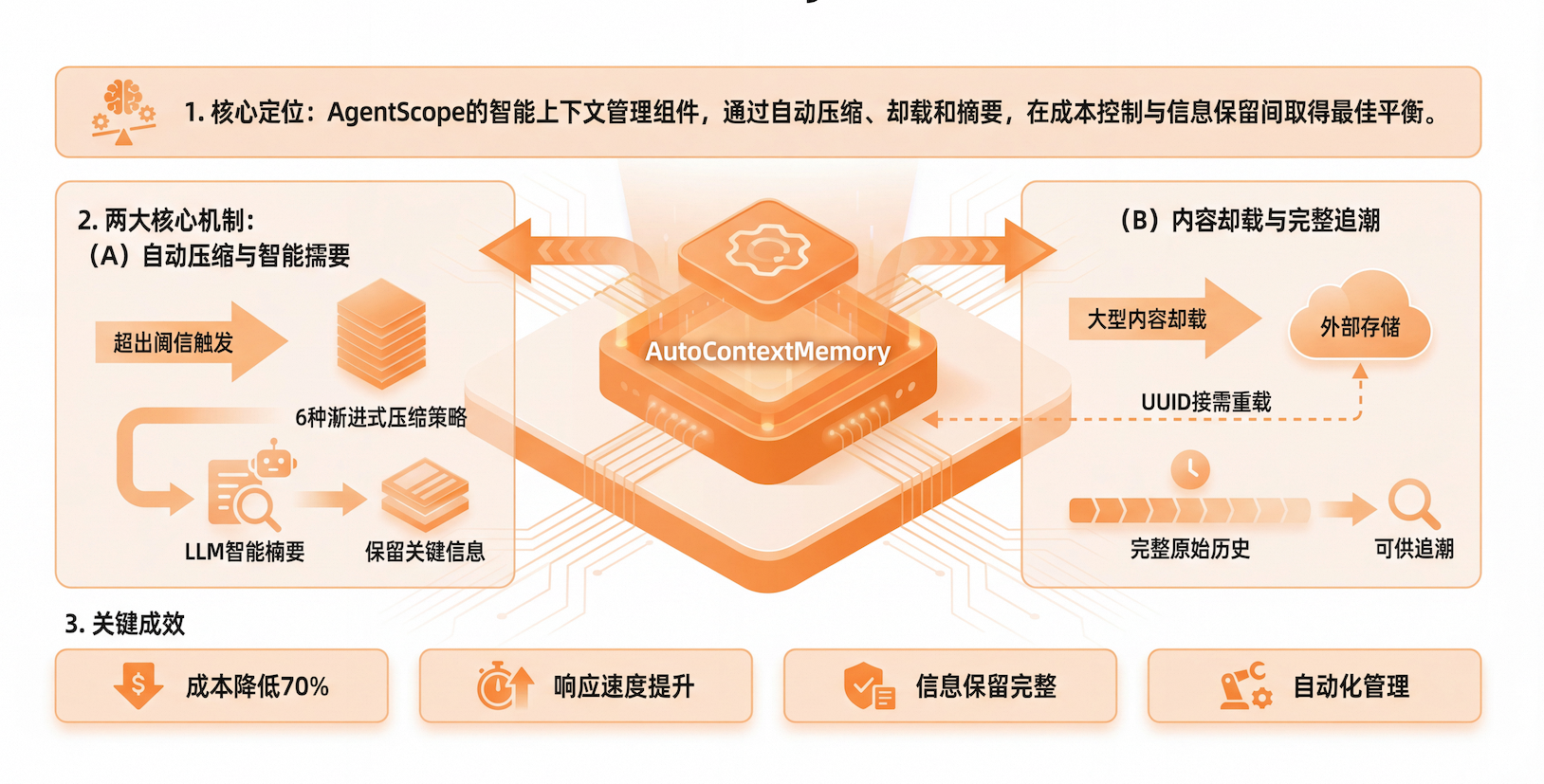
核心价值
1. 自动压缩与智能摘要
- 当消息或 token 数量超过阈值时,自动触发 6 种渐进式压缩策略
- 使用 LLM 智能摘要,保留关键信息而非简单截断
- 无需人工干预,系统自动管理
2. 内容卸载与完整追溯
- 将大型内容卸载到外部存储,通过 UUID 按需重载
- 所有原始内容保存在原始存储中,支持完整历史追溯
- 不会因为压缩而丢失任何信息
3. 实际效果
- ✅ 成本降低 70%:通过智能压缩,大幅减少 token 使用量
- ✅ 响应速度提升:更小的上下文意味着更快的处理速度
- ✅ 信息保留完整:关键信息不会丢失,Agent 决策质量不受影响
- ✅ 自动化管理:无需人工干预,系统自动优化
二、AutoContextMemory架构与工作原理
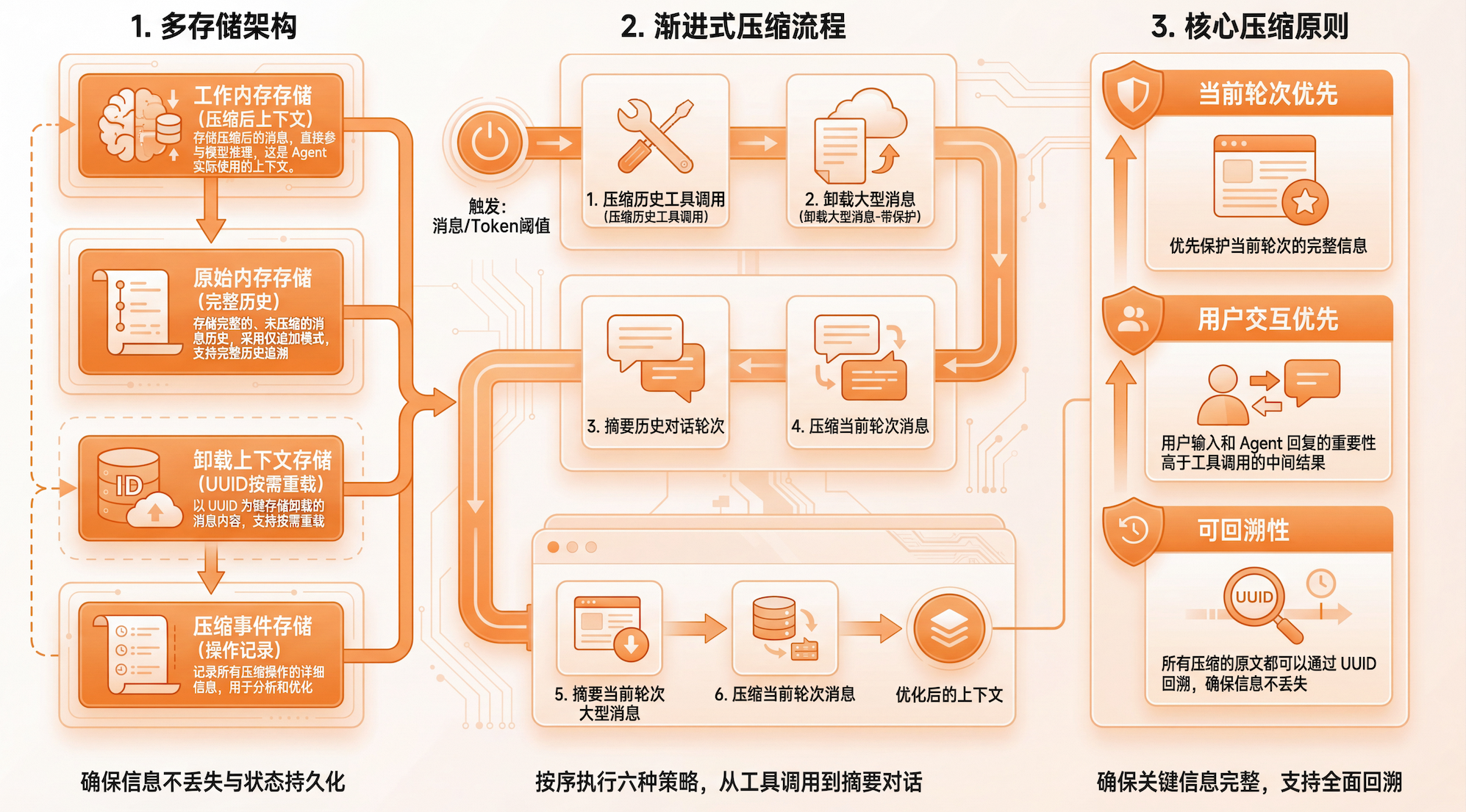
多存储架构
AutoContextMemory 采用多存储架构,确保在压缩的同时保留完整信息:
- 工作内存存储:存储压缩后的消息,直接参与模型推理,这是 Agent 实际使用的上下文。
- 原始内存存储:存储完整的、未压缩的消息历史,采用仅追加模式,支持完整历史追溯
- 卸载上下文存储:以 UUID 为键存储卸载的消息内容,支持按需重载
- 压缩事件存储:记录所有压缩操作的详细信息,用于分析和优化
所有存储都支持状态持久化,可以结合 SessionManager 实现跨会话的上下文持久化。
6 种渐进式开箱即用压缩策略
AutoContextMemory 的核心是 6 种渐进式压缩策略。
压缩触发条件:
消息数量阈值 或者 Token 数量阈值,两个条件满足任一即触发压缩
压缩流程:
检查阈值 → 策略1(压缩历史工具调用) → 策略2(卸载大型消息-带保护)
→ 策略3(卸载大型消息-无保护) → 策略4(摘要历史对话轮次)
→ 策略5(摘要当前轮次大型消息) → 策略6(压缩当前轮次消息)
压缩原则:
- 当前轮次优先:优先保护当前轮次的完整信息
- 用户交互优先:用户输入和 Agent 回复的重要性高于工具调用的中间结果
- 可回溯性:所有压缩的原文都可以通过 UUID 回溯,确保信息不丢失
6 种压缩策略:
- 压缩历史工具调用:查找历史对话中的连续工具调用消息(超过 6 条),使用 LLM 智能压缩,保留工具名称、参数和关键结果。轻量级策略,压缩成本低。
- 卸载大型消息(带保护):查找超过阈值的大型消息,保护最新的助手响应和最后 N 条消息,卸载原始内容并替换为预览和 UUID 提示。快速减少 token 使用。
- 卸载大型消息(无保护):与策略 2 类似,但不保护最后 N 条消息,仅保护最新的助手响应。更激进的压缩策略。
- 摘要历史对话轮次:对历史用户-助手对话对进行智能摘要,使用 LLM 生成摘要保留关键决策和信息。大幅减少 token 使用。
- 摘要当前轮次大型消息:查找当前轮次中超过阈值的大型消息,使用 LLM 生成摘要并卸载原始内容。针对当前轮次的优化。
- 压缩当前轮次消息:压缩当前轮次的所有消息,合并多个工具结果,保留关键信息。最后的保障策略,确保上下文不超限。
三、实战演示:5 分钟快速上手
Maven 依赖
在 pom.xml 中添加以下依赖:
<dependencies>
<!-- AgentScope Core -->
<dependency>
<groupId>io.agentscope</groupId>
<artifactId>agentscope-core</artifactId>
<version>1.0.2</version>
</dependency>
<!-- AutoContextMemory Extension -->
<dependency>
<groupId>io.agentscope</groupId>
<artifactId>agentscope-extensions-autocontext-memory</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
基本使用
在 ReActAgent 中使用 AutoContextMemory 非常简单:
import io.agentscope.core.ReActAgent;
import io.agentscope.core.memory.autocontext.AutoContextConfig;
import io.agentscope.core.memory.autocontext.AutoContextMemory;
import io.agentscope.core.memory.autocontext.ContextOffloadTool;
import io.agentscope.core.tool.Toolkit;
// 1. 配置 AutoContextMemory
AutoContextConfig config = AutoContextConfig.builder().build();
// 2. 创建内存
AutoContextMemory memory = new AutoContextMemory(config, model);
// 3. 注册重载工具
Toolkit toolkit = new Toolkit();
toolkit.registerTool(new ContextOffloadTool(memory));
// 4. 创建 Agent
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.memory(memory)
.toolkit(toolkit)
.enablePlan() // 启用计划功能,控制复杂任务进度;
.build();
关键配置参数说明
| 参数 | 默认值 | 说明 | 调整建议 |
|---|---|---|---|
msgThreshold |
100 | 触发压缩的消息数量阈值 | 短对话场景:30-50 长对话场景:50-100 |
maxToken |
128K | 上下文窗口的最大 token 限制 | 根据模型调整 |
tokenRatio |
0.75 | 触发压缩的 token 比例阈值 | 保守:0.5-0.6 激进:0.7-0.8 |
lastKeep |
50 | 保持未压缩的最近消息数量 | 重要对话:20-30 一般场景:10-20 |
largePayloadThreshold |
5K | 大型消息阈值(字符数) | 根据消息大小调整 |
currentRoundCompressionRatio |
0.3 | 当前轮次压缩比例 | 0.2-0.4 之间 |
四、场景实测效果
测试场景:分析 Nacos 服务端配置中心代码
我们选择了一个典型的代码分析场景:分析 Nacos 服务端配置中心代码,生成 2 万字分析报告。这是一个典型的长对话场景,涉及:
- 多轮代码阅读和解析
- 大量工具调用(代码搜索、文件读取、代码分析)
- 逐步构建分析报告
- 对话轮次超过 100 轮
- 累计生成超过 2 万字的分析报告
测试方法
在相同环境下,分别运行使用 AutoContextMemory 和不使用压缩两种配置,每种策略分别重复执行 5 次,对比平均结果。测试指标包括:
- Token 消耗:每次 API 调用的 token 数量
- 响应时间(RT):每次 API 调用的响应时间
- 累计成本:整个对话过程的累计 token 消耗
测试结果对比
Token 消耗对比
未执行自动压缩的5次测试Token消耗分别为:7313784,5208927,6208127,7208127,5288327
执行自动压缩的5次测试Token消耗分别为:1688838,2504389,895823, 2221470, 2203740
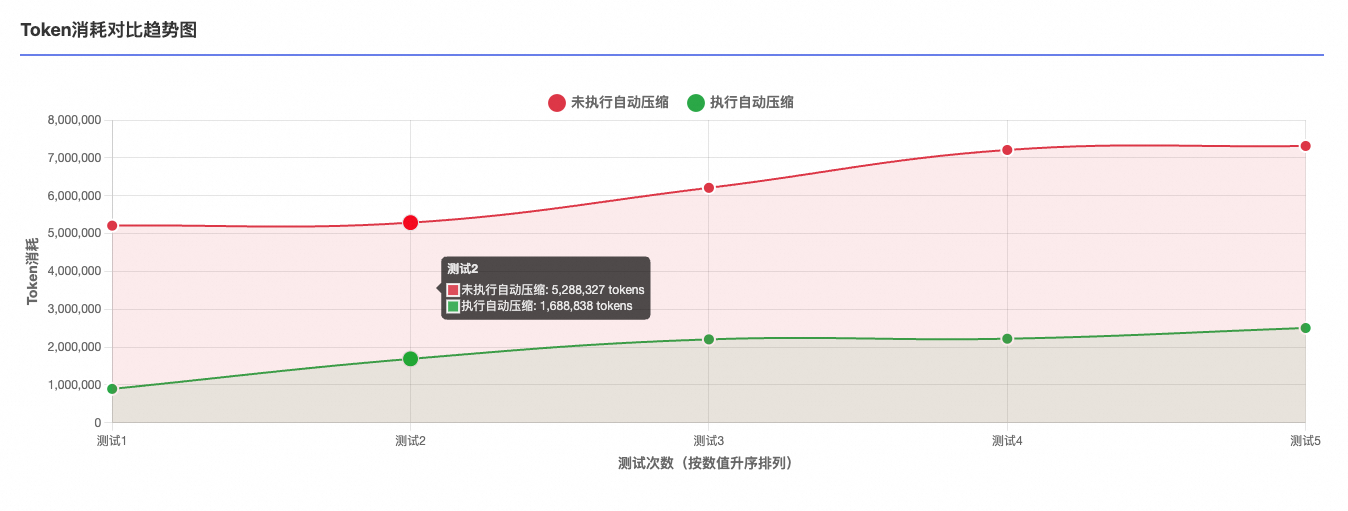
关键数据:执行压缩的场景 Token平均下降68.4%
响应时间(RT)对比
未执行自动压缩的5次测试总RT分别为:1小时41分5秒,1小时6分13秒,1小时20分13秒,1小时5分3秒,0小时59分5秒
执行自动压缩的5次测试总RT分别为:30分5秒,42分16秒,18分51秒,24分47秒, 32分15秒
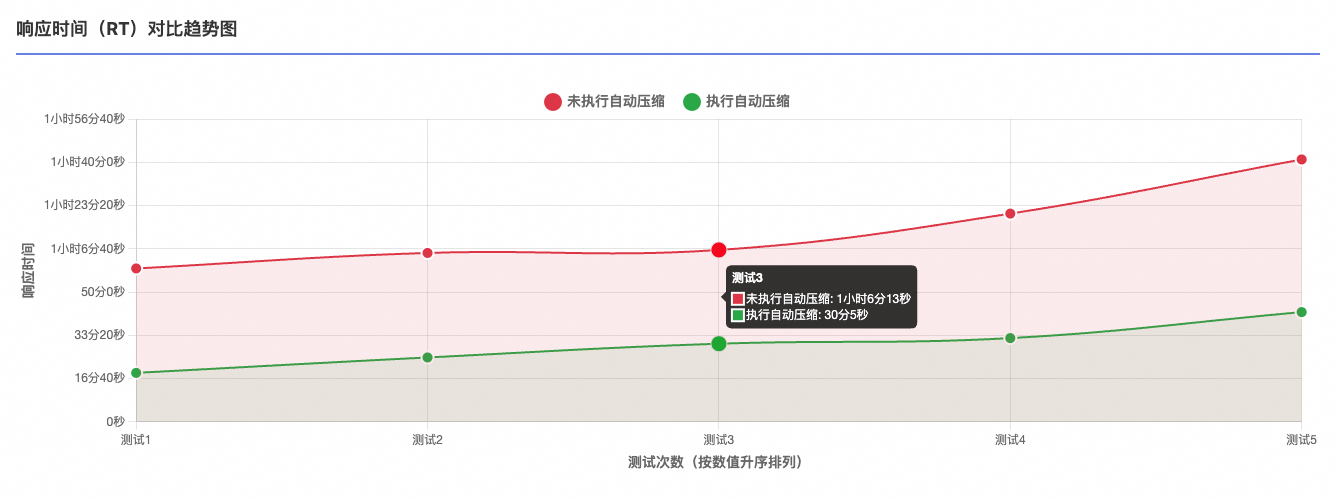
关键数据:执行压缩的场景 总RT耗时平均下降58%
在长对话代码分析场景中,AutoContextMemory 展现出显著优势:
- ✅ 成本控制:Token 消耗降低 70% 左右,大幅节省 API 调用成本
- ✅ 性能提升:响应时间减少 60%左右,用户体验显著改善
五、事件追踪与内存可视化分析
为什么需要分析工具?
AutoContextMemory 虽然提供了自动压缩功能,但不同业务场景下的最佳配置参数是不同的。盲目使用默认配置可能导致:
- 压缩过于频繁:增加不必要的 LLM 调用成本
- 压缩不够及时:上下文窗口仍然超出限制
- 策略选择不当:使用了成本高但效果差的压缩策略
因此,AutoContextMemory 提供了完整的压缩事件追踪和内存分析功能,帮助开发者根据实际场景数据驱动地优化配置参数。
内存状态可视化分析
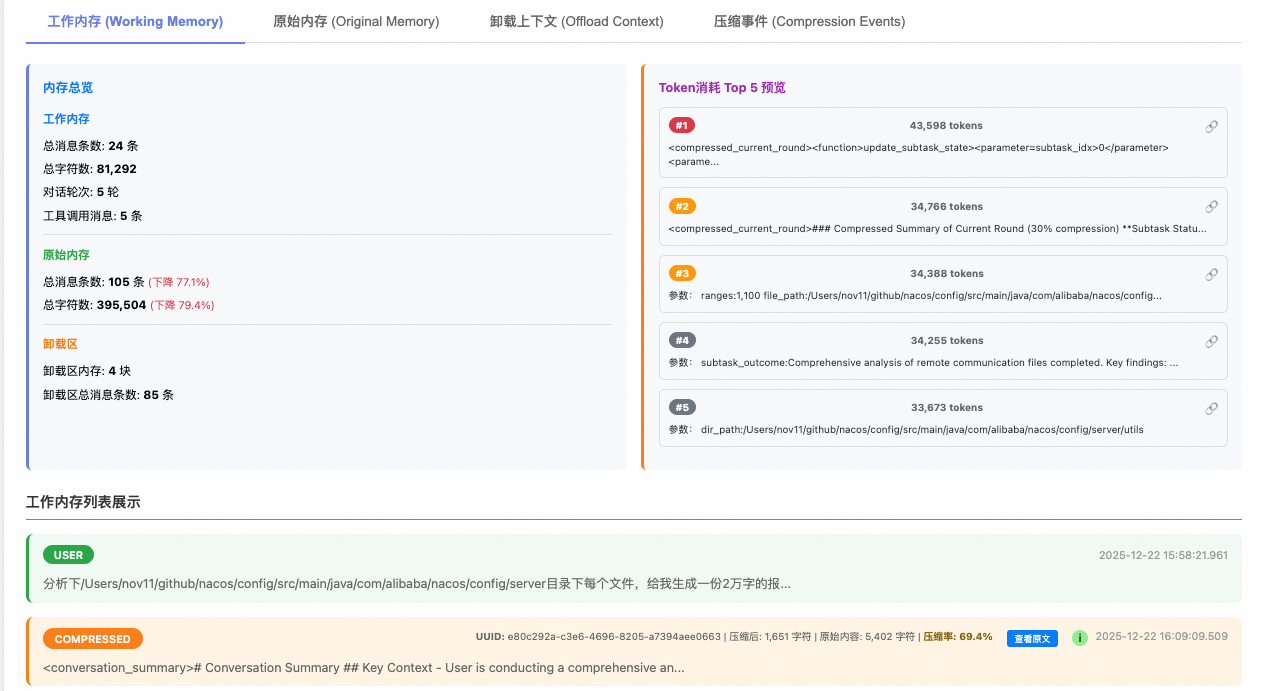
AutoContextMemory 提供了丰富的内存状态信息,包括:
- 工作内存存储(压缩后):实际用于对话的消息数量和 token 数量
- 原始内存存储(完整历史):未压缩的完整消息历史
- 用户-助手交互消息:过滤工具调用后的纯对话记录
- 卸载上下文:已卸载到外部存储的消息条目数
通过对比工作内存和原始内存的差异,可以直观地看到压缩效果。例如:
- 消息压缩率:工作内存消息数 / 原始内存消息数
- Token 压缩率:工作内存 token 数 / 原始内存 token 数
- 压缩事件统计:各策略的使用频率和效果
注:AutoContext Analysis 当前处于试验阶段,可通过 https://mse-public-temp.oss-cn-shenzhen.aliyuncs.com/autocontext-memory-analysis-v0.1.zip 下载体验。使用方式:解压 zip 包后,通过浏览器打开
analysis.html文件即可。需要注意的是,当前版本仅支持分析通过 JsonSession 序列化至本地的 session 文件,具体使用方法可参考 AutoMemoryExample 中的示例。
AucoContext Analysis工具示意图
- 工作内存
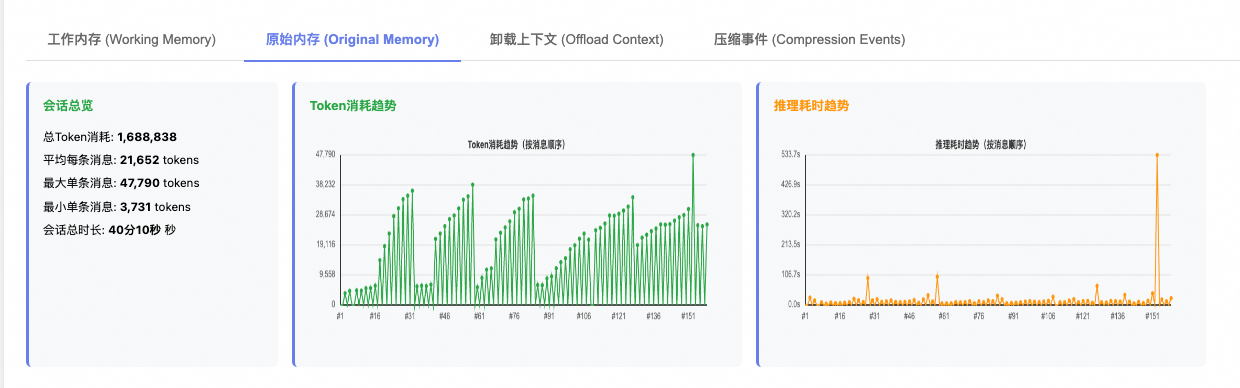
- 原始内存
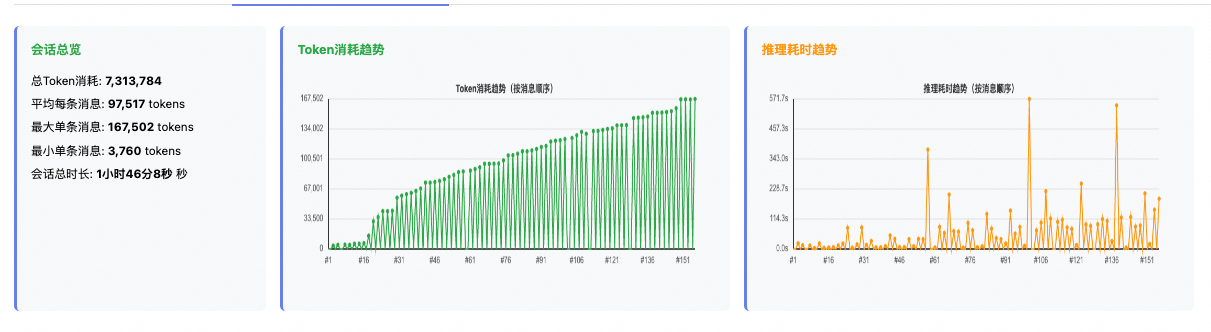
未执行压缩:可以明显看到随着对话轮次增加,每次推理的Token消耗线性增长
执行自动压缩:Token消耗因自动压缩机制呈现锯齿状
- 卸载上下文
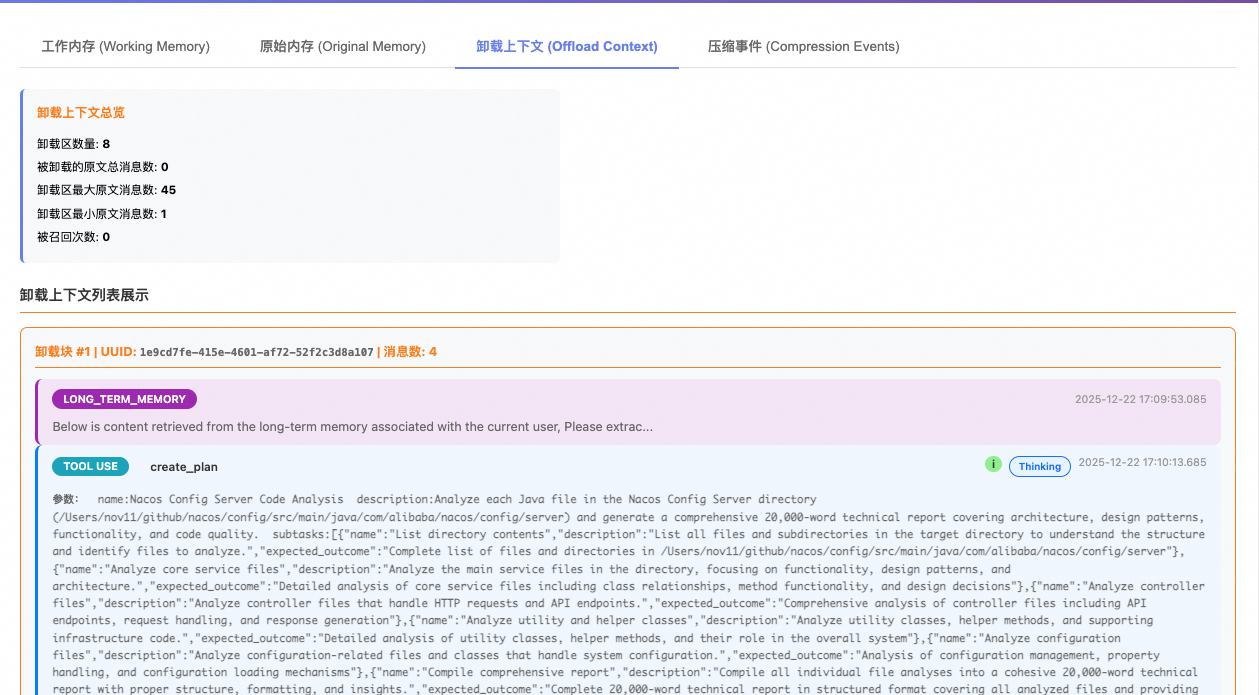
- 压缩事件
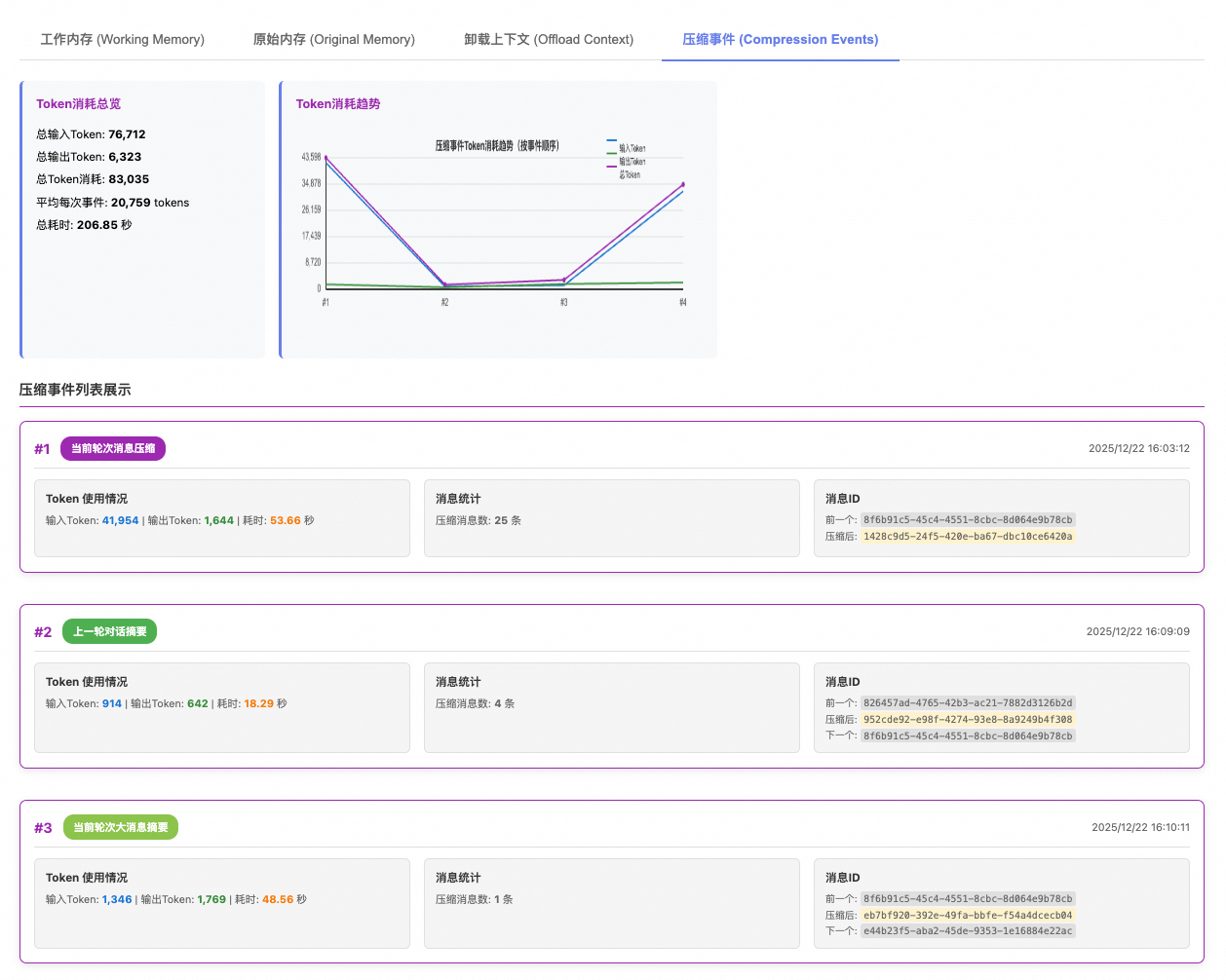
如何根据分析数据优化配置?
场景 1:压缩过于频繁
如果分析发现压缩事件非常频繁,但每次压缩的消息数量很少,说明 msgThreshold 或 tokenRatio 设置过低。
优化建议:
- 适当提高
msgThreshold(如从 30 提高到 50) - 适当提高
tokenRatio(如从 0.3 提高到 0.5)
场景 2:压缩效果不佳
如果发现压缩后 token 数量仍然很高,或者压缩率很低,可能的原因:
lastKeep设置过大,保护了太多消息不被压缩- 当前轮次消息过大,需要调整
currentRoundCompressionRatio - 大型消息阈值
largePayloadThreshold设置过高,导致卸载策略未触发
优化建议:
- 适当降低
lastKeep(如从 50 降低到 20) - 调整
currentRoundCompressionRatio(如从 0.3 调整到 0.2) - 降低
largePayloadThreshold(如从 5K 降低到 3K)
场景 3:压缩成本过高
如果发现压缩操作本身的 token 成本接近或超过节省的 token,说明:
- 可能使用了过于重量级的压缩策略(如策略 4、5、6)
- 建议优先使用轻量级策略(策略 1、2、3)
优化建议:
- 调整
minConsecutiveToolMessages,让策略 1 更早触发 - 降低
largePayloadThreshold,让策略 2、3 更早触发 - 避免频繁触发策略 4、5、6
六、结语
AutoContextMemory 的设计目标是满足 80% 以上场景的自动化上下文压缩需求,同时提供丰富的参数化配置以满足个性化场景需求。我们希望开发者更多地关注 Agent 的业务需求层面,如 Prompt 设计、工具集构建、知识库构建等,而上下文管理、自动压缩、资源优化等底层技术细节都由系统自动处理。
如果你在实际项目中使用了 AutoContextMemory,欢迎分享你的使用体验和反馈,这将帮助组件不断完善。同时,我们也期待社区能够参与贡献,一起探索更优的上下文压缩策略和实现方案。
相关资源:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)