Yarn资源调度器
目录
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
Container:【节点NM,CPU,MEM,I/O大小,启动命令】
Hadoop集群的启动脚本:startha.sh(3.x版本)
Yarn架构剖析
YARN(Yet Another Resource Negotiator):
核心思想:将MapReduce Version 1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。YARN的引入,使得多个计算可运行在一个集群中, 每个job对应一个ApplicationMaster。 目前多个计算框架可以运行在YARN上,比如MapReduce、Spark等解耦资源与计算。
Yarn是一个资源调度平台,负责为运行的程序(提交job作业)提供服务器的资源(CPU、Mem..,网络等)。
-
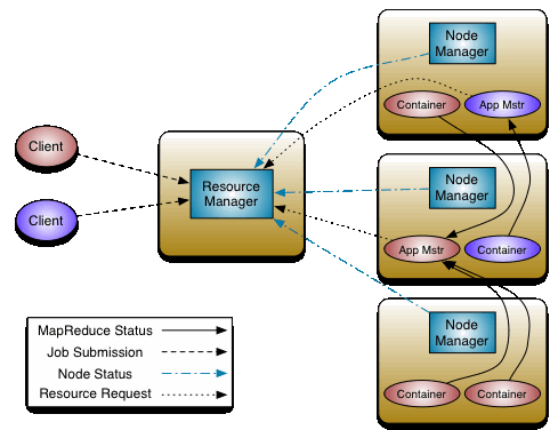
ResourceManager(简称RM)主要作用:
-
处理客户端的请求
-
监控NodeManager
-
启动和监控ApplicationMaster
-
负责整个集群的资源管理和调度
-
-
NodeManager:
-
与RM汇报资源
-
管理当前服务器上的Container容器
-
处理来自RM的指令
-
处理来之ApplicationMaster指令
-
-
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
-
以作业为单位,负载到不同的节点,避免单点故障。
-
向RM申请创建Task任务(MapTask、ReduceTask)所需要资源(Container)
-
负责任务切分、任务调度、任务监控和容错等
-
-
Container:【节点NM,CPU,MEM,I/O大小,启动命令】
-
默认NodeManager启动线程监控Container大小
-
超出申请资源额度,被kill掉
-
-
Client:
-
• RM-Client:请求资源创建AM
-
• AM-Client:与AM交互
-
MRAppMaster容错
-
失败后,由YARN重新启动
-
任务失败后,MRAppMaster重新申请资源
Yarn工作机制
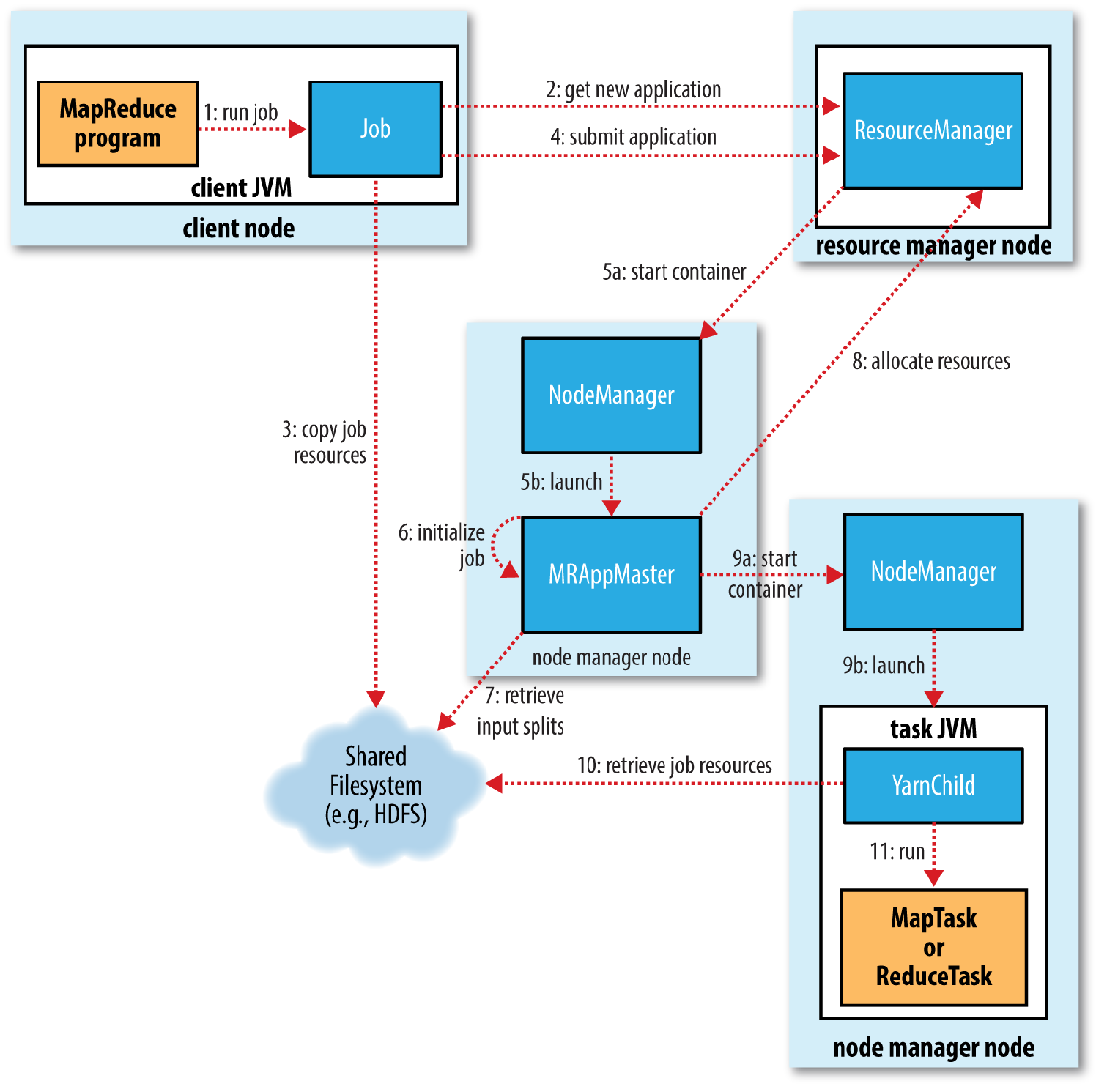
一. 作业提交:
1.提交作业job后,job.waitForCompletion(true)调用monitorAndPrintJob()方法每秒轮询作业进度,如果发现自上次报告后有改变,便把进度报告给控制台。Job的submit()方法创建一个内部的JobSubmitter实例,并调用其submitJobInternal方法(步骤1)。作业完成后,如果成功,就显示计数器;如果失败,这将导致作业失败的错误记录到控制台。
JobSubmitter所实现的作业提交过程如下所述:
2.向资ResourceManager源管理器请求一个新作业的ID,用于MapReduce作业ID。
3.作业客户端检查作业的输出说明,计算输入分片splits并将作业资源(包括作业Jar包、配置文件和分片信息)复制到HDFS
4.通过调用资源管理器上的submitApplication()方法提交作业
二.作业初始化
5.资源管理器ResourceManager收到调用他的submitApplication()消息后,便将请求传递给调度器(scheduler)。调度器分配一个容器(Container),然后资源管理器在节点管理器(NodeManager)的管理下载容器中启动应用程序的master进程(步骤5a和5b)
6.MapReduce作业的application master是一个Java应用程序,它的主类是MRAppMaster。它对作业进行初始化:通过创建多个簿记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告(步骤6)。
7.接下来,它接受来自共享文件系统的在客户端计算的输入分片(步骤7)。对每一个分片创建一个map任务对象以及由mapreduce. job.reduces属性确定的具体数量的reduce任务对象。
三.任务分配
8.AppMaster为该作业中的所有map任务和reduce任务向资源管理器请求容器。
四.任务执行
9.一旦资源管理器的调度器为任务分配了容器,AppMaster就通过与节点管理器NodeManager通讯来启动容器(步骤9a和9b)。
10.该任务由主类为YarnChild的Java应用程序执行。在它允许任务之前,首先将任务需要的资源本地化,包括作业的配置、JAR文件和所有来自分布式缓存的文件.
11.最后运行map任务或reduce任务。
五.进度和状态更新
在YARN下运行时,任务每3秒钟通过umbilical接口向APPMaster汇报进度和状态。客户端每一秒钟(通过mapreduce.client.Progressmonitor.pollinterval设置)查询一次AppMaster以接收进度更新,通常都会向用户显示。
六.作业完成
除了向AppMaster查询进度外,客户端每5秒还通过调用Job的waitForCompletion()来检测作业是否完成。查询的间隔可以通过mapreduce.client.completion.pollinterval属性进行设置。作业完成后,AppMaster和任务容器清理器工作状态。
类比总结
为了方便理解,我们可以把上述工作流程类比成 一家工厂接订单、安排生产、完成订单的全过程。
| 流程步骤 | 工厂生产场景 | Yarn 工作机制 |
|---|---|---|
| 一、作业提交(1-4) |
客户下单 1. 客户(客户端)想做一批玩具,打电话给工厂(集群),说要下订单(提交 Job)。 2. 工厂前台(ResourceManager)给客户分配一个唯一订单号(JobID),方便后续跟踪。 3. 客户准备好生产资料:玩具设计图纸(配置文件)、原材料清单(输入分片 splits)、制作手册(Jar 包),全部送到工厂仓库(HDFS)。 4. 客户正式把订单交给前台,确认开工。 |
1. 客户端调用 2. 向 ResourceManager 请求 JobID。 3. 检查输出、计算分片,把 Jar 包 / 配置 / 分片信息上传到 HDFS。 4. 调用 |
| 二、作业初始化(5-7) |
厂长安排生产负责人 5. 前台(ResourceManager)收到订单,交给生产调度员(Scheduler),调度员分配一个独立的生产车间(Container),并安排一位车间主任(MRAppMaster)来负责这个订单的全流程。 6. 车间主任到岗后,先准备生产台账(簿记对象),用来记录每一步生产进度、零件损耗、工人考勤。 7. 车间主任去仓库(HDFS)领出客户送来的资料,根据原材料清单(分片),确定要分 N 个小组做零件(Map 任务,数量 = 分片数),再安排 M 个小组组装零件(Reduce 任务,数量 = |
5. ResourceManager 把请求给 Scheduler,Scheduler 分配 Container,在 NodeManager 上启动 MRAppMaster。 6. MRAppMaster 创建簿记对象,跟踪任务进度和完成报告。 7. 从 HDFS 读取输入分片,创建对应数量的 Map 任务和 Reduce 任务。 |
| 三、任务分配(8) |
车间主任申请工人和设备 8.车间主任(MRAppMaster)向工厂前台(ResourceManager)申请:需要多少工人、多少台机器(对应资源),用来完成 N 个零件小组和 M 个组装小组的工作。 |
8.AppMaster 为所有 Map/Reduce 任务,向 ResourceManager 申请 Container 资源。 |
| 四、任务执行(9-11) |
工人开工生产 9. 前台(ResourceManager)批准资源,调度员派工人和机器到指定车间(Container),车间主任(MRAppMaster)通知车间管理员(NodeManager):让工人就位开工。 10. 工人到岗后,先去仓库领自己需要的工具:图纸(配置)、手册(Jar 包)、零件(分布式缓存文件),放在自己工位上(本地化资源)。 11. 零件小组(Map 任务)开始加工原材料,组装小组(Reduce 任务)等着零件做好后,统一组装成成品。 |
9. Scheduler 分配 Container 后,AppMaster 通知 NodeManager 启动容器。 10. 容器中启动 11. 运行 Map 任务处理分片数据,运行 Reduce 任务汇总 Map 结果。 |
| 五、进度和状态更新 |
汇报生产进度 1. 每个工人每 3 分钟,向车间主任汇报一次:“我做了多少零件 / 组装了多少成品”(任务通过 umbilical 接口向 AppMaster 报进度)。 2. 客户(客户端)每 1 分钟打一次电话给车间主任,问订单进度,主任随时反馈,客户心里有数。 |
1. 任务每 3 秒向 AppMaster 汇报进度和状态。 2. 客户端每秒查询 AppMaster,获取进度并显示到控制台。 |
| 六、作业完成 | 订单交付收尾 1. 客户除了查进度,还会每 5 分钟问一次前台:“我的订单做完了吗?”(客户端调用 waitForCompletion() 检测作业完成)。 2. 所有零件做完、组装完毕(作业完成),车间主任(AppMaster)安排人清理车间(清理容器资源),把成品交给客户,订单结束。 |
1. 客户端每 5 秒通过 2. 作业完成后,AppMaster 和任务容器清理资源,客户端拿到最终计算结果。 |
YARN RM-HA搭建
文档查看与集群规划
RM高可用官方网址:
http://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
本地进入文档首页:
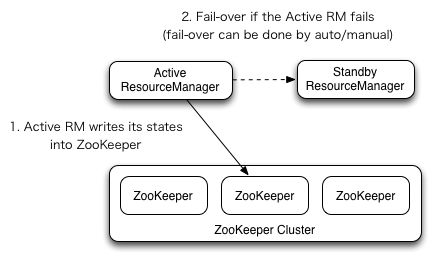
RM高可用机制:
RM高可用集群规划:
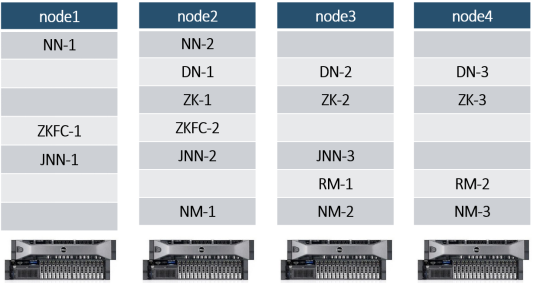
可以在之前NameNode HA的基础上继续配置。详情参考:NameNode HA(高可用)-CSDN博客
相关文件配置
1.mapred-site.xml
[root@node1 ~]# cd /opt/hadoop-3.1.3/etc/hadoop/
[root@node1 hadoop]# vim mapred-site.xml
# 修改文件内容
<configuration>
<!--作业资源管理Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.yarn-site.xml
<configuration>
<!-- 让yarn的容器支持mapreduce的洗牌,开启shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定zookeeper集群的各个节点地址和端口号 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的状态信息存储在zookeeper集群 -->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 声明两台resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定resourcemanager的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- rm1的配置 -->
<!-- 指定rm1的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<!-- 指定rm1的web端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node3:8088</value>
</property>
<!-- 指定rm1的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>node3:8032</value>
</property>
<!-- 指定AM向rm1申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>node3:8030</value>
</property>
<!-- 指定供NM连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>node3:8031</value>
</property>
<!-- rm2的配置 -->
<!-- 指定rm2的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node4:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>node4:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>node4:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>node4:8031</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_MAPRED_HOME,HADOOP_YARN_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<!-- 关闭yarn对物理内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>3.将配置文件在四台服务器同步
[root@node1 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
[root@node1 hadoop]#scp mapred-site.xml yarn-site.xml node2:`pwd`
[root@node1 hadoop]#scp mapred-site.xml yarn-site.xml node3:`pwd`
[root@node1 hadoop]#scp mapred-site.xml yarn-site.xml node4:`pwd`启动与测试
启动
node1上首先启动HDFS集群,使用之前写的脚本,详情参考:NameNode HA(高可用)-CSDN博客
[root@node1 hadoop]# starthdfs.sh在node3和node4上执行命令,启动ResourceManager:
[root@node3 ~]# start-yarn.sh
Starting resourcemanagers on [ node3 node4]
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
#需要在start-yarn.sh和stop-yarn.sh中配置YARN_RESOURCEMANAGER_USER和YARN_NODEMANAGER_USER
[root@node3 sbin]#cd /opt/hadoop-3.1.3/sbin
[root@node3 sbin]# vim start-yarn.sh
#添加一下两条配置
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node3 sbin]# vim stop-yarn.sh
#添加一下两条配置
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node3 sbin]# start-yarn.sh
Starting resourcemanagers on [ node3 node4]
上一次登录:三 1月 14 10:33:25 CST 2026从 192.168.20.1pts/0 上
node3: Warning: Permanently added 'node3,192.168.20.103' (ECDSA) to the list of known hosts.
Starting nodemanagers
上一次登录:三 1月 14 11:08:11 CST 2026pts/0 上
node2: Warning: Permanently added 'node2,192.168.20.102' (ECDSA) to the list of known hosts.
#可以通过jps查看,也可以调用node1上的allJps.sh脚本查看:发现node3和node4上分别多一个RM进程,node2、node3、node4上分别多出一个NodeManager进程。
#查看服务 arn rmadmin -getServiceState rm1
[root@node3 sbin]# yarn rmadmin -getServiceState rm1
standby
[root@node3 sbin]# yarn rmadmin -getServiceState rm2
active #说明node4上ResourceManager为Active状态。
测试
去zk集群节点上查看:
[root@node4 ~]# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, rmstore, yarn-leader-election, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /restore
Node does not exist: /restore
[zk: localhost:2181(CONNECTED) 2] ls /rmstore
[ZKRMStateRoot]
[zk: localhost:2181(CONNECTED) 3] ls /yarn-leader-election
[cluster-yarn1]
[zk: localhost:2181(CONNECTED) 4] get -s /rmstore/ZKRMStateRoot
null
cZxid = 0x400000013
ctime = Wed Jan 14 11:08:16 CST 2026
mZxid = 0x400000013
mtime = Wed Jan 14 11:08:16 CST 2026
pZxid = 0x40000002a
cversion = 16
dataVersion = 0
aclVersion = 1
ephemeralOwner = 0x0
dataLength = 0
numChildren = 6
通过浏览器测试:
http://node3:8088 或者 http://node4:8088 都会被重定向到状态为Active节点的信息页面上,目前我的node4上的RM是Active:
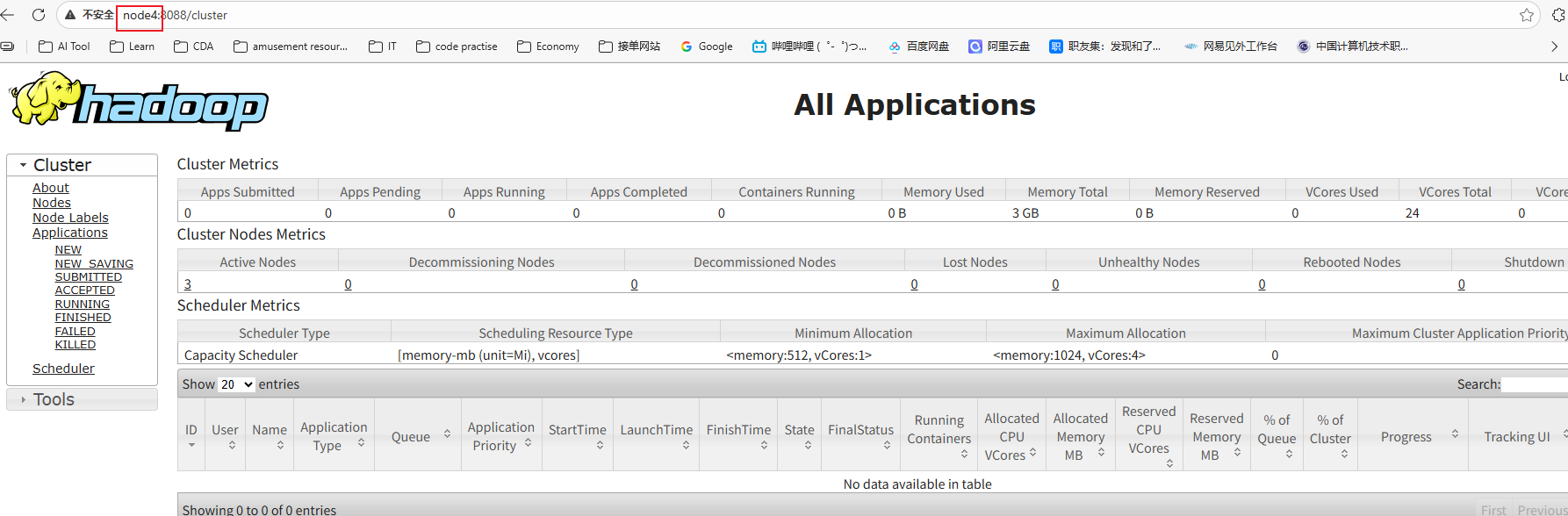
查看node3上的RM的状态信息:
http://node3:8088/cluster/cluster
查看node4上的RM的状态信息:
http://node4:8088/cluster/cluster
高可用演示:
Active对应的节点node3或node4上执行:
[root@node4 ~]# yarn --daemon stop resourcemanager
[root@node4 ~]# yarn --daemon start resourcemanagerhttp://node3:8088/cluster/cluster
http://node4:8088/cluster/cluster
启动脚本和停止脚本
Hadoop集群的启动脚本:startha.sh(3.x版本)
[root@node1 bin]# pwd
/root/bin
[root@node1 bin]# vim startha.sh
#!/bin/bash
#启动zk集群
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh start"
done
#休眠1s
sleep 1
#启动hdfs集群
start-dfs.sh
#启动yarn
ssh node3 "source /etc/profile;start-yarn.sh"
#查看四个节点上的java进程
allJps.sh
[root@node1 bin]# chmod +x startha.sh #添加执行权限Hadoop集群的关闭脚本stopha.sh (3.x)
[root@node1 bin]# vim stopha.sh
#!/bin/bash
#关闭yarn
ssh node3 "source /etc/profile;stop-yarn.sh"
#关闭hdfs
stop-dfs.sh
#关闭zk集群
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh stop"
done
#查看java进程
allJps.sh
[root@node1 bin]# chmod 755 stopha.sh #添加执行权限
[root@node1 bin]# ll
总用量 20
-rwxr-xr-x 1 root root 221 1月 13 10:21 allJps.sh
-rwxr-xr-x 1 root root 228 1月 14 11:27 startha.sh
-rwxr-xr-x 1 root root 418 1月 13 10:15 starthdfs.sh
-rwxr-xr-x 1 root root 228 1月 14 11:28 stopha.sh
-rwxr-xr-x 1 root root 211 1月 13 10:20 stophdfs.sh
配置完成给各个节点拍摄快照
资源调度器
目前,Hadoop作业调度器没有好坏之分,只有适合与否之分,所以Hadoop提供三种调度器让使用者进行选择,这三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.1.3默认的资源调度器是Capacity Scheduler。具体设置详见:yarn-default.xml文件
| Property | yarn.resourcemanager.scheduler.class |
|---|---|
| Value | org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler |
<!-- 修改自己搭建集群的调度器,修改yarn-site.xml文件 -->
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>先进先出调度器(FIFO)
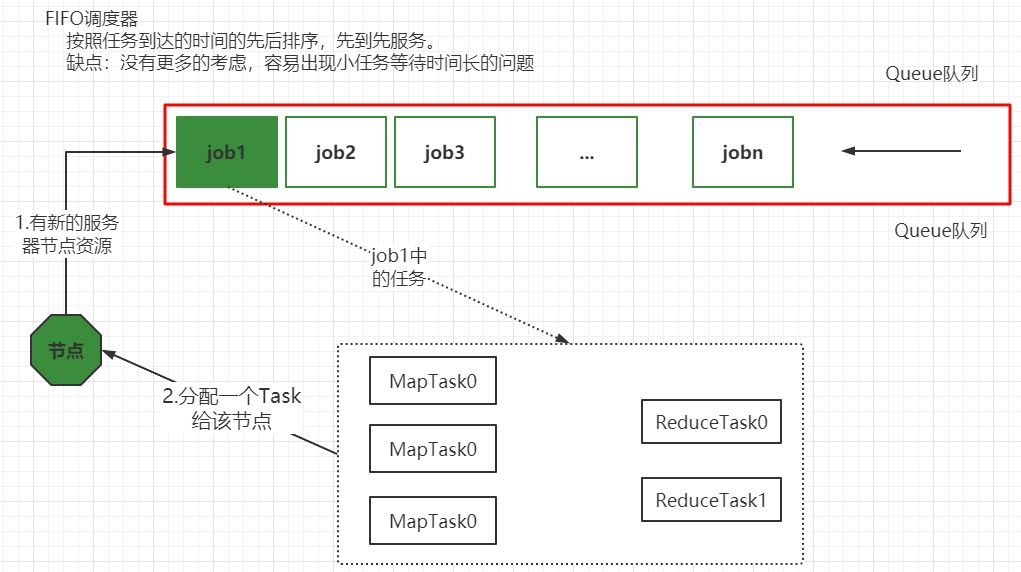
Hadoop最初设计目的是支持大数据批处理作业,如日志挖掘、Web索引等作业,为此,Hadoop仅提供了一个非常简单的调度机制:FIFO,即先来先服务,在该调度机制下,所有作业被统一提交到一个队列中,Hadoop按照提交顺序依次运行这些作业。
但随着Hadoop的普及,单个Hadoop集群的任务处理量越来越多,不同用户提交的应用程序往往具有不同的服务质量要求,典型的应用有以下几种:
-
批处理作业:这种作业往往耗时较长,对时间完成一般没有严格要求,如数据挖掘、机器学习等方面的应用程序。
-
交互式作业:这种作业期望能及时返回结果,如HQL查询(Hive)等。
-
实时统计作业:这种作业要求有一定量的资源保证,如淘宝交易量大屏等。
此外,这些应用程序对硬件资源需求量也是不同的,因此,简单的FIFO调度策略不仅不能满足多样化需求,也不能充分利用硬件资源。
容量调度器(Capacity Scheduler)
先保证配额,再弹性共享,像给每个部门分配固定办公室,闲置时可借出去,需要时收回,适合生产环境的强 SLA 保障;
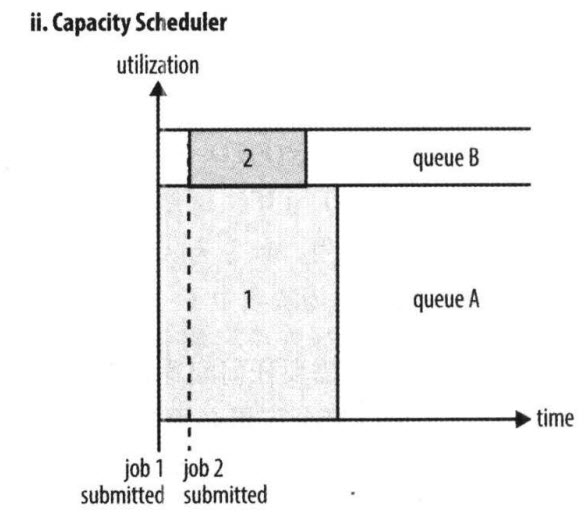
Capacity Scheduler 是Yahoo开发的多用户调度器。
-
它以队列为单位划分资源,支持多个队列,每个队列可设定一定比例的资源最低保证和使用上限。
-
每个队列采用是FIFO调度策略。
-
为了防止同一个用户的作业独占队列中的资源,调度器会对同一个用户提交的作业所占的资源量进行限定。
-
当有任务被提交时,计算每个队列中正在运行的任务数/该对应应分得的计算资源 的比值,任务分给比值最小(最闲)的队列。
-
每个队列最前端的作业可以并行运行。
总之,Capacity Scheduler 主要有以下几个特点:
-
容量保证。管理员可为每个队列设置资源最低保证和资源使用上限,而所有提交到该队列的应用程序共享这些资源。
-
灵活性,如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。这种资源灵活分配的方式可明显提高资源利用率。
-
多重租赁。支持多用户共享集群和多应用程序同时运行。为防止单个应用程序、用户或者队列独占集群中的资源,管理员可为之增加多重约束(比如单个应用程序同时运行的任务数等)。
-
安全保证。每个队列有严格的ACL列表规定它的访问用户,每个用户可指定哪些用户允许查看自己应用程序的运行状态或者控制应用程序(比如杀死应用程序)。此外,管理员可指定队列管理员和集群系统管理员。
-
动态更新配置文件。管理员可根据需要动态修改各种配置参数,以实现在线集群管理。
公平调度器(Fair Scheduler)
动态均分资源,像共享办公区,人少的时候一人占多桌,人多了自动均分,适合研发测试、混合负载场景,避免小任务饥饿。
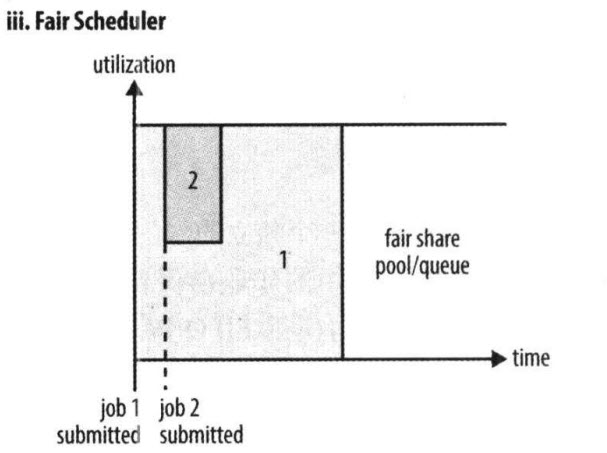
Fair Scheduler 是Facebook开发的多用户调度器。
公平调度器的目的是让所有的作业随着时间的推移,都能平均地获取等同的共享资源。当有作业提交上来,系统会将空闲的资源分配给新的作业,每个任务大致上会获取平等数量的资源。和传统的调度策略不同的是它会让小的任务在合理的时间完成,同时不会让需要长时间运行的耗费大量资源的任务挨饿!
同Capacity Scheduler类似,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用;当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
当然,Fair Scheduler也存在很多与Capacity Scheduler不同之处,这主要体现在以下几个方面:
① 资源公平共享。
在每个队列中,Fair Scheduler 可选择按照FIFO、Fair或DRF策略为应用程序分配资源。其中:
FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,就是禁用掉每个队列中的Task共享队列资源,此时公平调度器相当于上面讲过的容量调度器。
Fair策略
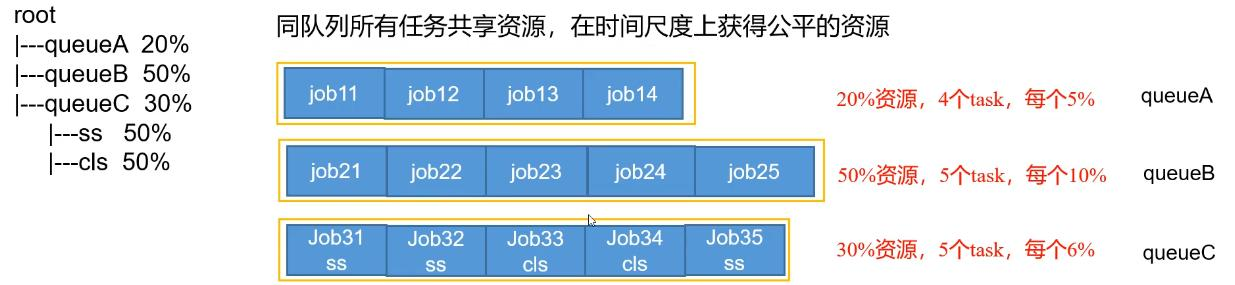
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
【扩展:】最大最小公平算法举例:
1.不加权(关注点是job的个数):
有一条队列总资源12个, 有4个job,对资源的需求分别是:
job1->1, job2->2 , job3->6, job4->5
第一次算: 12 / 4 = 3
job1: 分3 --> 多2个
job2: 分3 --> 多1个
job3: 分3 --> 差3个
job4: 分3 --> 差2个
第二次算: 3 / 2 = 1.5
job1: 分1
job2: 分2
job3: 分3 --> 差3个 --> 分1.5 --> 最终: 4.5
job4: 分3 --> 差2个 --> 分1.5 --> 最终: 4.5
第n次算: 一直算到没有空闲资源
2.加权(关注点是job的权重):
有一条队列总资源16,有4个job
对资源的需求分别是: job1->4 job2->2 job3->10 job4->4
每个job的权重为: job1->5 job2->8 job3->1 job4->2
第一次算: 16 / (5+8+1+2) = 1
job1: 分5 --> 多1
job2: 分8 --> 多6
job3: 分1 --> 少9
job4: 分2 --> 少2
第二次算: 7 / (1+2) = 7/3
job1: 分4
job2: 分2
job3: 分1 --> 分7/3 --> 少
job4: 分2 --> 分14/3(4.66) -->多2.66
第三次算:
job1: 分4
job2: 分2
job3: 分1 --> 分7/3 --> 分2.66
job4: 分4
第n次算: 一直算到没有空闲资源
DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU, 100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
②支持资源抢占。
当某个队列中有剩余资源时,调度器会将这些资源共享给其他队列,而当该队列中有新的应用程序提交时,调度器要为它回收资源。为了尽可能降低不必要的计算浪费,调度器采用了先等待再强制回收的策略,即如果等待一段时间后尚有未归还的资源,则会进行资源抢占:从那些超额使用资源的队列中杀死一部分任务,进而释放资源。
yarn.scheduler.fair.preemption=true 通过该配置开启资源抢占。
③提高小应用程序响应时间。
由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)