Yolov12-main框架内容介绍
是你将训练好的 YOLO 模型投入实际应用的“万能接口”。它定义了如何加载、验证和增强YOLO格式的数据,是连接你的标注文件与训练模型的桥梁。这个exporter.py文件是模型格式转换器,负责把训练好的PyTorch模型(.pt文件)转换成其他格式,以便在不同设备上运行。这个文件是Ultralytics YOLO的数据集转换工具,主要用于将不同格式的标注数据转换为YOLO训练所需的格式。是 YO
一、根目录主要文件
1.datasets --- 存放训练/验证/测试数据集
2.docker --- Docker容器化部署配置
|
Dockerfile |
默认或通用版本的 Docker 镜像构建文件,通常用于 x86-64 架构。 |
|
Dockerfile-arm64 |
专为 ARM64 架构(如苹果 M1/M2、树莓派等)设计的镜像构建文件。 |
|
Dockerfile-conda |
使用 Conda 作为 Python 环境管理器的镜像构建文件,适合科学计算或复杂依赖场景。 |
|
Dockerfile-cpu |
仅支持 CPU 运行的镜像,通常用于无需 GPU 的机器学习或推理任务。 |
|
Dockerfile-jetson-jetpack4 |
针对 NVIDIA Jetson 平台(JetPack 4 版本)的镜像构建文件。 |
|
Dockerfile-jetson-jetpack5 |
针对 NVIDIA Jetson 平台(JetPack 5 版本)的镜像构建文件。 |
|
Dockerfile-jetson-jetpack6 |
针对 NVIDIA Jetson 平台(JetPack 6 版本)的镜像构建文件。 |
|
Dockerfile-jupyter |
内置 Jupyter Notebook/Lab 环境的镜像,适合交互式开发或教学。 |
|
Dockerfile-python |
仅包含 Python 运行环境的轻量级镜像。 |
|
Dockerfile-runner |
可能用于 CI/CD 或任务执行器的专用镜像,如 GitHub Actions Runner 等。 |
3.1多框架推理实例
|
YOLOv8-ONNXRuntime |
使用 ONNX Runtime 运行 YOLOv8(可能是 Python 版本) |
|
YOLOv8-ONNXRuntime-CPP |
使用 C++ 和 ONNX Runtime 运行 YOLOv8 |
|
YOLOv8-OpenCV-ONNX-Python |
使用 OpenCV 和 ONNX 模型运行 YOLOv8(Python) |
|
YOLOv8-OpenVINO-CPP-Inference |
使用 OpenVINO 在 C++ 中运行 YOLOv8推理 |
|
YOLOv8-TFLite-Python |
使用 TensorFlow Lite 在 Python 中运行 YOLOv8 |
3.2多语言支持
|
YOLOv8-CPP-Inference |
纯 C++ 推理实现 |
|
YOLOv8-LibTorch-CPP-Inference |
使用 LibTorch(PyTorch C++ API)进行推理 |
|
YOLO-Series-ONNXRuntime-Rust |
使用 Rust 语言和 ONNX Runtime 运行 YOLO |
|
YOLOv8-ONNXRuntime-Rust |
使用 Rust 和 ONNX Runtime 运行 YOLOv8 |
3.3特殊模型和任务
|
RTDETR-ONNXRuntime-Python |
RT-DETR(实时检测变换器)模型在 ONNX Runtime 中的使用 |
|
YOLOv8-Segmentation-ONNXRuntime-Python |
实例分割任务在 ONNX Runtime 中的实现 |
|
YOLOv8-Action-Recognition |
行为识别应用示例 |
|
YOLOv8-SAHI-Inference-Video |
使用 SAHI(切片辅助超推理)处理视频中的小目标检测 |
3.4应用场景实例
|
YOLOv8-Region-Counter |
区域计数应用,统计特定区域内物体数量 |
|
object_counting.ipynb |
Jupyter Notebook:物体计数实现 |
|
object_tracking.ipynb |
Jupyter Notebook:物体跟踪实现 |
|
heatmaps.ipynb |
Jupyter Notebook:生成热力图可视化 |
3.5工具和教程
|
hub.ipynb |
Jupyter Notebook:使用 Ultralytics HUB(云端平台) |
|
tutorial.ipynb |
Jupyter Notebook:基础教程 |
|
README.md |
示例目录的说明文档 |
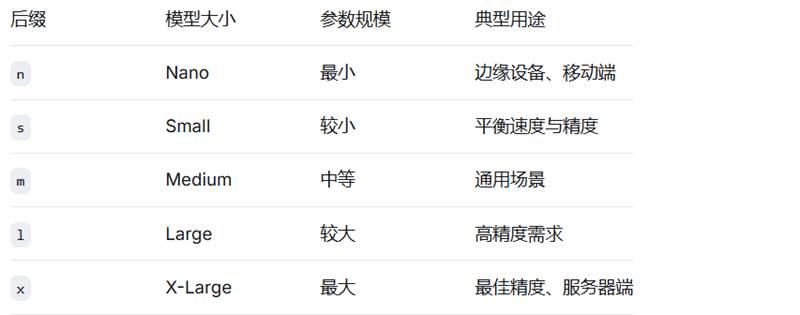
日志信息解释:

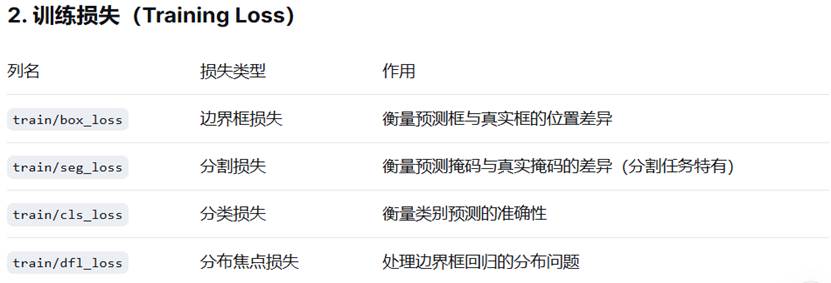
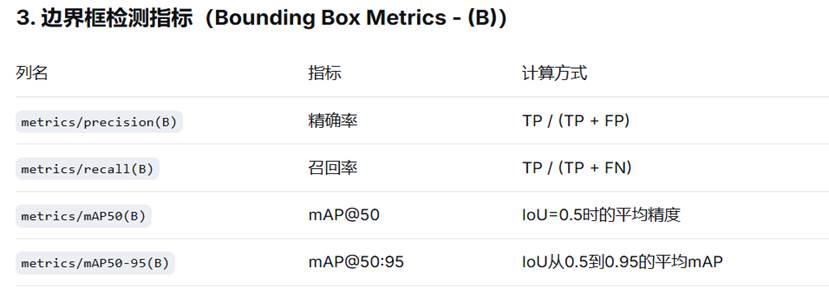
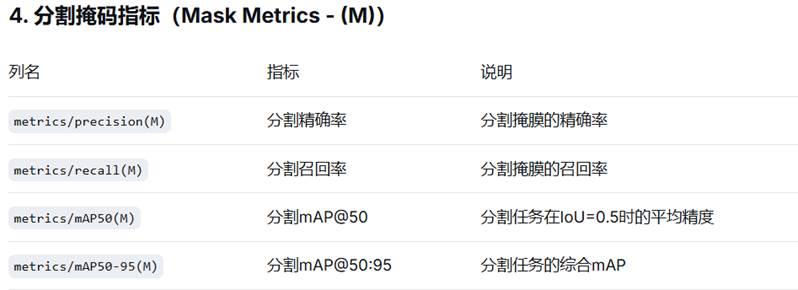
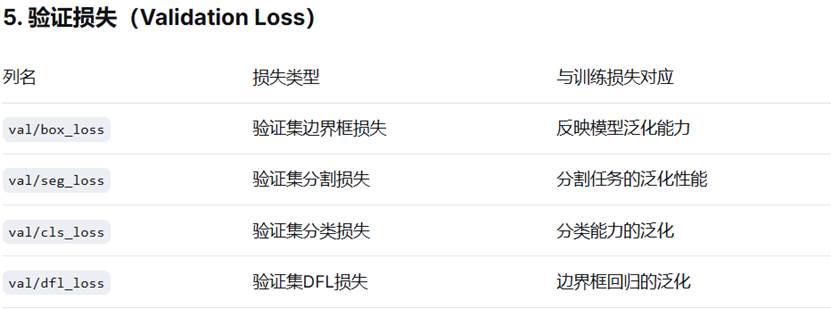
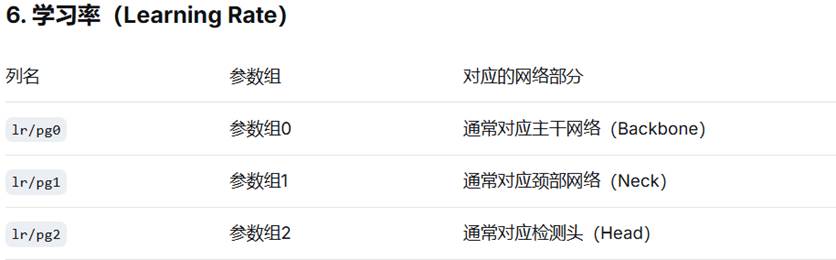
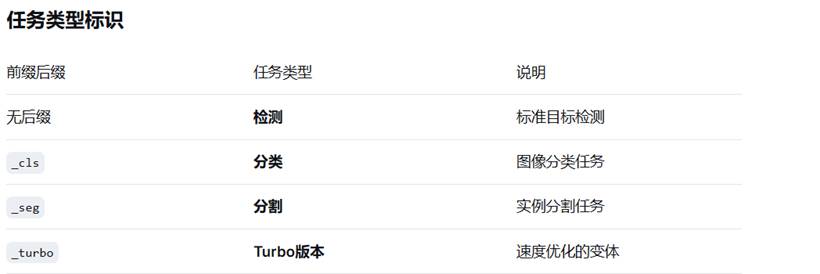
其中,着重介绍:
Precision (精确率/查准率)
Precision = TP / (TP + FP)
= 正确预测的目标数 / 所有预测的目标数
TP (True Positive): 模型预测正确(确实是目标)
FP (False Positive): 模型误报(把背景或其他物体当成目标)
# 假设检测结果:
预测框:10个
其中正确预测:7个(与真实框匹配且IoU>阈值)
误报:3个(其实是背景或其他物体)
Precision = 7 / (7 + 3) = 0.7 = 70%
模型说有目标的地方,70%确实有目标,30%是误判。
高Precision: 模型很谨慎,宁可漏检也不误检
Recall (召回率/查全率)
Recall = TP / (TP + FN)
= 正确预测的目标数 / 真实存在的所有目标数
TP (True Positive): 模型预测正确(确实是目标)
FN (False Negative): 模型漏检(真实目标没被检测出来)
# 假设真实情况:
真实目标:15个
模型检测到:12个(其中7个正确,5个误报)
漏检:3个(目标存在但模型没检测出来)
Recall = 7 / (7 + 3) = 0.7 = 70%
真实存在的目标中,模型找出了70%。
想知道模型找得全不全,看召回率。
想知道模型找得对不对,看精确率
mAP50 (mean Average Precision at IoU=0.5,平均精度均值)
IoU (Intersection over Union):预测框与真实框的重叠程度
IoU = 预测框∩真实框的面积 / 预测框∪真实框的面积
50: IoU阈值为0.5(50%)
(B): Bounding Boxes(边界框检测任务)
当预测框与真实框有50%以上重叠时,模型识别目标的能力有多好?
计算过程:
1. 对于每个类别:
a. 计算不同置信度阈值下的Precision-Recall曲线
b. 在得到多个recall和precision点之后,对每个Recall值,取该Recall值及之后所有Precision中的最大值(就是为了确保Precision-Recall曲线是单调递减的)
b. 利用梯形积分法计算平滑PR曲线下的面积→ AP (Average Precision)
2. 如果有多个类别(人,车,横幅)就对所有类别的AP取平均值 → mAP
3. 使用IoU=0.5的标准判断预测是否正确
mAP50-95(B) - 综合检测精度
mAP50-95: 在IoU从0.5到0.95(步长0.05)的10个阈值下的平均mAP
计算过程:
mAP50-95的计算流程总结:
- 设置10个IoU阈值:从0.5到0.95,步长0.05
- 对每个IoU阈值:
计算每个类别的AP(Precision-Recall曲线下面积)
对所有类别的AP取平均,得到该IoU下的mAP
- 对10个mAP取平均:得到最终的mAP50-95
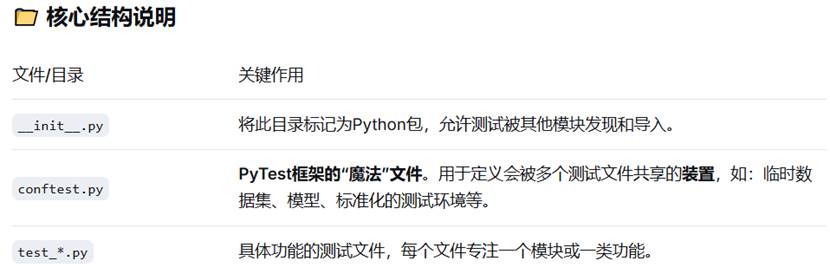
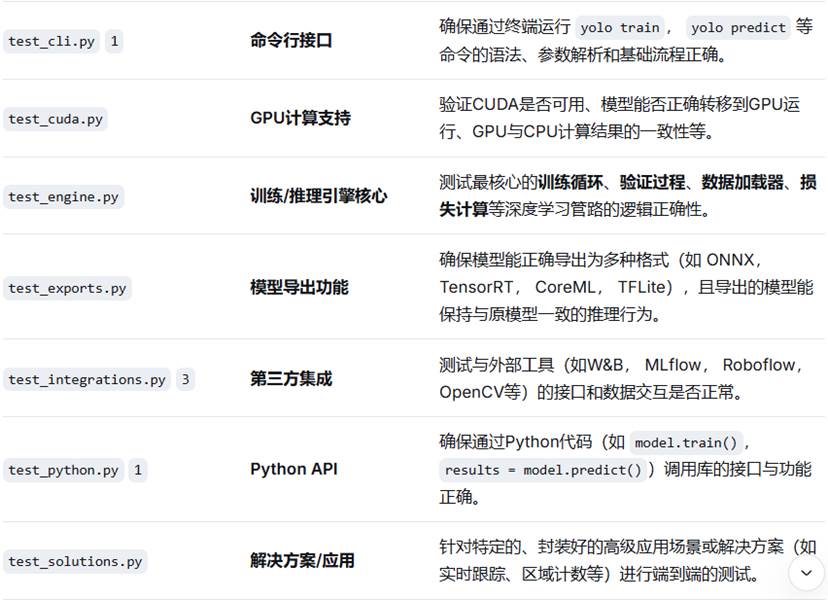
5.runs/train --- 训练过程自动生成的目录,保存训练结果
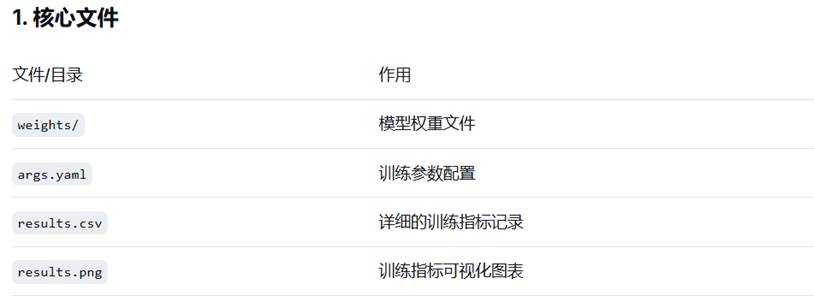



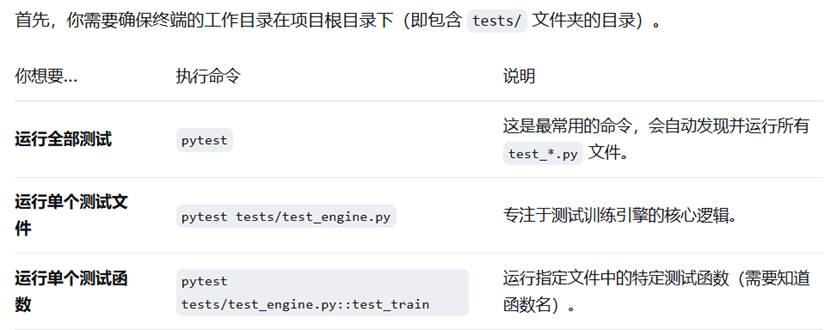
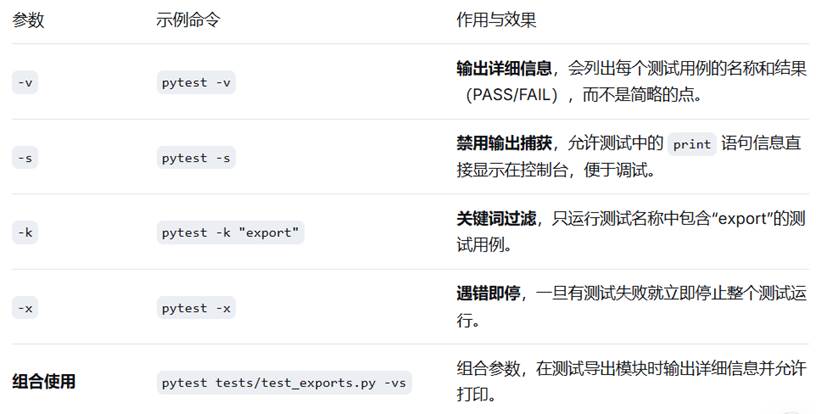
运行命令:
首先,确保当前运行目录是当前文件(cd /d D:\yoloV12\yolov12-main\yolov12-main)
7.Ultralytics --- 深度学习框架的核心源代码目录
一、CFG
cfg 目录是 Ultralytics YOLO 框架的 “中央控制台” 或 “参数集散中心”。它采用声明式的 YAML 配置文件,将所有可调整的参数集中管理,实现了代码与配置的完全分离。这是现代深度学习框架工程化设计的核心体现。
当你在代码中启动任务时,核心引擎会到 cfg 目录中加载并合并相关的配置文件,形成一份完整的指令,然后驱动整个系统运行。


主干网络→颈部网络→头部网络
3.trackers – 多目标追踪

如果在未来要将YOLO从图像检测转换成视频分析的话,导入这个trackers的追踪文件。

4.__init__.py – 命令行调度中心

了解如何使用 Ultralytics 的命令行工具。这是最常用、最高效的使用方式。
二、data
data 模块是 Ultralytics YOLO 框架的 “数据中心与管道工厂”,它负责构建从原始数据到模型可识别张量的完整流程。它的设计非常模块化,每个文件都有其专注的职责。
1.scripts --- 脚本
download_weight ---- 自动下载所有官方 YOLOv8 预训练模型权重的便捷脚本

2.annotator.py --- 自动标注工具
利用你已有的 YOLO 检测模型和 SAM 分割模型,自动为一批图片生成精确的实例分割标注文件。 将自己找到的没有标注的目标图片,利用这个annotator可以帮助我进行自动标注,生成训练时所用的数据集。
第一阶段:自动化标注
- 第一步:将你的所有原始图片放入一个文件夹,例如 my_raw_images/。
- 第二步:编写并运行一个简单的Python脚本,调用 auto_annotate。

- 第三步:等待运行完成。完成后,你会得到 my_auto_labels/ 文件夹,里面包含了所有图片的标注文件。
第二阶段:至关重要的质量控制
这是决定你的模型最终效果的关键一步,绝对不能省略。
- 第四步:必须进行人工抽检。随机打开一些生成后的图片和标签,使用标注查看工具(如LabelImg的YOLO格式模式)检查:
- 检测框是否准确:有没有漏掉物体?有没有把背景误认为物体?
- 分割边缘是否精细:物体的轮廓勾画得是否贴合?尤其是在边缘模糊、复杂的地方。
- 第五步:修正与筛选。
- 对于标注明显错误的图片,删除其标签文件,或者用专业的标注工具(如LabelStudio, CVAT)进行手动修正。
- 将检查后确认合格的图片和标签,按照YOLO要求的目录结构整理好,放入你的正式数据集文件夹(如 datasets/my_custom_dataset/images/ 和 datasets/my_custom_dataset/labels/)。
3.augment --- “数据增强核心库
增强发生在训练循环内部,是模型“看到”数据前的最后一道工序。
default.yaml 文件已经包含了所有训练超参数和数据增强的配置。在新的Ultralytics框架中,原先独立的 hyp.yaml 已经被整合到这个统一的配置文件中了。
4.base.py
这是 Ultralytics YOLO 数据模块的“地基”或“蓝图”。BaseDataset 类是一个抽象基类,它定义了所有YOLO数据集(检测、分割、分类等)都必须遵循的标准数据加载流程和接口。简单来说,它不实现具体任务(如读取某种标签格式),而是搭建了骨架,让子类(如 YOLODataset, ClassificationDataset)去填充血肉。它位于框架数据流的最上游,是数据从硬盘到模型的第一道关口。
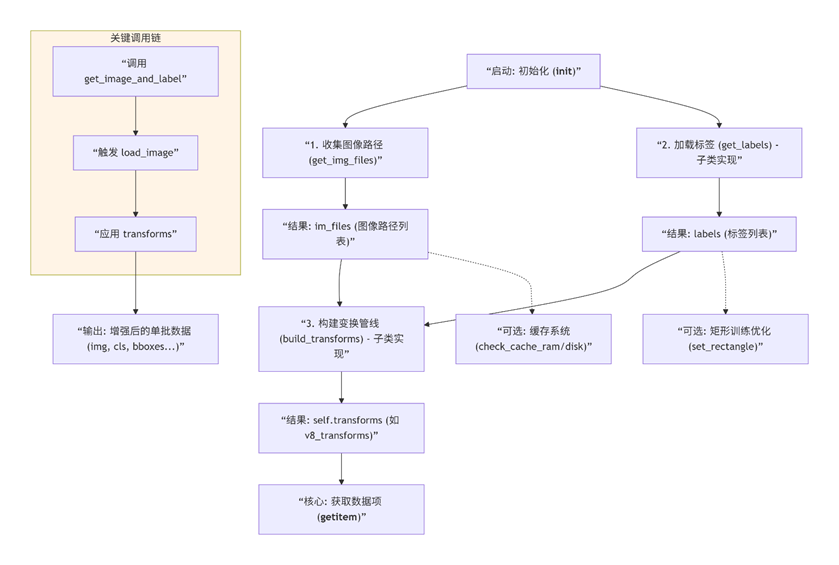
5.build.py
6.converter.py
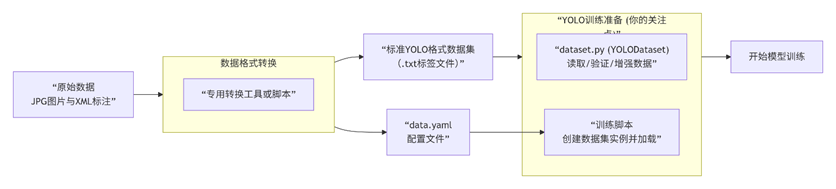
这个文件是Ultralytics YOLO的数据集转换工具,主要用于将不同格式的标注数据转换为YOLO训练所需的格式。这个模块主要设计用于处理COCO、LVIS或DOTA等特定格式,并不直接支持从VOC格式(即XML文件)进行转换。
7.dataset.py
根据你提供的代码文件,这是YOLO训练框架中处理数据集的核心模块 dataset.py。它定义了如何加载、验证和增强YOLO格式的数据,是连接你的标注文件与训练模型的桥梁。
8.loaders.py
loaders.py 是 YOLO 预测流程中的智能数据加载器,能将图片、视频、摄像头等多样化的输入源自动转换为模型可处理的格式,你只需在 model.predict(source='你的输入') 中指定 source 参数即可直接使用。
9.split_dota
这是一个专用于处理遥感影像数据集(DOTA)的工具脚本,用于将超大尺寸的遥感图像及其标注切割成多个适合GPU训练的小图块。
10.utils
这个 utils.py 文件是 YOLO 数据模块的核心工具库,它提供了一系列底层、通用的函数来支撑 dataset.py、loaders.py 等模块的运行。它不负责单一流程,而是为数据集的验证、检查、路径处理、格式转换和自动管理提供基础功能,确保数据从准备到加载的每一步都正确、高效。
三、engine
1.trainer.py
🧠 模型训练的总指挥。它组织整个训练周期:加载数据、前向/反向传播、计算损失、应用优化器、保存检查点、记录日志等。这是你运行 model.train() 时调用的核心。
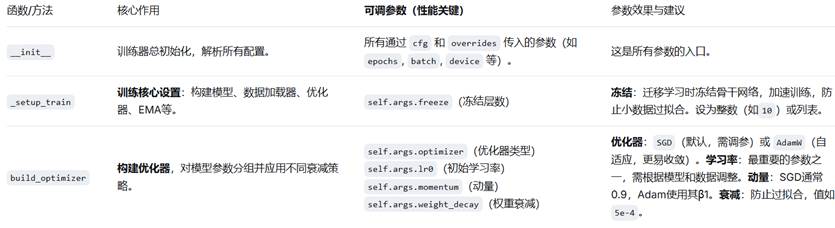


第一梯队:直接影响收敛速度和最终精度的核心参数
学习率 (lr0) 和 优化器 (optimizer)
- 作用:这是最重要的参数。学习率决定了参数更新的步长。
- 如何调:
- 从默认值开始(如YOLOv8的 lr0=0.01)。
- 如果训练损失震荡不降,调小学习率(例如 lr0=0.001)。
- 如果训练损失下降极其缓慢,调大学习率(但需谨慎)。
- 可以尝试将 optimizer 从 SGD 切换到 AdamW,后者对学习率不那么敏感,可能更容易收敛。
批次大小 (batch)
- 作用:影响梯度的估计方差和训练稳定性。更大的批次通常使训练更稳定,并能利用更大的学习率。
- 如何调:在你GPU内存允许的范围内,使用尽可能大的批次。如果内存不足,使用 batch=-1 让 auto_batch 帮你找,或使用 accumulate 参数模拟大批次。
第二梯队:防止过拟合、提升模型鲁棒性的参数
- 数据增强参数(在 hyp.yaml 或通过 args 传入)
- 作用:增加数据多样性,是防止过拟合最有效的手段。
- 关键参数:hsv_h, hsv_s, hsv_v(色彩抖动);degrees(旋转);translate(平移);scale(缩放);shear(剪切);perspective(透视)。
- 如何调:对于小数据集,适度增强(如增加 translate, scale)。对于大数据集或困难样本,可以增强强度。注意别过度,否则模型学不到有效特征。
- 权重衰减 (
weight_decay)- 作用:L2正则化,惩罚大的权重值,迫使模型学习更简单、更泛化的特征。
- 如何调:默认值(如
5e-4)是个好起点。如果模型在训练集上表现很好但在验证集上差(过拟合),尝试增加weight_decay(如1e-3)。
- 模型冻结 (
freeze)- 作用:在迁移学习中,冻结预训练模型的前几层(通常是骨干网络),只训练最后的检测头。
- 如何调:当你的数据集与预训练数据集(如COCO)相似但较小时,冻结可以加快训练并防止过拟合。可以尝试冻结10层、15层等。
第三梯队:高级微调与训练策略
- 学习率调度 (cos_lr, lrf)
- 作用:cos_lr=True 使用余弦退火,通常比线性衰减获得更好的性能。lrf 控制学习率最终下降到多低。
- 如何调:始终启用 cos_lr=True。lrf 可以设为 0.01 或 0.05,意味着学习率最终会降到初始值的1%或5%。
- 预热 (warmup_epochs)
- 作用:让训练初期更稳定。
- 如何调:通常3个epoch的预热足够。如果换了很大的数据集或模型,可以增加到5。
- 早停 (patience)
- 作用:当验证集指标在连续 patience 个epoch没有提升时,自动停止训练,防止过拟合和计算资源浪费。
- 如何调:根据任务设置,例如 patience=50。如果你的训练波动大,可以设大一点。
训练轮数(epochs)和优化器选择(optimizer)应该在 hyp.yaml 文件之外进行设置。它们是更高层级的训练配置,而非超参数。

1. 训练配置(在命令行或Python脚本中直接设置)
这类参数控制训练的宏观行为和资源使用。
- 位置:在启动训练的命令行或Python脚本的 overrides 字典中直接指定。
- 典型参数:
- epochs: 训练总轮数
- optimizer: 优化器类型 (SGD, AdamW, Adam, RMSProp)
- batch: 批次大小
- imgsz: 输入图像尺寸
- device: 指定GPU (0) 或CPU (cpu)
- workers: 数据加载线程数
- project/name: 实验保存的目录和名称
- resume: 是否从检查点恢复训练
- patience: 早停耐心值
- save/save_period: 保存模型策略
- cache: 是否缓存数据 (ram, disk)
2. 训练超参数(在 hyp.yaml 文件中修改)
这类参数是指导模型如何从数据中学习的内在参数,通常与模型收敛、正则化和数据变换的强度相关。
- 位置:在单独的 hyp.yaml 文件中。
- 典型参数:
- lr0: 初始学习率 (依赖于优化器选择)
- lrf: 最终学习率因子
- momentum: 动量
- weight_decay: 权重衰减系数
- warmup_epochs: 学习率预热轮数
- box, cls, dfl: 各种损失的权重
- hsv_h, hsv_s, hsv_v: 色彩空间增强强度
- translate, scale, degrees: 空间增强强度
- mosaic, mixup: 高级增强的概率
3. 任务与模型配置(在 data.yaml 和模型文件中)
这类参数定义了任务是什么和模型的基础结构。
- 位置:
- data.yaml: 定义数据集路径、类别数量和名称。
- yolov8n.yaml: 定义模型网络结构(如果你要修改模型深度、宽度等)。
- yolov8n.pt: 包含预训练权重和模型结构。
标准命令行公式:
yolo mode=train \
model=yolov8n.pt \
data=./path/to/data.yaml \
epochs=100 \
batch=16 \
imgsz=640 \
optimizer=SGD \
lr0=0.01 \
weight_decay=0.0005 \
hyp=./path/to/hyp.yaml \
project=my_project \
name=exp1 \
save=True \
pretrained=True
2.validator.py
BaseValidator 类在训练期间和训练结束后,在验证集或测试集上评估模型的性能,计算并返回 mAP(平均精度均值)、精确率、召回率等关键指标。它不修改模型,只进行公正的评分。
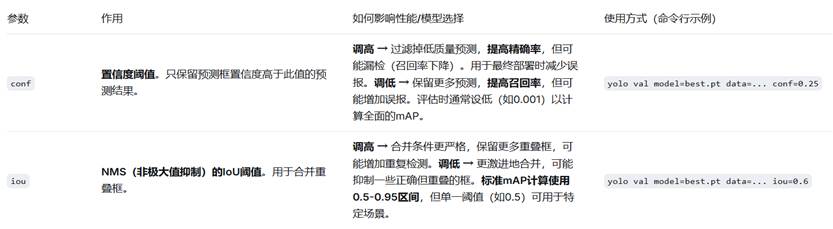

![]()
- 理解指标,而非盲目调参:validator 给出的是诊断报告,而非治疗手段。mAP 低可能是因为召回率低(漏检,调低 conf 或检查数据标注)或精确率低(误检,调高 conf 或增加训练数据)。
- 区分“评估用阈值”和“部署用阈值”:
- 评估时:使用低 conf(如0.001)和标准 iou(0.5-0.95区间),以获得对模型能力的全面、客观评价(这是论文和比较中使用的标准)。
- 部署时:根据应用场景调整 conf 和 iou。例如,安防需要高召回(低conf),而自动驾驶需要高精度(高conf)。
- 利用TTA获取性能上限:在最终模型报告或竞赛中,使用 augment=True 可以测出模型性能的理论上限,但这不适合日常训练验证,因为太慢。
- 验证集是关键:validator 的公正性依赖于验证集的质量和代表性。确保你的验证集与训练集独立且分布一致。
直接在训练命令中附加评估参数。这些参数会应用于每个epoch结束后的自动验证。
# 在训练命令中直接添加评估参数
yolo train \
model=yolov8n.pt \
data=coco8.yaml \
epochs=100 \
# 以下是评估参数 ⬇️
conf=0.001 \ # 验证置信度阈值(计算全面mAP时设低)
iou=0.6 \ # NMS IoU阈值
augment=False \ # 是否使用TTA(训练中通常关闭以节省时间)
half=True \ # 使用FP16半精度加速验证
save_json=False \ # 训练中通常不保存JSON
val_interval=1 # 验证频率(默认每个epoch)
====================================================================
my_yolo_project/
├── train.py # 你的训练脚本
├── your_hyp.yaml # 超参数文件
├── your_data.yaml # 数据集配置文件
├── yolov8n.pt # 预训练模型
└── datasets/ # 你的数据集
====================================================================
3.predictor.py
BasePredictor 的核心任务是打通从原始输入到可视结果的端到端预测流水线。它封装了数据加载、预处理、模型推理、后处理(NMS)、结果可视化和保存等一系列复杂操作,为用户提供了一个极其简洁的调用接口。



- preprocess: 将输入的图像/批次转换为模型所需的标准化张量(调整尺寸、BGR转RGB、归一化、移至设备)。
- inference: 调用模型进行前向传播,可启用 augment (TTA) 和 visualize (特征图可视化)。
- postprocess: 应用非极大值抑制 (NMS),根据 conf 和 iou 阈值过滤和合并预测框。
- stream_inference (核心): 实现了上图中的完整预测流水线,支持流式生成结果,是 __call__ 方法的基础。
- write_results / save_predicted_images: 负责将预测结果(边界框、类别、置信度)绘制到图像上,并保存为图片、视频或文本文件。
predictor.py 是你将训练好的 YOLO 模型投入实际应用的“万能接口”。通过调整其参数,你可以在速度、精度、内存消耗之间取得最佳平衡,满足从服务器端批量处理到嵌入式设备实时流分析等各种场景的需求。记住,实时流必用 stream=True,这是避免程序崩溃的第一法则。
Predictor VS tracker
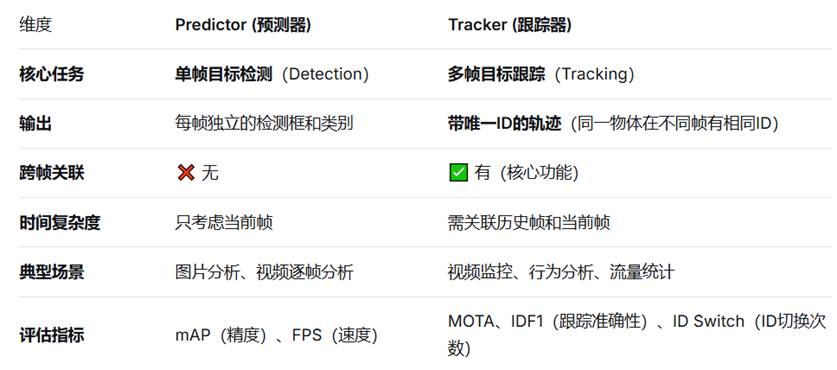
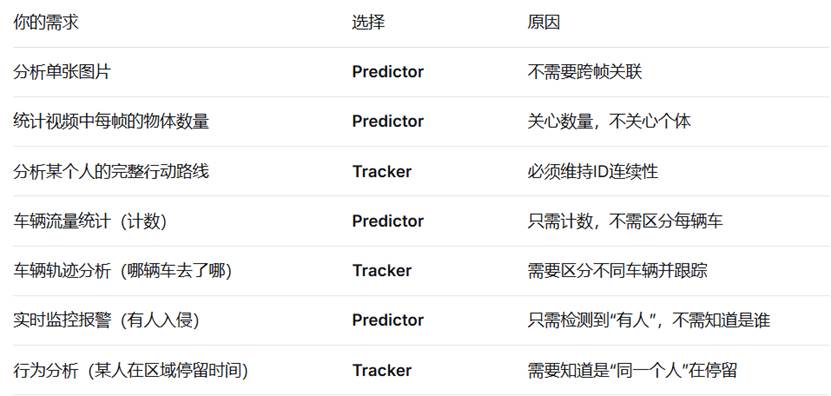
技术关系:Tracker = Predictor + 跨帧关联算法
4.model.py
这个model.py文件是YOLO模型的核心类,定义了YOLO模型的主要接口和行为。
5.exporter.py
这个exporter.py文件是模型格式转换器,负责把训练好的PyTorch模型(.pt文件)转换成其他格式,以便在不同设备上运行。
支持的导出格式:
# 支持的格式(总共17种!)
PyTorch -> .pt # 原始格式
TorchScript -> .torchscript # TorchScript格式
ONNX -> .onnx # 通用格式(Windows/Linux通用)
OpenVINO -> _openvino_model/ # Intel硬件加速
TensorRT -> .engine # NVIDIA GPU加速
CoreML -> .mlpackage # Apple设备(iOS/macOS)
TensorFlow -> _saved_model/ # TensorFlow格式
TensorFlow Lite -> .tflite # 移动设备/嵌入式
TensorFlow Edge TPU -> _edgetpu.tflite # Google Edge TPU
TensorFlow.js -> _web_model/ # 浏览器/Web
PaddlePaddle -> _paddle_model/ # 百度深度学习框架
MNN -> .mnn # 阿里巴巴移动端
NCNN -> _ncnn_model/ # 腾讯移动端
IMX -> _imx_model/ # Sony IMX处理器
可以通过命令行调用。
选择策略:
- 服务器部署 → TensorRT/ONNX + FP16
- Windows应用 → ONNX + CPU推理
- iOS/Android → CoreML/TFLite + INT8
- Web浏览器 → TensorFlow.js/ONNX.js
- 边缘设备 → TFLite/OpenVINO + INT8
6.results.py
这个results.py文件是推理结果的"数据包装器"和"可视化工具"。一句话总结:把YOLO的推理结果(框、掩码、关键点等)打包成标准格式,并提供可视化和导出功能。(推理结果是由predictor模块生成,然后由results.py进行包装和处理的。)
# 3. 导出结构化数据
df = result.to_df() # 转Pandas DataFrame
json_str = result.to_json() # 转JSON
csv_str = result.to_csv() # 转CSV
xml_str = result.to_xml() # 转XML
7.tuner.py
这个tuner.py文件是YOLO的"自动调参助手",用于自动搜索最优的超参数组合。一句话总结:自动寻找最佳训练参数,不用你手动试错!
运行tuner后,它会生成一个文件保存最优超参数,而不会自动替换你原来的超参数。
生成的文件结构:
runs/detect/tune/ # 调优目录(默认)
├── best_hyperparameters.yaml # ✅ 这是最重要的文件!
├── tune_results.csv # 所有调优结果的CSV文件
├── weights/ # 最佳权重文件
│ ├── best.pt # 最佳模型的权重
│ └── last.pt # 最后迭代的权重
├── tune.png # 调优过程图表
└── args.yaml # 调优的配置参数
四、hub
1.auth.py
auth.py 处理认证(身份验证)
2.session.py
session.py 处理会话管理(保持登录状态、处理请求等)
3.utils.py
这个 utils.py 模块是整个 Ultralytics HUB 客户端的基础设施,提供了网络通信、环境适配、数据收集等核心能力,支持上层功能模块(如 auth.py、session.py)的运作。
五、models
1.YOLO
1. detect/ - 目标检测 ✅ 最核心模块
- 功能:传统的边界框检测
- 输出:[x, y, w, h, confidence, class]
- 应用:物体识别、计数、跟踪等
2. segment/ - 实例分割
- 功能:检测+像素级分割
- 输出:边界框 + 分割掩码
- 应用:图像编辑、自动驾驶、医学图像
3. pose/ - 关键点检测
- 功能:人体姿态估计
- 输出:17个人体关键点
- 应用:动作识别、体育分析、人机交互
4. classify/ - 图像分类
- 功能:图像级别分类
- 输出:图像类别概率
- 应用:图像检索、内容过滤
5. obb/ - 旋转框检测
- 功能:带角度的边界框检测
- 输出:[x, y, w, h, angle, confidence, class]
- 应用:遥感图像、文本检测、工业检测
6. world/ - YOLO-World 🌍 最新特性
- 功能:开放词汇目标检测
- 特点:无需重新训练即可检测新类别
- 应用:自定义类别检测、零样本学习
选择建议:
- 只需要框 → detect/
- 需要像素级精度 → segment/
- 人体动作分析 → pose/
- 文字、遥感检测 → obb/
- 未知类别检测 → world/
命令行调用的 train 命令最终就是通过 detect/train.py 中的 DetectionTrainer 执行的,而 DetectionTrainer 又继承了 engine/trainer.py 中的 BaseTrainer,形成了完整的训练体系。
你的脚本 (train.py)
↓
YOLO类 (高级API)
↓
检测模型 → YOLO类内部根据模型类型选择 → DetectionTrainer
↓ ↓
开始训练 ←---------------------------------- 调用 train() 方法
何时用你的脚本?
✅ 快速实验:想测试不同参数组合
✅ 生产部署:需要稳定、简单的API
✅ 团队协作:提供清晰的配置接口
✅ 教学示例:展示如何使用YOLO
何时需要直接使用detect/train.py?
✅ 研究新算法:实现新的损失函数
✅ 定制训练流程:特殊的训练策略
✅ 集成新任务:添加非标准任务
✅ 性能优化:需要微调底层实现
2.rtdetr --- (Real-Time Detection Transformer)的训练器
class RTDETRTrainer(DetectionTrainer): # ← 继承自 DetectionTrainer
- 父类: DetectionTrainer (来自 yolo/detect/train.py)
- 意义: RT-DETR 共享目标检测的基础训练逻辑,但有自己的特殊实现
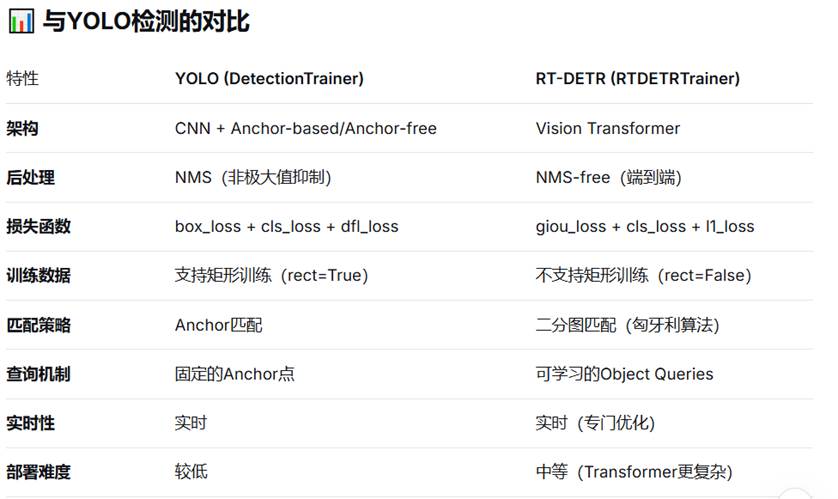
“RT-DETR不接受矩形训练”指的是它不能像YOLOv5/YOLOv8等那样,在同一个训练批次(batch)中直接处理长宽比不同、经过“保持原比例+填充黑边”的图片。RT-DETR要求一个批次内的所有输入图像必须具有完全相同的尺寸(Height x Width),通常是正方形。
3.sam --- Segment anything model
sam/
├── amg.py # 自动掩码生成算法
├── build.py # 模型构建工具
├── model.py # 模型定义
├── predict.py # 预测推理
└── modules/ # 子模块组件
Segment Anything Model (SAM) 是 Meta 发布的 通用图像分割模型,具有以下革命性特点:
核心优势:
- 🔍 零样本分割 - 无需训练即可分割新类别
- 🎯 提示驱动 - 支持点、框、掩码等多种提示
- 🌍 通用性强 - 适用于各种场景和对象类型
- ⚡ 高效交互 - 支持实时交互式分割
将YOLO和SAM结合:
输入图像
↓
YOLO检测 → 得到边界框和类别
↓ ↓
SAM精细分割 类别信息
↓ ↓
精细掩码 + 类别标签
↓
精确裁剪/分析/处理
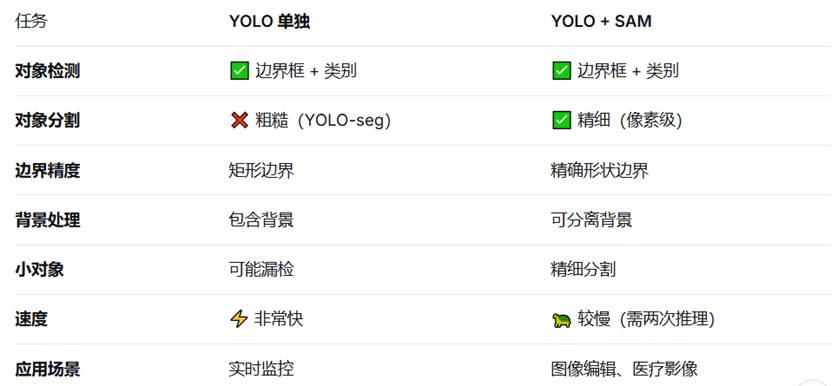
YOLO ---segment VS sam
关键区别表格:
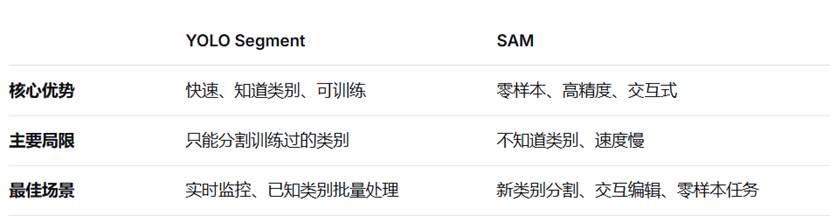
最终建议:
- 日常应用 → 用 YOLO Segment(实用、快速)
- 研究/新领域 → 用 SAM(灵活、强大)
- 生产系统 → 两者结合(YOLO检测类别 + SAM精细分割)
两者不是竞争对手,而是互补工具,根据具体需求选择合适的工具,或者结合使用达到最佳效果!
4.fastsam --- Fast Segment Anything Model
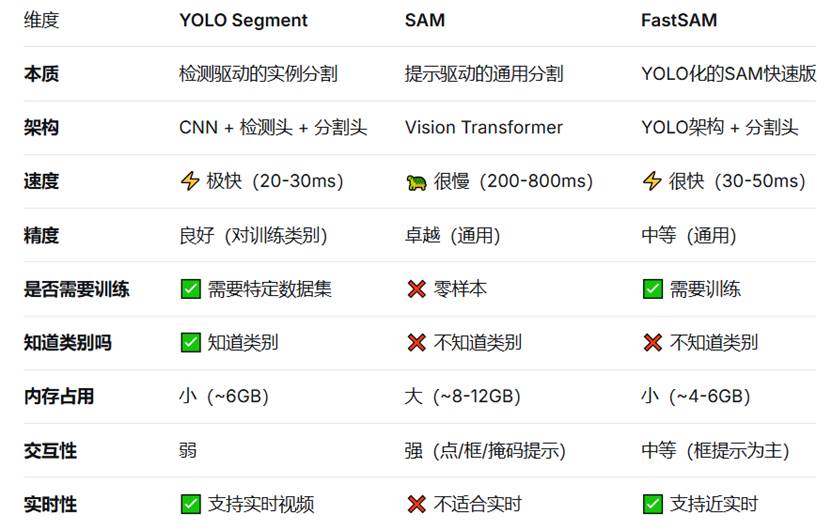
5.nas --- 神经架构搜索
- NAS:来自 Deci.ai 的 Neural Architecture Search 模型
- NAS:通过 super_gradients 库或 .pt 文件
- NAS:需要特定的格式转换(xyxy2xywh)
NAS 模块和 YOLO 的 detect 模块作用完全相同,都是执行目标检测任务,只是使用了不同的模型架构。
6.utils --- 模型工具库
这是 Ultralytics 框架中用于 RT-DETR(Real-Time DEtection TRansformer)模型的专用工具模块。RT-DETR 是一种基于 Transformer 的目标检测模型,这些代码实现了其核心的训练和匹配机制。
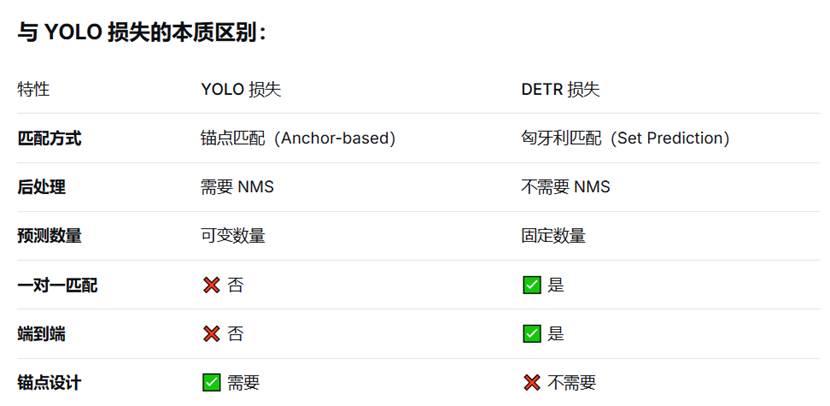
NMS --- 非极大值抑制( 是目标检测中常用的一种后处理算法,主要用于去除多余的候选框,保留最优的检测框。其核心目的是确保每个目标只被检测一次,避免多个重叠的边界框表示同一个目标。)
六、nn
1.activation
AGLU 是一个先进的可学习激活函数,其主要特点是:
- 完全可学习:有两个可训练参数(λ 和 κ)
- 自适应形状:可以根据数据调整激活函数形状
- 数学表达式复杂:结合了指数、Softplus和对数运算
- 实验性质:可能在特定任务上表现优异
2.block
block.py 是 Ultralytics 框架的神经网络构建块宝库,包含了:
- 经典模块:Bottleneck、C3、SPPF 等
- 现代模块:C2f、注意力机制、Transformer
- 优化模块:Ghost、Reparameterization、CIB
- 任务模块:DFL、Proto、对比学习头
3.conv
conv.py 模块是 Ultralytics 框架的卷积操作工具箱,
核心特点:
- 完整的卷积家族:标准卷积、深度可分离卷积、Ghost卷积等
- 高效操作:Focus、重参数化等优化技术
- 注意力机制:CBAM等提升特征提取能力
- 自动优化:自动填充、激活函数配置等

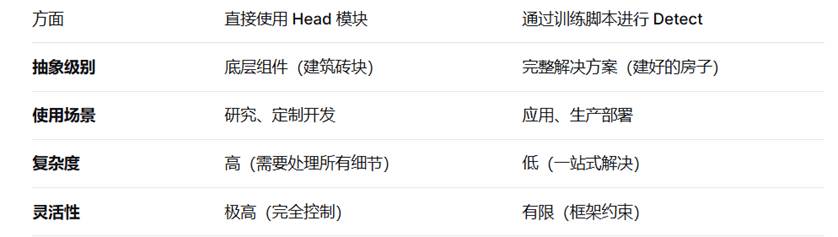
4.head.py
这是 Ultralytics 框架中的模型头模块,包含了各种任务专用的输出头。这些头是模型架构的最后部分,负责将特征转换为具体的预测结果。
Ultralytics 的 Head 模块是模型架构的重要组成部分,通常不需要直接使用,而是通过构建完整模型间接使用。
5.Transformer.py
这是 Ultralytics 框架中的 Transformer 模块,包含了各种基于注意力机制的神经网络组件。这些模块为现代目标检测模型提供了强大的长距离依赖建模能力。
核心价值:
- 现代注意力机制:标准Transformer、可变形注意力、多尺度处理
- 高效实现:优化的CUDA内核、内存管理
- 易于集成:与现有CNN架构无缝结合
- 研究前沿:集成了最新的Transformer变体
实际应用:
- 提升小目标检测:通过全局上下文信息
- 改善遮挡处理:通过可变形注意力聚焦关键区域
- 加速收敛:Transformer的并行计算特性
- 多模态融合:支持文本、图像等多模态输入
6.utils.py
这是 Ultralytics 框架中的 Transformer 工具模块,提供了一些关键的辅助函数,主要用于支持可变形注意力机制和模型初始化。
7.autobackend
这是 Ultralytics 框架中的 自动后端模块,这是一个极其强大和重要的组件。它实现了多格式模型自动加载和推理的功能,是 Ultralytics 框架能够无缝支持多种模型格式的核心所在!AutoBackend让你用一行代码加载任何格式的YOLO模型,无需关心底层实现,自动获得最优推理性能。
Autobackend模块 VS Export模块
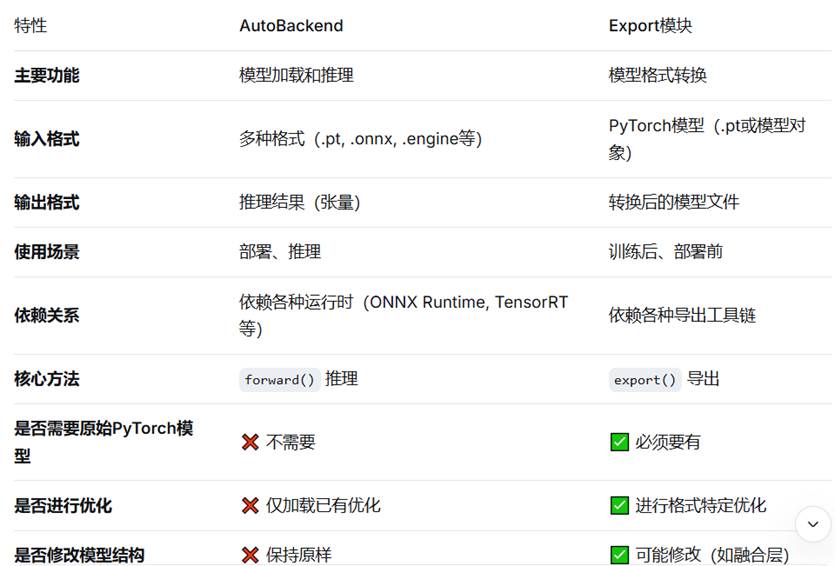
- Export模块:关注如何正确转换模型,保持精度,优化性能
- AutoBackend模块:关注如何高效加载和运行不同格式的模型
Export 模块的设计哲学:
- 一次性转换:训练后进行一次转换,后续直接使用
- 格式优化:针对每种格式进行专门的优化
- 元数据完整性:确保转换后的模型包含所有必要信息
AutoBackend 模块的设计哲学:
- 运行时适配:在运行时动态适配不同格式
- 接口统一:无论什么格式,提供统一的API
- 性能优化:针对不同设备进行运行时优化
AutoBackend推理输出的是"加密"的原始张量,你需要"解密"(后处理)才能得到真正的检测框。YOLO Model则帮你完成了所有的"解密"工作。
8.tasks

七、solutions


八、trackers
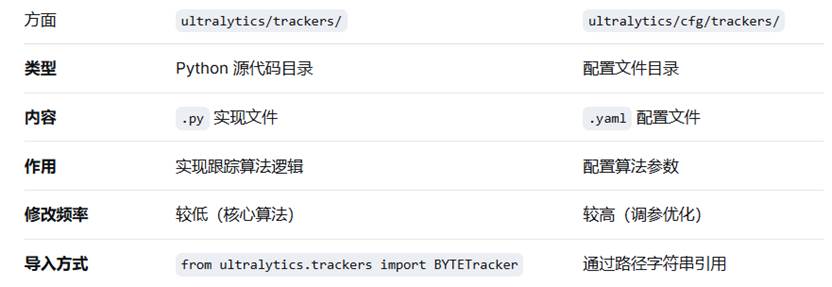
- ultralytics/trackers/ 是算法实现,包含跟踪的核心逻辑和代码
- ultralytics/cfg/trackers/ 是参数配置,包含不同场景下的调优参数
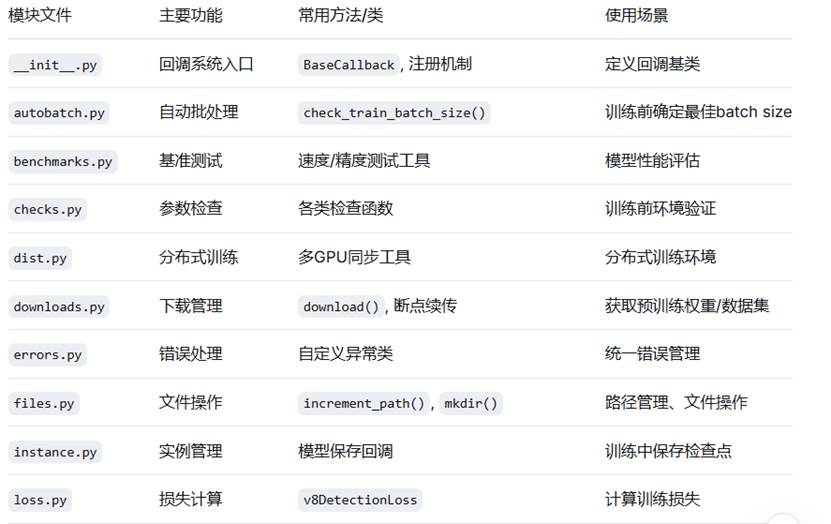
九、utils
┌─────────────────────────────────────────────────────────┐
│ utils 工具模块系统 │
├─────────────────────────────────────────────────────────┤
│ 核心功能 │
│ ├── 回调管理 (callbacks) ── 生命周期事件处理 │
│ ├── 图像操作 (ops) ── 张量/边界框转换 │
│ ├── 可视化工具 (plotting) ── 检测框/曲线绘制 │
│ ├── 评估指标 (metrics) ── mAP/精度/召回率计算 │
│ └── 损失函数 (loss) ── 多任务损失计算 │
│ │
│ 训练优化 │
│ ├── 自动批处理 (autobatch) ── 最佳batch size寻找 │
│ ├── 超参数调优 (tuner) ── 贝叶斯/网格搜索 │
│ ├── 分布式训练 (dist) ── 多GPU/多节点支持 │
│ └── TAL策略 (tal) ── 标签分配优化 │
│ │
│ 文件管理 │
│ ├── 文件操作 (files) ── 路径/目录管理 │
│ ├── 下载工具 (downloads) ── 模型/数据集下载 │
│ └── 检查验证 (checks) ── 环境/参数验证 │
└─────────────────────────────────────────────────────────┘


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)