解决LLM RL训练不匹配:详解训练-推理误差与稳定策略优化方法!
本文探讨了大模型强化学习中的训练-推理不匹配问题及稳定性提升方法。分析了数值实现差异导致的策略分布不一致,以及MoE模型中的专家不一致问题。提出了多种解决方案:包括重要性采样校正、截断技术、路由回放和学习率调度等。实验表明,SAPO等算法能有效提高训练稳定性,解决训推误差问题,为大模型强化学习提供了稳定训练的有效途径。
最近有一系列 paper 和 blog 讨论了 training–inference mismatch(训推误差) 以及由此带来的 LLM RL 稳定性问题。这里做一个简要整理和分享。
一、Preliminary
1.1 Training-Inference Mismatch
在标准的策略梯度框架下,我们希望优化如下目标:
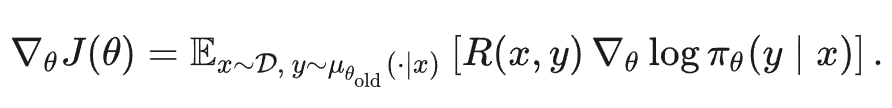
这里存在一个不一致性:动作序列 y 是从策略 μ 中采样得到的,而梯度更新却是基于 π 的 log-prob 来计算的。
在 LLM RL 中,一方面,rollout 通常由高吞吐的推理引擎(如vLLM/sgLang)完成;另一方面,参数更新则发生在训练引擎(如 FSDP/Megatron)中。
即便共享相同的模型参数,由于数值实现、精度以及算子差异,二者对应的策略分布在 token-level 上并不一致。
一个最直接的修正方式是引入 Importance Sampling (IS) correction,将 off-policy 采样重新加权为对目标策略的无偏估计:
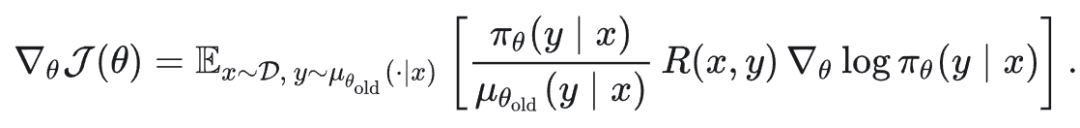
1.2 MoE RL
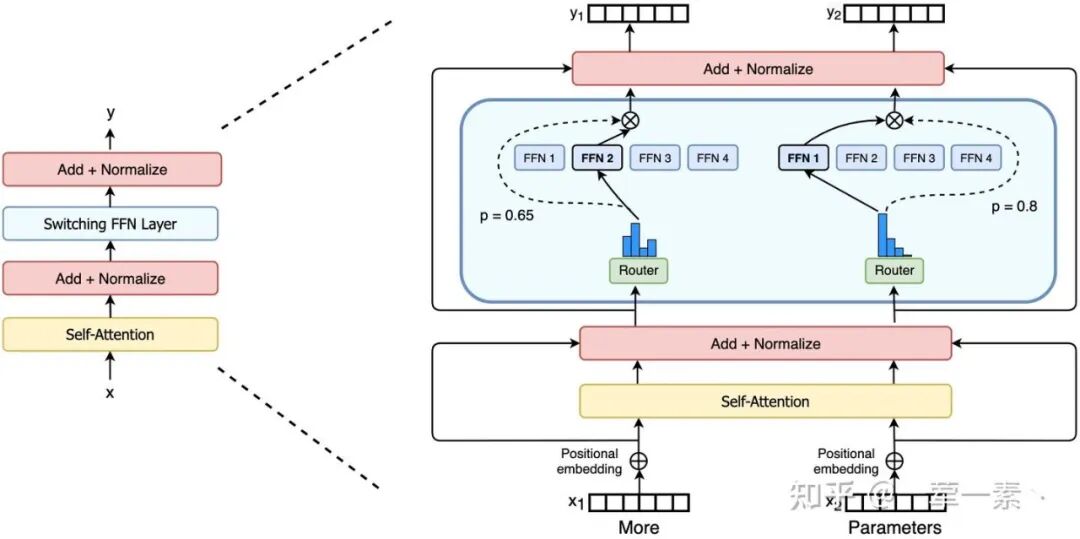
Mixture-of-Experts(MoE)模型通过门控(routing)机制,为每一个 token 动态选择一小部分专家(experts)参与计算,从而在保持计算成本可控的同时显著提升模型容量 [1]。
在 MoE 结构中,每个 token 由一个 router 根据当前隐状态,选择 Top-k 个专家并进行加权计算。
Expert Inconsistency
在 MoE RL 中,training–inference mismatch 不仅体现在概率数值上的偏差,还会直接导致在训练引擎与推理引擎中,对同一输入、同一模型参数,路由到的专家集合不一致。
与此同时,从训练效率角度考虑,模型会先以 global batch size 为单位,从当前策略中采样一大批完整的响应序列 rollout,随后再将这些样本拆分成多个 mini-batches,用于多次梯度更新。
新旧策略在相同时间步可能激活不同的专家(policy staleness)。
二、How to Stabilize RL?
Pradigm: Sequence Reward and Token Optimization
在 LLM RL 中,奖励通常是一个 scalar reward,它作用于整条 response(sequence)上,而不是某一个单独的 token。
“理想情况”下,目标函数应当是 sequence-level 的:
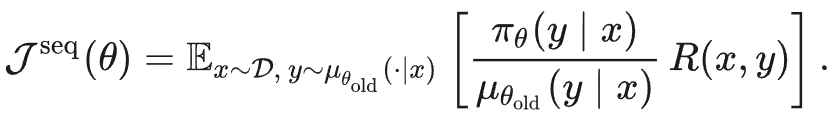
然而,由于序列级似然的数值范围极大,且由此带来的梯度估计具有极高的方差,Sequence-level Objective很难优化。
LLM RL 算法通常采用 Token-level Objective:
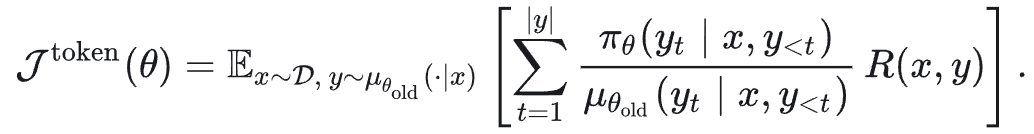

2.1 Importance Sampling
Truncated IS [2]
在引入 § 1.1 提到的 IS correction 的同时,将其限制在一个合理范围内,如 C 的取值为 5:
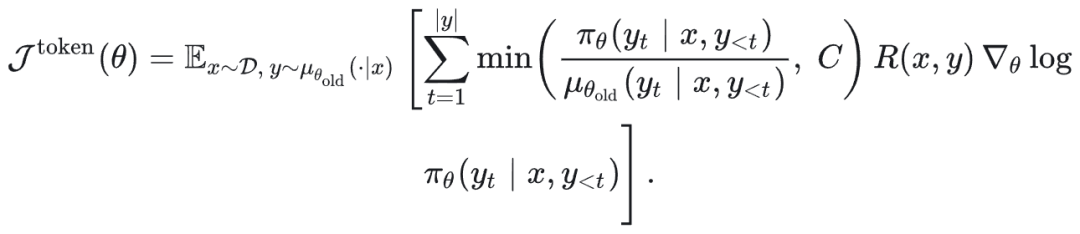
这里,C 的引入是为了偏差-方差权衡(Bias-Variance Tradeoff):

当两个分布 gap 很大(INT8, FP8)时,w/o C(图里的 vanilla-IS)不能稳定训练.
GSPO [3]
前面我们提到,token-level 的重要性加权是逐 token 独立进行的,而奖励却是赋给整条序列的。
GSPO 的核心思想是:将 IS 定义在整个响应序列(sequence)级别,而不是单个 token 的概率,与奖励粒度对齐。
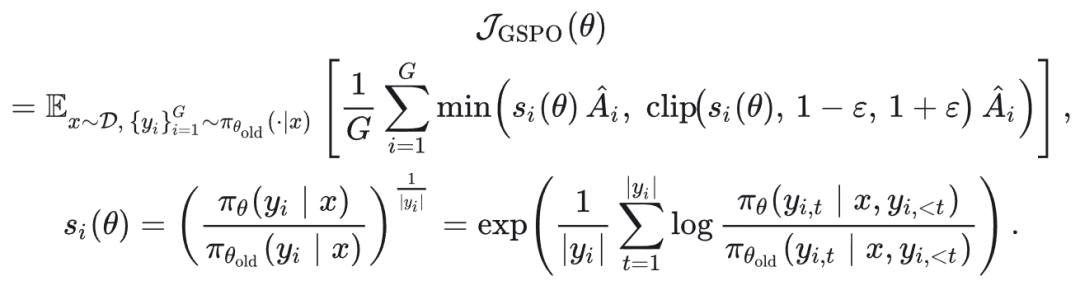
GRPO 中 token 级的不均匀缩放会累积,影响训练稳定性;GSPO 则均匀缩放一个 sequence 中的所有 tokens。
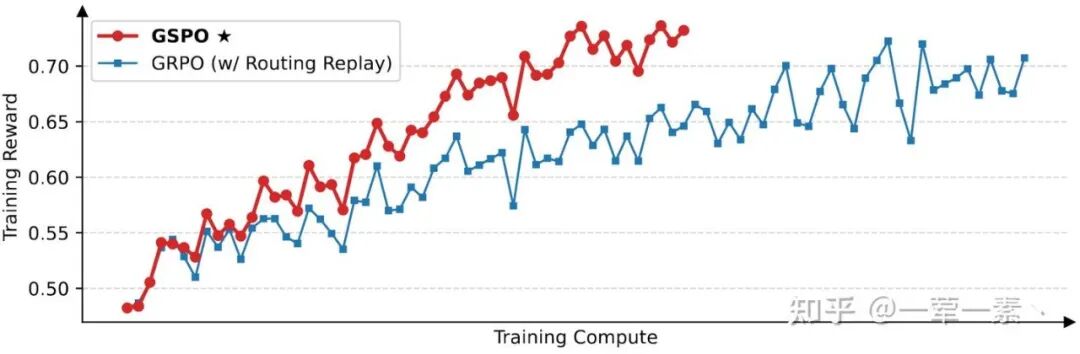
Qwen3-30B-A3B,这里 GSPO 相比 GRPO 的效果更好.
这里我们可以详细讨论一下两个算法中 token 的 log-likelihood 梯度如何加权?

2.2 Clipping
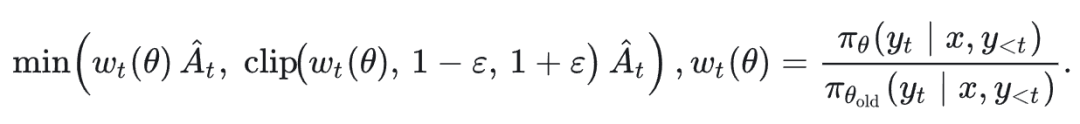
Clipping 的核心思想是:直接限制新策略相对于旧策略的偏离幅度,从而对策略更新施加一种显式的约束。
当新旧策略在某个 token 上的概率比超过阈值区间 【1-𝜖,1+𝜖】,对应的梯度会被直接置 0,从而抑制由 policy staleness 带来的不稳定更新。
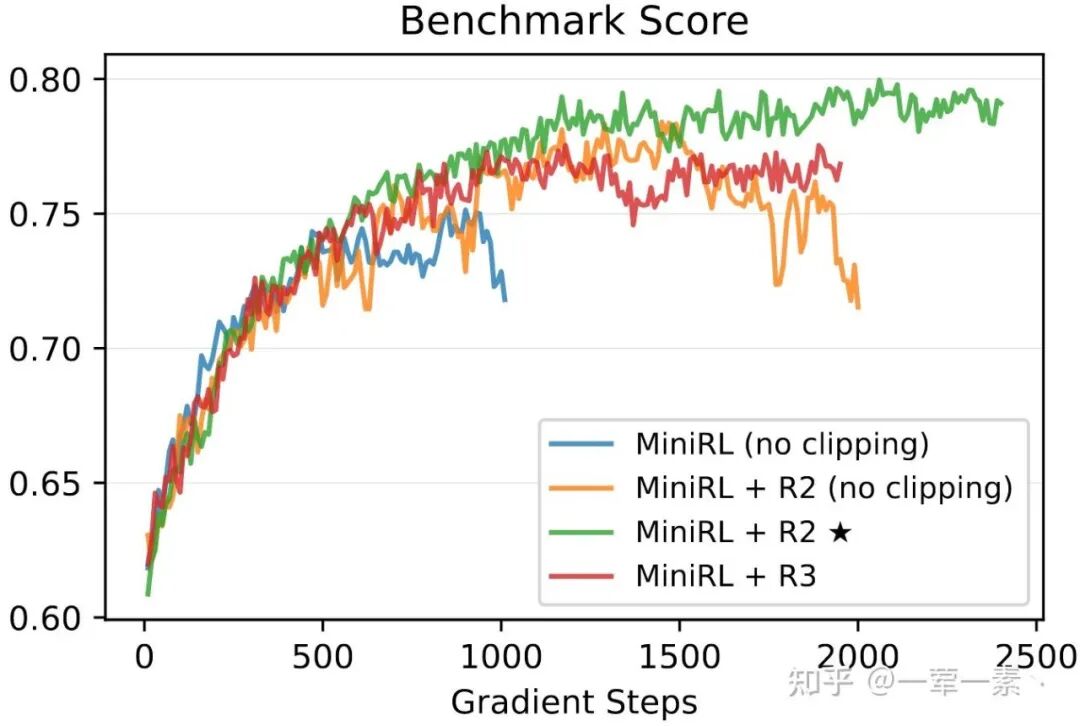
Off-policy setting 下,clipping 是必要的.
SAPO [4]
SAPO 指出 Hard Clipping 会有以下问题(下文中,ratio 表述由前文 w_t 转化为 r_i,t):
- r_i,t 超出 【1-𝜖,1+𝜖】的范围时,梯度直接置 0,有效样本数减少;
- 放宽 𝜖 的范围,虽然保留了更多样本,但引入了更多 off-policy 的噪声梯度。
相比硬截断 Hard Clipping,SAPO 的核心思想是:在偏离策略时平滑衰减梯度而非直接置 0。
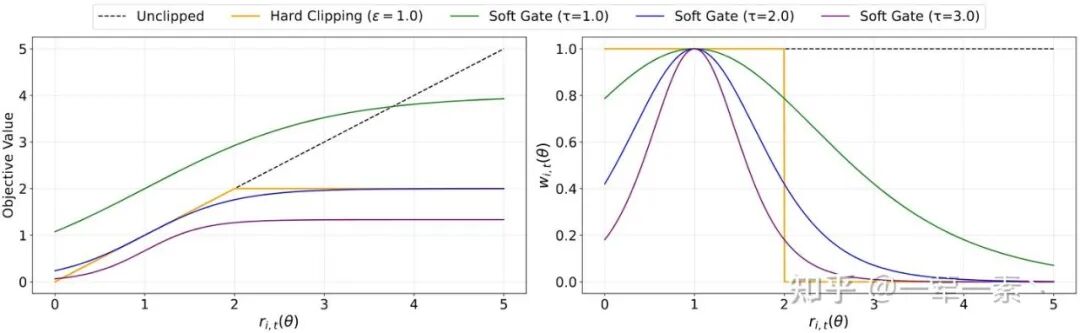
正 advantage 下的策略更新目标对比;Surrogate Objective 与梯度权重随 ratio 的变化.
这里权重函数 w_i,t 是一个以 r_i,t=1 为中心的钟形曲线:
- 当 r_i,t ≈ 1 时(on-policy),w_i,t ≈ 1,梯度保持原样;
- 当 r_i,t 偏离 1 时,w_i,t 呈指数级衰减。
换言之,SAPO 不会在某一个阈值突然切断梯度,而是根据偏离程度降低权重。
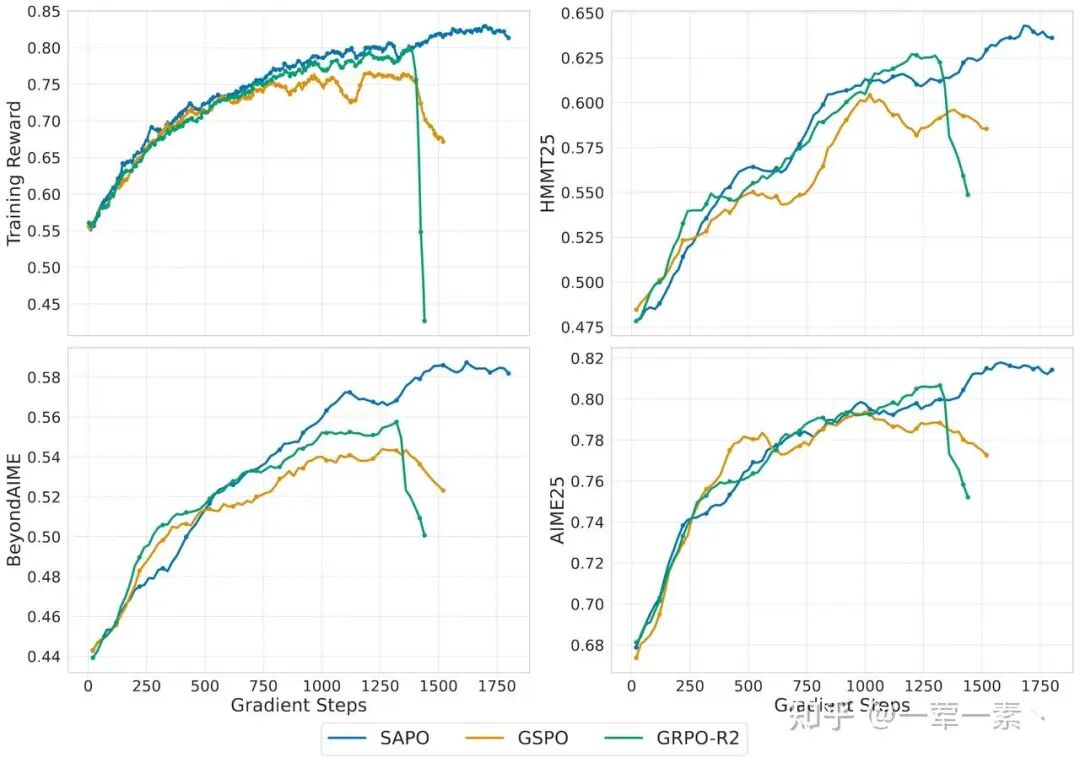
Qwen3-30B-A3B;相比 hard clipping 的 GRPO/GSPO,SAPO 的稳定性、最终性能更好.
2.3 Routing Replay for MoE Models
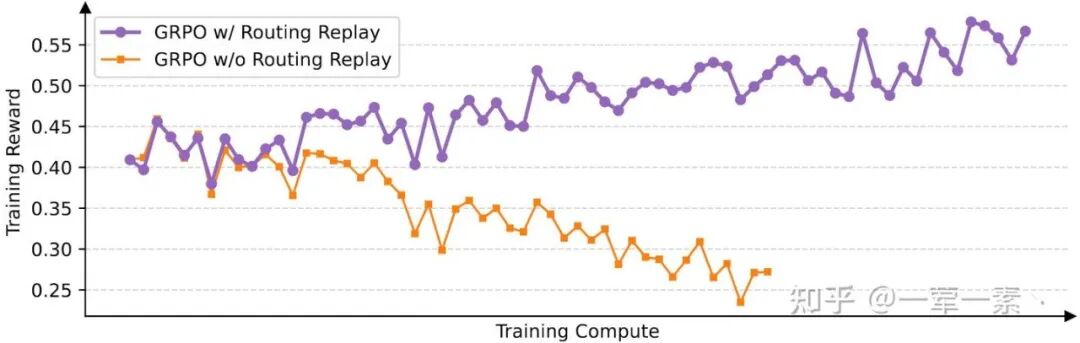
Routing Replay 在 MoE RL 的必要性.
Routing Replay 通过在策略优化阶段固定专家路由,使 MoE 在 RL 训练中等价为一个 dense 模型进行优化:

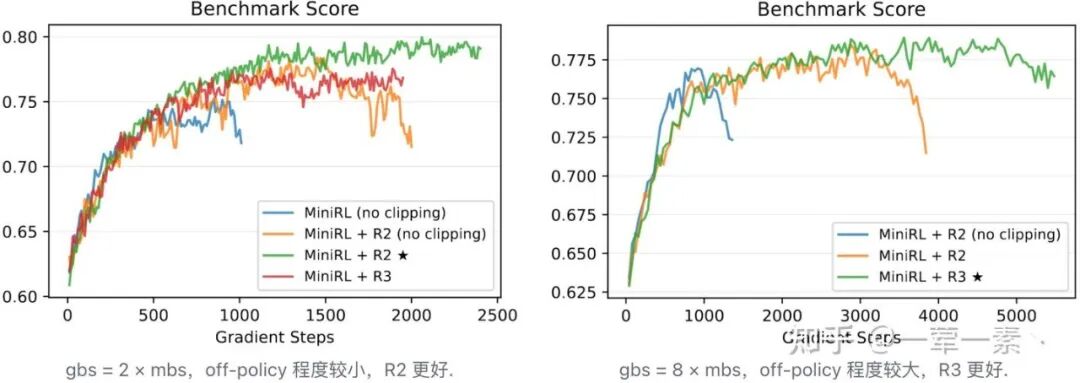
2.4 Others: Learning Rate
还有工作从另外一些维度探讨了 training-inference mismatch 和 LLM RL 稳定性。
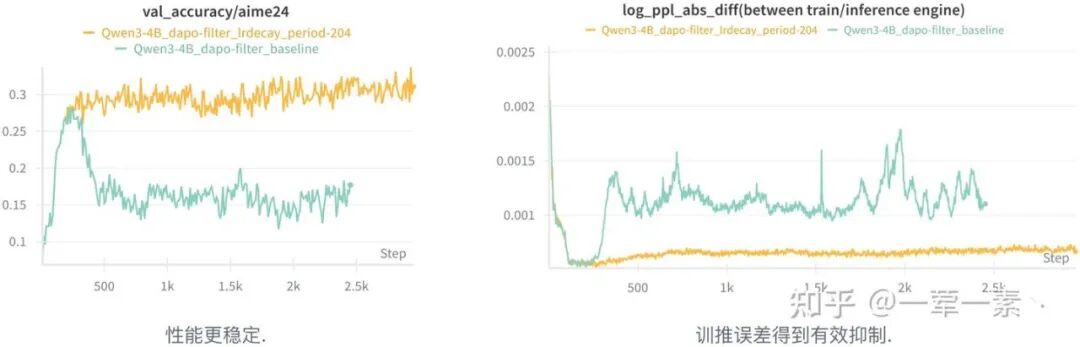
LR Scheduler [5]
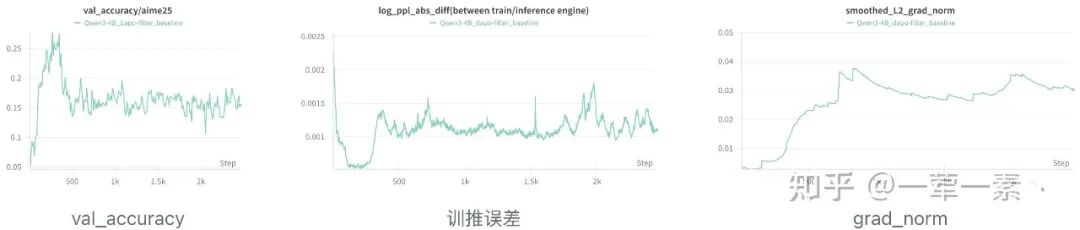
随着训练进行(300-400 steps),能观察到性能 ↓,训推误差 ↑,梯度范数 ↑:
- 数据中的有效学习信号逐渐减弱,而梯度 L2 范数却持续上升,说明更新方向被噪声主导;
- 梯度噪声与训推误差同步加剧,说明 training-inference mismatch 不仅是静态数值误差,还是动态的模型优化问题。
Possible Explanations:训练后期由噪声主导的优化过程会将模型引导至高曲率参数区域,从而放大数值层面的微小差异。
一个符合直觉的想法是:降低学习率 η 可以减弱梯度噪声带来的影响 -> 该怎么设置 LR Scheduler?
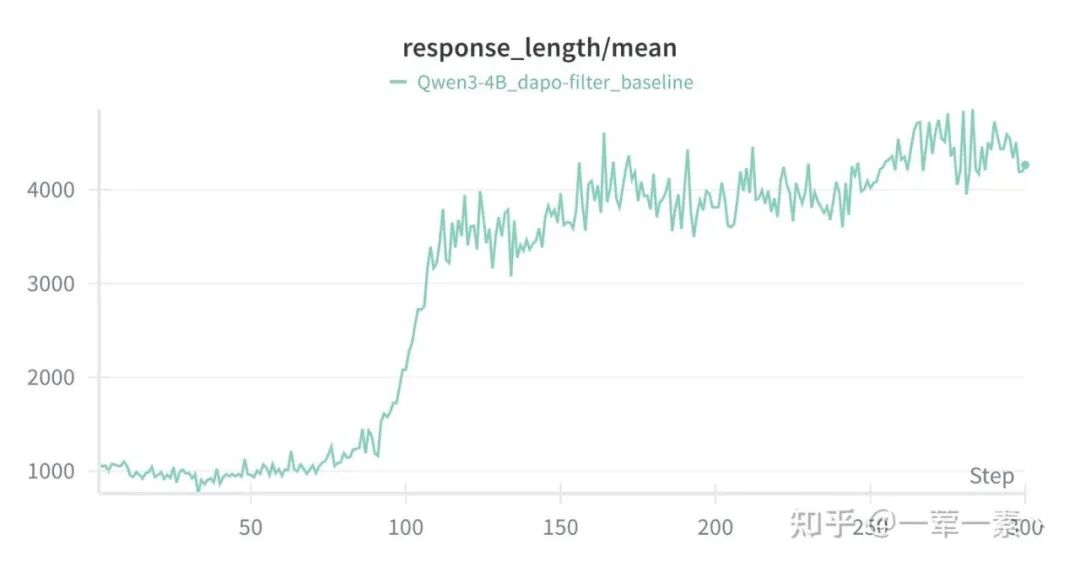
response length 的激增(75~175 step)先于训练不稳定的出现(性能 ↓,训推误差 ↑);
blog 作者推测 longer trajectories 导致梯度方差显著上升,从而带来梯度噪声;
设定一个 decay_period(如 lenth 激增结束),每经过一个周期将学习率减半,直到降至预设下限。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献431条内容
已为社区贡献431条内容

所有评论(0)