关于深度学习的计算机考研复试项目(四)
一次性把所有数据给模型训练方向很好,但是仅训练这一次虽然参数预测的方向没什么问题,但是参数的大小可能会出问题,因为仅一次训练模型不知道该一次修改参数多少。处理训练集时之前要加model.train()这个函数,具体原理不用关心,只需要知道这是个固定流程,作用是让模型会计算梯度,更新参数。丢入数据,梯度回传更新参数....丢入数据,梯度回传更新参数....丢入数据,梯度回传更新参数....一个一个训
其实(三)里面的函数模拟小项目还是有很多难以理解的地方,不仅仅是代码的意思,还有整个流程也比较模糊,那么我们这一节再次深入探讨这类简单的深度学习项目
深度学习项目的基本系统实现流程:
处理数据——>定义模型,输入x获得预测值y^——>回归损失函数loss,反求更合适的模型参数使得loss更小。经过多次迭代最终获得比较好的模型。
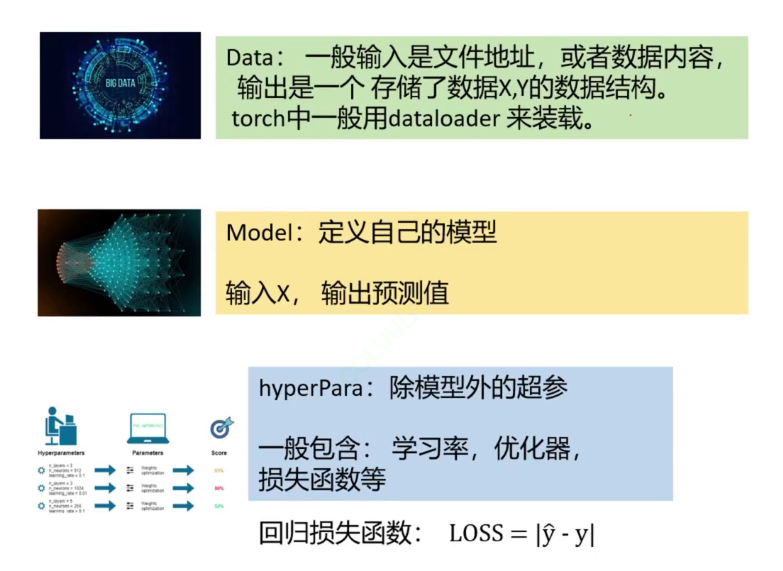
三大步骤里面其实最麻烦的是数据部分
关于数据部分,现在流行的是将数据集划分为三大模块:
1.训练集
2.测试集
3.验证集(本质是从训练集中拆出来一小部分)
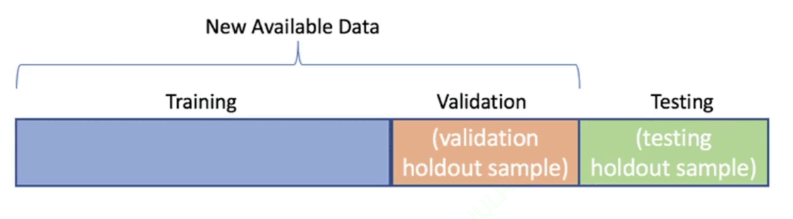
训练集和测试集容易理解,说说验证集
验证集是不经过训练的,模型看不见。则主要作用是检测经过训练后的模型效果如何(说白了就是交答案之前检查一遍)
取数据
我们数据集有一堆数据,那么应该一次性把所有数据给模型训练,还是一个一个训练呢?还是别的拆分方法?
一次性把所有数据给模型训练方向很好,但是仅训练这一次虽然参数预测的方向没什么问题,但是参数的大小可能会出问题,因为仅一次训练模型不知道该一次修改参数多少
一个一个训练会偏离我们的实际方向,实际问题中存在的大量的噪声,噪声会影响我们参数的预测方向。
上述两种方法都有问题,那么我们取数据应该分批次,比如一批次有十六组数据(和上一节一样)
一个批次(batch),批次大小(batchsize)
那么我们一个迭代周期内模型训练可以概括为:
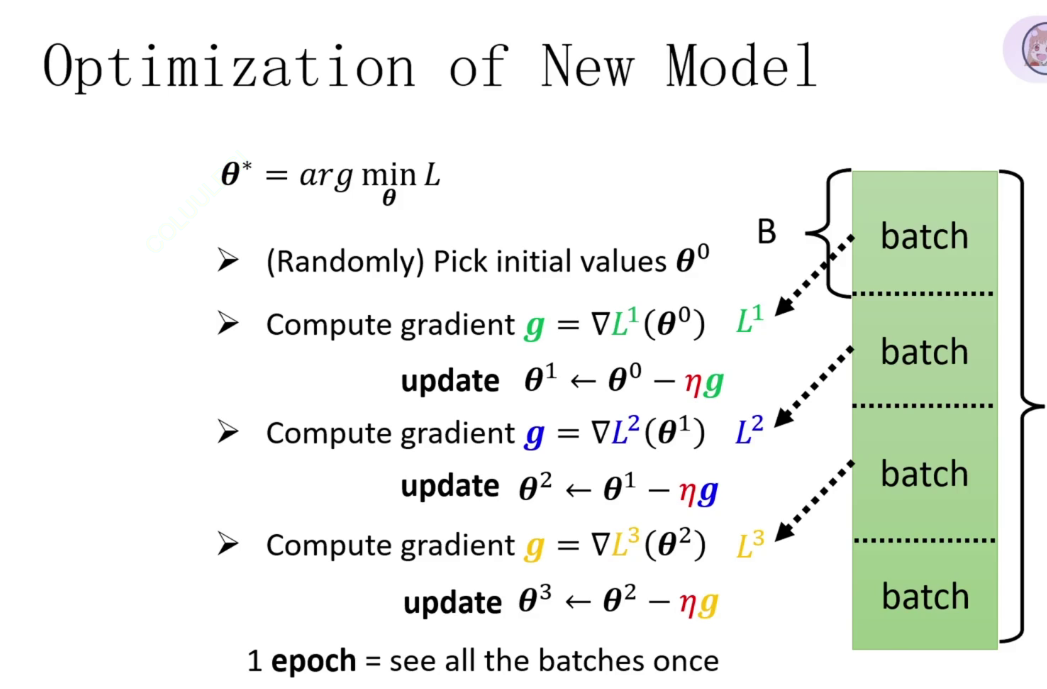 丢入数据,梯度回传更新参数....丢入数据,梯度回传更新参数....丢入数据,梯度回传更新参数....
丢入数据,梯度回传更新参数....丢入数据,梯度回传更新参数....丢入数据,梯度回传更新参数....
循环往复,注意一次迭代是要包含所有数据,不是一批次数据一次迭代
这就叫SGD随机梯度下降算法
那么又复习了一下训练流程之后,我们开始下一步的实操!
基于线性回归的新冠病毒感染人数预测
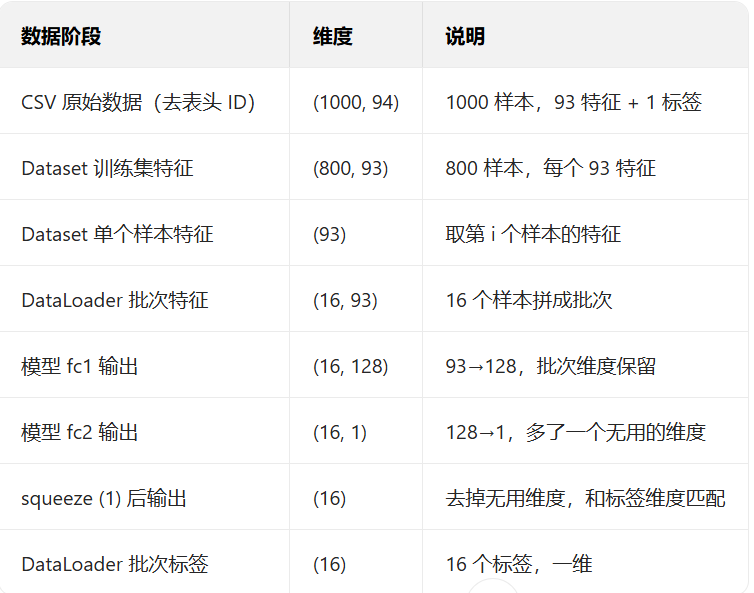
选用的数据集包含93个特征输入,继承torch.utils.data中的dataset基类获取模型
from torch.utils.data import Dataset,DataLoader自定义数据集类CovidDataset
class CovidDataset(Dataset):
#文件读取,要一个文件地址
def __init__(self,file_path,mode):
with open(file_path,"r") as f:
ori_data = list(csv.reader(f))
csv_data = np.array(ori_data)[1:,1:].astype(float) #不要第一行,第一列
#逢五取一,但不推荐
if mode =="train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
elif mode =="val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
elif mode =="test":
indices = [i for i in range(len(csv_data))]
X = torch.tensor(csv_data[indices, :93])
if mode != "test":
self.Y = torch.tensor(csv_data[indices, -1])
#标准化,概统知识,减期望除以标准差
self.X = (X - X.mean(dim=0,keepdim=True))/X.std(dim=0,keepdim=True)
self.mode = mode
def __getitem__(self,item):
if self.mode == "test":
return self.X[item].float()
else:
return self.X[item].float(),self.Y[item].float()
def __len__(self):
return len(self.X)要继承Dataset这一个基类,必须实现三个方法,分别是:
__init__:初始化,读数据、预处理
__getitem__:按索引取数据(比如要第 5 个样本)
__len__:返回数据集总长度
此次为了简单一点,我把训练集中每五个取一个作为验证集,测试模型训练的好坏
取数据集时我们训练模型的训练集,验证集需要把输入和输出都录入。其中训练集计算出预测值y^后需要梯度回转更新参数,验证集仅需对比y^和真实值检测效果,测试集仅需输入。
定义模型
#模型
class myModel(nn.Module):
def __init__(self,inDim):#inDim输入维度
super(myModel, self).__init__()
self.fc1 = nn.Linear(inDim, 128)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(128, 1) #输出维度为1,全局连接
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
if len(x.size ())>1:
#如果输出维数大于1,则将维度为1的维度去掉
x = x.squeeze(1)
return x建议全连接模型,与之前几节展示过的图片一样,就是要注意在一层全连接后记得要加上激活函数,不然和一层线性网络没区别
注意维度的问题:
forward就是求预测值的一步一步的过程,向前传播求y^
有了初始数据和模型之后,接下来就是开始训练了!
训练验证函数 train_val
def train_val(model, train_loader, val_loader, lr, optimizer, device, epochs, save_path):
# 把模型移到指定设备(GPU/CPU):必须!不然模型和数据不在一个地方,会报错
model = model.to(device)
# 记录每轮的训练损失和验证损失,用来画图
plt_train_loss = []
plt_val_loss = []
# 初始化最小验证损失:用无穷大
min_val_loss = float('inf') 记住我们训练模型的目的是找到最好的参数使得loss最小
处理训练集:
#开始训练模型
for epoch in range(epochs):
model.train()
start_time = time.time()
train_loss = 0.0#浮点型
#读数据
for x,y in train_loader:
x,y = x.to(device),y.to(device)
y_pred = model(x)
bat_loss = loss(y_pred,y,model)
bat_loss.backward()
optimizer.step()
#别忘了清零梯度
optimizer.zero_grad()
train_loss += bat_loss.cpu().item()
plt_train_loss.append(train_loss/train_loader.__len__())处理训练集时之前要加model.train()这个函数,具体原理不用关心,只需要知道这是个固定流程,作用是让模型会计算梯度,更新参数
训练模型的五部曲,必须刻在DNA里面去!
前向传播 → 计算损失 → 反向传播 → 优化器更新 → 梯度清零
模型中梯度是会累加的,这个问题强调过n次了,记住更新一次参数后就要清零一次。
还要注意的是我们计算的是一个批次的loss损失值,最后要取的是平均损失
验证部分,和训练部分比差不多,少了优化器的部分,验证阶段决不能更新参数
model.eval()
val_loss = 0.0
#进模型就会产生梯度,所以要关闭
with torch.no_grad():
for val_x,val_y in val_loader:
val_x,val_y = val_x.to(device),val_y.to(device)
val_pred_y = model(val_x)
val_bat_loss = loss(val_pred_y,val_y,model)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss/train_loader.__len__())更新的一轮参数与最小loss对比,更小则更新最小loss(就和在一堆数里面找最小值一样的)
# 早停策略:如果本轮验证损失比之前最小的还小,就保存模型
if val_loss < min_val_loss:
min_val_loss = val_loss # 更新最小验证损失
torch.save(model, save_path) # 保存整个模型损失函数 mseLoss
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean') #平方差损失
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss
loss = mseLoss #旨在进一步优化损失函数这里加了L2正则化防止过拟合,不用深究其原理,理解作用即可
最后,保存结果(即测试集)
def evaluate(model_path,test_loader,rel_path,device):
model = torch.load(model_path,weights_only= False).to(device)
rel = [] #记录预测结果
model.eval()
with torch.no_grad():
for x in test_loader:
x = x.to(device)
pred = model(x)
rel.append(pred.cpu().item())
#按规范格式提交
with open(rel_path,"w",newline="") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["id","tested_positive"])
#同时得到 第几个和第几个的结果
for i,pred in enumerate(rel):
csv_writer.writerow([str(i),str(pred)])
print("结果保存到了"+rel_path)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)