【AI学习-2.2】部署自己的本地大模型 —— 本地微调(LoRA)
前言
在上一篇文章《【AI学习-2.1】部署自己的本地大模型 —— 本地推理》中,我们已经完成了一件非常关键的事情:
在本地,把一个真实的大模型完整地跑了起来,但是在这一阶段,我们更多是在“使用模型”。 但如果模型永远只是一个只能调用、却无法改变的黑盒,那么对 AI 的理解始终停留在表层。这一篇,我们参数训练模型,改变原有的模型
一、什么是模型微调
微调并不是“重新训练一个模型”。 而是在原有模型的基础上做一些调整,改变他的参数,让他往你要的方向靠近
以 Qwen3-4B 为例,它已经在海量语料上完成过完整训练,内部参数规模达到数十亿级别。如果我们对它进行全参数训练:
- 对硬件资源要求极高
- 训练时间非常长
- 学习和试错成本都难以接受
因此,在实际工程和学习过程中,更常见的做法是:
在不破坏原有模型能力的前提下,对模型进行小幅度、定向的调整。
这类方法统称为参数高效微调(PEFT),而 LoRA 是其中最常见、也最成熟的一种方案。
二、什么是 LoRA,为什么从它开始
LoRA 的全称是 Low-Rank Adaptation,中文通常翻译为“低秩适配”。
从思想上看,LoRA 并不会直接修改原始模型的参数,而是:
- 冻结原模型的全部权重
- 在模型的关键线性层中插入一小组可训练参数
- 训练时只更新这些新增参数
可以把它理解为: 原模型是一台已经调校完成的精密机器,而 LoRA 是在关键位置外挂的一组“微调旋钮”。
LoRA 的主要特点
- 不改变原始模型参数
- 新增参数量极小,通常只占原模型参数的极小一部分
- 显存和内存占用低
- 训练完成后可以随时加载或卸载
LoRA 常见使用场景
- 学习和理解大模型微调流程
- 针对特定任务或风格进行定向训练
- 单卡、小显存或资源受限的本地环境
正因为这些特性,LoRA 非常适合作为第一次接触模型微调的起点。
三、本篇文章要做什么
在这一篇中,我们将完成一次完整、但刻意“简化”的本地微调流程:
- 加载已经训练好的基础模型
- 使用 LoRA 注入可训练参数
- 加载一份监督微调数据
- 执行训练
- 保存 LoRA 权重
整个过程的目标不是训练效果,而是理解每一步在做什么,以及为什么要这么做。
四、基础训练参数的含义
在微调中,这些参数经常会让新手感到困惑,这里逐一解释。
max_length = 512
lr = 2e-4
epochs = 2
batch_size = 1
batch_size
batch_size 表示:
每一次参数更新时,模型同时“看到”的样本数量。
可以把训练过程理解为一个循环:
模型先读取一小批数据,计算误差(loss),然后根据误差对参数进行一次更新。
这一小批数据的数量,就是 batch_size。
- batch_size 越大,梯度估计越稳定
- batch_size 越大,占用的显存或内存也越多
在本地微调大模型时,最常见的问题并不是训练慢,而是模型根本跑不起来,直接因为内存或显存不足而中断。
因此在学习阶段,将 batch_size 设置为 1,是一个非常稳妥的选择。
它的核心目标不是效率,而是优先保证训练流程能够完整跑通。
learning_rate
learning_rate(学习率)控制的是模型参数每一次更新时,调整的幅度大小。
可以简单理解为:
模型“犯一次错”,要改正多少。
- 学习率过大:参数更新过猛,训练容易震荡甚至发散
- 学习率过小:训练非常稳定,但学习速度极慢
在 LoRA 微调中,由于可训练参数本身就很少,学习率通常会比全参数训练略大一些。
2e-4 是一个非常常见、也相对安全的起始值。
epochs
epoch 表示:
整个训练数据集被模型完整“看一遍”的次数。
例如:
- epochs = 1:(平均)每条数据只参与一次训练
- epochs = 2:(平均)每条数据会被模型看到两次
在本文中,我们并不追求模型效果,而是希望完整跑通一次微调流程,因此只设置为 2。
五、Tokenizer 在微调中的作用
Tokenizer 的作用,是把人类可读的文本转换为模型可以处理的 token 序列。
在因果语言模型中,经常会遇到一个实际问题:
模型没有显式定义 pad_token,但训练时又需要对不同长度的样本进行 padding。
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
将 pad_token 设置为 eos_token,是一种非常常见且安全的做法,可以避免训练过程中的告警和错误。
六、加载基础模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
trust_remote_code=True
)
这一步与上一篇文章中的推理加载非常相似。
不同的是,此时模型将进入训练流程,但原始权重随后会被 LoRA 冻结,不会发生更新。
七、LoRA 配置的含义
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
这部分是 LoRA 微调的核心配置。
- target_modules 指定 LoRA 注入的位置
在这里,我们只对注意力机制中的 q_proj 和 v_proj 生效 - r 决定了 LoRA 的低秩维度,数值越大,表达能力越强
- lora_alpha 用于控制 LoRA 更新的整体幅度
- lora_dropout 用于缓解过拟合
从经验上看,将 LoRA 注入到注意力层,通常可以在极小参数量的前提下,显著影响模型行为。
八、加载监督微调数据
dataset = load_dataset("json", data_files=dataset_path, split="train")
这里使用的是 jsonl 格式的数据集。
在监督微调(SFT)中,每一条样本通常包含:
- 输入(用户问题或指令)
- 输出(期望模型给出的回答)
SFTTrainer 会自动完成样本拼接、tokenize、mask 构造和 loss 计算。
九、训练参数与 Trainer
training_args = TrainingArguments(
output_dir=r"E:\it\project\pycharm\learnModel\lora\first",
per_device_train_batch_size=batch_size,
learning_rate=lr,
num_train_epochs=epochs,
logging_steps=10,
save_strategy="epoch",
save_total_limit=2,
fp16=torch.cuda.is_available(),
optim="adamw_torch"
)
output_dir 用来指定训练过程中产生的所有文件保存到哪里,包括 LoRA 权重和中间的 checkpoint。训练结束后真正有用的结果基本都在这个目录里。
per_device_train_batch_size 表示每张卡(或 CPU)一次喂给模型多少条数据。这个值越大,占用的显存或内存越多,本地学习阶段一般都设得很小。
learning_rate 控制模型参数每一步更新的幅度大小。太大会导致训练不稳定,太小又学得很慢,这里直接复用前面定义好的学习率。
num_train_epochs 表示整个数据集会被模型完整训练多少轮。学习阶段不追求效果,跑一两轮主要是为了走通流程。
logging_steps 用来控制每隔多少步打印一次训练日志。值设小一点,可以更直观地看到 loss 是否在下降。
save_strategy 决定什么时候保存模型,这里设置为 “epoch”,表示每跑完一轮数据就保存一次。这样比较直观,也方便之后回滚或对比。
save_total_limit 用来限制最多保留多少个保存点,防止 checkpoint 越存越多把磁盘占满。超过这个数量,旧的 checkpoint 会被自动删除。
fp16 表示是否启用半精度训练,这里只有在 GPU 可用时才开启。开启后可以明显降低显存占用,对本地训练很友好。
optim 用来指定使用哪种优化器,adamw_torch 是一个比较稳妥、默认推荐的选择。对于 LoRA 这种微调场景,一般不需要纠结优化器类型。
十、开始训练并保存 LoRA 权重
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=lora_config,
processing_class=tokenizer,
args=training_args
)
trainer.train()
trainer.save_model(training_args.output_dir)
训练结束后,保存下来的并不是完整模型,而只是 LoRA 权重和相关配置文件。
这意味着:
- 原始模型可以被多个 LoRA 复用
- 不同任务只需要切换不同的 LoRA 权重
- 微调成本和风险都被大幅降低
十一、开始微调
自此,我们已经介绍微调的一些基础概念和步骤,总体代码如下
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
from peft import LoraConfig
from trl import SFTTrainer
# =========================
# 一、基础配置
# =========================
#换成你自己Qwen3-4B代码的位置
model_path = r"E:\it\project\pycharm\Qwen3-4B"
#换成你自己训练集的位置
dataset_path = r"E:\it\project\pycharm\learnModel\resource\finetune_data.jsonl"
device = "cuda" if torch.cuda.is_available() else "cpu"
max_length = 512
lr = 2e-4
epochs = 2
batch_size = 1
# =========================
# 二、Tokenizer
# =========================
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# 避免告警
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# =========================
# 三、加载基础模型
# =========================
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
trust_remote_code=True
)
# =========================
# 四、LoRA 配置
# =========================
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# =========================
# 五、加载数据集并 tokenize
# =========================
dataset = load_dataset("json", data_files=dataset_path, split="train")
# =========================
# 训练参数
# =========================
training_args = TrainingArguments(
output_dir=r"E:\it\project\pycharm\learnModel\lora\first",
per_device_train_batch_size=batch_size,
learning_rate=lr,
num_train_epochs=epochs,
logging_steps=10,
save_strategy="epoch",
save_total_limit=2,
fp16=torch.cuda.is_available(), # GPU 支持时开启半精度
optim="adamw_torch"
)
# =========================
# SFTTrainer 初始化
# =========================
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=lora_config,
processing_class=tokenizer,
args=training_args
)
# =========================
# 八、开始训练
# =========================
trainer.train()
# =========================
# 九、保存 LoRA 权重
# =========================
trainer.save_model(training_args.output_dir)
dataset_path 就是是你的训练数据文件,为了训练得快,我随便写了两行,实际上训练数据会很多
{"messages":[{"role":"user","content":"Kafka 是什么?"},{"role":"assistant","content":"Kafka 是一个分布式消息流平台。"}]}
{"messages":[{"role":"user","content":"Corki Tse 是谁?"},{"role":"assistant","content":"Corki Tse 是一个歌手,出生于中国,代表作是《VIVI》"}]}
运行后你会得到一个文件,就放在你output_dir指定的位置上,这个就是我们微调的成果,这里并不会保存原模型的全部参数,而是保存训练后的增量变化部分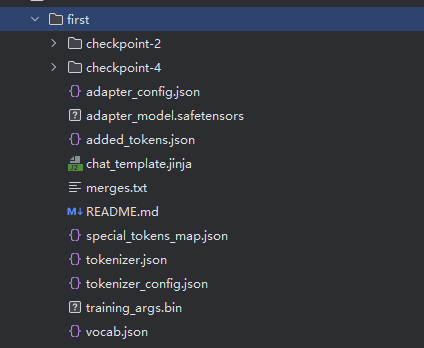
十一、使用微调的模型后做推理
在上一章推理代码上,替换下原本的model就可以了
model_path = r"E:\it\project\pycharm\Qwen3-4B"
#这里就是刚才微调时output_dir指定的文件
lora_path = r"E:\it\project\pycharm\learnModel\lora\first"
#获取到微调后的tokenizer
tokenizer = AutoTokenizer.from_pretrained(
lora_path,
trust_remote_code=True
)
# 原来的大模型
base_model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cpu",
dtype=torch.float32,
trust_remote_code=True,
# 启用分块加载 + 就地绑定, 在加载模型权重时,避免“权重在内存里被复制一遍”,把“加载峰值内存”降到最低。
low_cpu_mem_usage=True
)
#在原来的大模型原来大模型的基础上加上刚才lora的训练结果
model = PeftModel.from_pretrained(
base_model,
lora_path
)
#... 接下来就是原本的逻辑
执行过程和结果
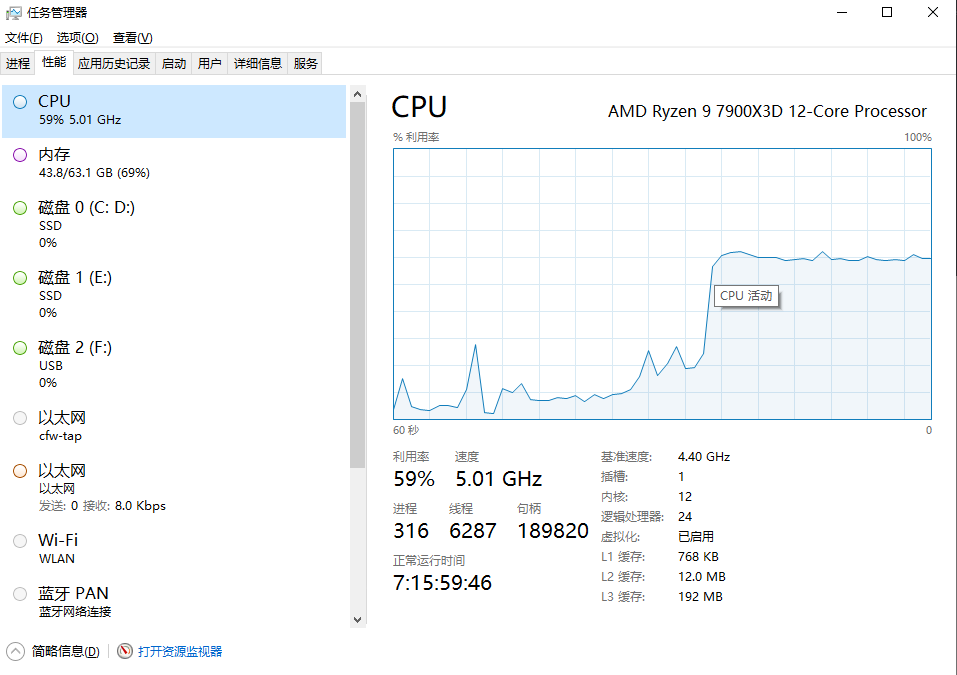

虽然感觉训练和没训练一样,但是这也正常,我们本身的微调训练数据就太少了,我们本次学习知识掌握怎么训练,后面需要自己训练得时候除了需要准备很多微调数据,还有很多其他参数也需要根据自己需求优化。前面的文章知识让大家对于模型有个初体验,拉进我们和ai的距离

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)