最近AI领域爆火的 Agent Skills 是什么?
AI智能体领域正经历从数据连接到能力构建的转变。MCP协议解决了LLM与外部工具的连接问题,而新兴的Agent Skills标准则致力于构建智能体的可执行能力。Agent Skills采用结构化文件夹形式(含指令文件SKILL.md、脚本、参考资料等),通过渐进式披露机制分阶段加载信息,有效管理上下文窗口。该标准已获行业广泛支持,其核心优势在于实现技能的可移植性、降低指令复杂性,并优化性能表现。典
过去一年,AI 智能体领域经历了从"功能摸索"到"标准建立"的剧烈演变。几个月前,MCP (Model Context Protocol) 还是开发者眼中的"小甜甜",它解决了 LLM 与外部数据源连接的碎片化问题。然而 AI 领域的风向变化总是猝不及防——随着 Agent Skills 开放标准的走红,曾经火爆的 MCP 在热度上似乎正逐渐变成"牛夫人"。开发者们已从单纯讨论如何连接数据(MCP),转向如何更结构化、更具可移植性地赋予 AI 真正的"执行力"(Skills)。
那么,在 MCP 已经主导底层连接标准的今天,为什么我们还需要 Agent Skills?
简单来说:如果 MCP 是 Agent 的"神经系统"和"感官"——像电脑的 USB 接口一样负责连接外部工具;那么 Agent Skills 就是 Agent 的"操作指南"和"专业课本"——负责教导它如何组合这些工具、遵循什么逻辑流程,以及参考哪些垂直领域的专业知识。
由 Anthropic 维护的 Agent Skills 开放标准,旨在解决 Agent 能力的可移植性与指令复杂性问题。标准发布后迅速引发行业跟进——除了 Anthropic 旗下的 Claude 系列原生支持外,头部 AI 编程工具 Cursor、以及科技巨头 Google 和 OpenAI 都在其生态中快速跟进。这种多方共识使 Skills 迅速从单一厂商构想演变为跨平台通用标准。
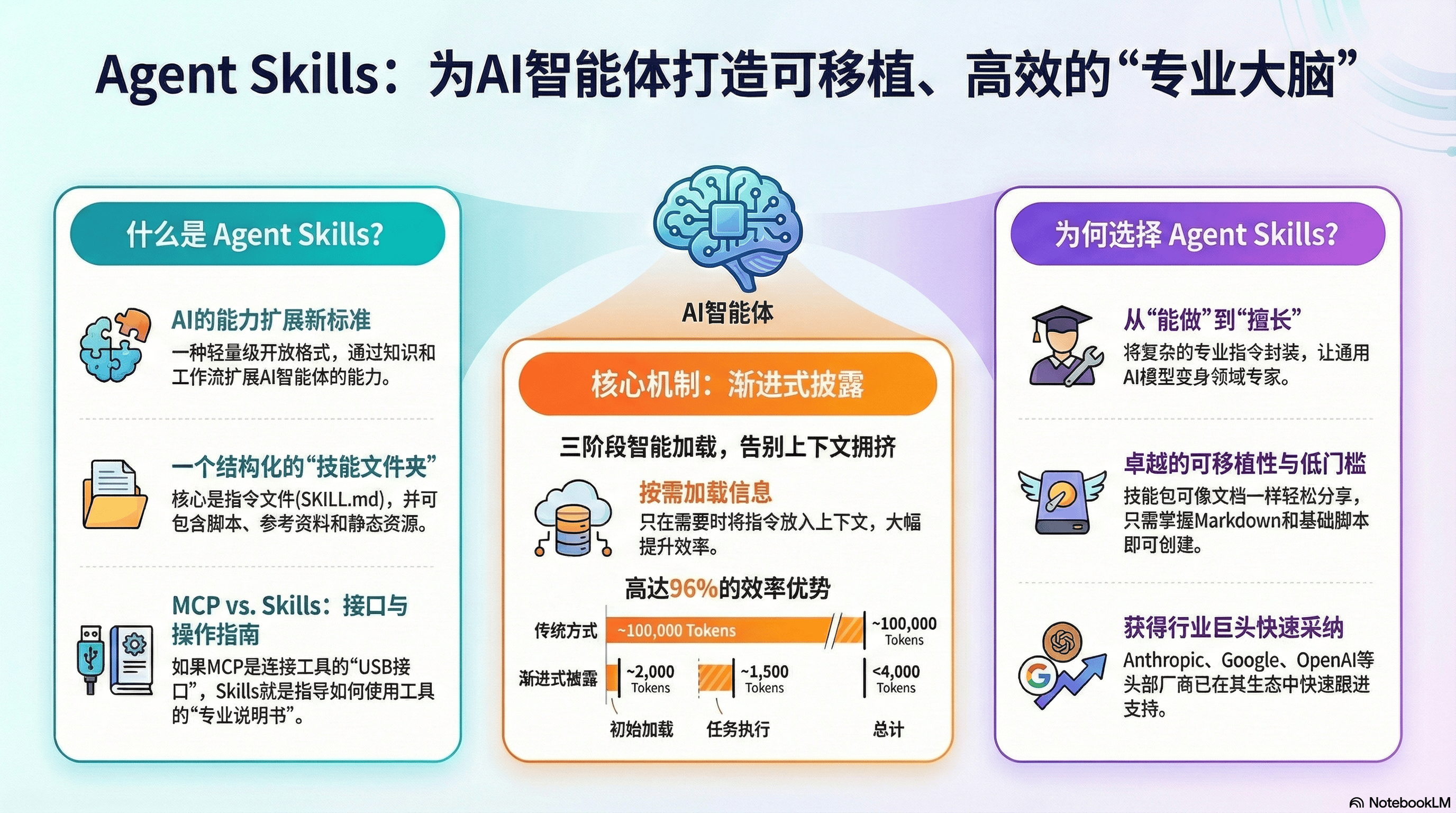
什么是 Agent Skills?
Agent Skills 是一种轻量级的开放格式,用于通过专业知识和工作流扩展 AI 智能体的能力。与 MCP 服务器需要运行代码服务不同,一个"技能"(Skill)在形式上就是一个结构化的文件夹。其核心是一个名为 SKILL.md 的文件,包含了元数据(如名称和描述)以及告知智能体如何执行特定任务的详细指令。
典型的技能目录结构如下:
my-skill/
├── SKILL.md # 核心文件:指令 + 元数据
├── scripts/ # 可选:该技能专属的可执行代码
├── references/ # 可选:技术文档、领域知识参考
└── assets/ # 可选:模板、静态资源
为了支持复杂的任务,除了核心的 SKILL.md,技能文件夹还可以包含以下可选目录:
scripts/:包含该技能专属的自动化脚本(如 Python、Bash 或 Node.js)。当某些任务通过纯 Prompt 难以稳定实现,或者需要进行复杂的数值计算、文件处理时,Agent 可以直接运行这些脚本。references/:存放该领域的专业文档、API 手册、技术标准或常见问题解答(FAQ)。Agent 会在需要时按需读取这些参考资料,这既能保证专业性,又避免了将所有知识硬编码在提示词中。assets/:存放各种静态资源,例如配置模板、数据文件、用于对比的示例图像或预定义的 JSON Schema。这些资源为 Agent 提供了执行任务所需的"原材料"。
如果说 MCP 是一个个独立的工具,那么 Skill 就是一个工具箱——里面不仅装有工具,还附带了详细的使用说明书(SKILL.md)。
理解了基本概念后,让我们通过一个具体示例看看如何构建一个实用的 Skill。
示例:PDF 处理SKILL
以下是构建 PDF 处理技能的完整示例:
---
name: pdf-processing
description: 从 PDF 文件中提取文本和表格、填写表单、合并文档
version: 1.0.0
author: Example Team
---
# PDF 处理技能
## 技能概述
这个技能帮助智能体处理各种 PDF 相关任务,包括文本提取、表格解析、文档合并等操作。
## 何时使用此技能
当用户提出以下需求时激活此技能:
- 从 PDF 中提取文本或数据
- 解析 PDF 中的表格结构
- 合并多个 PDF 文件
- 填写 PDF 表单
- 将 PDF 转换为其他格式
## 前置要求
- 确认环境中已安装 `PyPDF2` 和 `pdfplumber` 库
- 对于 OCR 功能,需要 `pytesseract`
- 检查 PDF 文件是否可访问且未加密
## 操作步骤
### 1. 文本提取
'''python
# 使用 scripts/extract_text.py
python scripts/extract_text.py --input document.pdf --output output.txt
'''
### 2. 表格解析
- 使用 `pdfplumber` 识别表格边界
- 将表格数据转换为 CSV 或 JSON 格式
- 参考 `references/table-parsing-guide.md` 了解复杂表格处理方法
### 3. PDF 合并
'''python
# 使用 scripts/merge_pdfs.py
python scripts/merge_pdfs.py --files file1.pdf file2.pdf --output merged.pdf
'''
### 4. 处理扫描件
- 如果 PDF 是扫描图像,先调用 OCR 功能
- 详细步骤参见 `references/ocr-guide.md`
- 使用 Tesseract 进行文字识别
## 常见问题处理
- **加密 PDF**:提示用户提供密码或使用解密工具
- **损坏文件**:尝试使用 PDF 修复工具
- **大文件**:分批处理,避免内存溢出
## 输出格式
根据任务类型返回:
- 纯文本:`.txt` 文件
- 表格数据:`.csv` 或 `.json` 文件
- 合并文档:新的 `.pdf` 文件
## 参考信息
- `references/pdf-standards.md` - PDF 格式标准说明
- `references/ocr-guide.md` - OCR 最佳实践
- `references/troubleshooting.md` - 常见问题排查
这个示例展示了一个完整的 PDF 处理技能的结构。可以看到:
- 元数据:在文件顶部使用 YAML 格式定义技能的名称、描述、版本等基本信息
- 指令内容:详细说明何时使用该技能、具体操作步骤、注意事项等
- 引用机制:通过相对路径引用
scripts/、references/等目录中的资源
这种结构化的方式让 Agent 既能理解"做什么",也能知道"怎么做"。更重要的是,它通过**渐进式披露(Progressive Disclosure)**机制,只在需要时才加载详细内容,从而有效管理上下文窗口。
核心机制:渐进式披露
渐进式披露是 Agent Skills 的核心设计理念,它通过分阶段加载信息来优化上下文窗口的使用效率。这个机制可以类比为"按需加载"或"懒加载"策略。
三个阶段的工作流程
阶段一:发现阶段(Discovery Phase)
在这个阶段,智能体启动时只会扫描所有技能文件夹中的 SKILL.md 文件头部的元数据(YAML Frontmatter)。它仅读取每个技能的:
name(技能名称)description(简短描述)version(版本号)等基础信息
此时,Agent 的上下文中只有一个轻量级的"技能索引表",就像书籍的目录一样。这个阶段消耗的 token 非常少,即使有数百个技能也不会造成负担。
阶段二:激活阶段(Activation Phase)
当用户提出具体任务时,Agent 会:
- 分析用户意图,判断需要哪项技能
- 根据技能的
description进行匹配 - 一旦确定需要某个技能,才会完整读取该技能的
SKILL.md文件内容
例如,用户说"帮我合并这三个 PDF 文件",Agent 会:
- 识别关键词"合并"、“PDF”
- 在技能索引中找到
pdf-processing技能 - 此时才将完整的 PDF 处理指令加载到上下文中
这种按需激活机制确保了任何时刻上下文中只包含当前任务真正需要的指令,避免了"指令拥挤"。
阶段三:执行阶段(Execution Phase)
在执行过程中,Agent 会根据 SKILL.md 中的指引:
- 按需读取
references/目录中的参考文档(如遇到特殊情况才查阅故障排查指南) - 调用
scripts/中的自动化脚本 - 使用
assets/中的模板或配置文件
这些资源不是一次性全部加载,而是"用到什么,加载什么"。比如只有在处理扫描件 PDF 时,才会读取 references/ocr-guide.md。
为什么渐进式披露如此重要?
1. 上下文窗口管理
即使是最先进的大语言模型,上下文窗口也是有限的。如果一次性加载所有技能的完整指令,很容易导致:
- 上下文溢出,模型无法处理
- 关键信息被"埋没"在大量无关指令中
- 推理成本大幅增加
2. 性能优化
通过渐进式披露:
- 初始化速度快:只需扫描元数据
- 响应延迟低:只加载必要内容
- Token 消耗少:避免浪费在无关信息上
3. 可扩展性
这种机制使得一个 Agent 可以轻松管理几十甚至上百个技能,而不会因为技能数量增加而导致性能下降。就像你的电脑可以安装很多软件,但只有打开的程序才会占用内存。
实际案例对比
传统方式(全量加载):
渐进式披露方式:
可以看到,渐进式披露将初始负载从 100,000 tokens 降低到了 2,000 tokens,而实际执行时只增加了 1,500 tokens,总计不到 4,000 tokens——节省了96%的上下文开销。
这种设计哲学体现了"信息的即时性价值"原则:在正确的时间提供正确的信息,而不是一次性抛给 Agent 所有可能用到的知识。这也是为什么 Agent Skills 能够在保持高性能的同时支持复杂的专业领域应用。
理解了 Skills 的工作原理后,一个自然的问题是:既然已经有了 MCP,为什么还需要 Skills?
为什么在有了 MCP 后仍需要 Skills?
- 从"能做"到"擅长":MCP 提供了打开 PDF 的"工具",但 Agent Skills 提供了"如何解析特定格式发票并进行账目核对"的"技能"。
- 指令封装:有些复杂的任务流(例如:代码审计、特定的法律文档审查)如果全部写在 System Prompt 里会显臃肿。Skills 允许将这些专业指令按需加载。
- 零成本分发:Skills 本质上是纯文本和脚本文件的集合,不需要部署额外的 MCP 服务器,非常适合在社区、团队间像分享 Markdown 文件一样快速分发。
- 互补关系:Skills 可以在指令中引用 MCP 提供的工具。例如,一个"数据分析技能"可以指导 Agent 调用 MCP 接口从 SQL 数据库取数,然后应用该技能内置的统计模型进行分析。
Agent Skills 的优势
- 自文档化 (Self-documenting):开发者和用户都可以直接阅读
SKILL.md,轻松理解其逻辑。 - 可移植性 (Portable):基于文件系统,可以在不同的智能体平台(如 Claude Code, Cursor 等)之间无缝迁移。
- 低门槛:只要你会写 Markdown 和简单的脚本,你就能为 Agent 创造一项新技能。
- 高效性:通过渐进式披露机制,在保持强大功能的同时最小化上下文占用。
- 模块化:技能可以独立开发、测试和分发,便于团队协作和知识积累。
结语
如果说 MCP 正在构建 AI 时代的"硬件接口标准",那么 Agent Skills 就在定义 AI 的"软件应用格式"。它弥合了模型原生能力与垂直领域复杂逻辑之间的鸿沟。在 Agent 的进化道路上,MCP 让它触达万物,而 Skills 让它无所不能。
参考资料
- agentskills.io - Agent Skills 官方网站
- GitHub 示例项目 - 官方技能示例

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)