拒绝做文献搬运工:我用2小时,给自己“捏”了一个不知疲倦的科研搭子
本文记录了作者开发深度学习科研助手的实践过程。面对论文阅读和综述写作的信息过载问题,作者基于Nvidia的"Build a Deep Research Agent"课程,构建了一个具备自主思考能力的智能体系统。该系统通过Docker环境隔离、Llama-3.3推理模型、RAG检索管道和AI-Q协调框架四层架构,实现了从文献检索到报告生成的完整科研流程。文章重点分享了网络配置、服
这里写自定义目录标题
在刚学完的 Nvidia 的 Build a Deep Research Agent 课程里,我找到了解药。原来,要把 AI 变成科研助理,关键不在于模型有多大,而在于**“架构”**。我需要的是一个 Agent(智能体),而不仅仅是一个 Chatbot。
下面是课程链接:https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-40+V1
左边 Zotero 几百个未读,右边综述写不出:我给自己捏了个“不知疲倦”的科研替身
现在是凌晨两点。左边的显示器是 Zotero 里几百篇标记为“待读”的 PDF,右边是写了一半卡壳的 Word 文档。如果你也是科研狗,一定懂那种绝望:不是读不懂,而是信息过载。
现在的顶会论文井喷,光是跟进最新的流体力学(CFD)和深度学习结合的进展就得耗掉半条命。我需要的不再是一个只能陪聊的 ChatGPT,而是一个能像我一样思考、但阅读速度比我快一万倍的“分身”。
市面上的工具,像 Cherry Studio 这种本地客户端,导入文档做问答还行,但一让它写长篇综述就“力不心”;国外的 Deep Research 功能虽然强,但针对我这种极度垂直的专业领域,由于缺乏私有数据支持,写出来的东西往往浮于表面。
既然现成的都不顺手,作为搞深度学习的,我决定自己动手“搓”一个。而在刷完 NVIDIA DLI 的《Build a Deep Research Agent》课程后,我发现这事儿比我想象的要更有趣——我不仅是在部署一个模型,而是在设计一个会反思的大脑。
为什么通用的 AI 搞不定我的综述?
之前我试过把论文扔给大模型,它们最大的问题是**“没有脑子”**。Chatbot 就像客服,你问一句它答一句;而科研需要的是 Agent(智能体)。
我想要的 Agent 是这样的:当我甩给它一个课题(比如“总结近三年 PINN 在湍流重建中的应用”),它能自己拆解任务、自己去检索库里翻书、自己规划写作路径,最后把报告拍在我桌上。
成果展示:它真的在“做研究”,而不是在“拼凑字数”
按照课程部署完之后,这个 Agent 的工作流让我有点感动。它不是上来就写,而是先思考。
在前端界面选好我的数据集(也就是那一堆让我头大的 PDF),再勾选上“网络搜索”作为补充,它会先吐出一个 Plan(执行计划)。比如它会把综述拆解为“物理约束机制”、“数据归一化影响”、“超分模型架构”几个章节。如果我觉得它跑偏了,还可以直接对话让它改计划。
点击执行后,它就开始给我“打工”了。通过后台日志,我能清晰地看到它的思考回路:
- RAG 检索:先去我的本地知识库里翻老底。
- 网络搜索:发现本地资料不够(比如最新的 NeurIPS 2025 还没入库),它会自动去联网搜补充材料。
- 反思与修正:这是最绝的一步。它写完一段摘要后,会自己进行 Reflection(反思),检查有没有遗漏的关键点。如果有,它会重新搜索、重新组织语言。
- 最终报告:输出一份带有一级、二级标题,且严谨引用来源的长篇报告。
下面是实际操作过程中AI规划的思考流程:
扒一扒源码:它为什么比 ChatGPT 更像研究生?
作为“调包侠”肯定不能满足于点点鼠标,我去扒了一下它的源码(LangGraph 实现的),发现了几个很有意思的设计细节,非常值得我们在做自己的工具时借鉴。
第一,它极其讨厌 Bullet Points(列表)。
在 prompts.py 文件里,我写了一段 Meta Prompt,明确写着:“Avoid bullet lists unless absolutely necessary.”
ChatGPT 特别喜欢列 1234,但严肃的学术综述需要的是逻辑严密的段落(Paragraphs),是起承转合,而不是简单的罗列。
第二,它有一个“反思”节点。
在 LangGraph 的图结构里,除了 Search 和 Summarize,专门有一个 Reflection 节点。它会拿着草稿问自己:“这里有没有解释清楚?有没有遗漏的视角?”然后生成新的搜索 query 去补全信息。这种 Loop 循环,才是它能写出深度的原因。
第三,前后端的状态管理。
它采用的是“后端无状态、前端维护状态”的模式。这和 LangChain 现在的 Middleware 路线不太一样。我的理解是,如果你的 Agent 交互逻辑特别复杂(比如你要在中间疯狂插手修改),把状态扔给前端处理可能更灵活。
从头开始打造智能体:Build a Deep Research Agent
英伟达的在线平台提供了方法的课程下面以我学的这个课程为例
课程概览与大纲
说明:课程启动页,展示了从基础推理模型到完整 Agent 搭建的学习路线。
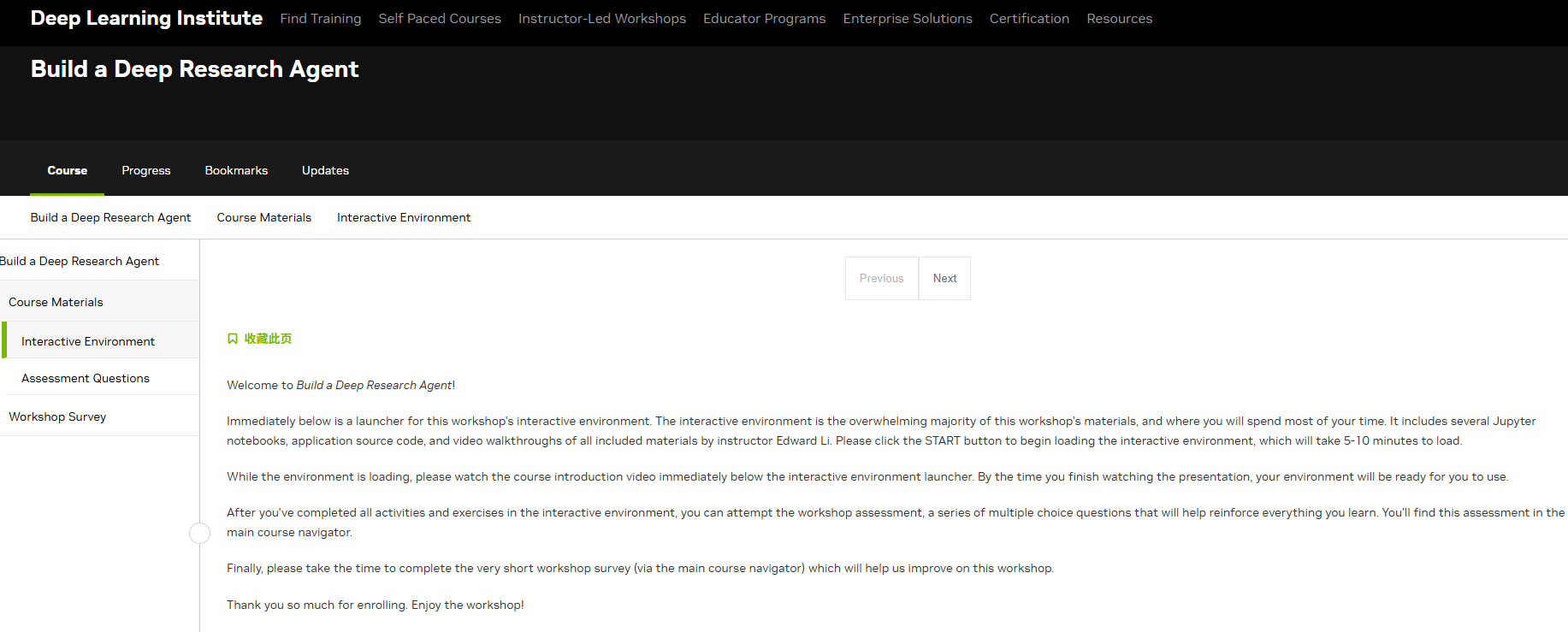
课程视频截图AI-Q 智能体架构图
说明:展示了 Deep Research Agent 如何通过 aira-backend 协调 RAG 检索与 LLM 推理的逻辑架构。

场景三:深度研究智能体运行界面 (Frontend)
说明:英伟达提供jupyter操作界面与CPU算力。
并没有想象中那么难:四步搭建指南
如果你担心自己代码能力不够,其实大可不必。整个实验在 Jupyter Notebook 里完成,除了填两个 API Key,几乎不需要写代码,一路 Run 下去就行。
1. 给它找个脑子(Deploy NIM)
首先是解决“智力”问题。课程用的是 NVIDIA 的 Nemotron 模型,这玩意儿不仅能对话,更关键的是开启“深度思考”模式后,逻辑推理能力大幅提升。Notebook 里演示了如何通过 OpenAI 兼容接口调用它,甚至支持本地部署(如果你显卡够硬的话)。
2. 给它装上记忆(Deploy RAG)
光有脑子不行,还得有书读。这一步是搭建 RAG(检索增强生成) 流水线。这里用到了 NVIDIA NeMo Retriever,它最让我惊喜的是对多模态数据的处理——它能识别论文里的图表和表格!这一点对科研文献太重要了,毕竟很多核心结论都在图里。它把知识切片、存入向量数据库(Vector DB),确保 Agent 说话有凭有据。
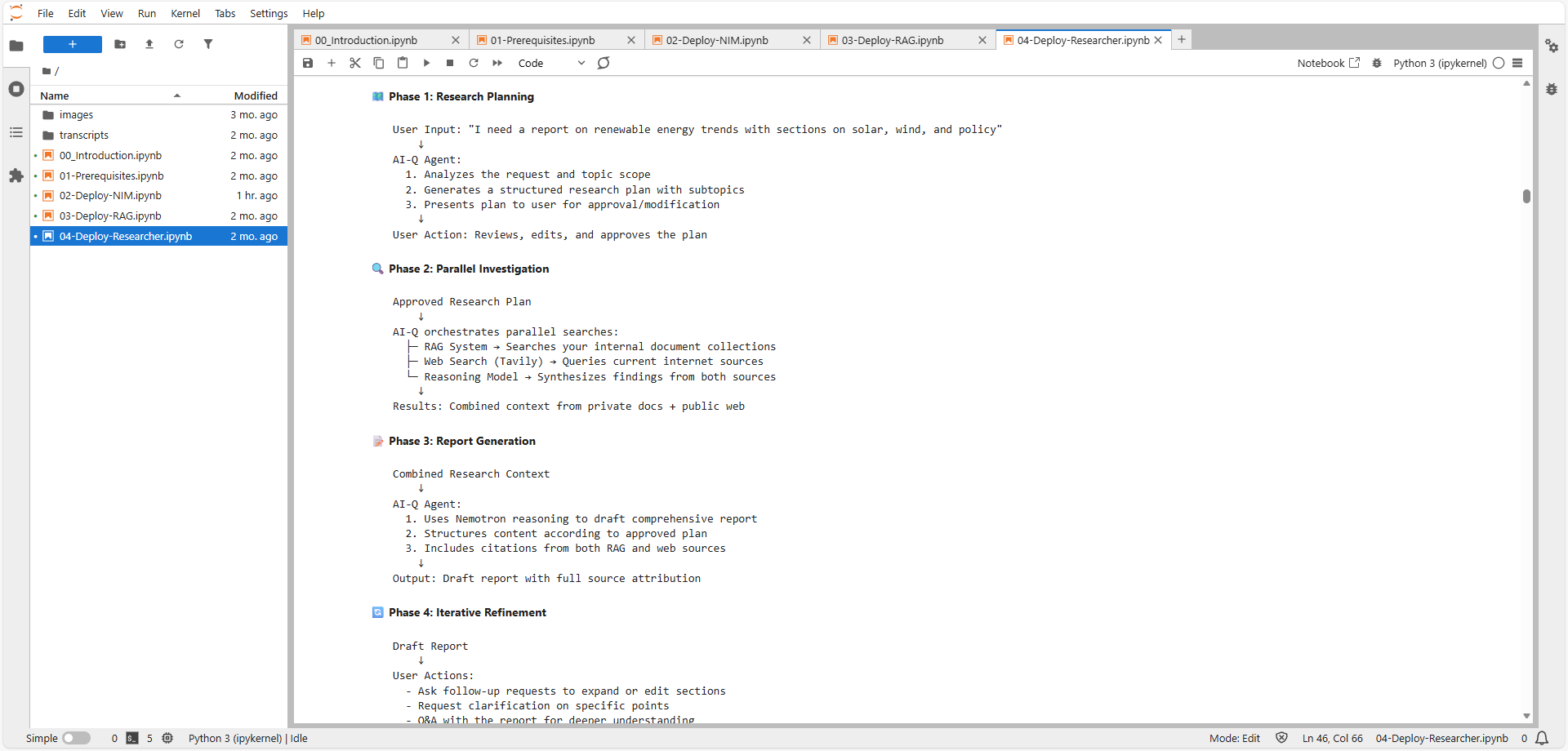
3. 组装“研究员”(Deploy Researcher)
最后就是把脑子(Nemotron)、记忆(RAG)和手脚(Tavily 搜索工具)拼在一起。这里用到了 Docker Compose,把前后端一共 10 个容器拉起来。虽然看着复杂,但脚本一跑,访问 localhost:3000,那个看起来很专业的界面就出来了。
操作平台中的部分Python 脚本讲解
下面代码放在博客里面为下次部署作为参考
# 1. 修正网络配置 (Network Adjustment)
# 目的:将 Agent 服务连接到之前部署 RAG 时创建的特定网络 's-fx-40-v1_default'。
# 原理:Docker 容器之间通信必须在同一网络下。如果 RAG 在 Network A,Agent 在 Network B,它们将无法对话。
if 'name' in data['networks']['default']:
data['networks']['default']['name'] = "s-fx-40-v1_default"
# ... (省略打印代码)
else:
# 如果没有定义,则强制创建一个指向该外部网络的 default 网络
data['networks'] = {
'default': {
'external': True,
'name': 's-fx-40-v1_default'
}
}
# 2. 清理服务配置 (Service Cleanup)
services = ["aira-instruct-llm", "aira-backend", "aira-frontend"]
for service in services:
# 移除 'runtime':在 DLI 的嵌套环境中,外层可能已经处理了 GPU 运行时,
# 或者特定的 runtime 标签会导致子容器启动失败。
if 'runtime' in data['services'][service]:
del data['services'][service]["runtime"]
# 移除 'networks':移除服务级别的特定网络配置,
# 强制服务使用上面定义的全局 'default' 网络,确保所有服务都在同一通道上。
if 'networks' in data['services'][service]:
del data['services'][service]["networks"]
# 3. 修正卷挂载 (Volume Mount Fix)
# 核心难点:在 Docker-in-Docker 中,${PWD} 通常指的是容器内的路径,
# 但挂载卷需要宿主机的绝对路径。
if 'services' in data and "aira-backend" in data['services']:
# 获取环境变量 HOST_TASK1_DIR,这是 DLI 平台预设的真实宿主机路径。
host_task1_dir = os.environ.get("HOST_TASK1_DIR", "")
# 动态重写 volumes 路径,确保 backend 能读取到正确的配置文件。
data['services']['aira-backend']['volumes'] = [f"{host_task1_dir}/task/aiq-research-assistant/configs:/app/configs"]
启动指令:Docker Compose
docker compose -f deploy/compose/docker-compose.yaml --profile aira up -d
--profile aira: 这是一个高级用法。Compose 文件中包含了许多服务(可能包括 RAG 相关的),但我们现在只想启动带有aira标签的服务(即 Research Assistant 相关的后端和前端),避免重启之前已经运行的 RAG 服务。-d: 后台静默运行,不占用终端。
学习心得与总结
踩坑与突围:当代码遇上环境隔离问题
搭建过程并非一帆风顺,最让我头秃的不是算法原理,而是工程落地的“最后一公里”。
在最后部署 Agent 时,我遇到了所有微服务架构的噩梦——网络隔离。我的“大脑”(Agent 后端)死活连不上“图书馆”(RAG 向量库),报错日志红成一片。排查了半天才发现,因为 DLI 环境的特殊嵌套结构,两个服务被锁在了不同的 Docker 网络里,就像两个人在隔音的房间里对喊。
那段 Python 自动化修补脚本,就是在这个绝望时刻诞生的。它不是为了炫技,而是为了生存——强制修改 docker-compose.yaml,给 Agent 颁发一张通往 RAG 网络的“通行证”。当看到终端里终于跳出 Connection Established 时,那种快乐不亚于论文被接收。它让我深刻理解到:在 AI 系统工程中,网络拓扑的设计与算法模型同样重要。
终局思考:它不仅仅是一个综述写手
看着屏幕上 AI 自主生成的带有引用标注的报告,我意识到这个 Agent 的潜力远不止于帮我写综述。
如果我把 RAG 的知识库换成 OpenFOAM 的官方文档和 GitHub Issues,再接入我的本地报错日志,它是不是就能变成一个 Debug Agent?在我代码报错时,直接分析 Traceback,检索文档,给出修复方案?
未来的科研,或许不再是比拼谁读的论文多,而是看谁能构建出更强大的 Agent 团队:一个负责广撒网检索,一个负责批判性筛选,一个负责逻辑整合。而我,只需要做那个定义问题、把控方向的“导师”。
这门课,就是我构建这个未来的第一块砖。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)