【论文笔记】RAG MAKES GUARDRAILS UNSAFE? INVESTIGATING ROBUSTNESS OF GUARDRAILS UNDER RAG-STYLE CONTEXTS
作者提出一个不需要人工标注的新指标:Flip Rate(翻转率)定义为:当 guardrail 在 normal context 和 RAG-style context 下给出不同判断就记为一次 Flip。随着大模型从“单模型生成”逐步演进为系统级架构(LLM + Tool + RAG + Guardrails),安全机制本身正成为系统中的一个独立模块。简单的 Prompt 修改或增加推理能力是不
论文信息
论文标题: RAG MAKES GUARDRAILS UNSAFE? INVESTIGATING ROBUSTNESS OF GUARDRAILS UNDER RAG-STYLE CONTEXTS
论文作者: Yining She, Daniel W. Peterson, Marianne Menglin Liu et al. - CMU, Oracle Cloud Infrastructure, UPenn
论文链接: https://arxiv.org/abs/2510.05310
论文关键词: guardrail, RAG
研究背景与动机
随着大模型从“单模型生成”逐步演进为系统级架构(LLM + Tool + RAG + Guardrails),安全机制本身正成为系统中的一个独立模块。当前工业界与学术界广泛采用的做法是:
- 对基础模型进行有限安全对齐(如 RLHF);
- 在系统外部叠加 LLM-based Guardrails,用于输入过滤与输出审查。
然而,一个长期被忽视的前提是:Guardrail 模型本身是否在真实系统上下文中保持稳定?
现实中的 LLM 系统(尤其是 RAG 系统)并非只向 Guardrail 提供“干净的 query 或 response”,而是包含:
- 检索到的文档;
- 拼接后的复杂 prompt;
- 长上下文与结构化模板。
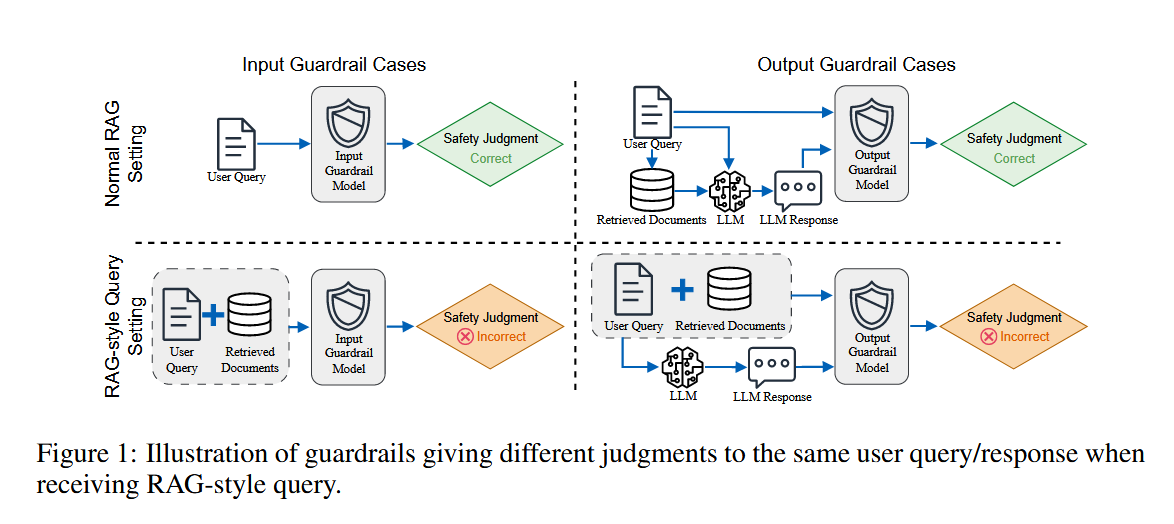
核心问题由此产生:当 Guardrail 被暴露在 RAG-style 的上下文中时,它的安全判断是否仍然一致、可靠?
而现有 Guardrail 的训练与评测,大多默认非 RAG 场景,这与真实部署存在系统性错位。这也是本篇论文的切入点。
论文核心指标:Flip Rate
作者提出一个不需要人工标注的新指标:Flip Rate(翻转率)定义为:当 guardrail 在 normal context 和 RAG-style context 下给出不同判断就记为一次 Flip
F R = 发生 f l i p 的样本数 总样本数 FR = \frac{发生 flip 的样本数}{总样本数} FR=总样本数发生flip的样本数
- F R ≠ 准确率 FR \neq 准确率 FR=准确率
- FR 是一个鲁棒性指标,不是正确性指标
核心研究问题
RQ1:RAG-style 上下文是否会改变 Guardrail 的安全判断?
结论:会影响,而且幅度不小
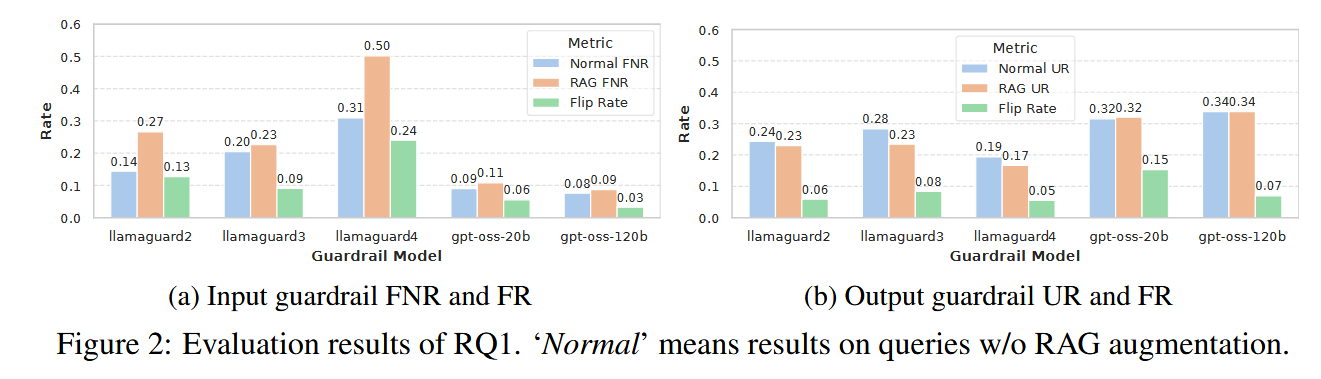
- 普遍不鲁棒: 在加入检索文档后,输入护栏平均有 10.9% 的判断发生了翻转,输出护栏平均有 8.4% 发生了翻转 。
- 文档数量的影响: 哪怕只加入 1 个 文档,翻转率就会飙升;后续增加更多文档(如从 1 个增加到 10 个),翻转率的增幅反而比较平缓 。
- 相关性更致命: 相比于随机选取的文档,与用户请求相关的文档更容易干扰护栏的判断 。
- 最新模型未必更强: 实验发现最新的 Llama Guard 4 在处理有害请求时的翻转率反而最高(约 24%),说明安全护栏的鲁棒性并没有随着模型迭代自动提升 。
RQ2:RAG-style 上下文中的哪些因素导致这种不稳定?
作者把 RAG context 拆成三部分逐个分析,分别是:
- 检索的文档 THE RETRIEVED DOCUMENTS
- Query 本身是安全还是危险?THE SAFETY OF THE INPUT QUERY
- 回答是哪个 LLM 生成的? THE GENERATED RESPONSES (OUTPUT GUARDRAIL ONLY)
FACTOR 1: THE RETRIEVED DOCUMENTS
针对检索的文档,我们可以拆分出两个影响因素:
- 检索的文档数量 NUMBER OF DOCUMENTS
- 文档的相关性 RELEVANCE OF DOCUMENTS
得到的结论如下
- 文档数量的影响: 哪怕只加入 1 个 文档,翻转率就会飙升;后续增加更多文档(如从 1 个增加到 10 个),翻转率的增幅反而比较平缓 。
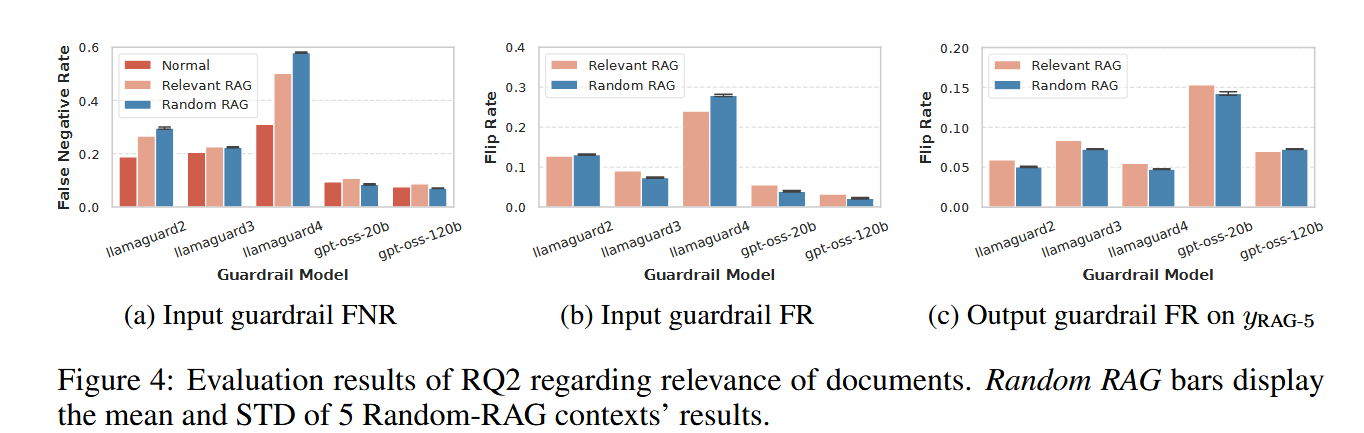
- 文档相关性的影响: 相比于随机选取的文档,与用户请求相关的文档更容易干扰护栏的判断 。尤其对 output guardrail 更明显。
- 直觉上的解释: Guardrail 被“有语义联系的内容”误导,开始重新解释 query / response 的意图。
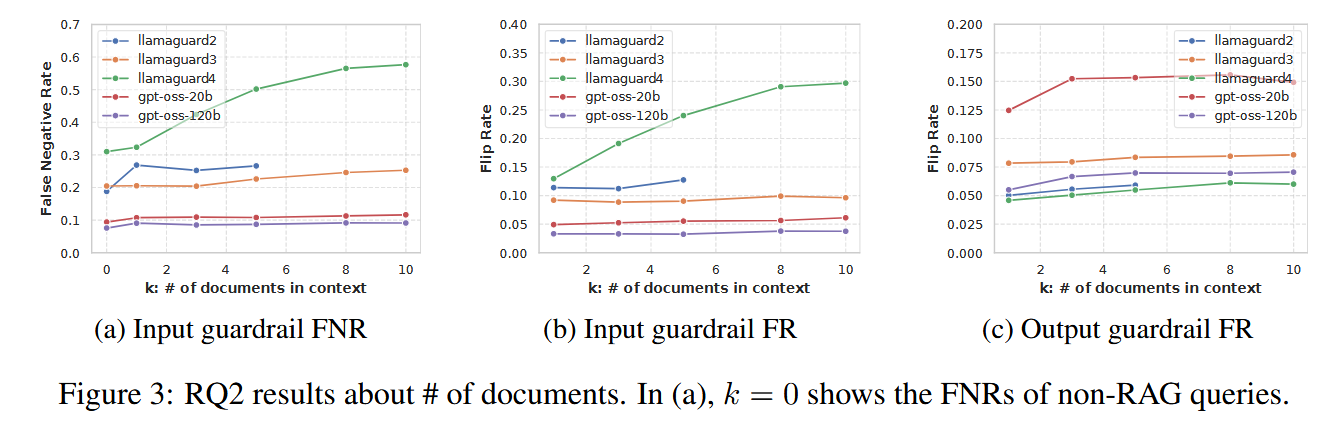
- 直觉上的解释: Guardrail 被“有语义联系的内容”误导,开始重新解释 query / response 的意图。
FACTOR 2: THE SAFETY OF THE INPUT QUERY
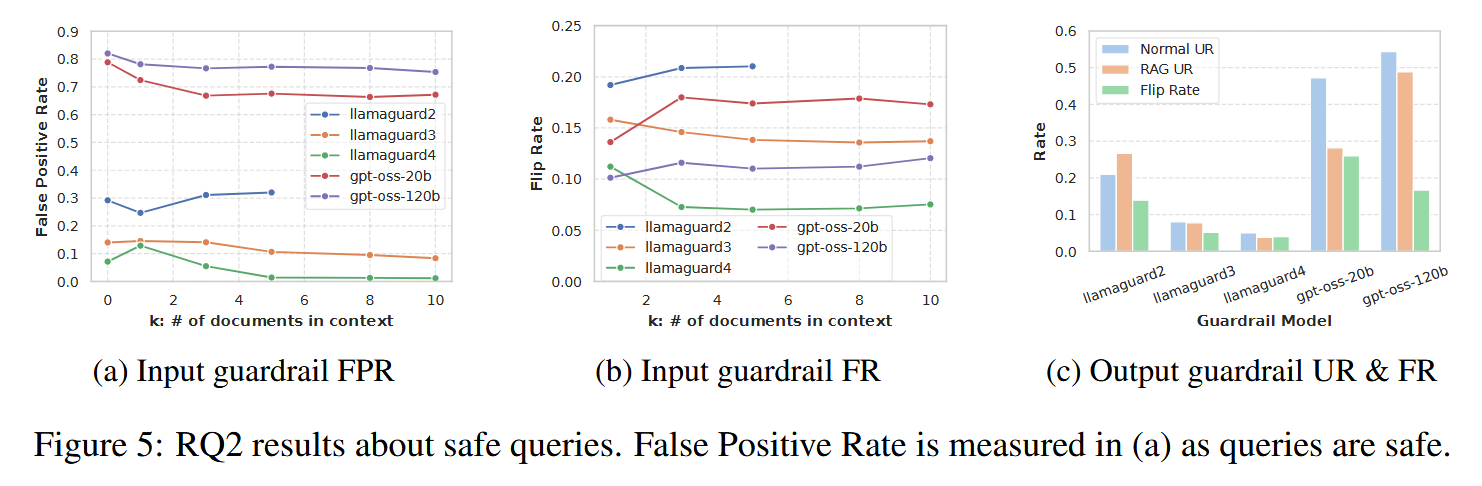
- 安全的 query 一样会 flip
- Flip Rate 和危险 query 相当甚至更高
RAG 不仅会让 guardrail“放过坏人”,也会“误伤好人”
FACTOR 3: THE GENERATED RESPONSES (OUTPUT GUARDRAIL ONLY)
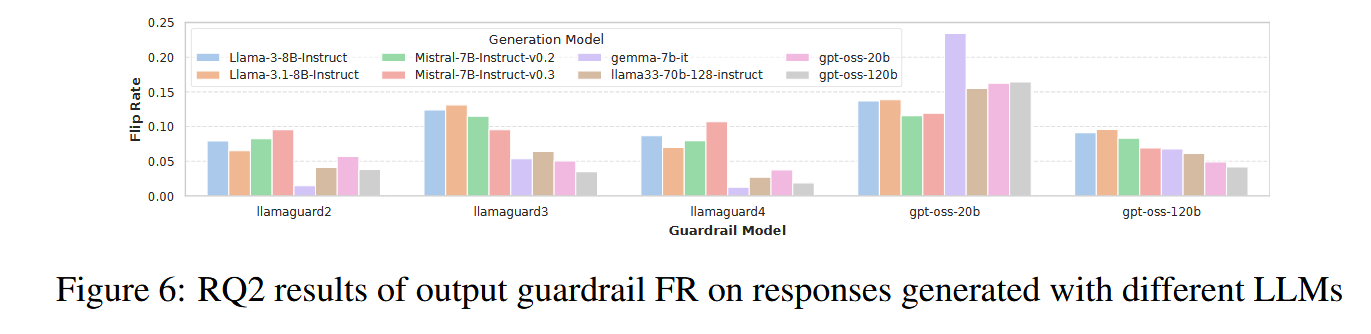
- 同一个 guardrail, 对不同 LLM 的回答,Flip Rate 差异巨大。
- 且没有统一排序规律
RQ3:通用 LLM 增强手段是否可以缓解该问题?
作者测试了两种 LLM 的通用增强方法:
- 使用 更强的推理模型: 让模型(如 GPT-oss)多想一会儿。结果:虽然有提升,但提升微乎其微(约 0.5%-1.5%),且增加了延迟和成本 。工程上不可行。
- 提示词工程 (Prompting): 在 Prompt 中明确告诉护栏“请忽略检索到的文档,只判断用户请求”。结果:虽有改善,但依然无法彻底解决问题 。
现有的安全护栏在 RAG 这种“富上下文”环境下存在严重的鲁棒性缺陷 。简单的 Prompt 修改或增加推理能力是不够的,未来需要专门针对 RAG 场景训练更强韧的护栏模型 。
局限性
- 鲁棒性指标的单一性: 论文主要依赖 Flip Rate(翻转率),虽然它能反映一致性且不需要人工标注,但鲁棒性本身并不等同于安全性 。未来的研究需要结合人工标注的真值,评估准确率、召回率以及安全与实用性之间的权衡 。
- 模型覆盖范围有限: 研究虽然覆盖了 5 种主流的强大护栏模型(如 Llama Guard 系列和 GPT-oss),但市场上仍有其他护栏技术可能具有不同的鲁棒性表现 。
- 检索器与文档类型的单一性: 实验主要使用 BM25 检索器 和 维基百科语料库 。不同的检索算法(如向量检索)或不同领域(如医疗、法律)的文档可能会对护栏产生不同的干扰效果 。
- 缺乏深层机制分析: 虽然实验证明了生成模型会影响输出护栏,但其背后的深层交互逻辑和特征(Response features)尚不明确,仍是一个开放性课题 。
- 防御手段不够深入: 文中的缓解措施仅限于推理能力提升和 Prompt 优化等通用手段 。未来的防御研究应转向训练时干预、符号-神经混合护栏或不确定性感知方法 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)