TileLang:一种用于AI 系统的可组合分块编程模型
25年4月来自北大、英国ICL和微软北京研究院的论文“TileLang: A Composable Tiled Programming Model for AI Systems”。现代AI工作负载高度依赖于经过优化的计算内核进行训练和推理。这些AI内核遵循明确的数据流模式,例如在DRAM和SRAM之间移动数据块,并对这些数据块执行一系列计算。然而,尽管这些模式清晰明了,编写高性能内核仍然十分复杂。
25年4月来自北大、英国ICL和微软北京研究院的论文“TileLang: A Composable Tiled Programming Model for AI Systems”。
现代AI工作负载高度依赖于经过优化的计算内核进行训练和推理。这些AI内核遵循明确的数据流模式,例如在DRAM和SRAM之间移动数据块,并对这些数据块执行一系列计算。然而,尽管这些模式清晰明了,编写高性能内核仍然十分复杂。要实现最佳性能,需要进行细致的、以硬件为中心的优化,以充分利用现代加速器。虽然特定领域的编译器试图减轻编写高性能内核的负担,但它们通常存在可用性和表达能力方面的不足。
本文提出一种名为TileLang的通用分块(tiled)编程模型,旨在提高 AI内核的编程效率。TileLang将调度空间(线程绑定、布局、张量化和流水线)与数据流解耦,并将它们封装成一组自定义注解和原语。这种方法允许用户专注于内核的数据流本身,而将大部分其他优化工作留给编译器。在常用设备上进行全面的实验,评估表明 TileLang 能够在关键内核中实现最先进的性能,证明其统一的“块-和-线程”范式以及透明的调度能力,能够提供现代 AI 系统开发所需的强大功能和灵活性。
过去几年,对AI工作负载更高性能的追求[13, 16, 17, 23]加速专用内核[4, 6, 11, 12]的开发,这些内核驱动着训练和推理。特别是矩阵乘法,它是从简单的前馈层到大规模Transformer模型等各种神经网络架构的基础。为了解决这些网络巨大的计算负担,诸如FlashAttention[19]之类的定制内核应运而生,用于优化注意机制,降低内存开销并提高处理吞吐量。然而,在不断发展的加速器硬件上实现高效率取决于硬件感知设计和精细调优的巧妙结合——这些挑战促使人们对更具表现力的领域特定编译器产生越来越浓厚的兴趣。
深度学习内核通常以数据流模式的形式呈现,涉及在DRAM和SRAM之间移动数据块,并在这些数据块上执行一系列计算。尽管这些模式看似清晰,但构建高性能内核仍然充满挑战,因为开发人员必须手动处理几个关键的优化问题:
• 线程绑定(Thread Binding)。绑定是指将数据块操作和数据映射到相应线程的过程。在现代加速器架构(例如GPU)中,这涉及到在线程块、线程束和单个线程之间仔细分配任务,以最大限度地提高并行性并最大限度地减少负载不均衡。最佳绑定策略可以增强数据局部性,并减少与线程同步和发散相关的开销,从而有助于提高计算吞吐量。
• 内存布局(Memory Layout)。内存布局优化涉及对物理内存中的数据进行系统化的组织,以消除存储体冲突并确保高效的访问模式。正如最近的研究[14, 18]所示,此过程通常需要将自然的数据表示转换为与架构内存子系统相匹配的分块或块状格式。这种重组有助于合并访问和有效利用缓存,从而降低内存延迟并提升系统整体性能。
• 内置张量化(Intrinsic Tensorization)。利用内置函数意味着直接使用针对特定目标优化的性能优化指令。现代处理器和加速器提供诸如张量核心[2]和矩阵核心[1]等专用操作,可以同时执行多个算术运算,并提供向量复制和异步复制等机制来更好地利用带宽。使用这些内置指令需要精确管理数据类型、内存对齐和控制流,才能充分发挥硬件的计算能力,从而显著提升关键内核操作的速度。
• 流水线(Pipeline)。流水线是一种将数据传输与计算重叠进行以减少内存访问延迟的技术。通过同时调度数据传输和计算任务,流水线确保处理单元保持活动状态,并将因内存延迟导致的空闲时间降至最低。在先进的Nvidia Hopper架构中,张量内存加速器(TMA)[10] 可以通过为不同的计算单元(例如CUDA核心和张量核心)启用异步处理来促进这一过程,从而进一步增强并发性。
尽管最近针对AI工作负载的特定域编译器[7, 24, 25]极大地简化高性能内核的创建,但即使显式地暴露数据流,它们仍然将大多数底层优化与内核实现紧密结合。例如,Triton[20]提供直观的块级原语,但将线程行为、内存布局和地址空间注释隐藏在自动生成的策略之后。这种抽象简化编程,但却阻止经验丰富的开发人员追求极致性能——例如,在实现带有量化权重的矩阵乘法时。此类内核通常需要在线汇编来执行向量化数据类型转换[15]以及与特定硬件内存缓冲区精心对齐的自定义数据布局[21]。尽管 Triton 提供诸如 tl.dot 之类的向量化操作,但将其扩展到特定用例(例如,通过 PTX 注册手工打造的高性能 tile 算子)仍然十分繁琐。此外,即使 Triton 提供一个用户友好的流水线参数(num_stage),它也不允许用户定义完全自定义的流水线。因此,域专家在开发需要显式控制内存层次结构和其他细粒度优化的内核时会受到限制。
为了解决这些限制,提出 TileLang,一种在保持 Triton 简洁性的同时提供更大灵活性的编程模型。TileLang 旨在为用户提供对调度空间的细粒度控制,以实现更高的性能。实现这一目标的关键在于数据流和调度的解耦:用户只需专注于使用可组合的 tile 算子定义数据流,而编译器则负责探索和应用调度策略。当编译器的默认优化不足以满足需求时,用户可以在前端进行更精确的控制。引入一种可组合的分块编程抽象,其中核心计算模式(例如 GEMM、COPY、ATOMIC 和 REDUCE)使用分块算子来表达。这些运算符定义了内核的数据流,而无需考虑调度决策。同时,还提供一组调度原语和注解来捕获进一步的优化,使用户可以选择依赖编译器生成的调度,或者手动微调内核中对性能至关重要的方面。
为了提升 TileLang 的易用性,用 Python 实现前端语言,使其拥有灵活的编程风格和最少的类型注解。此外,还引一个 TileLang 编译器,它可以将用户自定义程序转换为高度优化的底层代码,从而在现代硬件上高效执行。该编译器能够自动进行关键优化,减少性能调优所需的人工工作量。
以下基于tile编程模型的基础知识,解释 TileLang 如何系统地高效管理 AI 内核开发,并概述 TileLang 将数据流与其他调度空间分离的设计理念。
如图展示 TileLang 的五阶段编译流程。首先,开发者使用 TileLang 编写高级程序来描述计算逻辑和数据访问模式。在解析器阶段,TileLang 程序被解析为 Python 抽象语法树 (AST),随后转换为 TileLang AST。接下来,中间表示构建器将 AST 转换为 TVM 中间表示 (IR),从而能够利用 TVM 的语法树和相关基础架构。之后,优化阶段执行一系列图优化和调度转换,以提高执行效率。最后,代码生成阶段将优化后的 IR 转换为后端代码,例如 LLVM IR、CUDA C/C++ 或 HIP C/C++,以支持各种硬件平台。
下表展示 TileLang 提供的部分数据流算子和调度原语。Tile 语言采用以数据为中心的编程范式,其核心计算语义通过诸如 T.copy、T.gemm 和 T.reduce 等 tile 级算子来表达。作为这些算子的补充,TileLang 还提供一组调度原语,允许开发者微调并行性、流水线和内存布局等对性能至关重要的方面。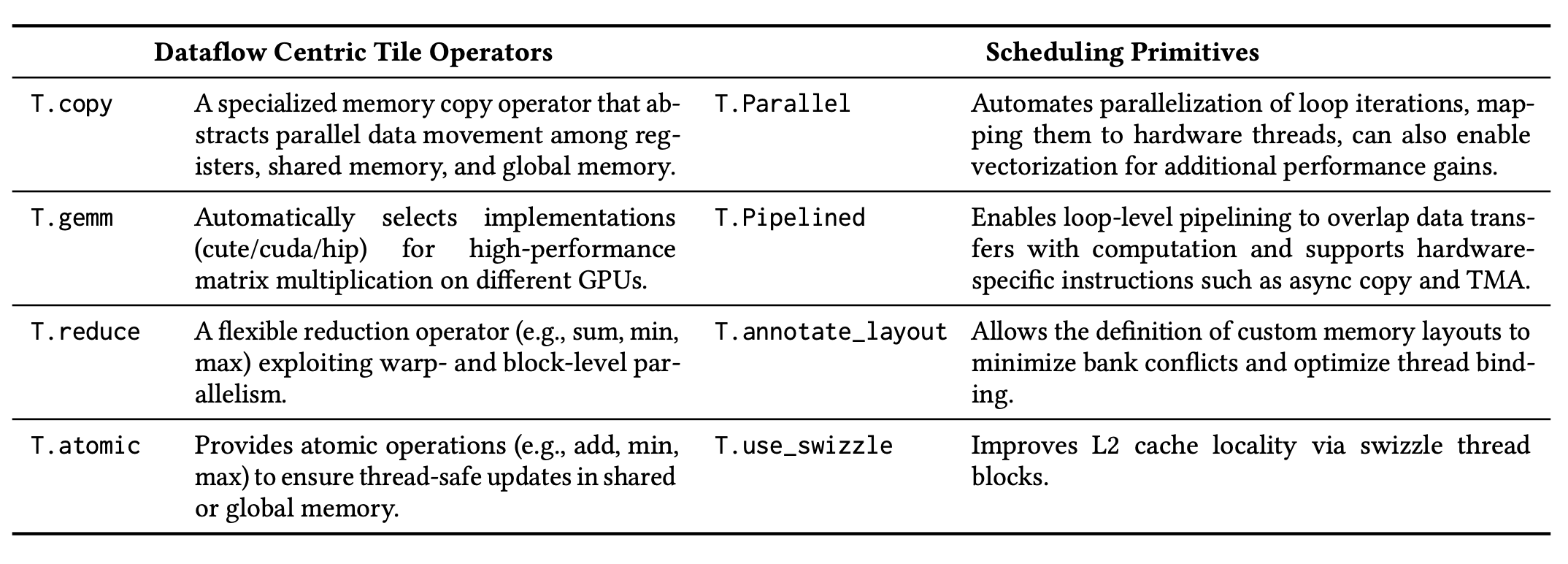
基于分块(tile)的编程模型
如图提供一个简洁的 TileLang 矩阵乘法 (GEMM) 示例,展示了开发者如何利用分块、内存放置、流水线和算子调用等高级结构,以精细化的方式管理数据移动和计算。特别是,图 (a) 中的代码片段演示多级分块如何利用不同的内存层次结构(全局、共享和寄存器)来优化带宽利用率并降低延迟。总而言之,图 (b) 展示 TileLang 类似 Python 的语法如何让开发者在一个用户友好的编程模型中思考性能关键型优化问题。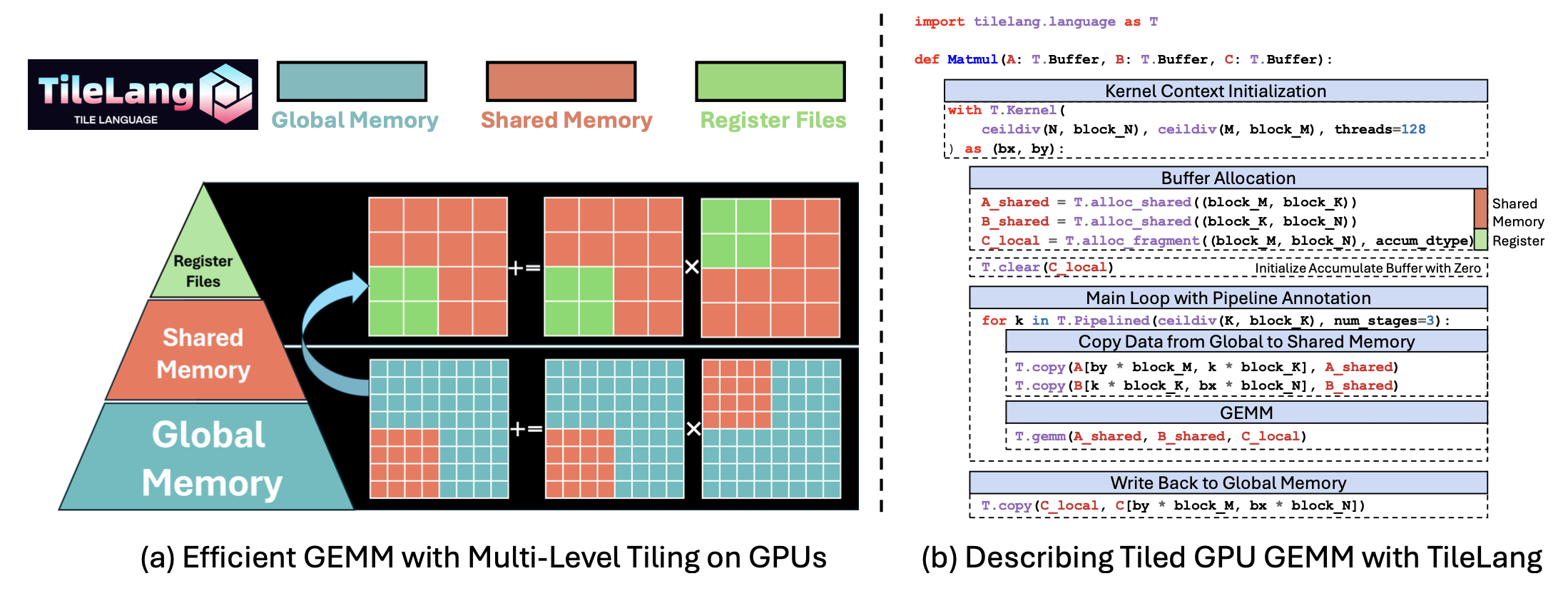
Tile 声明。方法的核心在于将tile视为编程模型中的一级对象。tile 代表一段经过特殊处理的数据,可以由线程束、线程块或等效的并行单元拥有和操作。在 Matmul 示例中,A 和 B 缓冲区在内核循环中以tiled块(由 block_M、block_N 和 block_K 确定)的形式读取。TileLang 通过 T.Kernel 定义执行上下文,其中包括线程块索引(bx 和 by)以及线程数。这些上下文可以帮助计算每个线程块的索引,从而使 TileLang 更容易自动推断和优化内存访问和计算。此外,这些上下文还允许用户手动控制线程块中每个独立线程的行为。
显式硬件内存分配。TileLang 的一个显著特点是能够将这些tile缓冲区显式地放置在硬件内存层次结构中。 TileLang 并没有依赖编译器不透明的优化过程,而是公开用户可直接访问的内置函数,这些函数直接映射到物理内存空间或特定于加速器的结构。具体来说:
T.alloc_shared:在快速的片上存储空间中分配内存,这对应于 NVIDIA GPU 上的共享内存。共享内存非常适合在计算过程中缓存中间数据,因为它比全局内存快得多,并且允许在同一线程块中的线程之间高效地共享数据。例如,在矩阵乘法中,可以将矩阵的分块加载到共享内存中,以减少对全局内存带宽的需求并提高性能。
T.alloc_fragment:在片段内存中分配累加器,这对应于 NVIDIA GPU 上的寄存器文件。通过将输入和部分和保存在寄存器或硬件级缓存中,可以进一步降低延迟。请注意,在这个 tile 程序中,每个 tile 都分配与共享内存相同的本地缓冲区,这可能看起来有悖常理,因为共享内存通常速度更快但容量更大,而寄存器文件是有限的。这是因为此处的分配指的是整个线程块的寄存器文件。TileLang 在编译期间使用布局推断过程来派生布局对象 T.Fragment,该对象决定如何为每个线程分配相应的寄存器文件。
全局内存和硬件特定内存之间的数据传输可以使用 T.copy 进行管理。此外,可以使用 T.clear 或 T.fill 初始化硬件特定缓冲区。对于数据赋值,还可以使用 T.Parallel 并行执行操作。
以数据流为中心的 Tile 算子
TileLang 抽象一组 Tile 算子,使开发人员能够专注于数据流逻辑,而无需管理每个 Tile 操作的底层实现细节。如图 展示 Tile 算子的接口以及几个代表性示例,包括 GEMM、Copy 和 Parallel。每个 Tile 算子都需要实现两个关键接口:Lower 和 InferLayout。Lower 接口定义如何将高级 Tile 算子降低到低级中间表示 (IR),例如线程绑定或向量化内存访问。例如,Copy 算子可以降低到一个带有显式线程绑定和向量化加载/存储的循环中。InferLayout 接口负责确定与 Tile 算子关联的内存和循环布局。这包括推断缓冲区布局(例如,内存交换)或循环级布局(例如,线程绑定)。例如,T.gemm 算子对其共享内存输入应用内存交换布局,并使用矩阵特定的布局来写回 MMA 片段。类似地,T.Parallel 中的并行循环结构可以使用线程级绑定和向量化访问模式来表示,这两者都是通过布局推断得到的。
上表列出 TileLang 算子的一个子集,用于简化基于 tile 的编程中的常见操作。这些内置算子抽象硬件内存访问和计算的底层细节,使开发人员能够从数据流的角度专注于高级算法设计,同时保持对性能关键方面的精细控制。每个算子都旨在与 tile 编程模型无缝集成,确保跨硬件内存层次结构的高效数据移动和计算。下面介绍几个关键算子及其在优化内存传输和算术运算中的作用。
copy:copy 算子是 T.Parallel 的内存复制sugar语法,允许从寄存器的片段作用域、静态共享内存的共享作用域、动态共享内存的 shared.dyn 作用域以及全局内存进行复制。
gemm:内置的 T.gemm 算子是针对通用矩阵乘法的高度优化实现,支持各种内存访问模式(ss、sr、rs、rr),其中 r 表示寄存器内存,s 表示共享内存。该算子会根据内核配置自动选择最佳实现。对于 CUDA 后端,T.gemm 利用 Nvidia 的 CUTLASS 库高效地使用 Tensor Core 或 CUDA Core;而对于 AMD GPU,它则同时采用可组合内核和手写的 HIP 代码进行性能优化。用户还可以通过在 Python 中注册自定义原语来扩展 T.gemm,使其能够灵活地适应特定用例。
reduce:T.reduce 算子提供一种灵活高效的归约机制,用于跨维度聚合数据。它支持多种归约操作,例如求和、最小值、最大值和乘积等。归约操作可以沿指定轴执行,从而实现矩阵的行归约或列归约等操作。T.reduce 的实现利用 warp 级和块级并行性,以在 CUDA 和 AMD 后端上实现最佳性能。用户还可以通过定义自己的归约内核来定制归约操作。
atomic:T.atomic 算子为并行上下文中的共享内存或全局内存的安全更新提供原子操作。常见的原子操作,例如 add、min 和 max,都已开箱即用地支持。T.atomic 确保并发更新期间的线程安全,因此对于直方图更新、共享内存的归约操作以及无需同步的计数器等操作至关重要。它旨在利用 NVIDIA 和 AMD GPU 上的原生硬件原子指令,从而在并行执行时确保高性能和正确性。
调度注解和原语
数据流模式构成了计算组织的基础,而现代高性能计算则需要对执行模式进行更精细的控制。为了满足这一需求,Tile-Lang 提供了一套全面的调度原语,使开发人员能够精确地调整应用程序的性能关键方面,如上表所示:
流水线式:T.Pipelined 原语允许高效地流水线式执行循环,通过重叠计算和内存操作来提高性能。在上面例子中,遍历 k(归约维度)的循环使用 num_stages = 3 进行流水线化,创建一个 3 阶段流水线。该流水线允许数据传输、计算和后续数据准备重叠执行,从而有效地减少内存瓶颈并提高计算吞吐量。
并行式:T.Parallel 原语通过将迭代映射到线程来实现循环的自动并行化。比如举例,将数据复制到 A_shared 的操作使用 T.Parallel(8, 32) 在 8 维和 32 维上进行并行化。它不仅利用硬件并行性提高了性能,还自动将线程映射到迭代,并支持向量化以进行进一步优化。
标注布局:T.annotate_layout 原语允许使用用户定义的内存布局为共享内存或全局内存指定内存布局优化。默认情况下,TileLang 采用优化的内存布局,旨在最大限度地减少 Nvidia 和 AMD GPU 上的库(bank)冲突。
使用交换:T.use_swizzle 原语通过启用内存交换来提高 L2 缓存局部性,从而提高光栅化的数据重用率。当在并行线程块中处理分块数据时,此原语尤其有效。
以下讨论除数据流之外,TileLang 中四种调度空间及其自动化设计。其中一些相对独立(例如流水线和张量化),而另一些则耦合性更强,例如线程绑定和内存布局设计。
内存布局组成
在 TileLang 中,支持使用诸如 A[i, k] 之类的高级接口对多维数组进行索引。这种高级索引最终通过一系列软件和硬件抽象层转换为物理内存地址。为了对这种索引转换过程进行建模,引入关键抽象概念布局(Layout),它描述数据在内存中的组织和映射方式。
在物理地址层面,布局可以表示为形如 sum(𝑦_i 𝑠_i) 的线性化地址表达式,其中 𝑦_i 表示沿第 𝑖 个维度的索引,而 𝑠_i 是该维度对整体线性内存地址的贡献步长。给定布局 𝐿 = 𝑠 : 𝑑 = (𝑠_0, 𝑠_1, . . . , 𝑠_𝑛−1) : (𝑑_0, 𝑑_1, . . . , 𝑑_𝑛−1),TileLang 采用受 TVM [8] 启发的设计,引入一种基于 IterVar 的可组合、可堆叠的布局函数抽象。由于 IterVar 可以封装步长信息,布局表达式可以简化为 IterVar 的代数形式。因此,布局函数可以形式化地表示为映射 𝑓,其中 𝑓 编码从高级索引到内存地址的转换。
如图 (a) 展示 TileLang 中一个布局(LayOut)的定义。其核心组件包括 iter_vars,它可以选择性地携带范围信息,以及一组计算内存位置的forward_index表达式。这些表达式共同定义一个代数函数 f。如图 (b) 所示,这可以表达从二维到一维的布局转换。给定缓冲区的形状,iter_vars 被绑定到特定的区域,并将生成的表达式传递给算术分析器以确定符号或常量边界。这些边界用于推断转换后缓冲区的形状,并相应地调整缓冲区访问索引。TileLang 还支持非-双射(non-bijective)布局转换。例如,图 © 展示如何使用布局来对缓冲区访问应用填充。这些布局转换是可组合的,TileLang 包含多种内置布局策略,例如布局交换(Layout Swizzling),它常用于缓解 GPU 上的共享内存库冲突。
此外,TileLang 还引入布局(Layout)抽象的扩展,称为片段(Fragment)。与标准布局不同,一个片段布局(Fragment Layout)始终生成形如 𝑓 的输出,其中两个输出维度分别表示线程在寄存器文件中的位置和本地寄存器文件的索引。例如,内核在块级别分配一个寄存器文件 𝐶_local。然而,由于 GPU 寄存器文件必须在块内的各个线程之间进行分区,片段布局(Fragment Layout)可以准确地描述这种分区方案。
下图 (a) 展示片段布局(Fragment Layout)的定义,TileLang 提供四个基本操作来帮助用户扩展现有的片段布局。下图 (b) 展示如何使用这些原语从 mma_ldmatrix 指令中用于 m16k16 矩阵片段的基本布局派生出完整的块级布局。这里,base_layout 表示单个 warp 消耗 m16k16 矩阵的布局。该布局通过 repeat 原语扩展形成 warp_layout,从而允许单个 warp 消耗 m32k16 矩阵。下图 © 可视化这一转换过程。然后,warp_layout 使用 repeat_on_thread 和 replicate 等原语进一步扩展,生成 block_layout,该布局表示四个 warp 共同消耗 m128k16 矩阵。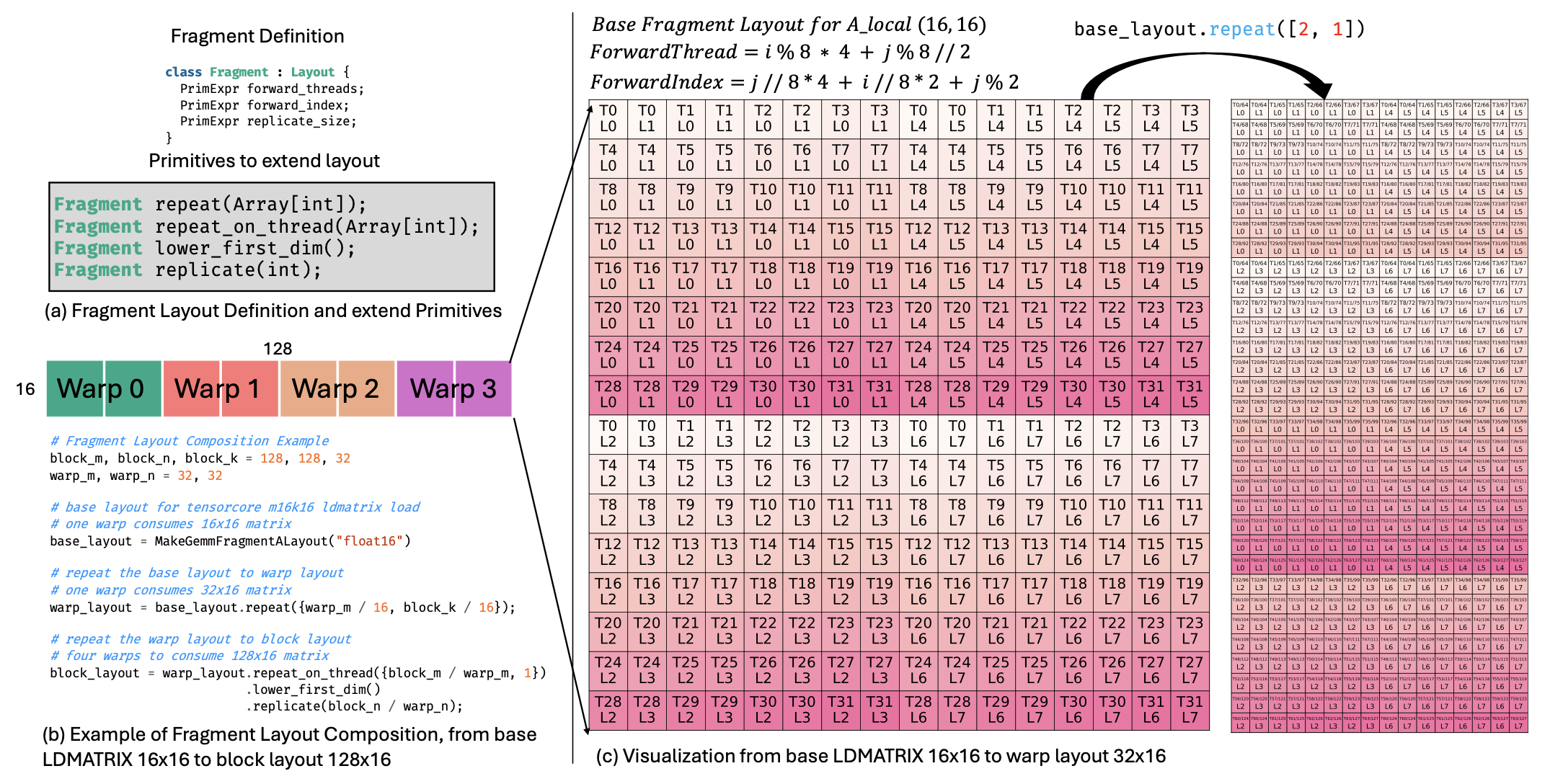
线程绑定
基于片段布局(Fragment Layout)的抽象,一个关键挑战是如何在执行期间将这些布局映射到线程上。这就引出了线程绑定问题,该问题涉及如何将块级寄存器文件分配给各个线程,以及如何推断合适的片段布局(Fragment Layout)。此外,还需要确定如何正确地并行化循环以匹配布局约束。
虽然前面引入片段布局(Fragment Layout)来简化这一过程,但对于任意计算表达式,确定所有缓冲区的合适片段布局(Fragment Layout)仍然很困难。本文提出两个关键观察结果来指导这一过程。首先,由于多个 tile 算子通常共享相同的缓冲区,因此它们各自的布局和线程绑定策略是相互依赖的。其次,布局和线程绑定要求的严格程度因操作符而异。例如,在 GPU 上,GEMM 算子(利用 Tensor Core)对布局和线程绑定都施加严格的约束,而元素级算子通常允许更大的灵活性。
基于这些观察,其提出一种基于布局(Layout)和片段(Fragment)对象的推理方案,以优化缓冲区布局和线程绑定。为了系统地管理缓冲区布局,维护一个布局图(LayoutMap),用于记录所有缓冲区的布局信息。为tile算子布局定义一个分层优先级系统,其中优先级越高,表示布局要求越严格,性能影响越大。TileLang 以自顶向下的方式处理布局推理,从最高优先级到最低优先级依次推理布局。在每个优先级级别,TileLang 会尝试推理所有未确定缓冲区的布局,直到无法继续推理为止,然后再进入下一个较低的优先级级别。
如图所示,考虑这样一种场景:矩阵 C 表示 GEMM 操作的结果,对应于一个片段(Fragment)对象,该对象需要在 GEMM 计算后添加偏置项 D。由于 GEMM 在推理过程中具有最高优先级,其线程绑定配置是预先确定的,而 D 的线程绑定策略仍待确定。输出矩阵 C 的维度为 4×4,分布在 8 个线程中,每个线程负责处理 2 个元素。因此,偏置缓冲区 D 的布局必须与此配置相匹配。由于张量 C 的每一行都由 2 个线程处理,因此两个线程都需要访问 D 中的相同元素来进行加法运算。所以,必须复制 D 以确保每个线程都能访问到对应的元素。D 的布局可以使用相同的方法推断出来。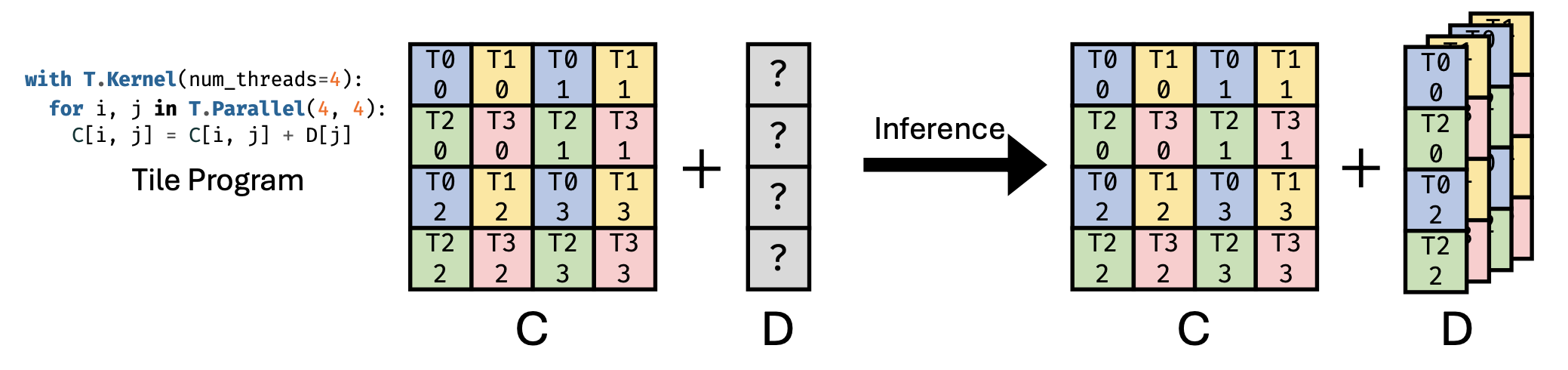
下图展示线程绑定推断过程的一个示例。具体来说,图 (a) 展示一个简单的数据复制代码片段,描述从全局内存到共享内存子图块的数据流。正确的线程绑定和向量化访问可以充分利用 GPU 的并行性,并发挥高性能内存访问指令的优势。在图 (b) 中,T.copy 操作被扩展为多个循环(loop)轴。应用布局推断过程后,如图 © 所示,程序将进行自动向量化和并行化。最后,在图 8(d) 所示的阶段,应用布局交换(Fragment Swizzling)。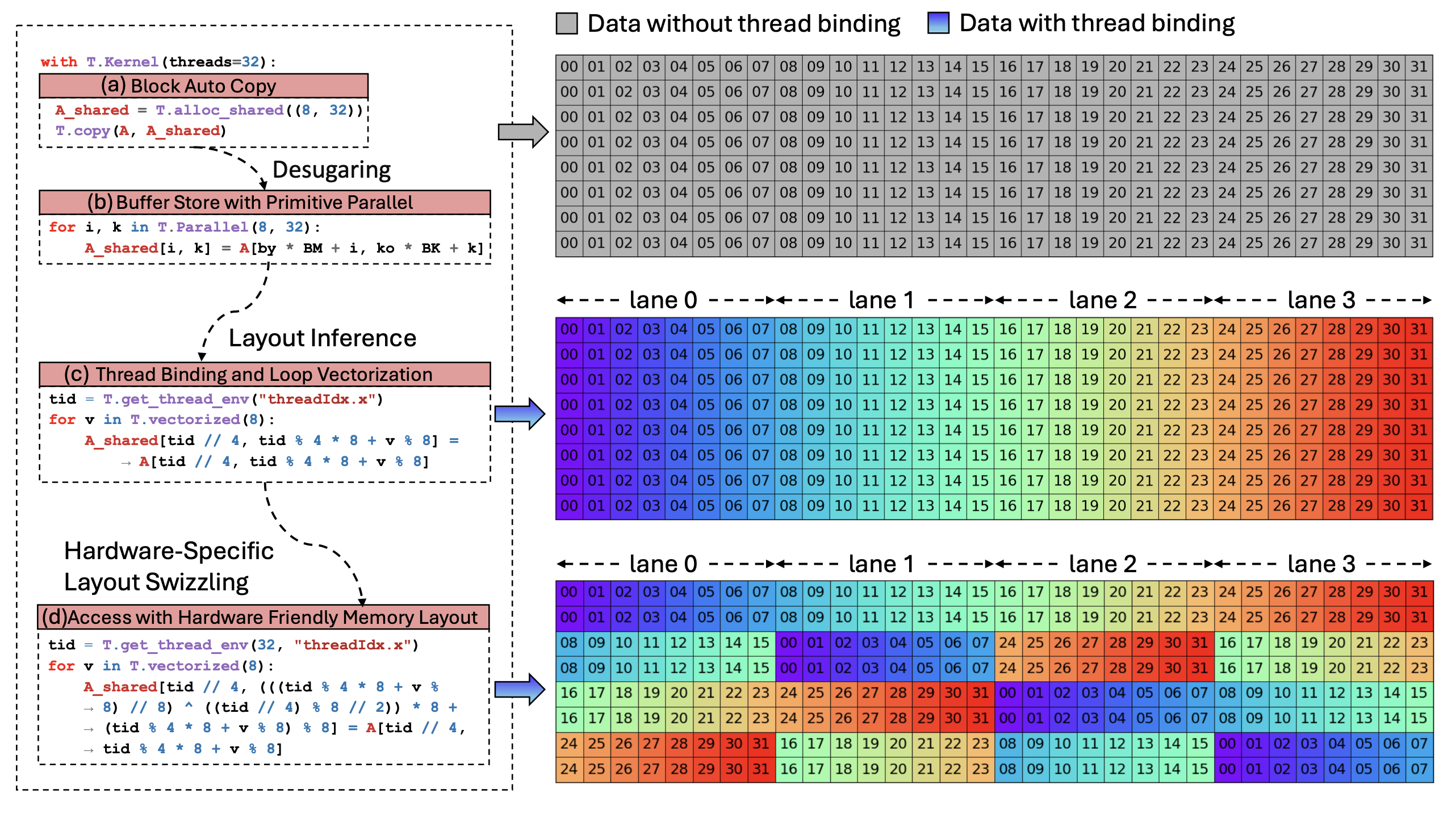
利用高性能硬件指令
现代硬件架构通常支持多条指令路径来实现相同的计算操作,如图所示DP4A指令和MMA指令。例如,在 NVIDIA GPU 上,一个 8 位乘加运算可以通过多种指令实现。IMAD 指令执行标量融合乘加运算,计算 𝑑 = 𝑎 · 𝑏 + 𝑐,其中所有操作数在内部都会被提升为 32 位整数进行计算。DP4A 指令支持向量化的点积运算,计算 𝑑 = ⟨a, b⟩ + 𝑐 = sum (𝑎_i 𝑏_i) + 𝑐,其中 a 和 b 是长度为 4 的 8 位整数向量,偏置项 𝑐 和输出 𝑑 均以 32 位整数精度表示。对于高吞吐量的矩阵计算,MMA 指令利用张量核心执行 D = A · B + C;其中,A 和 B 是 8 位整数矩阵,而 C 和累积结果 D 使用 32 位整数精度。在 NVIDIA RTX 3090 GPU 上,这些指令的吞吐量分别约为 17.8 TOPS、71.2 TOPS 和 284 TOPS。此外,MMA 指令在相同的精度设置下支持各种形状的矩阵。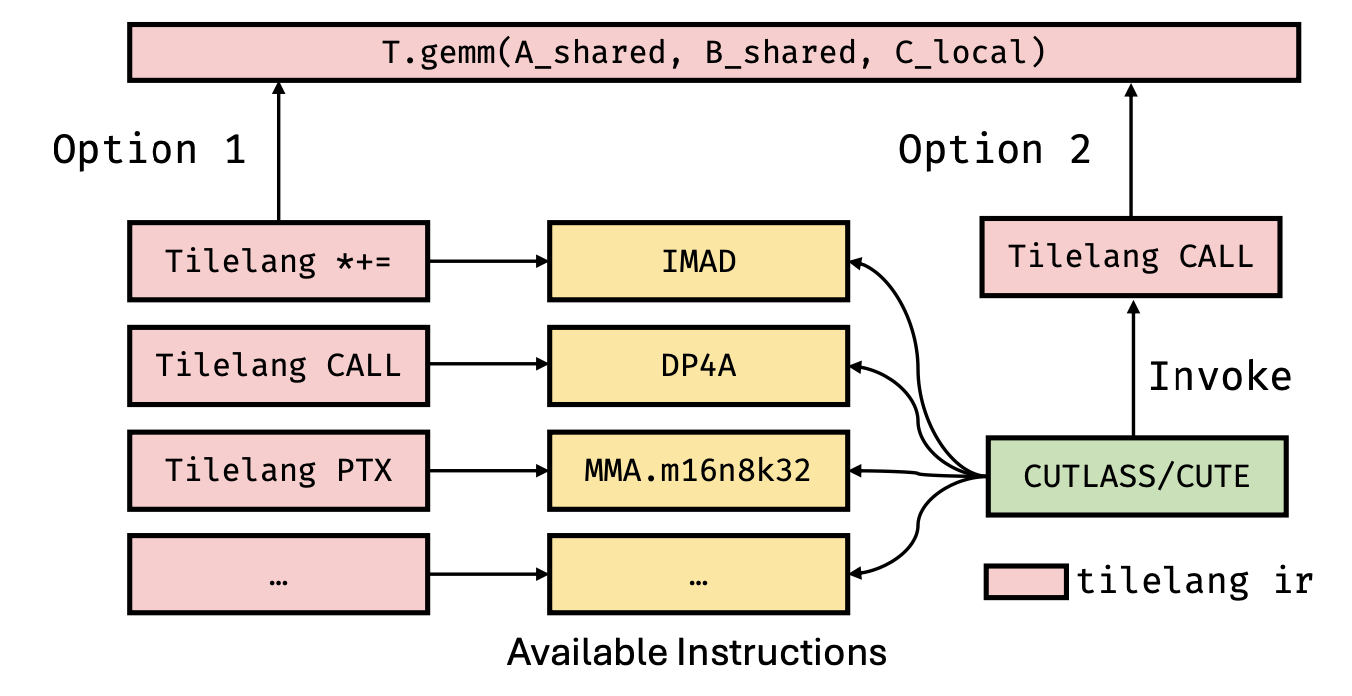
在 TileLang 中,如下图 (a) 和 (b) 所示,调用硬件张量指令有两种方法。第一种方法(图 (a))使用 C++ 源代码注入,其中像 dp4a 这样的指令使用 C++ 模板手动封装,并通过 T.import_source 和 T.call_extern 注入到内核中。这既实现底层控制,又利用熟悉的 C 风格语法。注入的函数定义在生成的代码开头,并在内核中调用。或者,如图 (b) 所示,TileLang 提供一个内置的 T.ptx 原语,允许在内核中直接发出在线 PTX 指令(例如MMA,mma.m16n8k32.row.col.s32.s8.s8.s32)。这为使用专用指令(尤其适用于线程束级别的操作)提供另一种底层机制。然而,根据输入形状和数据类型选择最合适的指令可能颇具挑战性。为了简化这一过程,TileLang 还支持与 Tile 库集成,如图 © 所示。Tile 库(例如 NVIDIA 的 cute 或 AMD 的可组合内核 (ck))为 GEMM 等操作提供高级的、标准化的基于 tile API(例如 tl::gemm_ss)。这些库抽象特定于硬件的细节,并允许底层实现自动为给定的输入配置选择最高效的指令。在 TileLang 中,开发人员可以使用 T.call_extern 以简单一致的方式调用这些库。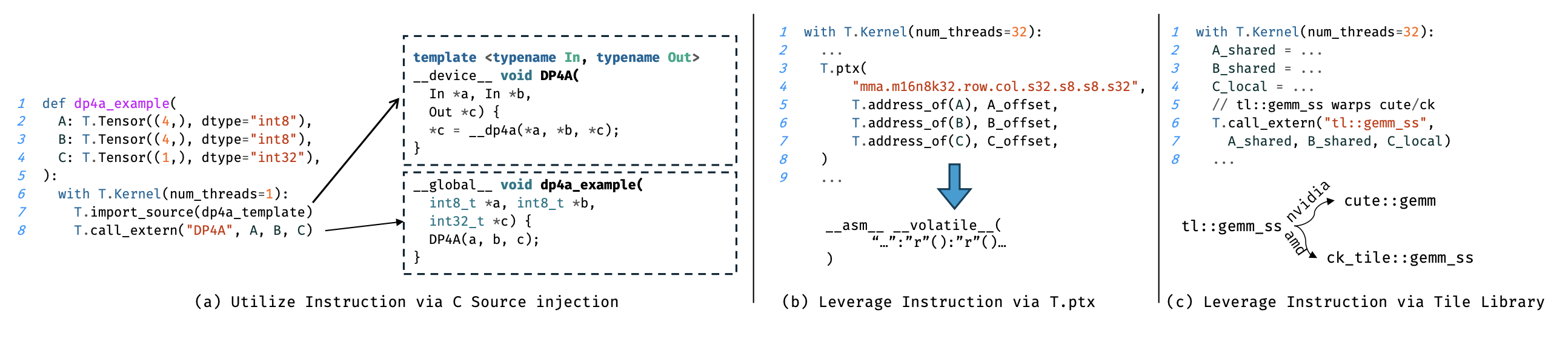
总而言之,TileLang 提供两种互补的方法来利用高性能指令。第一种方法是利用 Tile 库,这简化集成并受益于厂商优化的性能。然而,这种高级抽象可能会限制底层控制。例如,cute::gemm_ss 接口对共享内存输入执行 GEMM 操作,但从共享内存到寄存器的数据流由 cute 模板内部管理。这使得无法对内部布局进行外部注释或覆盖,从而降低了灵活性。此外,由于大量使用模板,编译速度可能会显著降低。使用 NVCC 12.8 跟踪工具进行的分析表明,对于 TileLang 生成的 CUDA 代码,模板展开大约占编译时间的 90%。
相比之下,TileLang 允许直接使用 TileLang 本身通过 T.gemm 实现指令。这避免布局注解的限制并缩短编译时间。然而,它要求用户为每个目标硬件指令在 TileLang 中实现完整的指令集。目前,TileLang 同时支持这两种方法,默认采用基于 Tile 库的方法,以便快速支持新的硬件指令。
软件定义流水线
TileLang 采用自动化的软件流水线推断机制来分析计算模块(例如本例中的 Copy 和 GEMM)之间的依赖关系,并生成结构化的流水线调度方案,以在保持正确执行顺序的同时最大限度地提高并行性,如图所示。具体而言,该机制将 Copy 任务与其他计算密集型操作交错执行,以减少空闲时间;当检测到异步处理的机会时,它会自动将这些任务映射到可用的硬件资源上,以实现并发执行。因此,TileLang 只需向用户公开一个 num_stages 接口,从而显著简化流程。但是也允许用户根据需要显式地提供有关顺序和阶段的信息。
对于 Ampere 架构,TileLang 使用 cp.async 指令支持异步内存复制操作。cp.async 指令能够快速地在全局内存和共享内存之间移动数据,从而实现内存传输与计算的重叠,进而提升性能。TileLang 通过分析循环结构并自动为符合条件的内存传输插入 cp.async 指令来实现这一功能。此外,TileLang 还确保正确使用 cp.async.commit 和 cp.async.wait 指令来处理同步,从而保证数据的正确性。这种优化尤其有效,因为它减轻了寄存器文件的压力,并能够更有效地利用硬件带宽。
在 Hopper 架构中,引入两个新特性。首先,引入一个新的 TMA 单元,作为专门负责全局内存和共享内存之间数据复制的硬件单元。其次,PTX 指令集引入新的 wgmma 指令,它允许由一个 warpgroup(由四个 warp 组成)执行矩阵乘法 (MMA) 操作,从而提高 TensorCore 的利用率。此外,wgmma.mma_async 指令是异步的。另外,Hopper 架构的内核优化通常采用 warp 特别化,将线程划分为生产者和消费者。生产者线程使用 TMA 来移动数据,而消费者线程负责计算。
在 TileLang 中,在降级过程时自动执行 warp 特别化优化。具体来说,TileLang 分析所有语句的缓冲区使用情况,并确定它们的角色(生产者或消费者)。基于此分析,生产者和消费者根据 threadIdx 被划分到不同的执行路径。为了确保计算的正确性,TileLang 利用实时变量分析来确定合适的同步点,并相应地插入内存屏障 (mbarrier)。
AMD CDNA 架构还提供异步复制指令和 DMA 支持,TileLang 通过 HIP 封装的复制原语来利用这些支持。具体来说,TileLang 使用诸如 s_waitcnt lgkmcnt 和 buffer_load_dword lds 之类的指令来高效地管理内存传输。这种集成使系统能够充分利用硬件在数据移动与计算重叠方面的能力,从而进一步提高流水线性能并减少空闲时间。
实验设置
硬件平台。分别在 NVIDIA 和 AMD GPU 上评估 TileLang,因为它们是目前应用最广泛的加速器之一。实验使用三款尖端 GPU:NVIDIA H100 (80 GB) [10]、NVIDIA A100 (80 GB) [9] 和 AMD Instinct MI300X (192 GB) [5]。NVIDIA H100 使用 CUDA 12.4;MI300X 使用 ROCm 6.1.0。所有平台均运行在 Ubuntu 20.04 系统下。
算子工作负载。评估 TileLang 在一系列常见于大规模深度学习流水线中算子工作负载上的性能。在 NVIDIA H100 上,重点关注多头注意机制 (MHA)、线性注意机制和通用矩阵乘法 (GEMM)。在 NVIDIA A100 上,测试去量化 GEMM 内核的性能。同时,在 AMD Instinct MI300X 上对 GEMM 和 MHA 进行基准测试,以涵盖不同 GPU 架构的代表性用例。这些工作负载构成许多现代神经网络模型(包括大型语言模型)的基础构建模块。
基准测试。为了评估 TileLang 的性能,将其与机器学习和 GPU 编程中广泛使用的几种最先进的基准测试进行比较。这些基准测试包括:FlashAttention-3,它针对多头注意机制进行优化,并支持 tma 和 wgmma.mma_async 等 CUDA 指令;Triton,一个用于高效 GPU 内核的开源框架,支持 Nvidia 和 AMD GPU,但需要手动优化;cuBLAS,NVIDIA 的高性能稠密线性代数库;AMD 的 BLAS 库 rocBLAS;以及 PyTorch,它具有像 GEMM 和 FlashAttention-2 这样的手动优化内核,但尚未完全优化。 BitsandBytes 专为支持 𝑊NF4𝐴FP16 等格式而设计,并提供高效的内核;而 Marlin 则针对 𝑊INT4𝐴FP16 计算进行了高度优化。此选择全面比较 TileLang 的各种优化策略和硬件兼容性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献169条内容
已为社区贡献169条内容

所有评论(0)