LLM - 跑大模型到底要多大显存?一文讲透从原理到实战
摘要: 大模型时代,显存成为能否运行模型的首要门槛。本文系统分析显存消耗的四大来源:模型参数、中间激活、KV Cache和框架开销,并针对推理、微调、训练场景给出显存估算方法。例如,7B模型FP16推理约需18GB显存,轻量微调需24GB,而全参数训练显存需求呈数量级增长。选型建议:本地玩家可选8-24GB显卡运行7B/13B量化模型,团队服务需24-48GB显存支持长上下文与并发。合理估算显存需
文章目录
概述
过去两年,大模型从云端走向本地,从实验室走向个人电脑,“显卡显存够不够”成了无数开发者的首要问题。很多人买卡前都会问两个问题:“这个模型多少 B?这张卡能不能跑?”以及“要几张卡、多少显存才能撑得住推理或微调?”
本文面向开发者、研究者与技术爱好者,系统梳理大模型显存到底花在了哪里,并给出一套从原理到实践可落地的显存估算与选型方法论,帮助你在购卡或选云服务器时做到心中有数。
一、显存为什么成了第一门槛
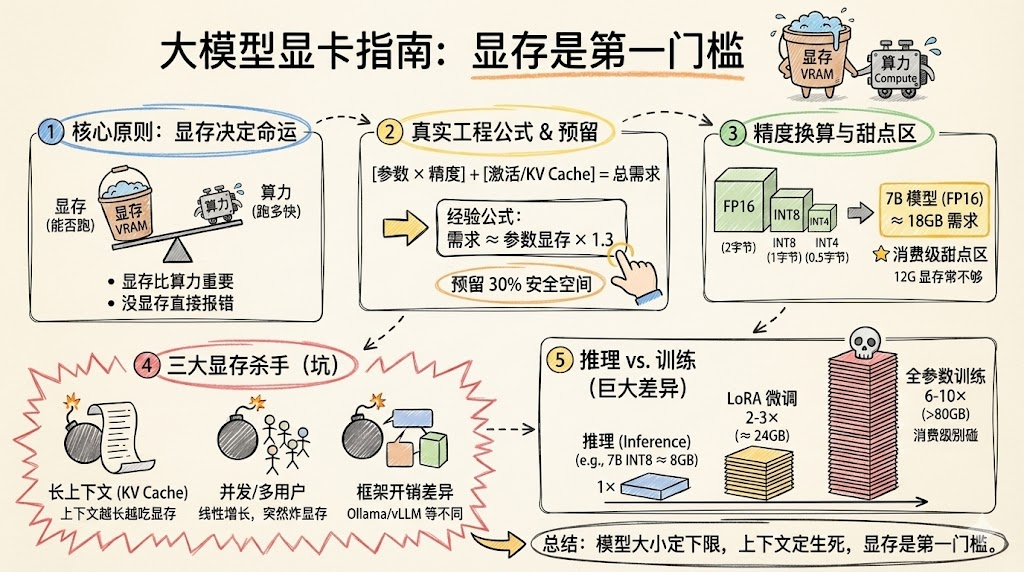
过去做传统 CV/NLP 小模型时,计算能力常是瓶颈,而在大模型时代,显存几乎成了「能不能跑」的硬门槛。算力只决定“跑得快不快”,显存先决定“能不能跑得起来”。
从实践看,有三个明显趋势:
- 模型参数规模快速膨胀:从 1B、7B、13B 到 70B、100B,参数翻一倍,理论参数显存也线性翻倍。
- 使用场景从离线实验走向在线服务:长上下文、多并发、多 Agent 等模式,让显存不再只是“参数大小”的问题。
- 本地部署与轻量微调普及:更多开发者在消费级 8–24GB 显卡上尝试大模型推理与微调,对显存估算的精度要求更高。
因此,要想科学规划硬件预算,首先要搞清楚:显存到底都被谁吃掉了?
二、显存都花在了哪里?
大模型在 GPU 上运行时,显存主要有四大构成:模型参数、优化器/梯度(训练时)、中间激活与临时缓冲、KV Cache 与框架开销。
1. 模型参数占用:参数量 × 精度
模型参数是最直观的一部分,也是很多人唯一想到的一部分。对于一个有 (N) 个参数的模型,不同精度下理论参数显存约为:
- FP32:4 字节/参数
- FP16/BF16:2 字节/参数
- INT8:1 字节/参数
- INT4:0.5 字节/参数
简单换算示例(仅参数本身):
- 7B 模型(70 亿参数)在 FP16 下:
- 参数显存 ≈ (7 \times 10^9 \times 2) 字节 ≈ 14 GB。
- 同一个 7B 模型在 INT4 下:
- 参数显存 ≈ (7 \times 10^9 \times 0.5) 字节 ≈ 3.5 GB。
很多“显存计算”只停留在这一步,但实际工程中显存远不止这些。
2. 中间激活与计算缓冲:推理/训练都绕不开
模型前向推理时,每一层都会产生中间激活与临时缓冲,用于后续计算或反向传播。对推理来说,这部分通常与 batch size、序列长度、网络结构有关;对训练来说,还要额外保留用于反向传播的中间结果。
常见经验是:
- 推理阶段,激活与临时缓冲大约会额外吃掉参数显存的 10–30%,复杂结构或长序列可能更多。
- 训练阶段,激活 + 梯度 + 优化器状态合计可能达到参数显存的 3–8 倍,这也是为什么训练显存远大于推理。
3. KV Cache 与上下文长度:推理的隐形杀手
自回归大语言模型在推理时会维护 Key/Value Cache,用于在生成过程中复用已计算过的注意力键值向量,这部分显存与「上下文长度 × 注意力头维度 × 层数」强相关。
重要影响因素包括:
- 上下文长度(context length):从 2K 到 8K、32K、128K,长度翻倍,KV Cache 大致线性翻倍。
- Batch size 与并发数:同时处理多条序列或多用户,会让 KV Cache 近似按并发数线性增长。
在很多长上下文场景下,KV Cache 对显存的消耗甚至可以与参数本身相当甚至超过,是推理 OOM 的主要来源之一。
4. 框架与运行时开销
不同推理框架(如 Transformers、vLLM、llama.cpp、Ollama 等)对显存的利用效率不同,会存在 20–30% 的差异。此外,还包括:
- 张量布局、缓存策略等引入的额外空间。
- 模型加载后保留的元数据、权重副本(如多精度共存)。
这也是为什么在实测中,你经常会看到“理论算出来 14GB,实际要 18GB 才稳”的情况。
三、推理、微调、训练:显存需求完全不是一个量级
从显存角度看,大模型的使用场景大致分为三档:推理、轻量微调(LoRA/QLoRA)、全参数训练。
1. 推理:大部分个人和小团队的主战场
推理是最常见的场景,也是显存需求最低的场景。在推理阶段,显存主要由参数 + 激活缓冲 + KV Cache 组成,可以用一个经验公式来估算:
推理所需显存 ≈ 参数显存 × 1.3
例如:
- 7B 模型,FP16(参数约 14GB):
- 推理显存 ≈ 14GB × 1.3 ≈ 18GB。
- 同样 7B,INT4(参数约 3.5GB):
- 推理显存 ≈ 3.5GB × 1.5(较长 context)≈ 5GB 左右。
在实际部署中,如果使用 4K 左右上下文、适中并发,12GB 显卡勉强可跑部分 7B 模型(需量化与高效框架),而 16–24GB 显存会明显更从容。
2. LoRA/QLoRA 等轻量微调:约是推理的 2–3 倍
LoRA/QLoRA 等方法通过冻结大部分基础权重,只对少量适配层进行训练,极大减少了需要更新的参数,从而显著降低显存需求。但相比纯推理,还是要为梯度与部分激活保留更多空间。
经验上:
- 轻量微调显存 ≈ 推理显存的 2–3 倍(与实现、batch、sequence length 有关)。
- 对 7B 模型来说,在 INT4 + QLoRA 组合下,在 24GB 显卡上做微调已经是较为常见的实践场景。
3. 全参数训练:显存需求呈数量级跃迁
全参数训练需要为全部参数维护梯度与优化器状态,并保留大量中间激活用于反向传播。常见 Adam 优化器下,参数 + 梯度 + 两个一阶/二阶矩估计,单是优化器状态就可以达到参数量的 3–4 倍显存。
综合来看:
- 全参数训练显存 ≈ 推理显存的 6–10 倍,甚至更高,取决于优化器与激活检查点等技巧是否启用。
- 100B 级别模型的全参数训练通常需要多张 80GB 级别 GPU,通过张量并行、流水线并行等手段才能完成。
这也是为什么对大多数个人开发者与小团队来说,不建议在消费级显卡上尝试真正的全参数训练,而是倾向于使用 LoRA/QLoRA 或云端训练服务。
四、从 1B 到 70B:显存需求与可玩程度一览
为了更直观地理解显存需求,下面给出一个基于实务经验与公开资料的简化参考表,主要面向单卡、适中上下文(≈4K)、中低并发情境下的大致显存建议。
注意:以下为经验范围,仅供选型决策时“量级参考”,实际数字会受具体模型结构、框架与量化实现影响。
大模型规模与显存参考表
| 模型规模 | 精度/用途 | 建议显存区间 | 典型用途与备注 |
|---|---|---|---|
| 1B–3B | INT4 推理 | 4–6GB | 低端消费卡可玩,本地聊天 Demo、边缘测试 |
| 7B | INT4 推理 | 6–8GB | 勉强可在 8GB 显卡运行,需高效框架 |
| 7B | FP16 推理 | 16–20GB | 16GB 可用但紧张,24GB 非常舒适 |
| 7B | QLoRA 微调 | 20–24GB | 24GB 卡的常见实践配置 |
| 13B | INT4 推理 | 10–12GB | 12GB 卡可以尝试,需牺牲上下文或并发 |
| 13B | FP16 推理 | 28–32GB | 24GB 常吃紧,32GB 更稳 |
| 13B | 轻量微调 | 32–48GB | 工作站或云端实例,面向领域调优 |
| 30–34B | INT4 推理 | 18–24GB | 高端消费卡可跑,但上下文和并发有限 |
| 30–34B | FP16 推理 | 60GB+ | 需 80GB 或多卡,面向服务器场景 |
| 70B | INT4 推理 | 30–40GB | 通常需 48GB 以上专业卡或多卡 |
| 70B | FP16 推理 | 120GB+ | 基本必然多卡并行或昂贵云实例 |
可以看到,7B 级别是目前个人玩家与小团队最常用的平衡点:
- 在 INT4 下,8–12GB 即可跑起来。
- 在 FP16 下,16–24GB 体验良好,还可以适度尝试轻量微调。
五、如何为自己的场景选显卡或云服务器?
理解原理与量级之后,还需要一套可执行的选型流程来指导实际决策。可以将决策拆成三个问题:你要跑什么模型、做什么任务、用什么上下文/并发。
1. 第一步:确定模型与任务类型
先回答三个最重要的问题:
- 模型规模:你打算跑 3B、7B、13B、34B 还是 70B?
- 任务类型:是纯推理、LoRA/QLoRA 微调,还是全参数训练?
- 延迟与质量要求:是本地自己玩、团队 Demo,还是要上线面向用户的服务?
大多数个人开发者与小团队的典型组合是:
- 7B/13B 模型 + 推理 / 轻量微调 + 中等上下文(2K–8K)。
2. 第二步:估算基础显存
以模型参数和精度为起点,估算参数显存后乘以适当经验系数:
- 推理:显存 ≈ 参数显存 × 1.3(默认上下文、适中并发)。
- 轻量微调:显存 ≈ 推理显存 × 2–3。
- 全参数训练:显存 ≈ 推理显存 × 6–10。
这一步的目的是给出一个大致量级,判断是 8GB 级、16GB 级、24GB 级还是 48GB 级以上。
3. 第三步:考虑上下文长度与并发
接下来需要根据场景校正显存需求:
- 长上下文:
- 如果需要 32K 或以上上下文,KV Cache 消耗会明显上升,建议显存再乘以约 1.5 的系数。
- 并发与多 Agent:
- 如果同时服务多用户或使用多智能体(多个会话并行),同一进程内的 KV Cache 与激活会近似随并发线性增长。
对于需要稳定线上服务的场景,建议再预留 20–30% 安全空间,避免因偶尔的长输入或负载波动导致 OOM。
4. 第四步:映射到具体硬件与方案
基于上述估算,可以大致做如下映射:
-
本地玩模型(单用户、适中上下文):
- 8–12GB:INT4 3B–7B 模型推理。
- 16–24GB:7B FP16、13B INT4 推理,少量轻量微调。
-
小团队产品验证或小规模在线服务:
- 24–48GB 单卡或双卡:7B/13B FP16 推理,多并发支持;7B 微调。
-
企业级与科研级训练/服务:
- 多卡 48–80GB:34B+ 模型推理和大模型训练,需分布式并行。
如果选择云服务器,可以直接参照云厂商 GPU 实例的显存配置(如单卡 24GB、48GB、80GB),根据估算结果和预算选择合适规格。
六、实战案例:以 7B 和 13B 为例的显存推导
为了让上述方法更具操作性,下面以 7B 和 13B 模型为例,做几个具体的显存推导案例。
案例一:本地单卡跑 7B 模型聊天
目标场景:
- 模型:7B LLM。
- 精度:FP16。
- 用途:本地单用户聊天,2K–4K 上下文,无需并发。
估算步骤:
- 参数显存:7B × 2 字节 ≈ 14GB。
- 推理经验系数:考虑上下文与少量激活,估计 ×1.3。
- 推理显存 ≈ 14GB × 1.3 ≈ 18GB。
结论:
- 16GB 显卡可以尝试运行,但容易在长对话或高负载时吃紧。
- 24GB 显存会明显更稳,可支持一定程度的多轮对话与 Agent 应用。
案例二:用 QLoRA 对 7B 做领域微调
目标场景:
- 模型:7B。
- 精度:INT4 + QLoRA。
- 用途:领域数据微调,batch 和 sequence length 适中。
估算:
- 参数显存:约 3.5GB(INT4)。
- 推理显存:考虑激活和 KV Cache,约 5–6GB。
- 轻量微调:显存 ≈ 推理显存 × 2–3 ≈ 10–18GB。
结论:
- 16GB 显卡可以进行 QLoRA 微调,但需控制 batch 与 sequence length。
- 24GB 显卡则显著更从容,是当前很多实务经验中的常见组合。
案例三:13B 模型的 FP16 推理
目标场景:
- 模型:13B LLM。
- 精度:FP16。
- 用途:本地或云端推理,4K 上下文,中低并发。
估算:
- 参数显存:13B × 2 字节 ≈ 26GB。
- 推理显存:26GB × 1.3 ≈ 34GB 左右。
结论:
- 24GB 显卡基本跑不动完整 13B FP16 推理,尤其在长上下文和并发情况下容易 OOM。
- 32GB 及以上显存(或多卡)更合适,用于提供高质量在线服务。
七、工具与工程优化:让显存用得更“值”
在硬件资源有限的现实下,各种软件与工程优化手段可以显著改善显存压力。
1. 显存估算与分析工具
为了避免凭感觉拍脑袋,可以借助工具:
- 显存估算工具(如 Accelerate 的 estimate-memory):根据模型规模、精度、batch 与序列长度,给出推理/训练显存的估算。
- 各大框架内置 profiler:例如 PyTorch、部分推理引擎内置的显存分布与峰值分析,可以帮助找出显存热点与优化空间。
这些工具可以与本文的经验公式结合使用:先用公式得到量级,再用工具细化配置与调优。
2. 量化与激活检查点
常见显存优化手段包括:
- 权重量化:使用 INT8、INT4 等低精度权重,在保持尽量少精度损失的同时,大幅降低参数显存。
- 激活检查点(Gradient Checkpointing):训练时只保留关键层的激活,其余在反向传播时重新计算,显著减少激活显存占用,以增加一些计算开销为代价。
这些方法通常可以在“增加一定计算时间”的前提下,换取“显存占用显著降低”,非常适合在显存有限但不极端追求速度的场景。
3. 分布式并行与内存分层
在大规模训练与服务中,还会用到更复杂的技术:
- 张量并行、流水线并行:在多卡间拆分参数与计算,单卡显存压力下降,但整体系统复杂度与通信开销增加。
- 分层存储:将部分权重或 KV Cache 放在 CPU 内存甚至磁盘,由推理引擎做按需加载(如部分 offloading 方案)。
这些方案更适合企业级或科研级场景,但理解其基本思想,有助于在面对“显存不够”的时候知道除了“换更大卡”之外还有哪些可能路径。
八、写在最后:给不同人群的简明建议
结合前文的原理与案例,可以给出几组简明的实践建议,帮助不同类型的读者快速定位自己的显存需求。
-
如果只是本地体验与玩模型:
- 8–12GB:INT4 3B–7B 推理,适合个人入门与桌面实验。
- 16–24GB:7B FP16 和 13B INT4 推理,能跑不少实际可用的本地助手与 Agent。
-
如果要做小团队产品验证与小规模服务:
- 优先考虑 24GB 或 48GB 显存,搭配 7B/13B 模型,使用 INT4/FP16 组合,在云上部署推理与 QLoRA 微调。
- 早期就要规划上下文长度和并发策略,避免显存被长上下文和高并发“偷袭”。
-
如果目标是科研级或企业级大模型训练/服务:
- 单卡 80GB 与多卡并行几乎是刚需,尤其是 34B、70B、100B 级模型的训练与高质量推理。
- 在项目启动之初就要设计好分布式策略、显存预算与成本模型,而不是上线前再临时“救火”。
显存不是越大越好,而是要在预算、性能与开发目标之间找到合适的平衡点。掌握“显存都花在哪里”和“如何估算自己场景的需求”,可以让每一次购卡和选云都有理有据,而不是靠运气和“别人说”。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 35
35 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)