从 Spec Coding 到规范驱动 —— AI 编程的确定性边界
本文探讨了AI编程中的规范驱动开发(Spec Coding)及其确定性边界。文章基于得物技术的实战案例,指出规范体系(约束层、示范层、视觉层)能有效约束AI输出质量,但需要警惕"规范腐败"现象。作者提出规范沉淀机制应包含经验记录、团队文档、Review验证等环节,强调规范不是越多越好,而是越精越好。同时分析了规范成本与提效收益的权衡关系,指出大团队更易实现ROI正收益。最后揭示
从 Spec Coding 到规范驱动 —— AI 编程的确定性边界
引言
- 背景:读完得物技术《AI编程能力边界探索:基于 Claude Code 的 Spec Coding 项目实战》
- 核心数据:10 天、2.5 万行代码、提效 36%、217 条人工指令、2,754 次工具调用
- 核心观点:这篇文章的价值不在于"AI 能写代码",而在于"如何用规范消除 AI 的不确定性"
- 个人体验:用 Claude Code 久了,确实会发现"先聊明白再执行"是最佳实践
- 本文立场:基于这篇文章的启发式思考,而非技术深度评测
一、Spec Coding 是什么?(快速回顾)
1.1 核心思想:文档先行
Spec Coding(规格驱动编码)的核心是在写代码之前,先写规格文档:
- proposal(为什么做)
- design(怎么做)
- specs(具体规格)
- tasks(任务拆解)
1.2 实际价值
- 减少返工:在 proposal 阶段明确方向,避免实现完才发现错了
- 适合复杂功能:tasks 分组让 AI 聚焦当前步骤
- 可审计:完整决策链留有记录,方便回溯
1.3 openspec 工具
- 拆解和规范每一个功能变更
- 简化和 AI 沟通的负担
- 实践参考:https://zhuanlan.zhihu.com/p/1980408655154257981
二、三层规范体系:约束 + 示范 + 视觉
2.1 为什么需要三层?
只有"约束层"时,AI 知道规则但缺乏参考实现,容易生成"合法但不地道"的代码。
2.2 第一层:约束层(.claude/rules/)
告诉 AI「禁止什么、必须怎样」
7 个规范文件:TS 规范、命名规范、注释规范、代码风格、样式规范、页面目录规范、API 接口规范。
2.3 第二层:示范层(.claude/code-design/)
告诉 AI「标准产出长什么样」
预置完整模板:pro-table、pro-form、editable-pro-table、drawer、component、utils。
案例:“参考 .claude/code-design/pro-table 生成知识治理列表页”,AI 直接继承这套模式,一次就能生成符合团队风格的代码。
2.4 第三层:视觉层(.claude/ui-design/)
告诉 AI「页面应该长什么样」
存放 HTML 设计稿,AI 可以读取结构和样式信息,提升与设计意图的吻合度。
2.5 规范约束的实际效果
正面效果:
- 205 个文件保持高度一致的命名规范
- 目录分层在每个新页面中都被正确创建
- CRUD 页面都参照了 pro-table 模板的 hooks 分离方式
需要人工干预的案例:
- AI 将所有代码写在单文件中,未按规范分层(一条追问后修正)
- AI 错误地使用了 .less 后缀(收到错误提示后修正)
- antd v5 废弃 API(需要通过报警信息触发修正)
结论:规范体系对 AI 的约束是有效的,但规范文件只是"约束"而非"能力"。加入"示范层"和"视觉层"后,输出质量和一致性明显提升。
三、AI 的能力边界:不是"能做/不能做",而是"如何做才高效"
3.1 需求颗粒度决定协作模式
文章给出了一个很实用的框架:
| 需求类型 | 场景 | 协作模式 | 理由 |
|---|---|---|---|
| 小颗粒 | 改文案、修逻辑、调 CSS | 对话框即扫即改 | 沟通成本低于编写规范 |
| 中颗粒标准化 | 标准 CRUD 页面、简单业务组件 | 基于 Rules/Skills | 有"模式感",规则清晰即可 |
| 中大颗粒复杂 | 重构核心逻辑、新业务模块 | OpenSpec 标准流(SDD) | 业务逻辑复杂,AI 易产生幻觉 |
3.2 AI 失效的三种模式
模式一:规范真空
- 表现:生成的代码功能正确,但风格/结构偏离团队约定
- 原因:任务涉及的领域没有规范约束,AI 自行填充"合理默认值"
- 发生频率:高(尤其在新功能开发初期)
- 应对:在 CLAUDE.md 或 code-design 中补充对应规范
模式二:信息孤岛
- 表现:本地正常,CI 失败;AI 分析每次都对,但解的都是当前暴露的问题
- 原因:AI 掌握的信息是当前会话快照,看不到系统外的状态
- 发生频率:低,但代价高
- 应对:跨平台、跨环境的依赖要在架构设计阶段提前锁定
模式三:任务目标模糊
- 表现:用户说"优化一下首页",AI 悄悄改了组件结构,而不是先澄清目标
- 原因:AI 把"该问人的问题"当成"执行问题"来解决
- 发生频率:中
- 应对:Spec 工作流的 proposal 阶段强制要求先描述"Why"
四、我的思考:规范腐败与规范沉淀机制
4.1 什么是"规范腐败"?
从文章中我注意到一个案例:
- AI 错误地使用了 .less 后缀,但项目实际配置使用 SCSS
- 这说明规范文件可能与实际项目配置不一致
这就是"规范腐败"——规范文件描述的"应该是什么"与实际项目的"实际上是什么"脱节。
4.2 为什么会发生规范腐败?
-
规范更新滞后于项目演进
- 项目从 SCSS 迁移到 Less,但规范文件还是 SCSS
- 项目换了 lint 工具,但规范文件还是旧工具的配置
-
规范缺乏版本管理
- 谁改了规范?什么时候改的?为什么改?
- 这些信息如果缺失,规范就会逐渐"失真"
-
规范质量缺乏 review 机制
- 任何人都可以往 rules 里加一条规则
- 但谁来保证这条规则是正确的、必要的、可执行的?
4.3 我的观点:规范不能直接落地,需要"沉淀机制"
文章提到"规范体系的结构化积累:每次踩坑后补充到 CLAUDE.md/rules",但我觉得这个做法不适合长期迭代。
问题在哪?
踩坑 → 直接加到 rules → 规范质量、长度都难以保证
更好的做法是什么?
踩坑 → 记录到团队文档 → 定期 Review → 提炼为规范 → 合并到 rules
为什么?
- 团队文档是"草稿箱" - 记录所有踩坑经验,但不一定都成为规范
- 定期 Review 是"过滤器" - 筛选出真正有价值的经验,避免规范爆炸
- 规范是"精炼品" - 只有经过 review、测试、验证的经验才能成为规范
4.4 规范的"生命周期"应该是什么样的?
[经验记录] → [团队文档] → [Review/验证] → [规范] → [持续维护]
↑ ↓
└────────────────────── 反馈循环 ←────────────────────┘
每个阶段的作用:
- 经验记录:快速记录踩坑、最佳实践,不做质量要求
- 团队文档:归类整理,方便查阅,但不直接喂给 AI
- Review/验证:评估经验的价值、适用性、正确性
- 规范:经过验证的精炼经验,喂给 AI 执行
- 持续维护:规范更新、过期清理、冲突解决
4.5 谁来负责这个"沉淀机制"?
- 经验记录:所有人都可以(踩坑的人记录)
- 团队文档:技术负责人维护(保证结构化)
- Review/验证:规范委员会(可以是虚拟的,但必须有)
- 规范:规范委员会批准后合并
- 持续维护:规范委员会定期 review
核心观点:规范不是"越多越好",而是"越精越好"。
五、我的思考:规范成本 vs 提效收益的权衡
5.1 文章的观点:复杂明确的任务适合 Spec Coding
简单明确的没必要,简单模糊的随机性太高 ROI 低,复杂模糊的解释半天不如自己搞,复杂明确的 Spec Coding 的 ROI 就比较高。
借用一下原文的图片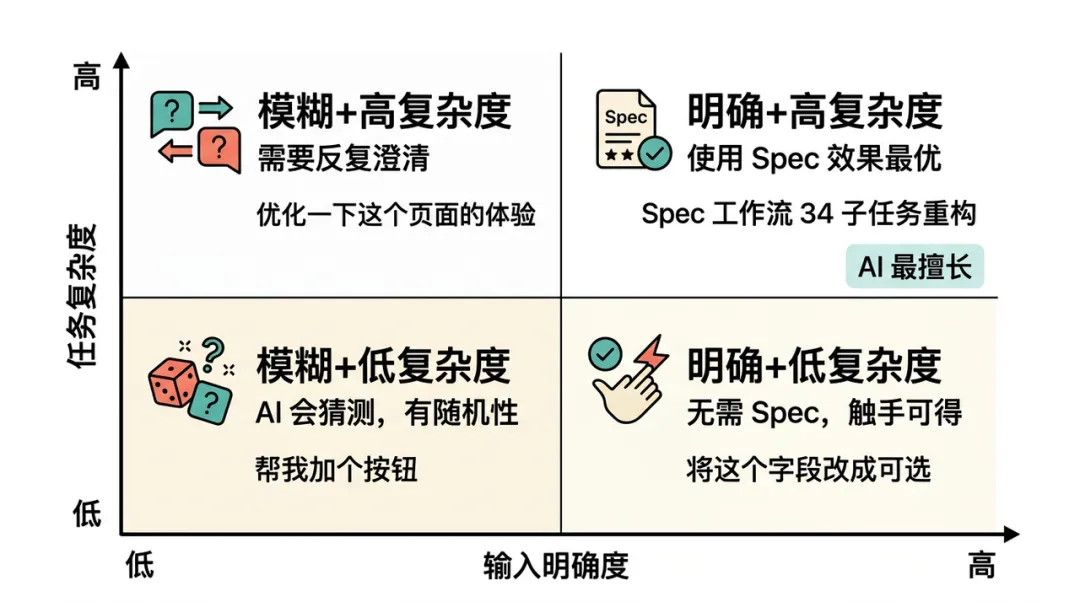
5.2 我的观察:规范成本是"隐性成本"
文章提到的 10 天、2.5 万行代码、提效 36%,这些是"显性收益"。
但规范成本是"隐性成本":
- 7 个规范文件的编写时间
- 6 个模板的维护时间
- HTML 设计稿的更新时间
- 定期 review 的时间
- 规范冲突的解决时间
如果把这些时间算进去,ROI 还是 36% 吗?
5.3 大团队 vs 小团队:规范成本的差异
大团队(>10 人):
- 规范可以分摊到更多人
- 统一规范的价值更大(减少沟通成本)
- 有专门的架构师/技术负责人维护规范
- 规范成本 < 规范收益
小团队(<5 人):
- 规范成本由少数人承担
- 口头沟通可能比写规范更高效
- 没有人专门维护规范
- 规范成本可能 > 规范收益
核心观点:Spec Coding 的 ROI 不是固定的,而是取决于团队规模、项目复杂度、规范质量。
六、我的思考:AI 能力边界的本质
6.1 文章的案例:生产构建排障花了 4 小时
4 小时、7 个会话、15+ 次方案尝试、59 条指令,这是整个项目单日指令最多的一天。
根因是什么?
- .npmrc 历史副作用:omit=optional 导致 Tailwind v4 的 native binding 被跳过
- Prisma v6 境外下载沉默卡死:AI 需要阅读 node_modules 源码第 2319 行
- pnpm 跨平台 lockfile 不一致:macOS arm64 生成的 lockfile 不含 Linux x64 的 native package
6.2 为什么这个问题这么难?
-
隐性行为无文档
- Prisma postinstall 在境外下载时不报错、不超时,只是无限等待
- AI 无法通过训练数据或当前上下文主动推断这个行为
-
多根因互相掩盖
- 解决一层才暴露下一层
- AI 每次分析都正确,但解的都是当前暴露的问题
-
信息范围有限
- AI 分析的是日志截图,无法感知"CI 环境还有哪些隐性配置"
- 本地无法复现,每次验证必须提交代码等待 CI(一轮约 10 分钟)
6.3 我的结论:AI 的能力边界不是"智力"问题,而是"信息"问题
AI 的分析能力足够强,但它掌握的信息是"当前会话的快照"。
- 它知道你告诉它的,但不知道你没告诉它的
- 它能分析你展示的,但看不到你没展示的
- 它能解决你描述的问题,但不知道你还没发现的问题
而一个人是不可能全知的,这个问题会一直伴随始终,只能尽可能设计标准的流程然后减少这种问题发生的频率,但是遇到问题的时候还是得首先想到这个问题。
七、MCP 工具:消除信息断层
7.1 两类高频信息断层
- 接口文档断层:接口文档在 API 平台,AI 无法直接访问
- 需求文档断层:PRD、设计文档存在飞书云文档中,需要手工复制
7.2 MCP 一:接口文档直连
- AI 可以根据接口 URL 自动拉取完整接口文档
- 累计被调用 21 次,完成 39 个接口联调
- 联调一次通过,6 个接口零联调返工
7.3 MCP 二:飞书云文档直连
- AI 可以直接读取飞书云文档的内容
- 无需用户手工打开→复制→粘贴,打断思路
7.4 我的想法:MCP 是 AI Coding 的基础设施
就像 HTTP 是 Web 的基础设施,MCP 是 AI 与工具交互的标准化协议。
未来会有更多 MCP:
- 设计稿直连(Figma/蓝湖)
- 测试用例直连(Jira/飞书)
- 发布平台直连(GitLab CI/Jenkins)
- 日志平台直连(Sentry/ELK)
核心观点:MCP 不是"可选增强",而是"必选基础"。
八、我的思考:开发者角色的重构
8.1 文章的观点:AI Coding 不是让开发者"消失",而是让开发者的工作向上迁移
8.2 三个关键变化
-
规范设计能力成为核心竞争力
- 能写出让 AI 可靠执行的规范,价值比能写出同等功能代码更高
- 过去:写代码
- 现在:写规范,让 AI 写代码
-
系统性思维变得更重要
- AI 可以帮你解决每一个局部问题,但无法帮你看到真实业务全局
- 过去:解决局部问题
- 现在:看到全局,设计系统
-
质量意识前移
- 过去:Code Review 在代码写完后进行
- 现在:需要在方案设计/任务执行阶段就介入,而不是等 AI 执行完再纠错
8.3 但我觉得还有一个关键变化:从"手艺人"到"指挥官"
手艺人时代:
- 你需要会写代码
- 你需要会调 bug
- 你需要会优化性能
- 这些是"硬技能",靠时间积累
指挥官时代:
- 你需要会设计规范
- 你需要会判断 ROI
- 你需要会协调资源
- 这些是"软技能",靠经验积累
8.4 "写规范"真的比"写代码"更难吗?
我的观察:不一定更难,但要求不同。
写代码的要求:
- 逻辑正确
- 代码质量
- 性能优化
写规范的要求:
- 准确性(不能有歧义)
- 可执行性(AI 能理解)
- 可维护性(能随项目演进)
- 适用性(适用场景清晰)
写代码是"把事情做对",写规范是"把事情定义清楚"
8.5 什么是不变的?
- 对业务的理解
- 对用户体验的敏感度
- 对技术选型的判断
- 对团队协作的责任感
这些是 AI 无法替代的,也是开发者的"护城河"。
核心观点:AI 时代的工程师,核心竞争力不是"能写出更好的代码",而是"能设计出更好的系统"。
九、未来:规范体系的结构化积累
9.1 规范体系的结构化积累
原文提到"每次踩坑后补充到 CLAUDE.md/rules",但我觉得需要引入"沉淀机制":
踩坑 → 团队文档 → 定期 Review → 提炼为规范 → 合并到 rules
9.2 MCP 工具链的纵向延伸
该文章中 MCP 仅覆盖了接口文档、飞书文档。后续针对设计稿、测试用例、发布平台、日志平台接入,可以进一步形成完整的 AI Coding 链路。
9.3 多 Agent 并行开发
该文章项目开发过程中,发现大型任务执行等待时间较长,下一步可以尝试多 Agent 并发生成,同时开发不同功能模块。
十、结语:AI Coding 的本质是用结构化规范消除不确定性
10.1 我的核心观点
AI Coding 的本质不仅仅是用 AI 写代码,而是用结构化的规范和工作流把不确定性消除在执行之前。
- AI 负责在确定性空间里高速执行
- 人负责维护和扩展那个确定性空间的边界
10.2 一句话总结(借用原文)
规范是杠杆,AI 是力,Spec 工作流是支点。
10.3 最后的思考
Spec Coding 不是"新概念",但这次实践给出了三个重要启示:
- 规范腐败是真实存在的 - 规范文件可能滞后于项目演进,需要建立沉淀机制
- 规范成本是隐性成本 - ROI 不是固定的,取决于团队规模、项目复杂度、规范质量
- 开发者角色正在重构 - 从"手艺人"到"指挥官",核心竞争力从"写代码"到"写规范"
在 AI 时代,"写代码"的价值在下降,"写规范"的价值在上升。
但更重要的是,谁能写出更精准、更可执行、更易维护的规范,并且建立有效的规范沉淀机制,谁就能更好地驾驭 AI。
原文:https://mp.weixin.qq.com/s/1Oi7YhMgcPp9gQAWPndXWA

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)