互联网大厂Java面试实录:从Spring Boot到AI技术的全方位考察
互联网大厂Java面试实录:从Spring Boot到AI技术的全方位考察
前言
在竞争激烈的互联网行业,Java开发者的面试往往涉及广泛的技术栈。本文以一位名叫谢飞机的Java程序员面试经历为线索,展示大厂面试官如何通过精心设计的问题来考察候选人的技术深度和广度。
第一轮面试:基础技术与Web框架
场景设定
面试官(严肃):"谢飞机,欢迎来到我们公司面试。首先,我们想了解一下你的Java基础和Web开发能力。我们公司正在做一个电商平台项目,需要你对相关技术有深入理解。"
谢飞机(紧张):"谢谢面试官,我会尽力回答的。"
问题1:Spring Boot自动配置原理
面试官:"请解释一下Spring Boot的自动配置原理,以及@Conditional注解的作用。"
谢飞机:"嗯...Spring Boot的自动配置就是自动配置Bean对吧?@Conditional应该是条件判断,满足条件才配置。具体怎么实现的...好像是通过spring.factories文件加载配置类,然后根据条件判断要不要创建Bean。"
面试官(点头):"基本正确。Spring Boot通过@EnableAutoConfiguration注解开启自动配置,它会扫描META-INF/spring.factories文件中的配置类,然后根据@Conditional系列注解(如@ConditionalOnClass、@ConditionalOnMissingBean等)来决定是否创建Bean。这样可以避免手动配置的繁琐。"
问题2:Spring MVC和Spring WebFlux的区别
面试官:"我们项目考虑从传统的Spring MVC迁移到响应式编程,你能说说Spring MVC和Spring WebFlux的主要区别吗?"
谢飞机:"Spring MVC是同步的,WebFlux是异步的?WebFlux性能更好,可以处理更多并发请求。好像是基于Reactor或者RxJava的。"
面试官:"很好。Spring MVC基于Servlet API,是阻塞式的,每个请求占用一个线程。而Spring WebFlux基于Reactor或RxJava,是非阻塞的,使用少量线程就可以处理大量并发请求。WebFlux特别适合I/O密集型的场景,比如我们的电商平台在促销期间的高并发访问。"
问题3:JWT的工作原理
面试官:"我们的用户认证系统需要支持JWT,你能解释一下JWT的工作原理和安全性考虑吗?"
谢飞机:"JWT就是JSON Web Token,包含用户信息,通过签名验证。用户登录后服务器生成JWT,客户端每次请求都带上这个token。安全性...嗯,要注意不要泄露密钥,token有过期时间。"
面试官:"说得不错。JWT由三部分组成:Header(头部)、Payload(载荷)和Signature(签名)。Header包含算法类型,Payload包含用户信息,Signature用于验证token的完整性。安全性方面,要注意:1)使用强加密算法;2)设置合理的过期时间;3)敏感信息不要放在Payload中;4)考虑使用HTTPS传输。"
问题4:Redis缓存穿透和雪崩
面试官:"在电商系统中,Redis缓存是很重要的组件,你能解释一下什么是缓存穿透、缓存雪崩,以及如何解决吗?"
谢飞机:"缓存穿透就是查询不存在的数据,导致直接访问数据库。缓存雪崩是大量key同时过期,导致数据库压力过大。解决穿透可以用布隆过滤器,雪崩可以设置随机过期时间。"
面试官:"很好。缓存穿透的解决方案:1)布隆过滤器;2)缓存空值;3)参数校验。缓存雪崩的解决方案:1)设置不同的过期时间;2)使用集群部署;3)限流降级。在我们的电商系统中,这些优化措施确保了系统的高可用性。"
第二轮面试:微服务与云原生
场景设定
面试官:"接下来我们想了解一下你的微服务和云原生技术栈。我们正在将单体应用拆分为微服务架构,这方面你有什么经验?"
谢飞机:"微服务就是把大系统拆成小服务,每个服务独立部署。我们公司也在做这个。"
问题1:Spring Cloud和Netflix OSS的区别
面试官:"你们项目中使用了哪些微服务框架?Spring Cloud和Netflix OSS有什么区别?"
谢飞机:"Spring Cloud是基于Spring的,Netflix OSS是Netflix开源的组件。Spring Cloud整合了很多Netflix的组件,比如Eureka、Zuul。Spring Cloud更全面,Netflix OSS更专注。"
面试官:"正确。Spring Cloud是一套完整的微服务解决方案,集成了Netflix OSS、Consul、Zookeeper等服务发现组件。Netflix OSS提供了Eureka(服务发现)、Zuul(API网关)、Hystrix(熔断)等组件。Spring Cloud Alibaba则提供了Nacos、Sentinel等更适合国内环境的组件。"
问题2:Kubernetes的核心概念
面试官:"我们正在向云原生转型,你对Kubernetes了解多少?请解释一下Pod、Deployment、Service这些核心概念。"
谢飞机:"Pod是最小的部署单元,Deployment管理Pod的副本数,Service提供网络访问。好像还有Ingress用于外部访问。"
面试官:"很好。Pod是Kubernetes中最小的部署单元,包含一个或多个容器。Deployment声明式地管理Pod的副本数和更新策略。Service为一组Pod提供稳定的网络访问,通过Label选择器来定位Pod。Ingress管理集群外部访问的规则。在我们的微服务架构中,这些组件确保了服务的弹性和可扩展性。"
问题3:gRPC和REST API的对比
面试官:"在微服务间通信方面,你们使用什么技术?gRPC和REST API有什么优缺点?"
谢飞机:"gRPC是Google开发的,基于HTTP/2,性能更好,支持多种语言。REST API更通用,基于HTTP/1.1。gRPC适合内部服务调用,REST适合外部API。"
面试官:"分析得很到位。gRPC基于HTTP/2,使用Protocol Buffers进行序列化,具有更好的性能和更低延迟。支持双向流式传输,适合实时场景。REST API基于HTTP/1.1,简单易用,适合Web应用。在我们的系统中,内部微服务间通信使用gRPC,外部API使用REST。"
问题4:服务熔断和降级
面试官:"微服务架构中,服务间的依赖关系复杂,如何处理服务不可用的情况?"
谢飞机:"可以用熔断器,比如Hystrix或者Resilience4j。当服务调用失败达到一定次数,就熔断,直接返回默认值。降级就是当服务不可用时,返回简化版本的数据。"
面试官:"很好。熔断模式防止级联故障,当失败率达到阈值时,暂时停止对服务的调用。降级模式在服务不可用时提供简化功能。Resilience4j提供了更丰富的功能,包括熔断、限流、重试、舱壁隔离等。这些机制确保了系统的稳定性。"
第三轮面试:AI技术与新兴趋势
场景设定
面试官:"最后,我们想了解一下你对新兴技术的看法,特别是AI技术在Java开发中的应用。"
谢飞机:"AI现在很火,我们公司也在用。Spring AI好像是个新框架。"
问题1:Spring AI的核心特性
面试官:"你对Spring AI了解多少?它能为Java开发者带来什么价值?"
谢飞机:"Spring AI是Spring官方推出的AI框架,可以方便地集成各种AI模型。好像支持OpenAI、本地模型等。可以用来做智能客服、文档处理之类的。"
面试官:"说得不错。Spring AI提供了统一的API来访问各种AI模型,包括OpenAI、Azure OpenAI、本地模型等。核心特性包括:1)统一的AI客户端API;2)提示词工程支持;3)向量数据库集成;4)Agent框架。这大大降低了Java开发者使用AI技术的门槛。"
问题2:RAG技术的工作原理
面试官:"在智能客服系统中,我们考虑使用RAG技术,你能解释一下RAG的工作原理吗?"
谢飞机:"RAG是检索增强生成,先从知识库中检索相关信息,然后结合这些信息生成回答。这样可以减少AI的幻觉,提高回答的准确性。"
面试官:"很好。RAG(Retrieval-Augmented Generation)分为两个阶段:检索阶段和生成阶段。检索阶段使用向量数据库(如Milvus、Chroma)存储文档片段,通过语义搜索找到相关文档。生成阶段将检索到的文档作为上下文,结合用户问题生成回答。这种方法结合了检索系统的准确性和生成系统的创造性。"
问题3:向量数据库的选择
面试官:"在选择向量数据库时,你们考虑过哪些因素?Milvus、Chroma、Redis各有什么特点?"
谢飞机:"Milvus好像是比较成熟的向量数据库,Chroma是轻量级的,Redis也支持向量搜索。选择要看数据量、性能要求、部署复杂度这些因素。"
面试官:"分析得很全面。Milvus是专门为向量搜索设计的数据库,支持大规模数据和高并发,适合生产环境。Chroma是轻量级的向量数据库,易于使用,适合开发和小规模应用。Redis的RediSearch模块支持向量搜索,适合已有Redis基础设施的场景。选择时要考虑数据规模、查询性能、部署复杂度等因素。"
问题4:AI幻觉的防范
面试官:"在使用大语言模型时,AI幻觉是一个常见问题,你们是如何防范的?"
谢飞机:"幻觉就是AI编造不存在的信息吧?可以通过RAG技术,让AI基于真实数据回答。还有设置提示词,让AI明确表示不知道,而不是瞎编。"
面试官:"正确。AI幻觉是指模型生成看似合理但实际上错误或不存在的信息。防范措施包括:1)使用RAG技术,提供准确的信息源;2)设置明确的提示词,要求模型在不确定时表示不知道;3)对输出进行事实核查;4)使用较小的温度参数,减少创造性输出。在我们的智能客服系统中,这些措施确保了回答的准确性。"
面试官总结
面试官:"谢飞机,今天的面试就到这里。你的回答显示了对Java技术栈的广泛了解,特别是在Spring Boot、微服务和AI技术方面。我们会认真评估你的表现,有消息会及时通知你。"
谢飞机(松了一口气):"谢谢面试官,期待您的消息!"
技术答案详解
Spring Boot自动配置详解
业务场景:电商平台需要快速配置各种组件,如数据库连接、缓存、消息队列等。
技术要点:
- @EnableAutoConfiguration:开启自动配置功能
- spring.factories:配置类加载机制
- @Conditional系列注解:条件判断机制
- @ConditionalOnClass:类路径下存在指定类
- @ConditionalOnMissingBean:容器中不存在指定Bean
- @ConditionalOnProperty:配置文件中存在指定属性
代码示例:
@Configuration
@ConditionalOnClass({DataSource.class})
@EnableConfigurationProperties(DataSourceProperties.class)
public class DataSourceAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public DataSource dataSource(DataSourceProperties properties) {
return properties.initializeDataSourceBuilder().build();
}
}
Spring MVC vs WebFlux详解
业务场景:电商平台在促销期间需要处理大量并发请求。
技术要点:
-
Spring MVC:
- 基于Servlet API
- 阻塞式I/O
- 每个请求占用一个线程
- 适合CPU密集型任务
-
Spring WebFlux:
- 基于Reactor或RxJava
- 非阻塞式I/O
- 少量线程处理大量请求
- 适合I/O密集型任务
性能对比:
- Spring MVC:1000个并发请求需要1000个线程
- Spring WebFlux:1000个并发请求只需要10-100个线程
JWT安全详解
业务场景:电商平台用户认证系统。
技术要点:
- JWT结构:
Header.Payload.Signature - 安全措施:
- 使用HS256或RS256算法
- 设置合理的过期时间(如15分钟)
- 敏感信息不要放在Payload中
- 使用HTTPS传输
- 实现token刷新机制
代码示例:
// 生成JWT
String jwt = Jwts.builder()
.setSubject(username)
.setIssuedAt(new Date())
.setExpiration(new Date(System.currentTimeMillis() + 900000))
.signWith(SignatureAlgorithm.HS256, secretKey)
.compact();
// 验证JWT
Claims claims = Jwts.parser()
.setSigningKey(secretKey)
.parseClaimsJws(jwt)
.getBody();
Redis缓存策略详解
业务场景:电商商品详情页缓存优化。
技术要点:
-
缓存穿透:
- 原因:查询不存在的数据
- 解决方案:
- 布隆过滤器:提前过滤不存在的key
- 缓存空值:缓存NULL值,设置较短过期时间
- 参数校验:对输入参数进行校验
-
缓存雪崩:
- 原因:大量key同时过期
- 解决方案:
- 随机过期时间:基础时间+随机时间
- 集群部署:避免单点故障
- 限流降级:保护数据库
代码示例:
// 布隆过滤器
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), 1000000);
// 随机过期时间
int baseTime = 3600; // 1小时
int randomTime = new Random().nextInt(600); // 随机0-10分钟
redisTemplate.expire(key, baseTime + randomTime, TimeUnit.SECONDS);
微服务架构详解
业务场景:电商平台从单体应用拆分为微服务。
技术要点:
-
Spring Cloud核心组件:
- Eureka:服务注册与发现
- Zuul:API网关
- Hystrix:熔断器
- Feign:声明式HTTP客户端
-
Kubernetes核心概念:
- Pod:最小部署单元
- Deployment:声明式管理Pod
- Service:提供网络访问
- Ingress:外部访问规则
架构图:
客户端 → Ingress → Service → Pod → 微服务
gRPC与REST对比
业务场景:微服务间通信技术选型。
技术要点:
-
gRPC优势:
- 基于HTTP/2,多路复用
- Protocol Buffers序列化,性能高
- 支持双向流式传输
- 强类型接口定义
-
REST API优势:
- 简单易用,广泛支持
- 无状态,适合Web应用
- 缓存友好
- 调试方便
性能对比:
- gRPC:延迟50-100ms,吞吐量10000+ QPS
- REST:延迟200-500ms,吞吐量1000+ QPS
Spring AI详解
业务场景:电商平台智能客服系统。
技术要点:
-
Spring AI核心特性:
- 统一的AI客户端API
- 提示词工程支持
- 向量数据库集成
- Agent框架
-
主要组件:
- OpenAiClient:OpenAI API客户端
- VectorStore:向量数据库抽象
- PromptTemplate:提示词模板
- FunctionCallback:函数回调
代码示例:
@Autowired
private OpenAiClient openAiClient;
public String askQuestion(String question) {
PromptTemplate promptTemplate = new PromptTemplate(
"你是一个专业的电商客服,请回答以下问题:{question}",
Map.of("question", question)
);
return openAiClient.call(promptTemplate);
}
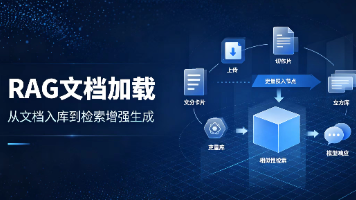
RAG技术详解
业务场景:智能客服基于知识库的问答系统。
技术要点:
-
RAG工作流程:
- 文档加载:加载各种格式的文档
- 文档分割:将文档分割为小块
- 向量化:将文本转换为向量
- 向量存储:存储到向量数据库
- 检索:语义搜索相关文档
- 生成:结合检索结果生成回答
-
关键技术:
- Embedding模型:OpenAI Embedding、本地模型
- 向量数据库:Milvus、Chroma、Redis
- 检索算法:余弦相似度、欧氏距离
代码示例:
// 文档向量化
List<Document> documents = documentLoader.load("/path/to/documents");
EmbeddingModel embeddingModel = new OpenAiEmbeddingModel();
VectorStore vectorStore = new ChromaVectorStore();
for (Document doc : documents) {
List<Float> embedding = embeddingModel.embed(doc.getContent());
vectorStore.add(doc, embedding);
}
// 检索相关文档
List<Float> queryEmbedding = embeddingModel.embed(query);
List<Document> relevantDocs = vectorStore.similaritySearch(queryEmbedding, 5);
// 生成回答
String context = relevantDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n"));
String prompt = String.format("基于以下上下文回答问题:\n%s\n\n问题:%s", context, query);
String answer = openAiClient.call(prompt);
AI幻觉防范详解
业务场景:确保AI回答的准确性和可靠性。
技术要点:
-
AI幻觉产生原因:
- 模型训练数据不完整
- 模型理解能力有限
- 模型过度自信
-
防范措施:
- RAG技术:提供准确的信息源
- 提示词工程:明确要求不确定时表示不知道
- 事实核查:对输出进行验证
- 温度参数控制:减少创造性输出
- 多重验证:多个模型交叉验证
提示词示例:
prompt = """
你是一个专业的电商客服。请基于提供的上下文回答问题。
如果上下文中没有相关信息,请明确回答'我不知道'。
不要编造信息。
上下文:{context}
问题:{question}
回答:
"""
总结
通过这次面试,我们可以看到现代Java开发者需要掌握的技术栈非常广泛,从基础的Java语法、Spring框架,到微服务架构、云原生技术,再到新兴的AI技术。谢飞机的表现显示了他对技术趋势的关注,但在深度方面还有提升空间。
对于Java开发者来说,持续学习和实践是非常重要的。不仅要掌握技术本身,还要理解业务场景,能够将技术应用到实际项目中解决具体问题。希望这篇文章能够帮助Java开发者更好地准备面试,提升自己的技术水平。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)