【2026】FAISS小白入门到应用,手把手完成本地Windows安装部署及学习
部分内容参考文档:https://blog.csdn.net/sinat_28461591/article/details/147031798。
部分内容参考文档:https://blog.csdn.net/sinat_28461591/article/details/147031798
一、FAISS 是什么?为什么它适合做本地向量检索?
应用:构建一个 RAG 系统、智能问答平台、文本相似度比对、或者 AI 搜索系统。
- 语义检索:根据问句的语义找到最接近的文档片段
- RAG 系统:作为大模型上下文召回的向量库
- 文本聚类:找出相似内容或主题群组
- 图像 / 视频搜索:嵌入图像特征后进行相似内容比对
FAISS(Facebook AI Similarity Search) 是由 Meta(原 Facebook)开发的开源向量检索引擎,专为“海量向量的高效相似度搜索”而设计。它不是数据库,而是一个超高性能的 C++/Python 向量索引库,可以让你在本地环境下进行数百万级别的向量匹配操作。
优点:
性能极强 支持百万向量以内毫秒级响应(本地 CPU / GPU)
部署轻量 不需要服务器,不需要 Docker,一句 pip 即可
本地私有化友好 所有数据都在你机器上,无外泄风险 模块组合灵活 提供 10 多种索引结构,适配不同精度 / 速度场景
和 Milvus / Qdrant 有什么区别?
对比点 FAISS Milvus Qdrant
部署复杂度 超简单(嵌入项目即可) 高(依赖集群) 中等(需服务端)
本地部署友好 完美 服务端依赖重 支持,但不轻量
支持量化搜索 支持 PQ/OPQ/HNSW 等 支持 支持部分
REST API 支持 ❌ 原生无(需自封装) 自带 自带
适合场景 本地 / 轻量 / 嵌入式系统 云原生大项目 中型服务项目
嵌入项目的轻量向量库首选 FAISS。
二、本地部署
先看看pycharm当前环境有没有所需的包
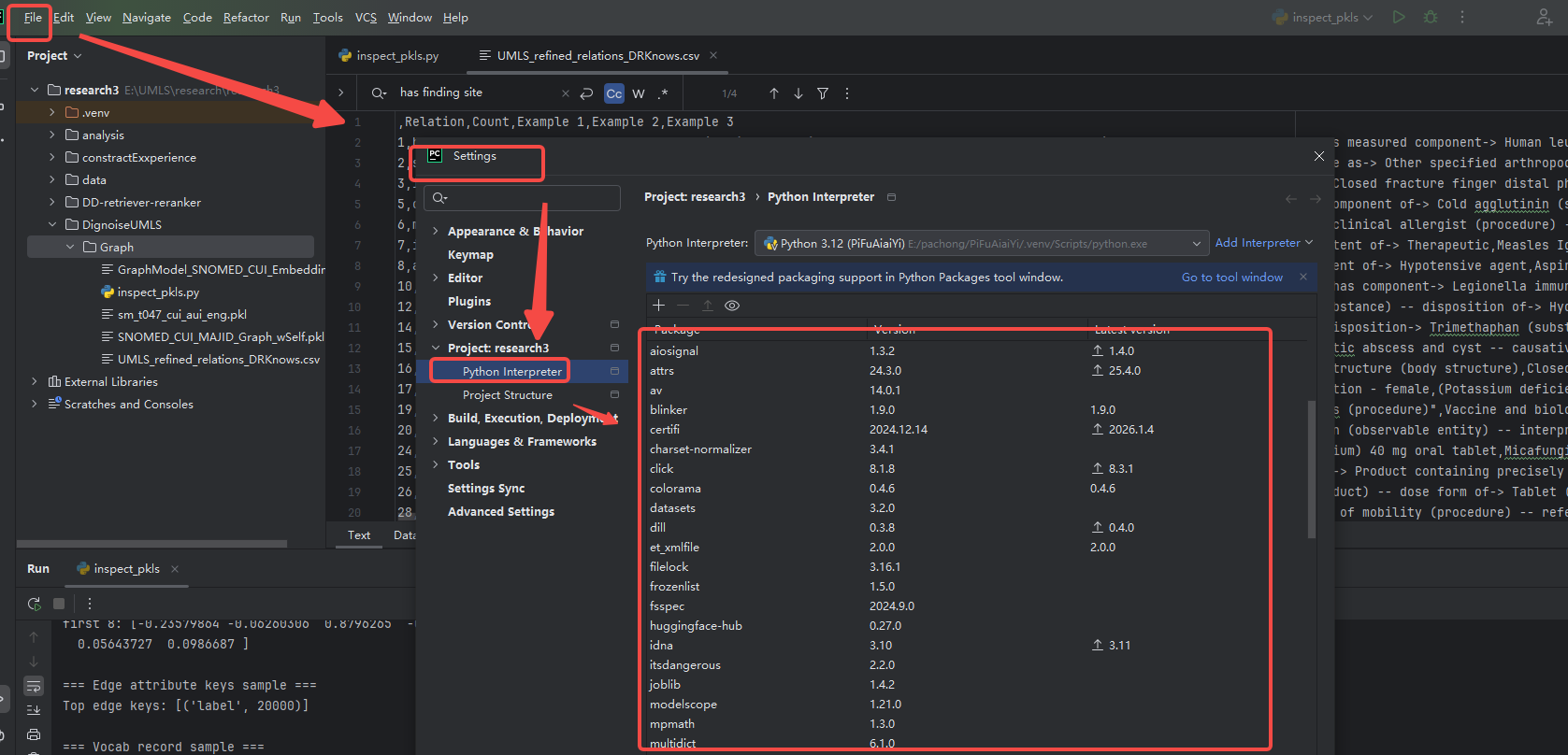
1.安装 FAISS(Windows 常见)
一般有两种:
-
CPU 版(最简单):
pip install faiss-cpu -
Conda(更稳):
conda install -c conda-forge faiss-cpu
你如果有 GPU 也可以装 faiss-gpu,但 Windows 上配置更麻烦;先用 CPU 足够。
有些博主建议用 pip install faiss-cpu sentence-transformers
是安装了两个东西,FAISS + 一个“现成的文本→向量”框架
1️⃣ faiss-cpu 是什么?
FAISS = Facebook AI Similarity Search
-
只做一件事:给定向量 → 快速找相似向量
-
它完全不知道文本、token、BERT
-
输入必须是
float32 numpy array
你可以把它理解成:
“一个非常快的向量数据库内核”
2️⃣ sentence-transformers 是什么?
这是一个 高层 NLP 框架,它帮你做三件事:
-
下载/加载一个预训练模型(BERT / MiniLM / MPNet 等)
-
把文本 tokenize
-
跑模型 forward,得到 sentence embedding
👉 适合“我还没有编码模型,想快速把文本变成向量”的场景
pip install faiss-cpu
👉 只安装向量检索引擎(FAISS)
👉 必须自己已有/自己实现向量生成(比如我已经有了一个 BERT模型)
所以我只需要pip install faiss-cpu,我直接在pychrm里加
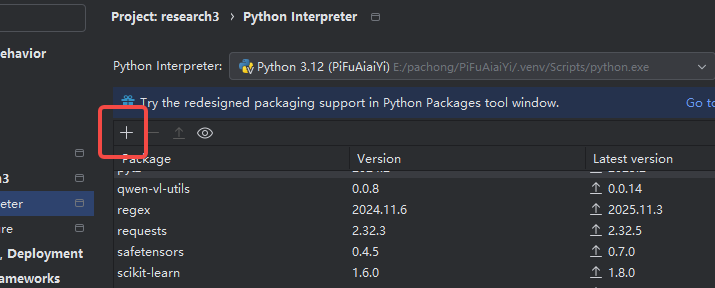
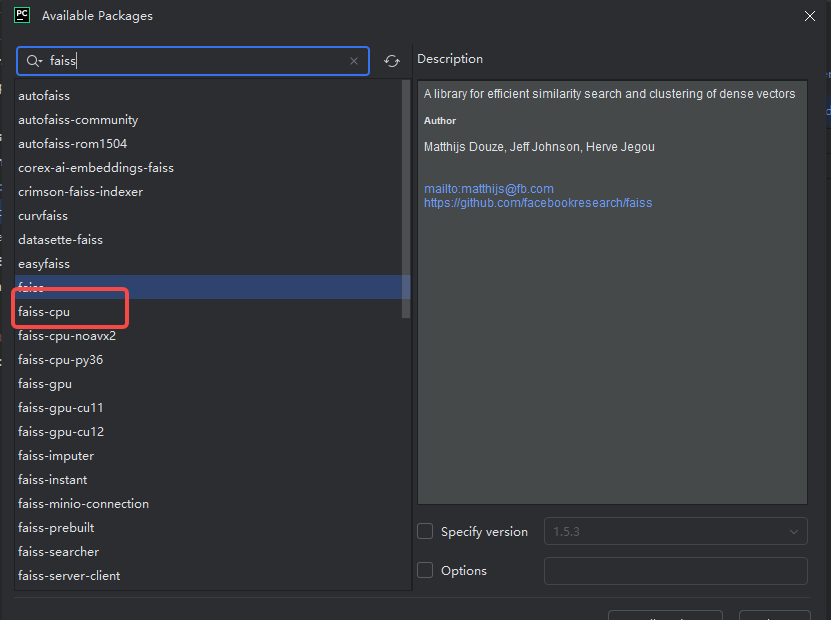
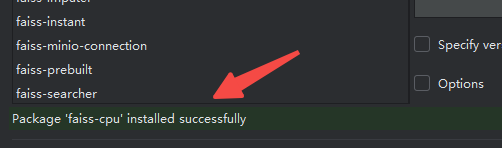
出现下面内容就ok了
2.创建FAISS索引
a.选择搜索算法
HNSW(Hierarchical Navigable Small Worlds,分层可导航小世界)是一种高效的近似最近邻(ANN)搜索算法,核心用于解决高维数据(如图像特征、文本嵌入、推荐系统向量等)的快速相似性检索问题,平衡了搜索速度与结果准确性。
其核心原理可拆解为两点:
- 分层结构设计:算法会为数据集构建多层 “导航图”—— 底层包含全部数据点,上层则是从下层随机抽样的 “稀疏子集”。越上层的节点越少,导航范围越广;越下层节点越密集,定位越精准。这种结构类似 “高速公路系统”:上层快速跨区域导航,下层精准抵达目标。
- 小世界网络特性:每层内的节点仅与少量邻居连接,但任意两个节点间能通过极短路径连通(符合 “小世界效应”)。搜索时,从最上层起点出发,通过 “贪心选择”(每次跳向当前最接近目标的邻居)快速缩小范围,直到下探至底层,最终找到近似最近邻。
相比传统 ANN 算法(如 KNN、KD 树),HNSW 的核心优势是高维场景下的效率优势:KD 树等在维度超过 20 时性能会急剧下降(“维度灾难”),而 HNSW 通过分层导航,能在百万 / 千万级高维数据中,以极低的计算成本(少量距离计算)实现高效检索,因此广泛用于推荐系统、图像检索、自然语言处理(如语义搜索)等领域。
cosine 语义检索,核心是基于余弦相似度(Cosine Similarity) 实现文本语义匹配的检索技术,本质是通过 “计算向量夹角” 判断文本语义关联度,而非传统检索依赖的关键词匹配。
1. 核心原理:从 “文本” 到 “向量” 再到 “相似度”
语义检索的关键是解决 “文本语义无法直接计算” 的问题,余弦语义检索通过三步实现:
- 第一步:文本向量化用自然语言处理(NLP)模型(如 BERT、Word2Vec)将文本(如 query 查询、文档内容)转化为高维向量(也称 “语义向量”)。向量的每个维度对应文本的一个语义特征(如 “猫” 的向量会包含 “哺乳动物”“宠物”“有毛” 等隐含特征)。
- 第二步:计算余弦相似度余弦相似度衡量两个向量在 “方向” 上的接近程度(而非长度),公式为:\cos\theta = \frac{\vec{A} \cdot \vec{B}}{\|\vec{A}\| \times \|\vec{B}\|}其中 \vec{A}、\vec{B} 是两个文本的向量,\theta 是向量夹角。
- 若夹角 \theta=0^\circ,\cos\theta=1:语义完全一致(如 “买奶茶” 和 “选购奶茶”);
- 若夹角 \theta=90^\circ,\cos\theta=0:语义完全无关(如 “买奶茶” 和 “修电脑”);
- 数值越接近 1,语义关联度越高。
- 第三步:排序与检索对查询向量与数据库中所有文档向量的余弦相似度排序,返回相似度 Top N 的文档,即 “语义最匹配” 的结果。
2. 核心优势:解决传统检索的 “语义鸿沟”
传统关键词检索(如早期搜索引擎)依赖 “关键词是否重合”,容易出现 “漏检” 或 “误检”,而余弦语义检索的优势在于:
- 理解 “语义相似” 而非 “关键词一致”:比如查询 “如何缓解头痛”,即使文档写 “减轻头疼的方法”(无完全相同关键词),因向量方向接近,仍能被检索到;
- 忽略 “文本长度差异”:余弦相似度仅看向量方向,短查询(如 “推荐科幻电影”)与长文档(如电影影评)也能准确匹配,不受文本长度影响。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)