AI - ADK Runtime(运行时):Runner、Event Loop、Session/State 是怎么“跑起来”的?
Runner、Event Loop、Session/State 是怎么“跑起来”的
AI - ADK Runtime(运行时):Runner、Event Loop、Session/State 是怎么“跑起来”的?
当你用 ADK 写好 Agent、Tools、Callbacks 之后,真正“把它们跑起来”、并在用户交互时把整条链路串起来的,就是 ADK Runtime。它就是你 Agent 应用的“引擎”:你负责定义零件(agents/tools/callbacks),Runtime 负责把它们组织起来执行、管理信息流动、状态变化,以及与 LLM 或存储等外部服务交互。
一、Runtime 的核心思想:Event Loop(事件循环)
Runtime 的“心脏”是 Event Loop:它让 Runner 和你写的执行逻辑(Agents、LLM 调用、Callbacks、Tools)之间形成一种“你来我往”的协作。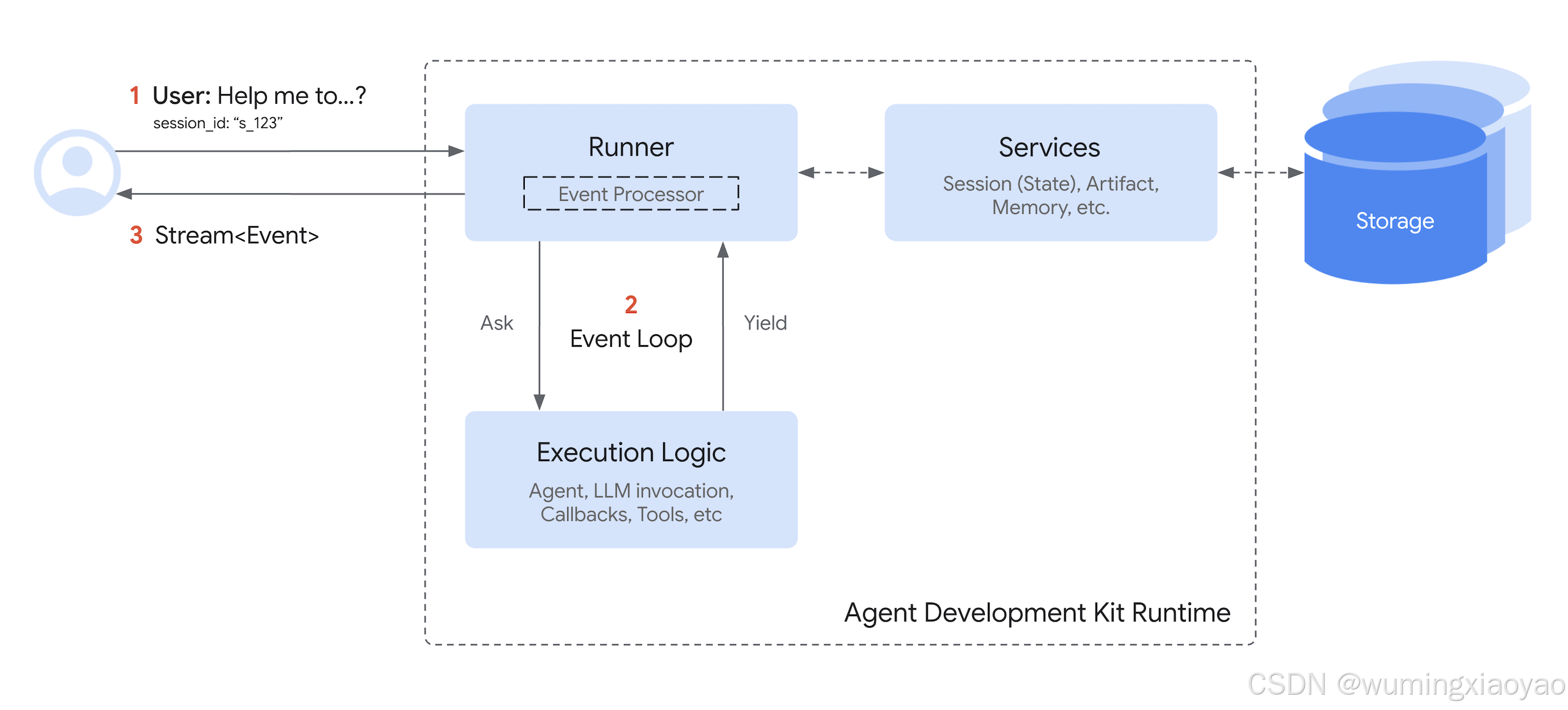
用 5 句话概括了这个循环:
- Runner 收到用户请求,叫主 Agent 开始处理
- Agent 运行到某个节点:需要说一句话/要调用工具/要改状态 —— 就“吐出”一个 Event
- Runner 收到 Event:把里面需要落地的动作处理掉(例如用 Services 保存状态),并把 Event 往上游转发(UI/调用方)
- 只有当 Runner 处理完这个 Event,Agent 才会从刚才暂停的位置继续跑,并且此时可以看到 Runner 已经提交的变化
- 重复上述过程,直到这个用户请求没有更多 Event 产出为止
你可以把它想象成:
Agent 负责“想”和“决定下一步做什么”,Runner 负责“把决定落地并把过程播报出去”。
二、Event Loop 的分工:Runner vs Execution Logic(Agent/Tool/Callback)
1. Runner 的职责:一次 invocation 的总调度(Orchestrator)
Runner 在一次用户请求(一次 invocation)里扮演“总控/编排器”。它的典型职责包括:
- 收到用户输入(new_message),通常会先通过 SessionService 把用户消息追加到会话历史
- 调用主 Agent 的执行方法启动事件流(例如 Python 的 agent.run_async(…))
- 等待 Agent yield/emit Event
- 拿到 Event 后,调用配置的 Services(Session/Artifact/Memory 等)去 提交 event.actions 里的变化(例如 state_delta、artifact_delta),做内部 bookkeeping
- 把处理后的 Event 往上游 yield 给 UI 或调用方
- 告诉 Agent:“这个 event 我处理完了”,Agent 才能继续生成下一个 Event
# Simplified view of Runner's main loop logic
def run(new_query, ...) -> Generator[Event]:
# 1. Append new_query to session event history (via SessionService)
session_service.append_event(session, Event(author='user', content=new_query))
# 2. Kick off event loop by calling the agent
agent_event_generator = agent_to_run.run_async(context)
async for event in agent_event_generator:
# 3. Process the generated event and commit changes
session_service.append_event(session, event) # Commits state/artifact deltas etc.
# memory_service.update_memory(...) # If applicable
# artifact_service might have already been called via context during agent run
# 4. Yield event for upstream processing (e.g., UI rendering)
yield event
# Runner implicitly signals agent generator can continue after yielding
2. 执行逻辑的职责:真正“干活”的地方(Agent/Tool/Callback)
你写的 Agents / Tools / Callbacks 属于“Execution Logic”。它们的工作方式有一个非常关键的节奏:
- Execute:基于当前 InvocationContext(包括当前可见的 session state)运行
- Yield:需要对外沟通时(输出文本、请求调用工具、报告状态变化等),构造一个包含内容与 actions 的 Event,把它 yield 给 Runner
- Pause:yield 之后立即暂停(Java 的 RxJava 场景对应 return/emit 的“暂停点”概念)
- Resume:Runner 处理并提交完 Event 后,你的逻辑才从 yield 下一行继续
- See Updated State:恢复执行后,可以可靠读取到 Runner 已提交的 ctx.session.state 变化
这就是为什么你会在 ADK 里频繁看到“事件驱动 / 生成器式输出 / 逐步产出事件”的形态:它不是语法花活,是 Runtime 的执行模型。
# Simplified view of logic inside Agent.run_async, callbacks, or tools
# ... previous code runs based on current state ...
# 1. Determine a change or output is needed, construct the event
# Example: Updating state
update_data = {'field_1': 'value_2'}
event_with_state_change = Event(
author=self.name,
actions=EventActions(state_delta=update_data),
content=types.Content(parts=[types.Part(text="State updated.")])
# ... other event fields ...
)
# 2. Yield the event to the Runner for processing & commit
yield event_with_state_change
# <<<<<<<<<<<< EXECUTION PAUSES HERE >>>>>>>>>>>>
# <<<<<<<<<<<< RUNNER PROCESSES & COMMITS THE EVENT >>>>>>>>>>>>
# 3. Resume execution ONLY after Runner is done processing the above event.
# Now, the state committed by the Runner is reliably reflected.
# Subsequent code can safely assume the change from the yielded event happened.
val = ctx.session.state['field_1']
# here `val` is guaranteed to be "value_2" (assuming Runner committed successfully)
print(f"Resumed execution. Value of field_1 is now: {val}")
# ... subsequent code continues ...
# Maybe yield another event later...
三、Runtime 的关键组件
Runtime 拆成以下几个关键部件
1. Runner
角色:入口与总编排器 (run_async)
功能:负责驱动 Event Loop、接收 Event、调用 Services 提交 actions、把 Event 往上游输出。
2. Execution Logic Components
角色:包含你写的自定义逻辑与核心能力:
组件:
- Agent(如 BaseAgent、LlmAgent 等):主要逻辑单元,最终会实现能产出 events 的执行方法( _run_async_impl 会 yield events)
- Tools(如 BaseTool、FunctionTool、AgentTool 等):给 Agent 用的外部能力(调用 API、执行特定任务等),执行后返回结果,再被包装进 Event
- Callbacks:挂在 Agent 上的一些函数钩子(例如 before_agent_callback、after_model_callback),能在执行流程特定点位介入,影响行为或 state;其效果同样会通过 Event 体现
功能: 执行实际的思考,计算或则外部交互。它们通过 yield(产出)Event 对象来传达自己的结果或需求,并在 Runner 处理这些 Event 之前暂停执行。
3. Event
角色:是 Runner 与执行逻辑之间传递的“消息”。
功能:它表示一次原子发生的事情:用户输入、Agent 输出文本、工具调用/返回、请求状态变化、控制信号等;同时还会携带“副作用意图”,即 actions(比如 state_delta)。
4. Services
角色:Services 是“持久化/共享资源”的后端组件,主要在 Runner 处理 Event 时使用
组件:
- SessionService:管理 Session(保存/加载),把 state_delta 应用到 session state,并把 events 追加到 event history
- ArtifactService:管理二进制 artifacts 的存取(例如 InMemory/GCS)。即使 save_artifact 是执行逻辑里通过 context 调用的,event 里的 artifact_delta 仍用来“确认这次动作”,供 Runner/SessionService 处理
- MemoryService(可选):管理跨 session 的长期语义记忆
功能:提供持久化层。Runner 会与这些组件进行交互,确保由 event.actions 标识的变更在执行逻辑(Execution Logic)继续运行之前,已经被可靠地存储。
5. Session
角色:Session 是一次“特定对话”的容器
功能:持有当前 state 字典、历史 events 列表(event history)、以及关联 artifacts 的引用等;它由 SessionService 管理。
6. Invocation
角色:Invocation 是一个“概念级术语”:从 Runner 收到单次用户请求开始,到该请求相关的 agent 逻辑不再产出 events 结束,这整段就是一次 invocation。
功能:一次 invocation 可能包含多次 agent run(例如 agent transfer 或 AgentTool)、多次 LLM 调用、多次 tool 执行、callback 执行等,它们通过同一个 InvocationContext 里的 invocation_id 串起来。还有一个很实用的细节:以 temp: 前缀命名的 state 变量严格限定在单次 invocation 内,invocation 结束后会被丢弃。
四、一次用户请求到底发生了什么?
一个典型例子:LLM Agent 在回答过程中调用一个工具。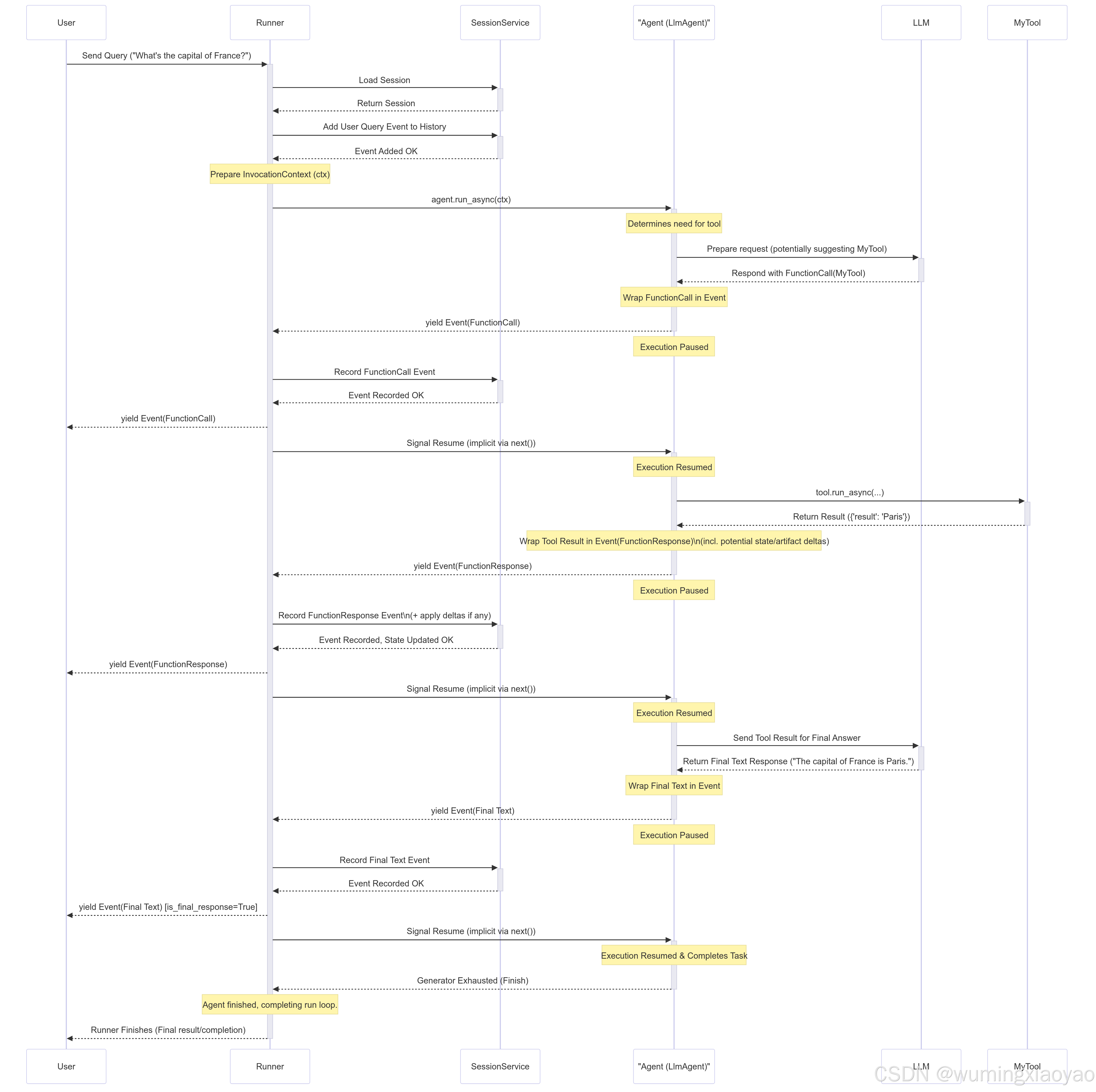
从用户输入到“请求调用工具”
- 用户发来问题
- Runner.run_async 启动:加载对应 Session,把用户输入作为第一个 Event 写入历史,并准备 InvocationContext
- Runner 调用 root agent 的 agent.run_async(ctx)
- LLM agent 判断可能需要工具,向 LLM 发请求;假设 LLM 决定调用 MyTool
- Agent 把 LLM 的 FunctionCall 包装成 Event 并 yield
- Agent 立刻暂停
- Runner 收到 FunctionCall Event:写入 session history,并向上游转发(UI/调用方)
- Runner 处理完成后,Agent 恢复执行
工具执行与工具结果回注
- Agent 开始执行 MyTool(调用 tool.run_async(…))
- Tool 返回结果
- Agent 把 FunctionResponse 包装成 Event yield(如果 tool 改了 state 或保存了 artifact,这个 Event 里也会带 state_delta / artifact_delta)
- Agent 再次暂停
- Runner 收到 FunctionResponse Event:交给 SessionService 应用 state_delta / artifact_delta 并记入历史,然后转发上游
- Agent 恢复执行,并且此时可以认为 tool 结果和状态变化已经提交
- Agent 把工具结果再发给 LLM,让 LLM 生成自然语言回答
最终回答与收尾
- Agent 把最终文本包装成 Event yield
- Agent 暂停
- Runner 记录并转发最终文本 Event(这通常会被标记为 is_final_response())
- Agent 恢复并结束本次 run_async
- Runner 发现生成器耗尽,结束本次 invocation 的循环
强调:这种 yield/pause/process/resume 的循环,保证了状态变化的一致性,并让执行逻辑在 yield 之后总能看到“最新已提交状态”。
五、Runtime 最关键、也最容易踩坑的行为
因为很多“我明明改了 state,为啥没生效”的疑问,都在这里。
1. 状态更新的提交时机:不是你写进去就立刻“持久化”
规则(The Rule):当你在 agent/tool/callback 中修改 session state(例如 context.state[…] = …),它会先记录在当前 InvocationContext 的本地变更里;只有当携带相应 state_delta 的 Event 被你 yield 出去,并且被 Runner 处理后,才保证被 SessionService 持久化保存。
含义(Implication):在 yield 之后恢复执行的代码,才可以可靠假设:上一个事件声明的状态变化已经提交。
# Inside agent logic (conceptual)
# 1. Modify state
ctx.session.state['status'] = 'processing'
event1 = Event(..., actions=EventActions(state_delta={'status': 'processing'}))
# 2. Yield event with the delta
yield event1
# --- PAUSE --- Runner processes event1, SessionService commits 'status' = 'processing' ---
# 3. Resume execution
# Now it's safe to rely on the committed state
current_status = ctx.session.state['status'] # Guaranteed to be 'processing'
print(f"Status after resuming: {current_status}")
2. “Dirty Reads”:同一次 invocation 内,你可能读到“未提交但已写入本地”的状态
定义:提交发生在 yield 之后;但在同一个 invocation 中,如果在 state-changing event 真正 yield/被 Runner 处理之前,后续运行的代码往往仍然能读到本地未提交的改动,这叫 dirty read。
例如:
# Code in before_agent_callback
callback_context.state['field_1'] = 'value_1'
# State is locally set to 'value_1', but not yet committed by Runner
# ... agent runs ...
# Code in a tool called later *within the same invocation*
# Readable (dirty read), but 'value_1' isn't guaranteed persistent yet.
val = tool_context.state['field_1'] # 'val' will likely be 'value_1' here
print(f"Dirty read value in tool: {val}")
# Assume the event carrying the state_delta={'field_1': 'value_1'}
# is yielded *after* this tool runs and is processed by the Runner.
影响(Implications):
- 好处:同一个复杂步骤里(例如多个 callback + 多次工具调用,且还没走到下一次 yield/commit),各个逻辑片段可以通过 state 协调
- 风险:如果 invocation 在对应事件 yield/被 Runner 处理前失败,那么这些“未提交改动”会丢失;关键状态迁移要确保最终能跟随某个会被 Runner 成功处理的 Event 一起提交
3. Streaming vs 非 Streaming:为什么有 partial=True,以及它对 state 意味着什么
当使用 streaming 生成时,LLM 会分块/逐 token 产生输出,框架通常会为“一次概念上的回复” yield 多个 Event,其中大多数会标记 partial=True。
- Runtime 的关键行为是:
Runner 收到 partial=True 的 Event:一般会立即转发上游(让 UI 实时展示),但跳过处理其 actions(例如不提交 state_delta)直到框架 yield 最终的“非 partial”事件(partial=False 或通过 turn_complete=True 体现),Runner 才会完整处理它并提交 state_delta / artifact_delta
非 streaming:一次性生成完整回复,通常只 yield 一个非 partial Event,Runner 直接完整处理并提交
为什么重要:它保证 state changes 只会基于“完整输出”被原子地提交一次,同时 UI 仍能流式显示。
六、Async 是主角:run_async 是 Runtime 的主入口
核心设计:ADK Runtime 是以异步模式为基础设计的(例如 Python asyncio、Java RxJava、TypeScript 的 Promise/AsyncGenerator 等),目的是高效处理并发等待(LLM 响应、工具执行等)而不阻塞。
主入口:Runner.run_async 是执行一次 agent invocation 的主要方法
同步便捷方法:也存在 Runner.run 作为方便用法(脚本/测试常见),但内部通常只是调用 run_async 并代你管理异步事件循环
开发者体验(Developer Experience):建议将你的应用(例如基于 ADK 的 Web 服务)设计为异步架构,以获得最佳性能。在 Python 中,这意味着使用 asyncio;在 Java 中,推荐使用 RxJava 的响应式编程模型;在 TypeScript 中,则应基于原生的 Promise 和 AsyncGenerator 来构建。
同步回调 / 工具(Sync Callbacks / Tools):ADK 框架同时支持异步函数和同步函数,可用于工具(tools)和回调(callbacks)。
- 阻塞式 I/O(Blocking I/O):对于耗时较长的同步 I/O 操作,框架会尽量避免阻塞整体执行流程:
- 在 Python ADK 中,可能会使用 asyncio.to_thread 将阻塞操作放入线程中执行;
- 在 Java ADK 中,通常依赖合适的 RxJava Scheduler 或对阻塞调用进行包装;
- 在 TypeScript 中,框架只是简单地 await 该函数,如果同步函数内部执行了阻塞式 I/O,就会阻塞事件循环。
👉 因此,强烈建议开发者尽可能使用异步 I/O API(即返回 Promise 的接口)。
- CPU 密集型任务(CPU-Bound Work):
纯粹的 CPU 密集型同步任务,在所有环境中仍然会阻塞其所在的执行线程,这是不可避免的。
七、你学会了什么?(把 Runtime 用在排查问题上)
读懂 Runtime 后,你应该能用一套非常实用的方式定位问题:
- Agent 为什么会“停一下再继续”?
因为它 yield Event 后会暂停,等待 Runner 处理/提交 actions,再 resume。 - 我在 tool/callback 里写了 state,为什么别处看不到/重启后丢了?
看你是不是在真正 yield 出携带 state_delta 的 Event 之前就结束/失败了;提交时机在 “yield → Runner 处理” 之后才有保证。 - 为什么 streaming 时 state 似乎不更新?
因为 partial=True 的事件通常不会被 Runner 提交 actions;要等最终非 partial 事件。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)