《PCI EXPRESS体系结构导读》---(7)cache相关的事务
有关cache中的MESI协议,可以参考这个博客:【Cache篇】MESI协议
HIT#和HITM#信号
在SMP系统中,每个CPU都使用HIT#和HITM#信号来反映HOST主桥访问的地址是否在各自的cache中命中。各个CPU的**HIT#和HITM#**信号通过线与的方式直接相连。

cache一致性中的Agent:
- request agent,FSB总线的发起设备。
- snoop agents,FSB总线的监听设备。这是指多个CPU,agent会判断总线事务访问的地址是否在cache中命中。通过HIT#和HITM#信号向FSB通知cache命中结果,某些情况下,需要价格cache中的数据写回DDR,同时为request agent提供数据。
- response agent,FSB总线的目标设备。特指DDR控制器,response agent根据snoop agents提供的监听结果,决定如何接收数据/向request agent设备提供数据。多数情况下,当前数据访问没有在snoop agent中命中时,response agent需要提供数据,此外snoop agents有时需要将数据写回到response agent中。
FSB的总线事务由多个阶段组成。包括request phase,snoop phase,response phase和data phase。支持流水线操作,同一个时间内,不同的阶段可以叠加。
request phase:request agent在获得FSB总线的使用权后,在该阶段将访问数据区域的地址和总线事务发送到FSB上。
snoop phase:snoop agents根据访问数据区域在cache中的命中情况,使用HIT#和HITM#信号,向其他agents通知cache一致性结果。有时snoop agent需要将数据回写到DDR。
response phase:response agent根据request和snoop阶段提供的信号,可以要求request agent重试,或者request agent延迟处理当前总线事务。
data phase:该阶段用于数据传输,包括request agent向response agent写入数据,response agent为request agent提供数据,snoop agent将数据回写到response agent。
PCI设备对不可cache的DDR空间进行DMA读写
处理器中的inbound寄存器可以设置是否使能cache一致性操作。如果访问不可cache空间时,处理器会忽略FSB总线数据的snoop phase。数据将直接进入DDR。PCI读的数据将直接从DDR中获得。
PCI设备对可cache的DDR空间进行DMA读写
PCI 设备向“可 Cache 的存储器空间”进行读操作相对简单。如果访问的数据在 Cache 中命中,CPU 会通知 FSB 总线,PCI 设备所访问的数据在 Cache 中。
首先 HOST 主桥发起DDR读总线事务,并在 Request Phase 中提供地址。Snoop Agent在 Snoop Phase 进行总线监听,并通过 HIT#和 HITM#信号将监听结果通知给 Response Agent。如果 Cache 行的状态为 E 时,Response Agent 将提供数据,而 CPU 不必改变 Cache 行状态。
如果 Cache 行的状态为 M 时,Response Agent 在 Response Phase 阶段,要求 Snoop Agent将 Cache 中的数据回写到DDR,并将 Cache 行状态更改为 E。Snoop Agent 在 Data Phase 将 Cache 中的数据回写给DDR控制器,同时为 HOST 主桥提供数据。
当 PCI 设备访问的数据未在 Cache 中命中时,Snoop Agents 会通知 FSB 总线,表明 PCI 设备所访问的数据不在 Cache 中。此时,DDR控制器(Response Agent)将在 Data Phase 向 HOST 主桥提供数据。
PCI 设备对“可 Cache 的”DDR区域进行写操作,当 HOST 主桥通过 FSB 将数据发送给DDR控制器时,系统总线上的所有 CPU 都需对这个 PCI 写操作进行监听,并根据监听结果,合理地改动 Cache 行状态,同时将数据写入DDR。
以图3-7所示的 SMP 处理器系统为例,可说明 PCI 设备对“可 Cache 的存储器空间”进行 DMA 写的实现过程。
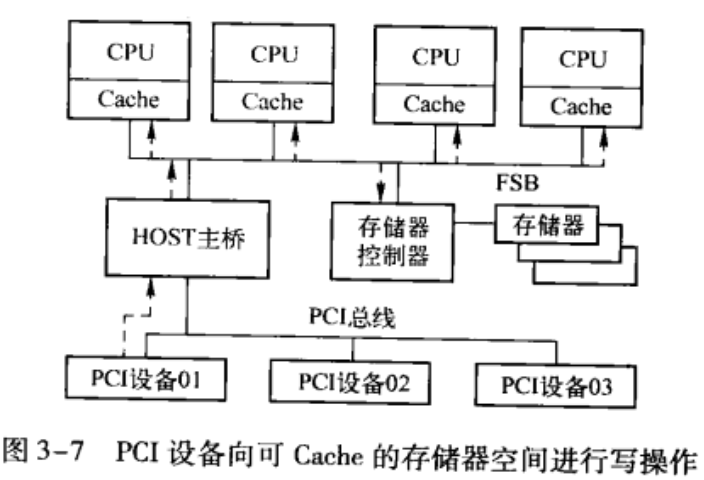
在图3-7所示的处理器系统中,存在4个CPU,这4个CPU通过一条FSB连接在一起,而CPU之间使用MESI协议进行Cache一致性处理,HOST主桥和DDR控制器与FSB直接相连。HOST主桥向DDR控制器传递数据时,需要处理Cache的一致性。
在这个处理器系统中,当PCI设备(如PCI设备01)进行DMA写操作时,数据将首先到达HOST主桥,HOST主桥将首先接管该PCI设备数据访问并将其转换为FSB总线事务,并在Request Phase中提供本次FSB总线事务的地址。CPU将在Snoop Phase对这个地址进行监听,判断当前地址在Cache中的命中情况。
当HOST主桥访问的地址不在Cache中命中时,此时在处理器系统中,所有CPU都没有驱动HIT#和HITM#信号,HIT#和HITM#信号都为1,表示HOST主桥访问的地址没有在CPU的Cache中命中,HOST主桥可以简单地将数据写入DDR。当HOST主桥访问的DDR地址在Cache中命中时,Cache行的状态可以为S、E或者为M,此时处理器系统的处理过程相对较为复杂,下一节将专门讨论这种情况。
PCI设备进行DMA写时发生cache命中
当 PCI 设备访问的地址在某个 CPU 的 Cache 行中命中时,可能出现三种情况:
- Cache 行状态为 E(Exclusive):表示该数据在 SMP 处理器系统中,有且仅有一个 CPU 的 Cache 中具有数据副本。此时处理较为简单,CPU 仅需在 Snoop Phase 使无效(Invalidate)该 Cache 行,然后 FSB 总线事务将数据写入存储器即可。若 FSB 总线事务能直接将数据写入 Cache 并将 Cache 行状态更改为 M,可提高 DMA 写效率,但实现难度较大。
- Cache 行状态为 S(Shared):表示该数据在 SMP 处理器系统中,至少在两个以上 CPU 的 Cache 中具有数据副本。处理方式与状态为 E 时大同小异,PCI 设备在进行写操作时也将数据直接写入主存储器,并使无效状态为 S 的 Cache 行。
- Cache 行状态为 M(Modified):表示 Cache 行中的数据与存储器的数据不一致,Cache 行中保存最新的数据副本,主存储器中的部分数据无效。对于 SMP 系统,此时有且仅有一个 CPU 中的 Cache 行的状态为 M。假设处理器的 Cache 使用回写(Write-Back)策略进行更新,当 HOST 主桥对存储器的某个地址进行写操作时,若该地址在某个 CPU 的 Cache 行命中且状态为 M,则该 CPU 将置 HITM# 信号为 0,并置 HIT# 信号为 1,表示当前 Cache 行中含有的数据比存储器中含有的数据更新。
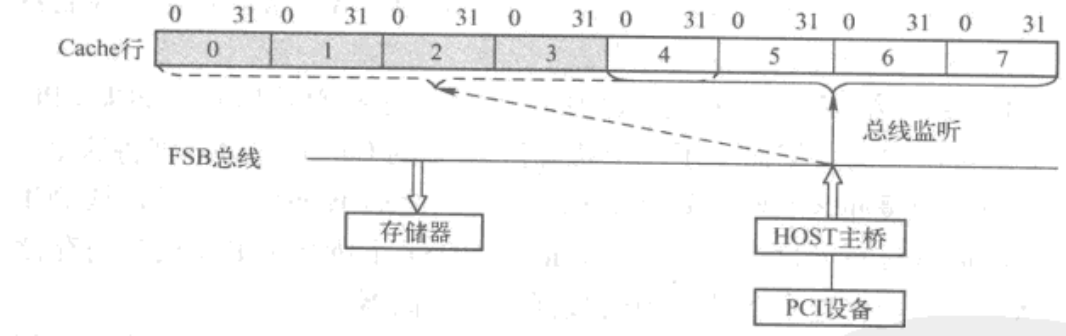
若此时在 Cache 行中,阴影部分的数据比存储器中的数据新,而其他数据与存储器保持一致(即第 0-3 个双字的数据是当前处理器系统中最新的数据,而第 4-7 个双字中的数据与存储器保持一致),且 PCI 设备向存储器写的数据区域可以完全覆盖这些阴影部分(如对第 0~5 个双字进行写操作),则处理不难。此时 CPU 只需在总线监听阶段将这个 Cache 行使无效,然后将数据写入存储器即可。因为完成这个存储器写操作之后,PCI 设备写入的数据是最新的,并且将完全覆盖在 Cache 行中阴影部分的数据,所以 CPU 只需要简单地将这个 Cache 行使无效即可。
当PCI设备写操作命中状态为M的Cache行时,因无法预知Cache行内有效数据范围,不能简单使其无效。若PCI设备写入数据(如第4 - 7个双字)命中状态为M且部分数据(前4个双字)被修改的Cache行,直接无效会丢失有效数据。HOST主桥处理该情况有三种方法:
①CPU监听到命中状态为M的Cache行,通知HOST主桥重试/延时,待CPU同步该Cache行与存储器后无效Cache行,HOST主桥重试写操作;
②HOST主桥将PCI设备写数据放入存储器控制器一个缓冲区,结束PCI写事务,CPU监听到命中状态为M的Cache行时,将其放入另一缓冲区后无效Cache行,最后存储器控制器合并两缓冲区数据写入存储器;
③HOST主桥不结束当前PCI总线周期,直接监听,若命中状态为M的Cache行,将该Cache行写入存储器控制器缓冲区后无效Cache行,再接收PCI设备数据写入该缓冲区,最后结束PCI写事务并将缓冲区数据写入存储器。其中第1种方法最常用,x86处理器的implicit writeback方式与第2种类似,第3种与第2种无本质不同。
当 PCI 设备对一个或多个完整 Cache 行的存储器区域进行写操作时,上述复杂处理过程显得多余。因为对完整 Cache 行写操作可保证完全覆盖对应存储器区域,操作完成后该区域数据在处理器系统中不再最新。此时 PCI 设备可直接将数据写入存储器,同时直接使无效状态为 M 的 Cache 行。
PCI 总线使用“存储器写并无效(Memory Write and Invalidate)”总线事务支持对完整 Cache 行的写操作。使用该事务时,PCI 设备必须事先知道当前处理器系统中 CPU 使用的 Cache 行大小,一次总线事务传递数据大小需以 Cache 行为单位对界。为此,PCI 设备需使用配置寄存器 Cache Line Size 保存当前 Cache 行大小,该寄存器在 PCI 配置空间。
此外,存储器读(Memory Read)、存储器多行读(Memory Read Multiple)和存储器单行读(Memory Read Line)总线事务也是 PCI 总线中的重要事务,它们不仅与 Cache 有关,还与 PCI 总线的预读机制相关。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)