2025年睿抗机器人开发者大赛CAIP-编程技能赛-本科组(国赛)解题报告 | 珂学家
本文是2025年睿抗机器人开发者大赛CAIP编程技能赛本科组(国赛)解题报告,包含5道题目的题解和代码实现。 RC-u1题(15分):使用哈希表处理投票数据,考虑减半影响操作的特殊情况。 RC-u2题(20分):模拟包裹填充过程,通过相对偏移向量匹配物品坐标与包裹空间。 RC-u3题(25分):利用栈结构处理字符串删除操作,统计特定模式串的删除次数。 RC-u4题(30分):采用二分查找结合Dij
前言

题解
2025年睿抗机器人开发者大赛CAIP-编程技能赛-本科组(国赛)解题报告
睿抗一如既往的码量大,喜欢阅读理解挖坑,T_T。
T3 应该是最简单,如果去掉匹配串 2 字节的限制,感觉会是一道有趣的题。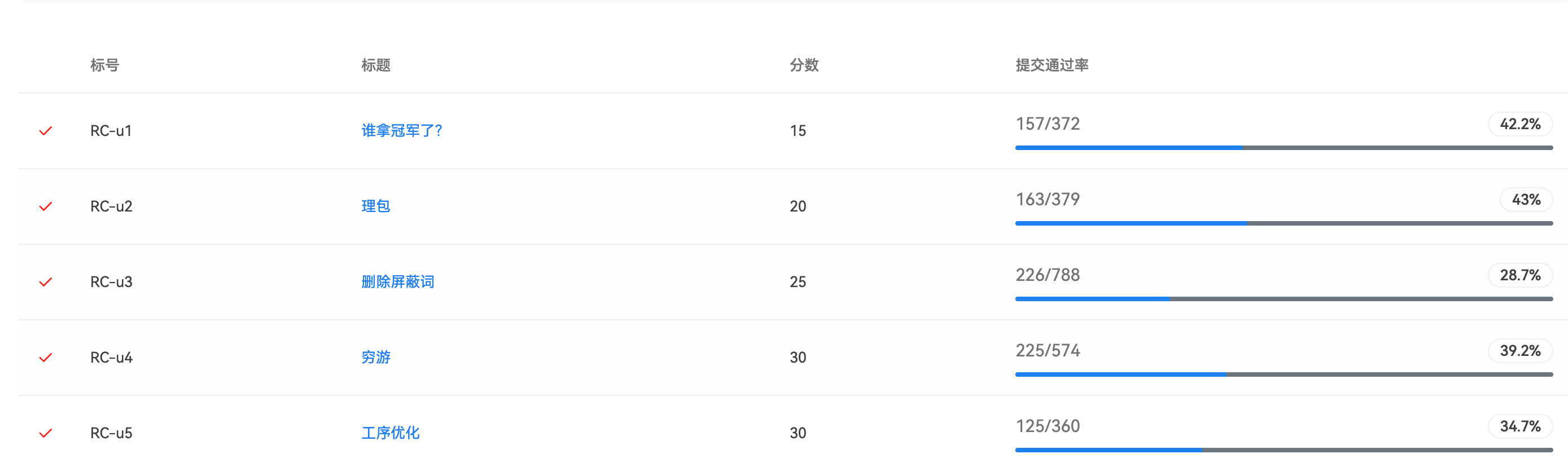
RC-u1 谁拿冠军了?
分值: 15分
考察点:hash表的使用
注意点:明明某一天里,可能存在多个相同操作,需要求其总和,在除 2。
#include <bits/stdc++.h>
using namespace std;
int main() {
int n, m;
cin >> n >> m;
int A1, A2, B1, B2, B3;
cin >> A1 >> A2 >> B1 >> B2 >> B3;
// 利用 array<int, 2> 表示二元组 (d,op)
map<array<int, 2>, int> ops;
for (int i = 0; i < n; i++) {
int d, op;
cin >> d >> op;
ops[{d, op}] += 1;
}
// 题意保证 一天最多一个操作
map<int, int> ban;
for (int i = 0; i < m; i++) {
int t, op;
cin >> t >> op;
ban[t] = op;
}
int sw1 = 0, sw2 = 0;
for (auto [k, cnt] : ops) {
auto [d, op] = k;
// 减半影响的操作
if (ban.count(d) && ban[d] == op) {
if (op == 1) {
sw1 += A1 * cnt;
sw2 -= B1 * cnt / 2;
} else if (op == 2) {
sw2 -= B2 * cnt / 2;
} else if (op == 3) {
sw1 -= A2 * cnt;
sw2 -= B3 * cnt / 2;
}
} else {
if (op == 1) {
sw1 += A1 * cnt;
sw2 -= B1 * cnt;
} else if (op == 2) {
sw2 -= B2 * cnt;
} else if (op == 3) {
sw1 -= A2 * cnt;
sw2 -= B3 * cnt;
}
}
}
cout << sw1 << " " << sw2 << "\n";
return 0;
}
RC-u2 理包
分值: 20分
思路:模拟
枚举包裹的空坐标,然后以物品坐标系,以相对偏移向量尝试填充匹配
感觉码量有点大,看起来简单,但写起来稍头痛。
#include <bits/stdc++.h>
using namespace std;
int main() {
int n, m, q;
cin >> n >> m >> q;
vector<string> g(n);
for (int i = 0; i < n; i++) {
g[i].resize(m, '.');
}
while (q-- > 0) {
int r, c;
cin >> r >> c;
vector<string> mat(r);
int sy = -1, sx = -1;
for (int i = 0; i < r; i++) {
cin >> mat[i];
if (sy == -1) {
for (int j = 0; j < c; j++) {
if (mat[i][j] == '*') {
sy = i; sx = j;
break;
}
}
}
}
// 以物品坐标去匹配包裹,oy/ox是相对偏移向量
auto check = [&](int oy, int ox) -> bool {
for (int i = 0; i < r; i++) {
for (int j = 0; j < c; j++) {
if (mat[i][j] == '*') {
if (i + oy >= 0 && i + oy < n && j + ox >= 0 && j + ox < m) {
if (g[i + oy][j + ox] == '*') {
return false;
}
} else {
return false;
}
}
}
}
return true;
};
// 以物品坐标去填充包裹,oy/ox是相对偏移向量
auto fill = [&](int oy, int ox) {
for (int i = 0; i < r; i++) {
for (int j = 0; j < c; j++) {
if (mat[i][j] == '*') {
g[i + oy][j + ox] = '*';
}
}
}
};
// 从包裹坐标出发,寻找空格去,查询是否放入物品
auto solve = [&](int &ay, int &ax) -> bool {
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (g[i][j] == '.') {
if (check(i - sy, j - sx)) {
ay = i; ax = j;
fill(i - sy, j - sx);
return true;
}
}
}
}
return false;
};
int ay = 0, ax = 0;
if (solve(ay, ax)) {
cout << (ay + 1) << " " << (ax + 1) << "\n";
} else {
cout << -1 << " " << -1 << "\n";
}
}
return 0;
}
RC-u3 删除屏蔽词
分值: 25分
思路:模拟+栈
这题限定模式串固定为2,如果为k,那这题就麻烦了。
就是当前字符,以及栈顶元素,是否构成模式串
注意: 需要输出 删除次数,不是最后文本的长度
#include <bits/stdc++.h>
using namespace std;
int main() {
string p;
string s;
getline(cin, p);
getline(cin, s);
int del = 0;
stack<char> stk;
for (char c: s) {
// 核心代码,就是这一行
if (c == p[1] && !stk.empty() && stk.top() == p[0]) {
stk.pop();
del++;
} else {
stk.push(c);
}
}
string buf;
while (!stk.empty()) {
buf.push_back(stk.top());
stk.pop();
}
reverse(buf.begin(), buf.end());
cout << del << " " << buf << "\n";
return 0;
}
RC-u4 穷游
分值: 30分
思路:二分 + dijkstra
可以先确定最小的住宿费用,再求解此基础上的最小时长。
这个套路,在睿抗编程赛中,多次出现。
二分check的核心逻辑是连通性,为了简化代码,可以复用带限制的求时长dijkstra
这样在追求编码效率 和 代码 AC 之间达到一个好的平衡。
#include <bits/stdc++.h>
using namespace std;
struct E {
int v, w;
E() {}
E(int v, int w)
: v(v), w(w) {}
};
struct P {
int u, c;
P() {}
P(int u, int c)
: u(u), c(c) {}
};
int main() {
int n, m;
cin >> n >> m;
vector<int> prices(n);
for (int &x: prices) cin >> x;
vector<vector<E>> g(n);
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
u--; v--;
g[u].push_back(E(v, w));
g[v].push_back(E(u, w));
}
int s, e;
cin >> s >> e;
s--; e--;
auto comp = [](const P&lhs, const P&rhs) {
return lhs.c > rhs.c;
};
int inf = 0x3f3f3f3f;
auto dijkstra = [&](int limit) {
vector<int> dp(n, inf);
dp[s] = 0;
priority_queue<P, vector<P>, decltype(comp)> pq(comp);
pq.push(P(s, 0));
while (!pq.empty()) {
P p = pq.top(); pq.pop();
if (p.c > dp[p.u]) continue;
// 提前返回
if (p.u == e) {
return p.c;
}
for (E &e: g[p.u]) {
if (prices[e.v] > limit) continue;
if (dp[e.v] > p.c + e.w) {
dp[e.v] = p.c + e.w;
pq.push(P(e.v, dp[e.v]));
}
}
}
return inf;
};
int l = 0, r = *max_element(prices.begin(), prices.end());
// 二分确认最小费用
while (l <= r) {
int mid = l + (r - l) / 2;
int ret = dijkstra(mid);
if (ret != inf) {
r = mid - 1;
} else {
l = mid + 1;
}
}
// 再求解最小时长
int ret = dijkstra(l);
cout << l << " " << ret << "\n";
return 0;
}
RC-u5 工序优化
分值: 30
思路: 动态规划
题目可以归纳如下,更好的理解
定义一个merge操作
-
第i项可以和第i-1项合并,时间合并,工作时间按第i-1项为准,但需额外消耗 CiC_iCi
-
合并可以连续,即 [ia, b]的连续区间可以合并,操作次数为(b - a)次
-
这个操作为最多 k 次
如何理解呢?
定义把[a, b]连续区间进行合并,则
E[a,b]合并的时间消耗=(∑i=ai=bPi)∗Ta,E[a, b]合并的时间消耗=(\sum_{i=a}^{i=b} P_i) * T_a,E[a,b]合并的时间消耗=(i=a∑i=bPi)∗Ta,
E[a,b]合并的代价=cost[a,b]=∑i=a+1i=bCiE[a, b]合并的代价= cost[a, b]=\sum_{i=a+1}^{i=b} C_i E[a,b]合并的代价=cost[a,b]=i=a+1∑i=bCi
能理解这个核心的概念后,那个这个 dp 就相对容易解了
-
定义状态
dp[i][j]为前i项,使用j次merge操作的最小时间/代价dp[i][j] 为前 i 项,使用 j 次merge 操作的最小时间/代价dp[i][j]为前i项,使用j次merge操作的最小时间/代价
-
转移方程
dp[i+1+s][j+s]=mins∈[0,k−j]dp[i][j]+E[i+1,i+1+s]dp[i + 1 + s][j + s] = \min_{s\in[0, k - j]} { dp[i][j] + E[i + 1, i + 1 + s] }dp[i+1+s][j+s]=s∈[0,k−j]mindp[i][j]+E[i+1,i+1+s]
-
结果
ans=minj∈[0,k]dp[n−1][j] ans = \min_{j\in[0, k]} { dp[n - 1][j] } ans=j∈[0,k]mindp[n−1][j]
时间复杂度为O(n∗k2)O(n*k^2)O(n∗k2)
#include <bits/stdc++.h>
using namespace std;
const int64_t inf = (int64_t)1e18;
struct W {
int t, p, c;
W() {}
W(int t, int p, int c)
: t(t), p(p), c(c) {}
};
struct E {
int64_t p = inf;
int64_t c = 0;
// 重定义<, +
bool operator<(const E&rhs) const {
return p != rhs.p ? p < rhs.p : c < rhs.c;
}
E operator+(const E&rhs) const {
return {p+rhs.p, c+rhs.c};
}
};
int main() {
int n, k;
cin >> n >> k;
vector<W> tasks(n);
for (int i = 0; i < n; i++) {
W &w = tasks[i];
cin >> w.t >> w.p >> w.c;
}
// 预处理,时间和费用的前缀和
vector<int64_t> pre_p(n + 1, 0);
vector<int64_t> pre_c(n + 1, 0);
for (int i = 0; i < n; i++) {
pre_p[i + 1] = pre_p[i] + tasks[i].p;
pre_c[i + 1] = pre_c[i] + tasks[i].c;
}
// 定义 dp[i][j], 前i项使用j次操作的最小时间/费用
vector<vector<E>> dp(n, vector<E>(k + 1));
for (int i = 0; i <= k && i < n; i++) {
dp[i][i] = {(pre_p[i + 1] - pre_p[0]) * tasks[0].t, pre_c[i + 1] - pre_c[1]};
}
// 刷表
for (int i = 0; i < n; i++) {
for (int j = 0; j <= k; j++) {
for (int s = 0; s + j <= k && i + s + 1 < n; s++) {
E tmp = {
(pre_p[i + s + 2] - pre_p[i + 1]) * tasks[i + 1].t,
pre_c[i + s + 2] - pre_c[i + 2]
};
E tmp2 = dp[i][j] + tmp;
if (tmp2 < dp[i + s + 1][j+s]) {
dp[i + s + 1][j + s] = tmp2;
}
}
}
}
E ans = {inf, 0};
for (int i = 0; i <= k; i++) {
if (dp[n - 1][i] < ans) {
ans = dp[n - 1][i];
}
}
cout << ans.p << " " << ans.c << "\n";
return 0;
}
写在最后


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)