ai学习笔记(一)
AI发展经历了符号主义、统计学习和深度学习三个阶段,从基于规则到依赖大数据,逐步实现从感知到认知的突破。NLP面临歧义性、上下文依赖等挑战,大模型时代还面临幻觉、偏见等问题。机器学习包括监督、无监督、半监督和强化学习等范式,各有适用场景。完整机器学习流程涵盖数据收集、特征工程、模型训练到部署监控等环节。模型训练需解决欠拟合、过拟合、训练不收敛等问题,通过调整模型复杂度、数据增强等方法优化。AI发展
1. AI发展历程
| 符号主义(1956-1974) | 统计学习(1980-1987) | 深度学习(2012-至今) | |
| 技术基础 | 逻辑推理、专家系统 | 支持向量机、决策树 | 神经网络、注意力机制 |
| 数据依赖 | 少量数据 | 需要标注数据 | 需要海量数据 |
| 代表成果 | 通用问题求解器(GPS) | 贝叶斯网络 | 阿尔法go、GPT |
| 主要局限 | 无法处理不确定星 | 泛化能力有限 | 黑箱问题、能耗高 |
| 衰退原因 | 计算能力不足 | 商业化失败 | 上升期 |
黑箱问题:一种不关注内部结构或运作机制,而只关注输入与输出之间关系的研究方法。
演进规律总结:
-
从规则到数据:从人类赋予知识,到机器从数据中自己发现知识。
-
从专项到通用:从解决单一任务的“窄AI”,向能处理多任务的“通用AI”底座演进。
-
从感知到认知:从图像识别(感知)发展到语言理解、逻辑推理(认知)。
-
“三要素”螺旋上升:新算法思想渴求更大算力和数据,算力和数据的增长又催生新的算法思想。
2. NLP的核心任务及面临的挑战
NLP为Nature Language Process缩写,目标是让机器理解、解释和生成人类语言。
核心任务分为NLU(Nature Language Understand)和NLG(Nature Language Genarate)
面临的挑战:
-
歧义性:一词多义(“苹果”)、句法歧义(“咬死了猎人的狗”)
-
上下文依赖:指代关系(“他喜欢打篮球,打的很好。”)
-
文化差异:言语理解(“画蛇添足”)、情感表达差异
大模型时代的特定挑战:
-
幻觉:生成看似合理但事实错误的内容。
-
偏见与安全:放大训练数据中的社会偏见,生成有害内容。
-
可解释性差:难以理解决策过程(“黑箱”问题)。
常用的消除歧义方法:
上下文语境分析、常识知识库、机器学习模型(BERT通过上下文嵌入消除歧)
3. 不同机器学习范式的适用场景
机器学习是人工智能的一个分支,它使计算机系统能够通过经验自动进行改进。
AI四要素:算法、算力、场景、数据。
泛化能力:模型适应新样本的能力。
-
监督学习
-
定义:使用 “带标签的数据” 进行训练。模型学习从输入到输出的映射函数。
-
场景:任务目标明确,有历史标注数据。
-
典型算法:线性回归、逻辑回归、SVM、决策树、神经网络。
-
例子:垃圾邮件分类(输入邮件,输出是否为垃圾)、房价预测。
-
-
无监督学习
-
定义:使用 “无标签的数据” 进行训练。模型发现数据内在的模式或结构。
-
场景:探索数据,发现未知分组或简化数据。
-
典型算法:K-Means聚类、主成分分析、自编码器。
-
例子:客户细分、新闻主题聚类、数据降维可视化。
-
-
半监督学习
-
定义:同时使用少量标注数据和大量未标注数据进行训练。
-
场景:标注成本高,但未标注数据易获得。
-
例子:在医疗影像中,专家标注少量肿瘤图片,利用大量未标注图片提升模型性能。
-
-
强化学习
-
定义:智能体通过与环境交互试错,根据获得的奖励或惩罚来学习最优策略。
-
场景:序列决策问题,有明确的目标和规则环境。
-
关键概念:状态、动作、奖励、策略。
-
例子:AlphaGo、机器人控制、游戏AI、推荐系统的长期收益优化。
-
-
深度学习/表示学习
-
定义:一种能够从原始数据中自动学习多层次抽象特征的方法,可应用于以上多种范式。
-
场景:处理高维、复杂的非结构化数据(图像、文本、语音)。
-
例子:CNN用于图像(监督),Transformer用于NLP(监督/自监督)。
-

常用算法对比:
|
算法类型 |
核心原理 |
优点 |
缺点 |
案例 |
|
线性回归 |
拟合线性方程 y=wx+b |
简单易解释训练速度快 |
无法处理非线性关系 |
波士顿房价预测 |
|
逻辑回归 |
用Sigmoid函数输出概率 |
可输出概率值模型轻量 |
表达能力有限 |
信用卡欺诈检测 |
|
决策树 |
模拟人类决策过程通过特征分裂构建树 |
可处理非线性关系无需特征缩放 |
容易过拟合不稳定 |
贷款违约预测 |
|
随机森林 |
多棵决策树集成投票决定结果 |
泛化能力强抗过拟合 |
模型复杂解释性差 |
客户流失预测 |
|
神经网络 |
模拟人脑神经元连接多层非线性交换 |
处理复杂模式表达能力强 |
需大量数据训练成本高 |
手写数字识别 |

4. 机器学习完整工作流程
标准化流程:
-
业务理解:明确"要解决什么问题",设定可量化评估标准。
-
数据收集与理解:数据来源探索,统计描述与可视化分析。
-
数据预处理:处理缺失值、异常值、重复数据。
-
特征工程:特征创建、选择与降维处理。
-
模型训练与调优:算法选择与参数优化。
-
模型评估:在测试集上评估性能,分析错误案例。
-
模型部署与监控:集成到业务系统,实时监控性能变化。
-
持续优化:定期重新训练模型以适应数据变化。
-
交叉验证:确保模型稳定性。
-
与业务目标对比:判断是否达标。

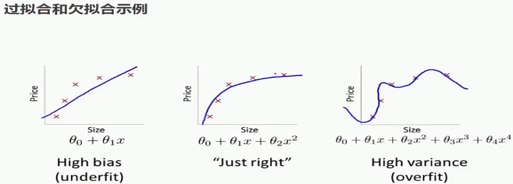
5. 模型训练中的常见问题
| 问题现象 | 可能原因 | 诊断方法 | 解决方案 |
|---|---|---|---|
| 欠拟合 | 1. 模型太简单(能力不足) 2. 特征信息不足 3. 训练轮次太少 |
训练集和验证集误差都很高 | 1. 使用更复杂的模型(增加深度/宽度) 2. 做更好的特征工程 3. 增加训练轮次 |
| 过拟合 | 1. 模型太复杂(记忆噪声) 2. 训练数据太少 3. 训练轮次过多 |
训练集误差低,验证集误差高 | 1. 正则化(L1/L2, Dropout) 2. 获取更多训练数据/数据增强 3. 早停 4. 降低模型复杂度 |
| 训练不收敛/震荡 | 1. 学习率设置不当(过大或过小) 2. 梯度爆炸/消失(深度学习) 3. 数据预处理问题 |
观察损失曲线,看是否下降平缓或剧烈波动 | 1. 调整学习率(使用学习率调度器) 2. 梯度裁剪(解决爆炸) 3. 使用批归一化、残差连接 4. 检查数据标准化是否正确 |
| 模型表现不稳定 | 1. 数据划分不均匀 2. 随机种子影响大 3. 数据量小,噪声大 |
多次运行实验,结果方差大 | 1. 使用分层采样确保分布一致 2. 固定随机种子 3. 增加数据量,清洗数据 |
| 线上效果差 | 数据分布漂移:线上数据与训练数据分布不同 | 比较线上输入数据的特征分布与训练数据分布 | 1. 收集新数据重新训练 2. 建立模型监控和在线学习/定期更新机制 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)