DeepSeek V4能否再次引领开源模型突围,创造新的AI神话?
DeepSeek v4即将面世,具体在哪些方面做了提升?
最近很多做银行Agent的朋友跟我吐槽:现在的模型写SQL总是幻觉严重,查个信贷数据还要人工复核,完全没法商用。 别急,据可靠消息,下个月DeepSeek V4就要来了。这次它不是简单的升级,而是专门针对代码生成和长上下文做了史诗级加强。这对我们金融IT人意味着什么?
01
中国AI的发展方向
根据 《财经》统计发现,中国在算力投资规模处于明显劣势,且AI芯片在训练周期和训练成本也更具提升空间。
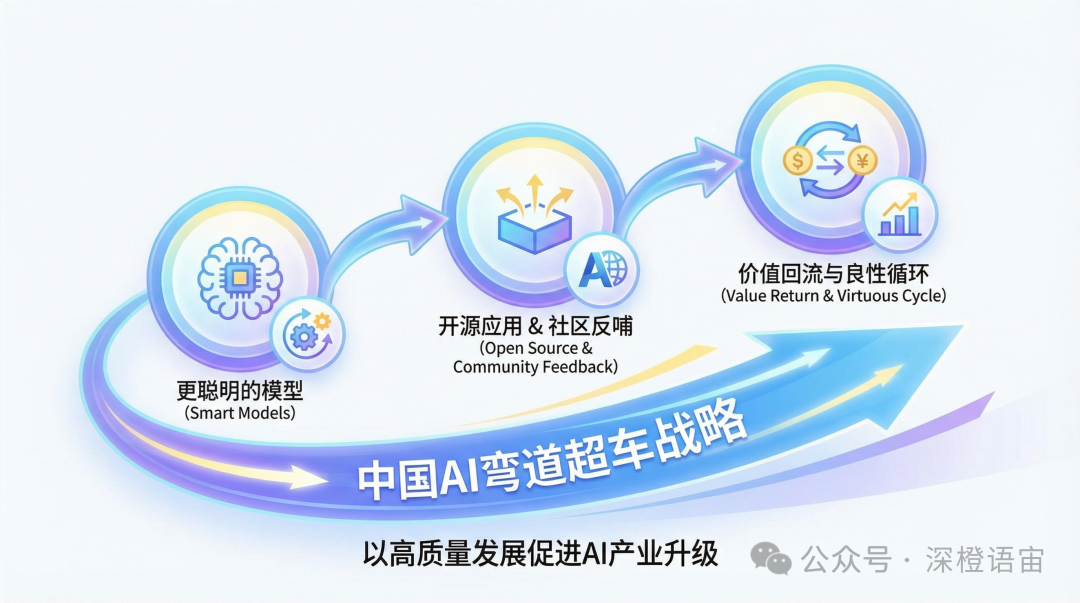
中国AI的发展,目前集中在几个方面进行弯道超车努力:
-
一方面,提升模型训练算法、训练策略以及训练使用的数据质量,训练出更聪明的模型;
-
另一方面需要将模型应用到更多实际业务场景中,也就是开源,从而利用社区的力量以及大量的应用场景经验,反哺模型的提升;
-
同时在应用过程中创造的价值再回流到AI产业的发展中,形成良性循环。
02
DeepSeek V4
作为当初突破chatGPT闭源大模型技术封锁的领头羊deepseek,本次到底在哪些方面进行了升级?

图为深度求索官方首页
提升在哪里
根据知情人士透露,V4将主要在代码生成与处理能力上进行大幅提升。
根据初步测试结果,V4已经优于目前市场主流模型,包括Anthropic 的 Claude 系列和 OpenAI 的 GPT 系列。
同时, 新模型在超长代码提示词(Prompt)的处理与解析方面实现了技术突破,这对于需要处理庞大项目代码库的工程师来说是一个巨大的利好。
技术突破
本次模型底层的训练逻辑也主要解决了“死记硬背”和“性能衰减”两个问题。
V4 是能理解数据背后的逻辑,在不断学习新知识或延长训练时间的过程中,依然保持了极高的稳定性。
为何执着于代码能力
很多人在我之前的文章AI路线的大道之争,DeepSeek v3.2突出重围直面Gemini 3 pro中表示疑问,为啥deepseek不提升其多模态能力?
其实并非深度求索不想提升,而是有以下几点考量:
1、代码数据的价值
AI训练中,相比于自然语言,代码具有极强的结构性与因果关系,高质量的代码训练能够显著提升模型在非编程任务上的推理能力。
2、避开算力黑洞
多模态训练所需的算力和存储是指数级的,开头提到,当前国内算力中心正处发展建设中。算力这块的成本较高,具有明显的缺口。
而低密度、高价值的文本和代码数据更符合深度求索“用最少的钱,做最聪明的模型”的战略定位。
3、拥抱需求着眼未来
超长上下文的理解和处理能力是行业使用模型解决实际问题的刚需,集中在超长提示词的理解和处理将为行业实际模型应用提供更多可能。
03
对金融AI建设的影响
从目前AI发展的路径和阶段来看,当前正处在Agent发展的高峰期。
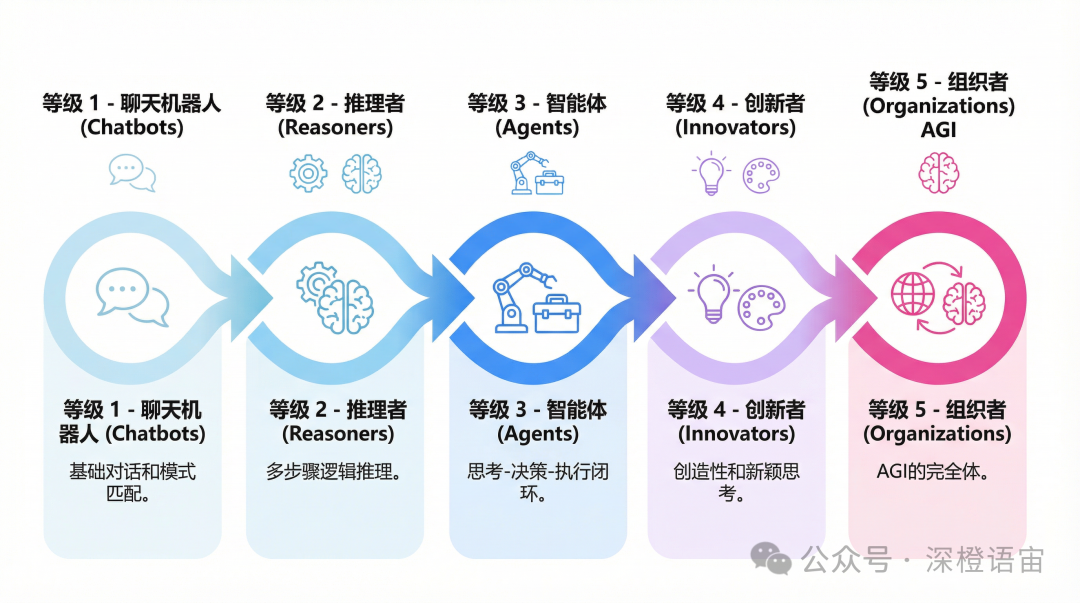
图为“AICon北京《明略科技吴明辉_可信Agent的规模化之路》-page10”重绘
金融行业具有数据高密度和行业规则更新频率快的特点,其Agent建设在上下文窗口大小的需求是不容忽视的。而V4对注意力机制衰减和上下文窗口的限制问题的提升,无疑非常利好金融智能体(Financial AI Agent)的建设。
展开来说,V4将在Agent工具调用、局部专业问题处理以及超长监控上有更好的发挥。
1、从调用工具到自生成工具
目前金融AI多是基于RAG做模型回答增强,V4可通过编写Python代码调用Wind/LBloombergd API,实时拉取并清洗数据,甚至编写回测策略;在数据分析上也能实时生成Pandas代码进行精确计算,提升分析结果的准确性和专业性。
2、局部问题专家临时介入
在做风控和审批相关智能体建设过程中,依靠RAG或者模型参数做出的判断往往存在幻觉和不稳定的情况,V4可根据问题实时生成复杂SQL,提升数据搜索过程中的精确度,也就间接提升了智能体结果的准确性和稳定性。
3、装下一个“图书馆”
相比于处理老系统的bug,金融业务场景下对于上下文的窗口需求是难以想象的。无法一次性理解场景的前因后果将显著降低智能体在金融领域解决问题的水平。
V4在处理超长上下文上做了更深层次的优化,有望在复杂多变的金融文档和监管信息中,实现更强的理解和实时变动的分析处理。
04
写在最后
随着开源模型能力的不断提升,金融行业的智能体落进程将会被不断加快,作为金融从业者,需要把握好每一次技术迭代过程中的利好信息,并实践于具体的AI应用与工具上。
关注我,我是【深橙语宙】,一个专注落地金融AI的实干派。

后续我将继续跟踪金融Agent建设的相关资讯,记得把我加入星标才不会错过我的更新哦。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)