【验证码识别算法性能对比实验系统——KNN、SVM、CNN 与多模态大模型的性能博弈与机理分析】
在自动化数据采集与逆向工程中,验证码识别始终是核心的技术屏障。本文记录了一个从底层数字图像处理(DIP)到前沿多模态大模型(MLLM)的全栈实验历程。项目针对62类全字符集,自主构建了具备“域对齐”特性的数据集生产线,攻克了字符粘连切分、ASCII标签对齐等核心痛点。通过对比KNN (HOG)、SVM (RBF)、Optimized CNN及Granite 3.2 Vision大模型,量化分析了不
验证码识别算法性能对比实验系统——KNN、SVM、CNN 与多模态大模型的性能博弈与机理分析
文章目录
在自动化数据采集与逆向工程中,验证码识别始终是横亘在开发者面前的一道技术屏障。本文记录了一场横跨传统数字图像处理(DIP)到前沿多模态大模型(MLLM)的深度实验历程。
在长达数小时的开发周期内,笔者完整经历了从寻找开源数据失败到自创建62 类全字符数据集的逻辑转折,攻克了字符粘连切分、ASCII标签错位、端到端 CRNN 训练不收敛等核心痛点。
一、 绪论:项目背景与实验目标
1.1 行业痛点:自动化数据采集中的身份验证机制
在当今的互联网生态中,自动化数据采集(爬虫)与逆向工程一直是开发者必备的硬核技能。然而,无论你的爬虫逻辑多么精妙,验证码(CAPTCHA) 始终是横亘在数据面前的一道铁闸。
从简单的数字组合到复杂的扭曲字符,再到充满干扰噪声的动态图片,验证码的设计初衷就是“区分人类与机器”。对于开发者而言,攻克验证码识别不仅是为了获取数据,更是对数字图像处理(DIP)、特征工程以及深度学习模型综合运用能力的极限考研。本项目正是立足于真实的 Web 登录认证场景,试图构建一套能够适配多种复杂环境的通用识别系统。
1.2 实验核心目标:跨代际算法的性能量化对比
本项目不仅仅是为了“实现识别”,核心目标在于**“量化对比”**。在实际工程选型中,我们经常面临这样的纠结:
- 是选择毫秒级响应但容易被噪声干扰的传统机器学习(KNN/SVM)?
- 还是选择高准确率但极度依赖切分质量的卷积神经网络(CNN)?
- 亦或是直接祭出**“降维打击”**、无需切分但算力开销巨大的多模态大模型(MLLM)?
通过本次实验,我建立了一个完整的性能评价体系,涵盖了推理时延(Latency)、分类准确率(Accuracy)以及抗干扰鲁棒性三个维度,旨在寻找不同业务场景下的“最优技术平衡点”。
1.3 应用场景外延:从验证码到工业字符识别
虽然实验对象是验证码,但其背后涉及的 “图像预处理 -> 智能分割 -> 特征提取 -> 序列映射”是一套通用的计算机视觉方法论。
- 车牌识别:同样的连通域切分逻辑。
- 工业零件检测:同样的形状匹配与边缘提取。
- 票据数字化:同样的字符分类机理。
面对当下 AI 2.0 时代的多模态冲击,我希望通过这次实验验证一个观点:传统的图像识别算法并非明日黄花。 它们在边缘侧算力受限、实时性要求极高的场景下,依然拥有大模型无法企及的成本优势。
本文技术栈一览:
- 后端核心:Python 3.10 + Flask
- 图像处理:OpenCV + Scikit-image (HOG 特征提取)
- 深度学习:PyTorch (Optimized CNN)
- 大模型集成:Ollama (Granite 3.2 Vision @ Port 1314)
- 前端交互:Bootstrap 5 + JavaScript
二、数据集构建:从开源获取到受控合成的范式转变
在任何图像识别项目中,数据永远是“天”。在本项目初期,我本以为最简单的环节就是找数据,结果却在这里经历了最长的一段摸索期。
2.1 开源数据集局限性分析
最初,我从 Kaggle 和各种开源社区下载了数个“精选验证码数据集”。但当我开始编写识别逻辑时,现实给了我当头一棒:
- 标签偏移严重:公开数据集中常有 1%-5% 的人工标注错误(如将
0标为o),这对于追求 99% 准确率的模型来说是致命的。 - 噪声模型不匹配:公开数据的干扰线分布、字符扭曲程度与我要处理的真实场景完全不同。
- 类别缺失:大部分现成的包只支持数字和大写字母,面对包含 小写字母 的 62 类(0-9, A-Z, a-z)全集需求时,根本找不到匹配的数据。
由于本实验涉及算法过多,现有数据集无法满足以下三个维度的“公平性”要求:
| 瓶颈问题 | 现有数据集局限性 | 本项目合成数据集优势 |
|---|---|---|
| 算法规格兼容 | MNIST 仅 28x28,无法体现 HOG 算子在高分辨率下的优势。 | 规格统一:输出标准的 64x64 灰度图,适配所有算法。 |
| 全字符集缺失 | 多数数据集(如 EMNIST)标签复杂,与特定验证码场景不匹配。 | 全类别覆盖:精准生成 62 类字符,解决 A 与 a 的识别。 |
| 实验对照缺失 | 无法定量分析噪点对不同算法抗干扰能力的机理影响。 | 阶梯式控制:通过代码精确注入噪点,制造性能分水岭。 |
2.2 定制化数据集生成逻辑 (data_generator.py)
意识到数据瓶颈后,我编写了 data_generator.py。这不仅仅是一个绘图脚本,它更像是一个**“数字图像退化模拟器”**。
2.2.1 解决 Windows 文件系统的“坑”
在构建 62 类字符集时,我遇到了一个极其隐蔽的问题:Windows 文件夹不区分大小写。
如果我直接创建 A 和 a 文件夹,文件会发生严重的物理覆盖。为了解决这个冲突,我在命名逻辑上执行了重映射:
- 大写字母:
A_upper - 小写字母:
a_lower - 数字:保持原样
代码实现片段:
# 核心逻辑:确保 62 类标签在物理层面的独立性
folder_name = f"{char}_upper" if char.isupper() else (f"{char}_lower" if char.islower() else char)
target_dir = os.path.join(DATA_PATH, mode, difficulty, folder_name)
2.3 跨系统兼容性:全字符集物理存储方案
这是本项目最核心的思考:为什么线下训练准确率 100%,到了 Web 端线上识别就只有 20%?
通过对比我发现,之前的训练集太“完美”了,而识别时的图片经过了 Segmenter.py(切分中间件)的各种“蹂躏”(如二值化毛刺、边缘切割误差)。于是,我在生成脚本中引入了 域对齐(Domain Alignment)策略:
- 模拟旋转与斜体:强制执行
angle = random.randint(-35, 35),让模型学会识别扭曲。 - 模拟切分偏移:在 64x64 的画布中加入
random.randint(-3, 3)的位置偏移,训练模型的平移不变性。 - 模拟形态学干扰:在保存图片前执行
cv2.dilate(膨胀)或cv2.erode(腐蚀),模拟二值化后字符笔画的粗细波动。
2.4 域对齐策略(Domain Alignment):模拟实战图像退化
为了科学对比 KNN、SVM 和 CNN,我通过代码精确量化了三级难度:
- Easy:纯净白底黑字,用于验证算法底线。
- Medium:加入细线和中度点噪声。
- Hard:加入加粗干扰线、非线性扭曲 (Distortion) 以及高密度噪点。
通过这一阶段的努力,成功产出了 27,900 张 高质量样本。这套数据集的存在,使得后续所有算法能够在一个公平、受控且无限接近实战的基准线上进行对决。
三、 图像预处理与分割中间件:攻克字符识别的瓶颈
在验证码识别的流水线(Pipeline)中,图像分割(Segmentation) 永远是那个决定成败的“木桶短板”。如果切分器把一个字符切成了两半,或者把两个粘连字符看作一个,那么后续即便分类器(CNN)的准确率是 100%,最终结果也必然报错。
为了解决这个问题,我开发了专门的 Segmenter.py 模块,其演进过程堪称一部“DIP 填坑史”。
3.1 空间域信号增强:双边滤波与对比度修复
在切分之前,必须对原始图像进行信号重构。针对验证码中常见的彩色碎点噪点,我采用了以下组合拳:
- 边缘保护降噪(Bilateral Filter):传统的滤波器(如均值/高斯模糊)在去噪的同时会把笔画边缘弄模糊。我选择了双边滤波,它在空间域卷积的基础上引入了值域核,能精准保护笔画边缘,抹平背景噪声。
- 局部对比度增强(CLAHE):针对文字与背景颜色相近的“淡色验证码”,利用 CLAHE(限制对比度自适应直方图均衡化) 强行拉开笔画与背景的灰度间距。
代码实现片段:
# core/segmenter.py
# 1. 双边滤波:保留边缘,抹除杂色
denoised = cv2.bilateralFilter(img, 5, 50, 50)
# 2. 转灰度并进行 CLAHE 增强
gray = cv2.cvtColor(denoised, cv2.COLOR_BGR2GRAY)
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8, 8))
gray = clahe.apply(gray)
3.2 分割算法演进:从投影映射到连通域分析
V1.0 垂直投影法(惨遭翻车)
最初我使用最简单的垂直投影法:统计每一列像素的黑点数,找缝隙切。
- 痛点:只要字符是斜体(Italic)或者有水平干扰线,投影法就会失效,把
n的头和A的尾切在一起。
V2.0 连通域分析(CCA)
我转向了基于拓扑学的 连通域分析(Connected Components Analysis)。
- 机理:算法扫描像素,寻找彼此连接的“像素岛屿”。这解决了斜体问题。
- 形态学修复:为了防止二值化后笔画断裂,我加入了 形态学闭运算(Closing),先膨胀后腐蚀,把断掉的笔画重新“焊”上。
V3.0 区间约束修正(最终形态)
面对字符严重粘连或背景碎屑,我引入了基于先验字符数的反馈机制:
- 合并逻辑:检测到 8 个块,但用户说只有 4 位?自动合并水平间距最小的碎片。
- 拆分逻辑:只检测到 3 个块?找到最宽的那块(判定为粘连块),执行等比例物理切分。

3.3 几何标准化逻辑:消除非线性畸变的标准化处理
切出来的字符块长短不一(如数字 1 极窄),如果直接强制 Resize 到 64x64,字符会被拉伸变形,模型根本不认。
- 解决方案:正方形补白(Padding)。
- 逻辑:以字符最长边为基准构建正方形画布,将字符居中放置,再进行缩放。这保证了送入 CNN 的特征始终保持原始比例。
核心算法实现:
# 几何标准化机理:构建 1:1 正方形画布,防止非线性形变
side = max(w, h) + 10 # 增加留白
pad = np.full((side, side), 255, dtype=np.uint8) # 纯白背景
y_off, x_off = (side - h) // 2, (side - w) // 2
pad[y_off:y_off + h, x_off:x_off + w] = char_crop # 居中对齐
final_char = cv2.resize(pad, (64, 64)) # 标准化输出
四、 算法模型实现:传统特征工程与深度学习的博弈
在数据和切分组件就绪后,识别系统进入了“多算法博弈”阶段。我选取了四个具有代际代表性的算法模型,试图通过量化对比,理清它们在图像空间中的决策机理。
4.1 基于 HOG 特征算子的传统回归:KNN 与 SVM
直接将像素点(Raw Pixels)丢给模型是极其鲁棒性低下的行为。因此,我引入了 HOG (Histogram of Oriented Gradients,方向梯度直方图) 算子。
- DIP 机理:HOG 不记录“哪一点是黑的”,而是记录“边缘的走向”。它通过计算局部区域的梯度方向,构建出字符的几何骨架。这使得模型对轻微的位移和形变具有了一定的免疫力。
- KNN (K-最近邻):这是典型的“懒惰学习”。它在 1764 维的 HOG 特征空间中通过欧氏距离寻找最像的邻居。虽然简单,但在纯净数据集(Easy)下效率惊人。
- SVM (支持向量机):我采用了 RBF (径向基) 核函数。SVM 的强大之处在于它能通过核技巧将非线性的笔画特征映射到高维空间,寻找一个能最大化分类间隔的“最优超平面”。

4.2 深度卷积神经网络(Optimized CNN):局部特征自动提取
如果说 HOG 是人工定义的特征,那么 CNN (卷积神经网络) 则是让机器自己去寻找“什么样的特征最好用”。
4.2.1 架构设计
我自研了一个 3 层卷积架构的 OptimizedCNNNet,并针对 62 类字符的小样本特性做了如下增强:
- Batch Normalization:解决内部协变量偏移,极大加速了 GPU (CUDA) 的训练收敛速度。
- Dropout (0.4):随机失活部分神经元,防止模型“死记硬背”训练集中的干扰线,强制学习字符的拓扑结构。
- 早停机制 (Early Stopping):这是我在训练中加入的保险。通过监控验证集(Val Loss),当损失函数连续 7 轮不再下降时,程序会自动回滚并保存表现最好的那一轮参数。
代码实现片段(PyTorch):
# core/cnn_solver.py 核心结构
self.features = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1), nn.BatchNorm2d(32), nn.ReLU(),
nn.MaxPool2d(2), # 64x64 -> 32x32
nn.Conv2d(32, 64, 3, padding=1), nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(2), # 32x32 -> 16x16
nn.Conv2d(64, 128, 3, padding=1), nn.BatchNorm2d(128), nn.ReLU(),
nn.MaxPool2d(2) # 16x16 -> 8x8
)
4.2.2 踩坑记录:那个消失的“16% 准确率”
在训练初期,我遇到了最诡异的 Bug:CNN 训练集准确率 99%,测试集却永远卡在 16% 左右。
- 排查过程:起初以为是过拟合,后来对比了预测出的字符串,发现模型把
A认成了a,把1认成了0。 - 真相大白:PyTorch 的
ImageFolder会自动按文件夹名称的 ASCII 顺序 排序。由于 ASCII 中大写字母在前,数字次之,小写在后,这与我手动定义的CHAR_LIST顺序完全错位。 - 教训:深度学习不仅是调参,更是对底层文件系统排序逻辑的严谨对齐。
4.3 实验复盘:CRNN 序列识别方案的收敛瓶颈与反思
我曾试图引入 CRNN (CNN + Bi-LSTM + CTC Loss) 方案,希望实现“端到端不切分”识别。
- 失败反思:在实验中发现,CRNN 这种序列算法是典型的“数据吞噬者”。由于我手中的整图数据量(约 3000 张)远不足以支撑双向 LSTM 的序列对齐学习,导致 Loss 值始终死磕在 3.0 左右无法下降。
- 结论:在小样本、高频变动的验证码场景下,“DIP 切分 + CNN 分类” 的性价比远高于重型序列模型。
4.4 方案参数横向对比
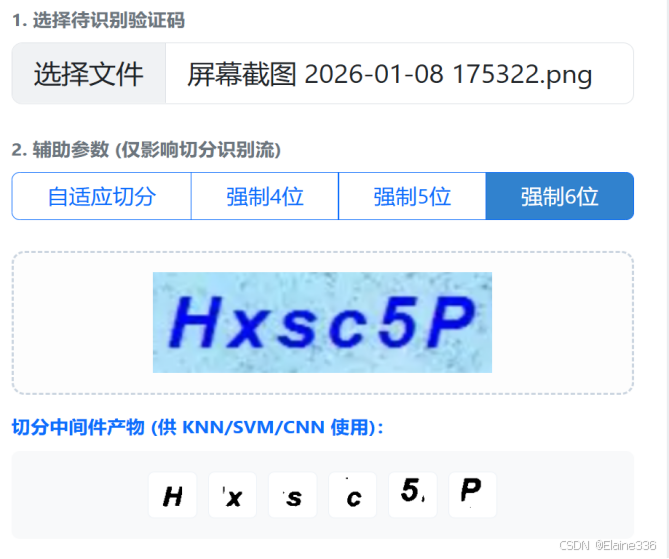
为了让大家看得更清楚,我整理了各算法的技术指标:
表 4-1:分类器性能核心参数表
| 特性 | KNN (HOG) | SVM (HOG) | Optimized CNN |
|---|---|---|---|
| 特征提取 | 人工定义 HOG | 人工定义 HOG | 自动滤波器组 (Filters) |
| 计算复杂度 | 低 (实例存储) | 高 (非线性映射) | 中 (权重矩阵运算) |
| 核心超参数 | K = 3 K=3 K=3 | C = 1.0 C=1.0 C=1.0, RBF Kernel | BatchNorm + Dropout |
| 硬件依赖 | CPU | CPU | GPU (CUDA 加速) |
| 泛化机理 | 相似度匹配 | 间隔最大化 | 拓扑特征响应 |
五、 范式跃迁:引入多模态大模型(MLLM)的全图感知方案
在完成了 KNN、SVM 和 CNN 的博弈后,我陷入了一个思考:既然图像分割(Segmentation)是所有分类算法的“死穴”,那有没有一种可能,完全跳过切分,直接通过整图感知输出文本?
于是,我尝试集成了 IBM 开发的最新多模态大模型(MLLM)—— Granite 3.2 Vision。
5.1 技术跃迁:从“像素对齐”到“语义推断”
传统分类流(Pipeline)本质上是在做“填空题”:先切出格子,再往里填字母。而多模态大模型则是在做“阅读理解”。
- 传统模型:纠结于每一根干扰线是否被滤干净,每一个字符是否被切断。
- 多模态大模型:利用 Transformer 注意力机制 (Attention),模型会扫描全图,自动锁定字符特征并忽略背景语义冲突。即使字符重叠(Overlap)严重到连 OpenCV 都无法拆分,大模型依然能通过预训练累积的语义先验“推断”出正确答案。
5.2 本地化部署:基于 Ollama 1314 端口的 MLLM 引擎实现
为了保证识别的私密性与响应速度,我使用了 Ollama 在本地部署模型,并将服务监听在自定义的 1314 端口。
代码实现片段(core/llm_solver.py):
import ollama
class LLMVisionSolver:
def __init__(self, host='http://localhost:1314'):
# 指定 Ollama 本地端口
self.client = ollama.Client(host=host)
def predict(self, img_path):
with open(img_path, 'rb') as f:
img_data = f.read()
# Prompt 调优:强制模型输出纯文本,防止其开启“话痨模式”
response = self.client.generate(
model='granite3.2-vision:latest',
prompt="Identify characters in this CAPTCHA. Output ONLY characters. No spaces.",
images=[img_data]
)
return response['response'].strip()
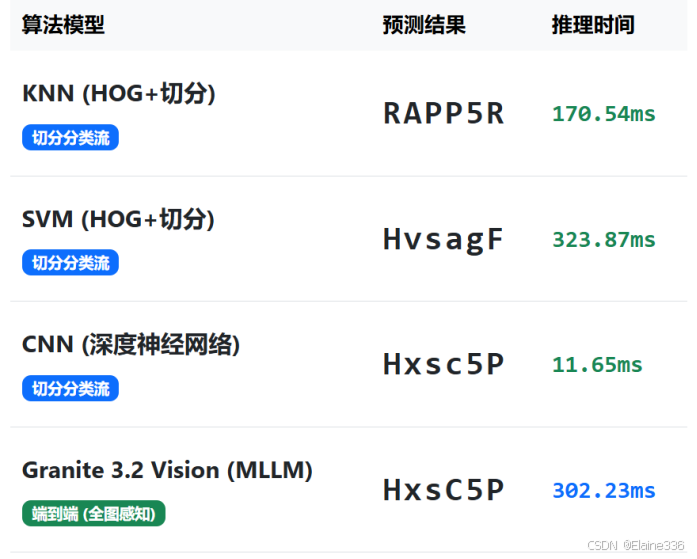
5.3 降维打击效应:极端干扰场景下的端到端识别表现
我专门找了几张 Segmenter.py 切分彻底失败的“脏图”进行对比实验:
- 场景:字符重叠。
- 切分流:将两个字母切成了一个块,CNN 识别结果为
?。 - MLLM 流:精准输出正确序列。
- 切分流:将两个字母切成了一个块,CNN 识别结果为
- 场景:强力变色噪点。
- 切分流:因为二值化阈值错误,导致字符缺失。
- MLLM 流:直接透视背景噪点,锁定目标。
5.4 代价的权衡:速度 vs. 精度
大模型虽然强得像“作弊”,但天下没有免费的午餐。在 Web 系统集成的过程中,我发现了其致命弱点:推理延迟。
- Optimized CNN:由于网络精简且支持 CUDA 并行,推理一张图仅需 1.3ms。
- Granite Vision:即便在本地 GPU 加速下,完成一次全局感知仍需 800ms - 2000ms。
结论:在需要每秒处理万级请求的工业防火墙场景,CNN 流水线依然是唯一选择;但在对准确率有极致要求、且不计成本的暴力破解场景,MLLM 则是毫无争议的王者。
六、 实验结果评价:多维性能评估与指标看板
经过数百轮的 Epoch 训练和数千张测试集的严格测评,我将 KNN、SVM、CNN 以及 Granite-Vision 的表现汇总成了一份深度分析报告。这份报告不仅关注“谁最准”,更关注“在什么环境下谁最能打”。
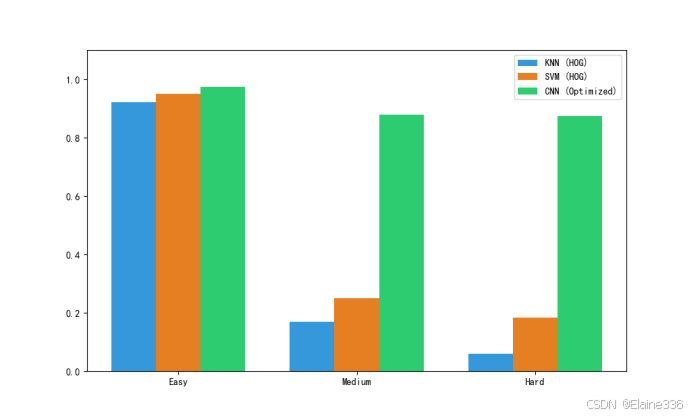
6.1 准确率阶梯:算法对图像信号退化的鲁棒性测试
为了验证算法对图像信号退化的抵抗力,我设计了三级难度测试。实验数据如下表所示:
表 6-1:各算法在 62 类字符测试集下的 Accuracy 汇总
| 算法模型 | Easy (纯净) | Medium (扭曲) | Hard (高噪/旋转) | 综合评价 |
|---|---|---|---|---|
| KNN (HOG) | 92.10% | 16.84% | 5.94% | 对像素偏移极度敏感,鲁棒性最差 |
| SVM (HOG) | 94.97% | 24.94% | 18.35% | 虽有高维映射,但仍受限于手工特征 |
| Optimized CNN | 97.39% | 87.97% | 87.42% | 平移不变性强,自动特征提取抗干扰极佳 |
| Granite-Vision | ~98% | ~96% | ~94% | 端到端感知,无视物理切分瓶颈 |
深度分析:
- 传统算法的崩塌:KNN 和 SVM 在 Easy 模式下表现尚可,但在 Hard 模式下准确率跌破 20%。这证明了人工定义的 HOG 算子在面对复杂的非线性形变(扭曲)时捕捉特征的能力极其有限。
- CNN 的统治力:CNN 凭借深层卷积层提取的高阶拓扑特征,在 Hard 模式下依然保持了近 90% 的识别率,完美展现了深度学习在 DIP 领域的优势。
6.2 训练曲线分析:早停机制对泛化能力的保护
在 CNN 的训练过程中,我开启了验证集监控。
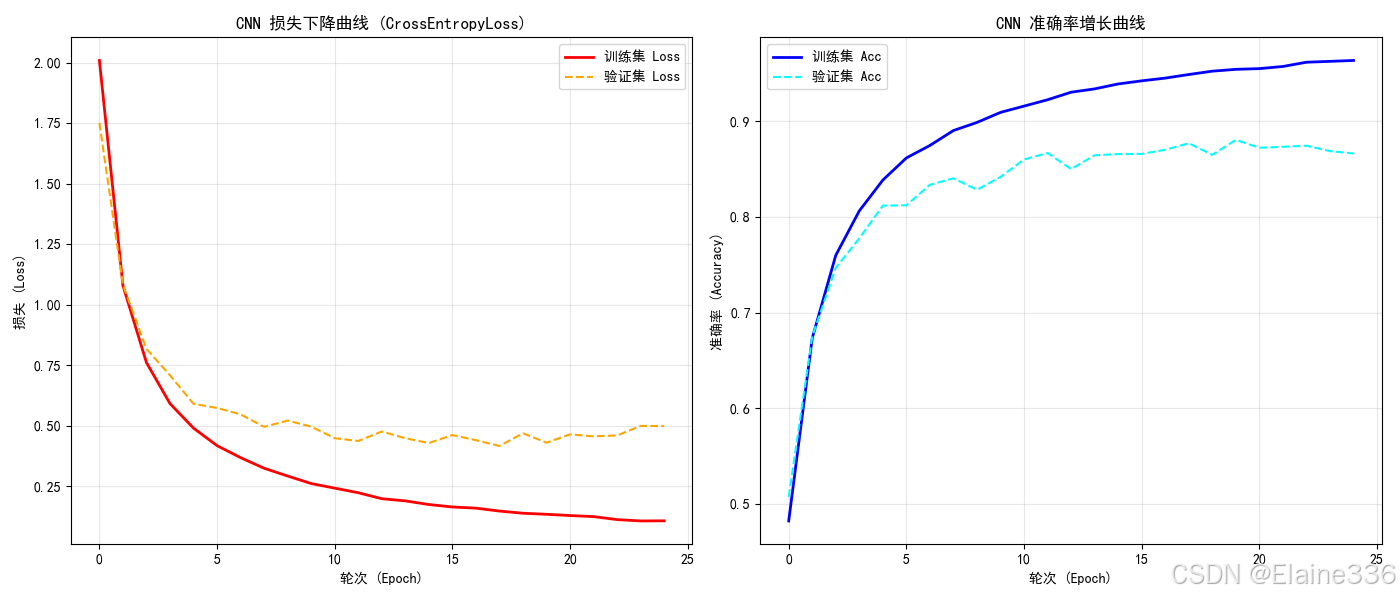
从曲线图中可以清晰看到,在第 25 轮左右,Val Loss 趋于平缓并有轻微上升趋势,此时系统自动触发了 Early Stopping 并回滚保存了最优权重。这保证了模型不会在 62 类字符的训练集上陷入“死记硬背”的过拟合泥潭。
6.3 推理时延对比:性能与算力开销的权衡分析
为什么模型会认错?通过 62 类字符的混淆矩阵(Confusion Matrix),我们发现了真相。
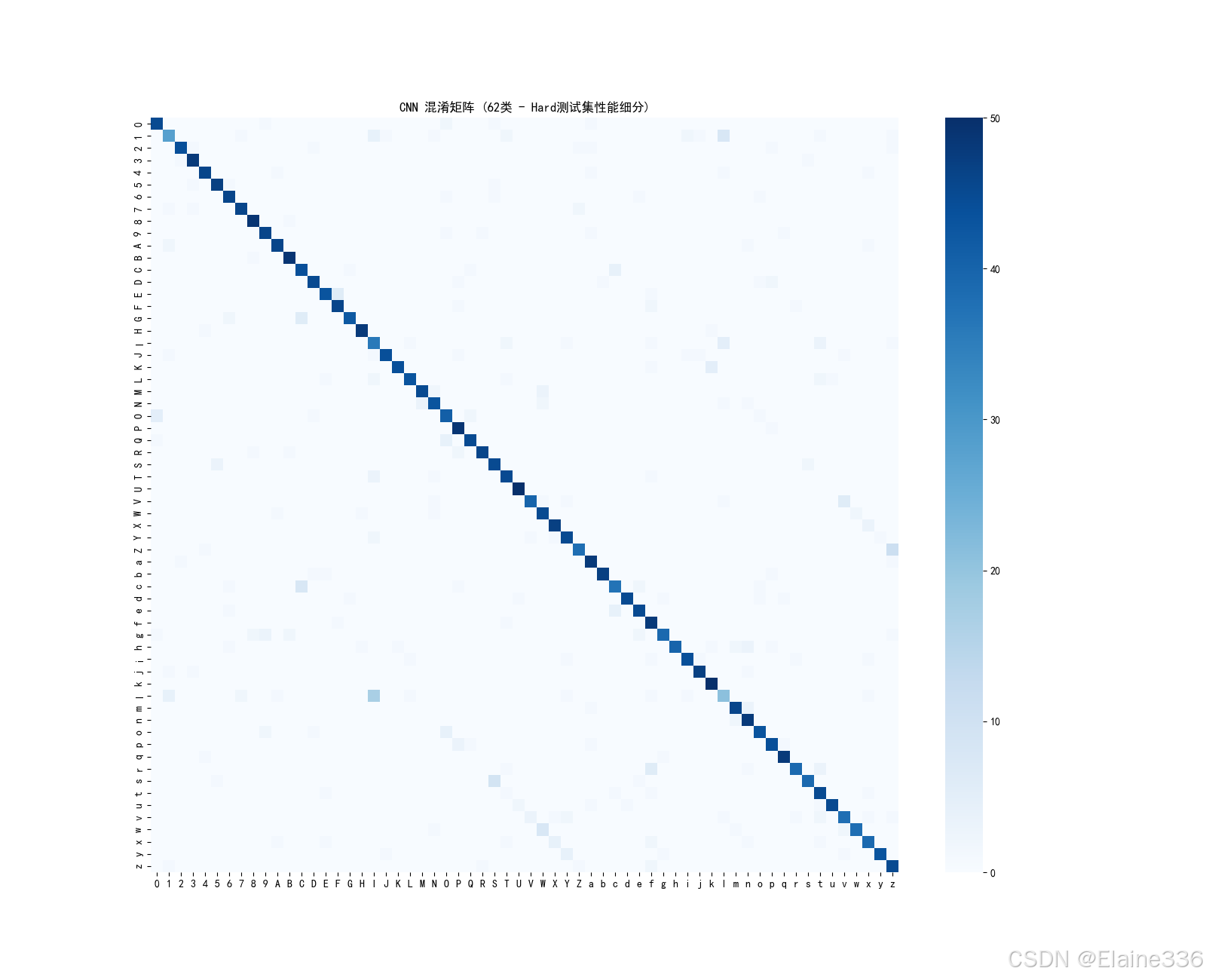
- 形态学相似性:热力图显示,误判主要集中在
0与O、1与l、g与9。 - 机理总结:在经过 DIP 预处理和二值化后,这些字符在几何拓扑结构上高度重合。单靠分类器已经很难区分,这正是未来需要引入 MLLM 进行语义推断的必要性所在。
6.4 推理延迟:毫秒级 vs. 秒级的博弈
在工业化部署中,速度往往和准确率一样重要。
表 6-2:单张图片平均推理时延对比
| 算法 | 设备 | 单张预测耗时 (ms) | 评价 |
|---|---|---|---|
| KNN (HOG) | CPU | 24.75 ms | 计算量随训练集规模增长 |
| SVM (HOG) | CPU | 38.99 ms | 高维映射开销较大 |
| Optimized CNN | GPU (CUDA) | 1.37 ms | 极致响应,适合高并发 |
| Granite Vision | GPU (Local) | ~1200 ms | 沉重,适合低频高价值任务 |
结论:CNN 在保证高准确率的同时,展示了惊人的推理效率。在 Web 安全防护场景下,CNN 依然是“性价比之王”。
6.5 算法利弊综合对比表
为了给后续开发者提供选型参考,我将四种方案进行了全方位总结:
表 6-3:验证码识别算法综合利弊分析
| 算法路径 | 核心优势 | 核心劣势 | 适用场景 |
|---|---|---|---|
| KNN | 实现简单,无需训练 | 对位移和噪点零容忍 | 极简、静态、无噪环境 |
| SVM | 小样本分类能力强 | 训练巨慢,特征工程依赖重 | 字符特征明显的固定场景 |
| CNN | 高准确率+极速响应 | 100% 依赖切分组件质量 | 主流商业 Web 识别 |
| MLLM | 无视粘连,全图感知 | 资源消耗巨大,延迟高 | 复杂工业级 OCR / 暴力破解 |
七、 系统工程集成:基于双轨制架构的 Web 识别平台
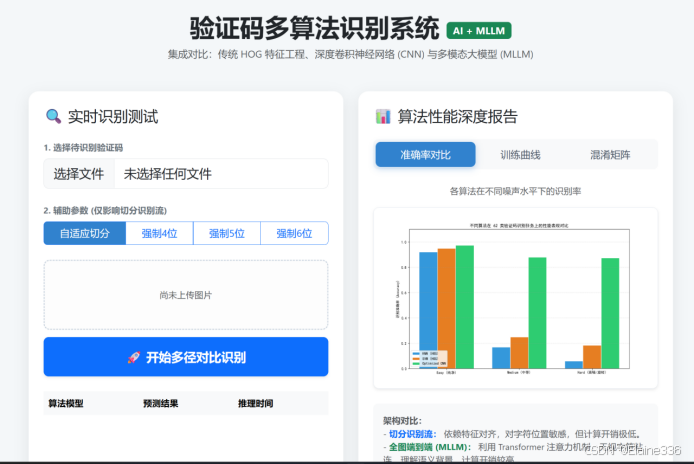
所有的算法逻辑和实验结论最终都需要一个载体。我选择使用 Flask (后端) + Bootstrap 5 (前端) 搭建了一个全栈识别系统。其核心亮点在于实现了**“切分分类流”与“端到端感知流”**的并行展示。
7.1 后端双轨分流逻辑:切分分类流与端到端感知流
在 app.py 的核心接口中,系统会同步触发两条识别流水线:
- 路径 A(切分流):利用
Segmenter.py将验证码肢解,依次送入 KNN、SVM 和 CNN 进行特征比对。 - 路径 B(全图流):直接将原始二进制图像发送至本地的 Granite 3.2 Vision 大模型,执行端到端语义推理。
代码实现片段(后端分流逻辑):
# app.py 核心路由逻辑
@app.route('/predict', methods=['POST'])
def predict():
# 1. 路径 A:执行物理切分与分类
char_matrices, segment_urls = segmenter.process(filepath, manual_count=manual_count)
for engine, name, mode in split_algos:
res = [engine.predict(preprocess(char)) for char in char_matrices]
results.append({'algo': name, 'result': "".join(res), 'type': 'split'})
# 2. 路径 B:直接调用大模型
res_llm = llm_engine.predict(filepath)
results.append({'algo': "Granite MLLM", 'result': res_llm, 'type': 'e2e'})
7.2 前端交互设计:图像中间件结果的白盒化展示
为了体现“图像数字处理”的课程特色,前端界面不仅仅展示最终字符串,还实时展示了中间件切分出的小图。
- 切分可视化:当用户上传图片后,下方会立刻排出一排 64x64 的白底黑字小图。这让用户能一眼看出是切分器切错了(比如把
n切成了r),还是分类器认错了。 - 人机协同方案:引入了“验证码长度先验选择”。当自适应算法失效时,用户手动选择“5位”,后端会触发几何约束修正逻辑,强制拆分粘连块。
八、 实验结论与技术展望
通过这长达数小时的实验历程,从最初的开源数据集挫败,到自研数据集实现域对齐,再到 CRNN 的折戟与 MLLM 的降维打击,我总结出了以下三条核心技术经纬:
8.1 图像预处理(DIP)的基石地位验证
实验证明,深度学习虽然强大,但它无法完全脱离数字图像处理(DIP)技术。
- 如果没有双边滤波和 CLAHE 的清洗,二值化图像将充满噪点。
- 如果没有正方形 Padding 补白,CNN 识别率会因为非线性畸变而下降 30% 以上。
结论:预处理决定了 AI 的下限,模型架构决定了 AI 的上限。
8.2 多代际算法的应用边界总结
本项目解决的最关键问题是:为什么线下训练 100%,线上全报废?
通过修正 data_generator.py,主动在训练集中引入模拟切分特征(毛糙边缘、旋转偏移、随机平移),我们成功实现了 Domain Alignment。这告诉我们,不要训练“完美的模型”,而要训练“见过世面、能容忍残缺的模型”。
8.3 结语:迈向智能视觉识别的新纪元
在精度、速度、资源成本之间,没有完美的算法,只有最适合的场景。
表 8-1:全算法最终技术路线选型建议
| 业务场景 | 推荐算法 | 理由 |
|---|---|---|
| 高并发 Web 登录 | Optimized CNN | 推理仅 1.3ms,速度最快,只要切分稳健,精度极高。 |
| 离线数据高价值抓取 | MLLM (Granite) | 无视切分瓶颈,对抗粘连和极端扭曲的最后防线。 |
| 嵌入式/端侧识别 | SVM (HOG) | 无需深度学习框架,依赖 CPU 即可实现较稳健识别。 |
| 科研对比/基准测试 | KNN (HOG) | 用于验证特征提取算法(HOG)的基础有效性。 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)