AI时代,为什么企业的数据治理要重新做
开篇先问大家一个问题:公司上了AI系统,数据却喂不进去?最近和几位做AI项目的朋友聊天,听到最多的吐槽是:想用AI做智能质检,结果发现历史图像数据标注标准不统一,模型训练准确率只有65%,根本没法用;上线了AI推荐系统,但线上线下客户数据打不通,推荐点击率不到2%,投入全打水漂;AI信贷审批系统,敏感数据管控不足,随时可能面临监管处罚;想做AI分析,数据血缘追踪不到位,模型出错了连问题出在哪儿都找
开篇先问大家一个问题:公司上了AI系统,数据却喂不进去?
最近和几位做AI项目的朋友聊天,听到最多的吐槽是:
-
想用AI做智能质检,结果发现历史图像数据标注标准不统一,模型训练准确率只有65%,根本没法用;
-
上线了AI推荐系统,但线上线下客户数据打不通,推荐点击率不到2%,投入全打水漂;
-
AI信贷审批系统,敏感数据管控不足,随时可能面临监管处罚;
-
想做AI分析,数据血缘追踪不到位,模型出错了连问题出在哪儿都找不到。
听着是不是很熟?说实话,这不是AI技术的问题,而是数据治理没跟上。
很多企业以为,之前做过数据治理了,BI报表也跑得好好的,为什么AI一上就不行了?说白了,传统数据治理是为BI报表设计的,但AI时代需要的是"喂养模型"的数据——这是本质上的代际差异。
今天就用最直白的方式,聊聊AI时代为什么要重做数据治理,以及具体怎么做。

为什么传统数据治理撑不住AI时代
1. BI时代 vs AI时代:数据要求完全不同
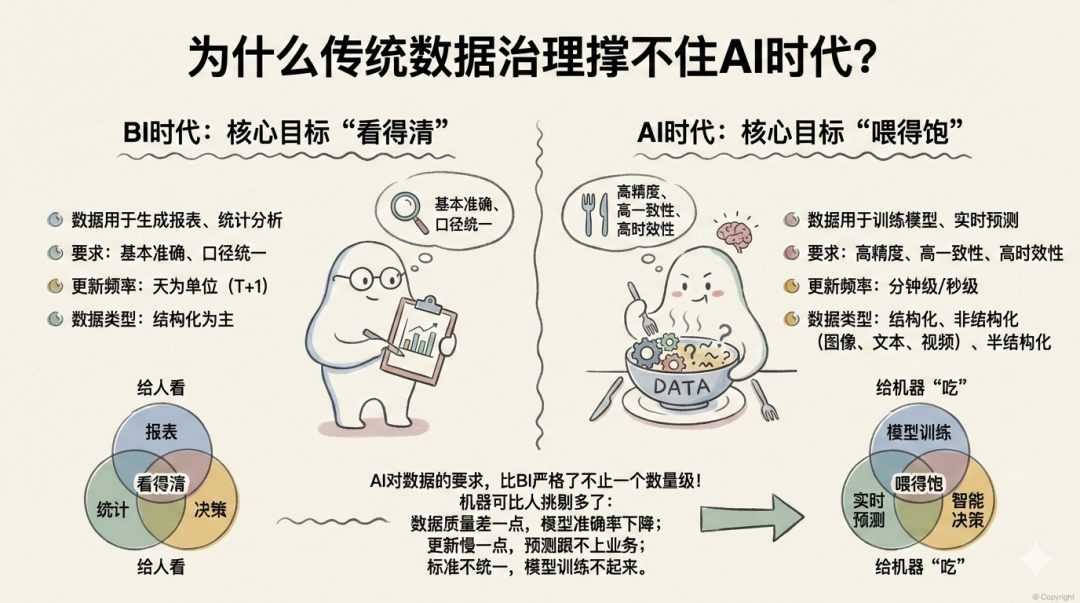
BI时代的数据治理,核心目标是看得清:
-
数据主要用于生成报表、做统计分析
-
对数据质量的要求是"基本准确、口径统一"
-
更新频率以天为单位,T+1就够用
-
数据类型以结构化数据为主
AI时代的数据治理,核心目标是喂得饱:
-
数据要用来训练模型、做实时预测
-
对数据质量的要求是"高精度、高一致性、高时效性"
-
更新频率要达到分钟级甚至秒级
-
数据类型包括结构化、非结构化(图像、视频、文本)、半结构化
BI时代的数据是给人看的,AI时代的数据是给机器"吃"的。机器可比人挑剔多了:
-
数据质量稍微差一点,模型准确率就会大幅下降
-
数据更新慢一点,预测结果就会跟不上业务变化
-
数据标准不统一,模型根本训练不起来
说白了,AI对数据的要求,比BI严格了不止一个数量级。
2. 企业面临的四大数据困境
根据2025年多份行业调研报告,81%的AI专业人士表示,他们的公司不能很好地处理数据质量问题。更严峻的是,企业只捕获了约56%的潜在有价值数据,在这些数据中,有77%是冗余、过时或未分类的数据。这使得仅有23%左右的"好数据"可用于AI驱动的业务。具体来说,企业在AI时代面临四大数据困境:
困境1:寻数之难
亿信华辰接触过一家零售企业,他们想做AI精准推荐,结果发现同一个客户在不同系统里有5个不同的ID:CRM里一个、电商平台一个、会员系统一个、线下门店又是一个。数据团队花了3个月时间做数据打通,光是确认“这5个ID是同一个人”就开了十几次跨部门会议。这种数据当然不能用。
困境2:信数之难
“上个月的活跃用户数到底是多少?”市场部说是320万,因为他们统计了所有登录过App的用户;运营部却说是280万,因为他们只算有下单行为的用户;而产品部给出的数字是350万,因为他们把访问小程序的人也算了进去。同一个指标,三个部门各执一词,数据口径不统一、质量参差不齐,谁也不敢拍胸脯说“这个数据准确”。AI模型训练最怕的就是“垃圾进、垃圾出”。
困境3:用数之难
某物流企业想用AI优化配送路径,以降低燃油成本。技术团队好不容易从各个分公司调来了GPS数据,却发现数据格式五花八门:有的用经纬度坐标,有的用文本地址,还有的只记录到了城市级别。更头疼的是,这些数据有的是实时上传,有的是每天批量同步一次,导致AI模型根本无法统一接入和实时计算。项目上线一拖再拖,最后只能手工处理数据,效果大打折扣。
困境4:管数之难
AI训练需要大量敏感数据,但数据脱敏、权限管控跟不上。某银行的AI信贷审批系统,因为数据安全问题,被监管部门约谈,差点罚款几百万。
3. 不做AI数据治理,代价有多大?
有人可能会问:这么做值不值?用数据说话。
-
经济损失角度:研究表明,由于数据质量问题,一般企业会损失8%到12%的收入。各行各业每年的损失加起来高达数十亿美元。
-
AI落地角度:麦肯锡的研究显示,使用高质量数据的供应链统计模型可以节省3-8%的成本。如果数据存在缺陷,模型就会产生不可靠的结果并浪费资金。
-
对比来看:根据行业研究,使用AI进行供应链优化的公司可以降低成本20%,提高收入10%。但前提是——你得有"好数据"。
说白了,不做AI数据治理,AI投入就是打水漂;做好了,ROI立竿见影。

AI时代数据治理要解决什么问题
1. 多模态数据的统一管理
传统数据治理主要处理结构化数据,但AI时代要处理的数据类型复杂得多。
说白了,AI要“吃”的数据五花八门:
-
Excel表格:这是结构化数据,传统治理能管;
-
图片、视频、语音:这是非结构化数据,AI视觉质检、语音识别都需要;
-
JSON、XML文件:这是半结构化数据,API接口、物联网设备都在用;
-
传感器数据:工业AI、智能制造离不开这些实时数据流。
传统数据治理只管Excel,但AI时代这些都得管起来。这些数据如何统一存储、标注、清洗、管理?那哪儿是简单买个数据库就能解决的。
2. 实时数据血缘的追踪
AI模型的预测结果出了问题,如何快速定位是哪个数据源的问题?这需要完整的数据血缘追踪,就像追踪一个人的家族谱系,不仅要知道他的父母是谁,还要知道他的每个基因来自哪个祖先。具体来说:
数据从哪里来?
经过了哪些处理步骤?
被哪些模型使用?
最终影响了哪些业务决策?
传统数据治理的血缘追踪以"表"为单位,但AI时代要追踪到"字段"甚至"特征"级别。粒度要细得多。
3. AI场景下的数据安全合规
AI训练需要大量数据,但这些数据往往包含客户隐私、商业机密。如何在保证数据可用性的同时,做好数据脱敏、权限管控、合规审计?举个例子,客户手机号138****1234,AI训练时能看到号码段和尾号,但看不到中间4位。这样既能保护隐私,又不影响模型学习用户行为特征。
某金融企业的做法就很实在,建立分级分类体系,敏感数据自动打标;AI训练环境使用脱敏后的数据;全流程操作日志,可追溯审计。根据行业案例,数据安全合规优先的企业可以降低60%的运营风险和成本。
4. 数据质量的持续监控
AI模型对数据质量极其敏感。某制造业企业的经历很典型:
-
问题:历史图像数据标注标准不一致
-
后果:AI质检模型准确率只有65%,需要重新标注12万张图片
-
损失:项目延期3个月,人力成本增加上百万
后来他们建立了数据质量监控体系:
-
自动检测数据标注是否符合标准
-
实时预警数据质量下降
-
定期生成质量报告
结果是AI质检准确率提升到92%。

怎么做AI时代的数据治理
说到具体实施,很多企业首先纠结的是该从何处入手。根据亿信华辰多年的经验,以下步骤经得起实践检验:
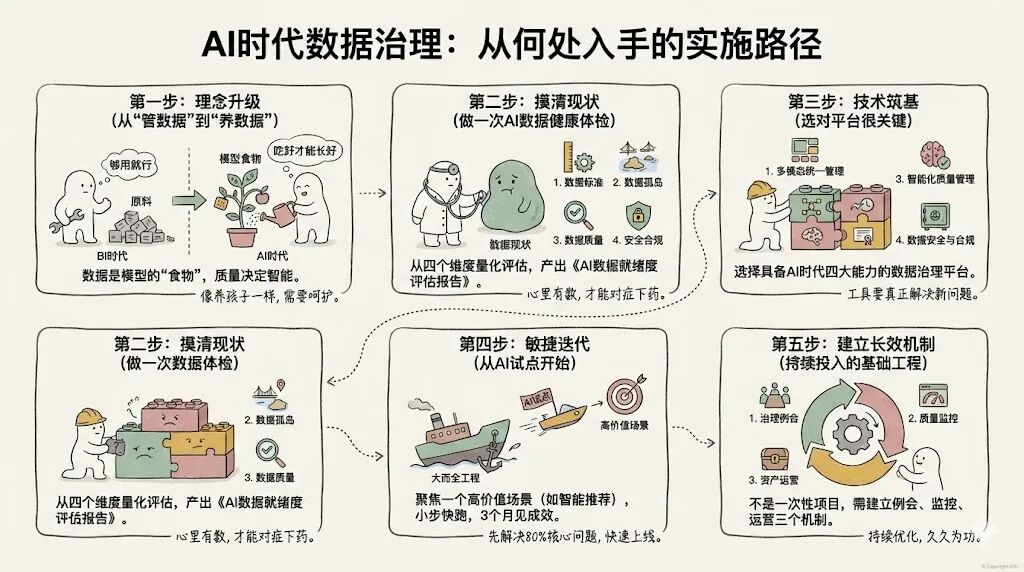
第一步:理念升级——从"管数据"到"养数据"
这是第一步,也是最关键的一步。传统思维认为,数据是BI报表的原料,够用就行,质量差一点也能凑合。AI思维认为,数据是模型的"食物",质量决定智能水平。就像养孩子一样,吃得好才能长得好。同样的道理,你给AI模型喂劣质数据,它能做出精准预测吗?
具体怎么做?
-
召开管理层会议,达成"数据即资产"的共识;
-
明确:AI时代的数据治理不是IT部门的事,而是全公司的战略工程;
-
设立专门的数据治理委员会,业务部门、IT部门、法务部门共同参与。
亿信华辰服务过的一家企业,原来数据治理就是IT部门在折腾,业务部门根本不配合。后来CEO亲自挂帅成立数据治理委员会,业务部门才真正重视起来。
第二步:摸清现状——做一次AI数据健康体检
很多企业对自己的数据现状其实是心里没数的。其实可以从四个维度评估:
维度1:数据标准
-
关键业务对象(客户、商品、订单等)是否有统一标准?
-
不同系统的数据格式是否一致?
-
评估结果量化:标准覆盖率、一致性比例
维度2:数据孤岛
-
有多少个数据源?
-
这些数据源之间是否打通?
-
核心业务数据的完整度如何?
维度3:数据质量
-
数据准确率、完整率、及时率分别是多少?
-
有多少数据可以直接用于AI训练?
-
数据质量问题导致的业务损失有多大?
维度4:安全合规
-
敏感数据是否有明确分级?
-
是否有数据脱敏机制?
-
数据使用是否有权限管控和审计?
第三步:技术筑基——选对平台很关键
摸清现状后,就要开始真正动手了。这个阶段,技术工具的选择很关键。数据治理平台要能真正解决AI时代的新问题,而不只是传统功能的堆砌。AI数据治理平台至少要具备这几个能力:
能力1:多模态数据统一管理
不只是管数据库表,图像、视频、文档、API接口都要能管起来,在一个平台上进行元数据管理、血缘追踪、质量监控。
能力2:实时数据血缘追踪
要追踪到字段级别,清晰展示数据从源头到AI模型的完整流转路径。模型出现问题时,能快速定位是哪个环节的数据出了问题。
能力3:智能化数据质量管理
要有丰富的数据质量规则库,能自动检测数据质量问题,实时预警。对于AI训练数据,还要能设置专门的质量标准。
能力4:数据安全与合规
要提供数据分级分类、数据脱敏、权限管控、操作审计等完整能力,满足《数据安全法》《个人信息保护法》等法规要求。
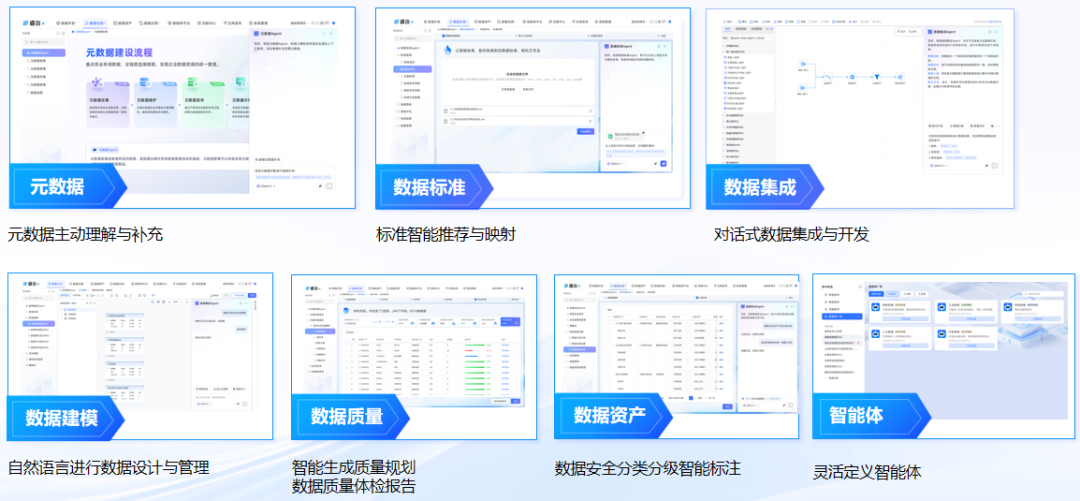
亿信华辰睿治数据治理平台正是这样一款为AI时代量身打造的数据治理工具,它将AI大模型与知识图谱双引擎深度融入治理全流程,实现了对多模态数据的统一智能解析与管控,并能通过自然语言交互自动生成数据质量报告与规则,同时依托精准的字段级血缘追踪能力,快速定位模型问题根源,再结合完善的数据分级分类、脱敏及审计机制确保合规,从而为企业快速构建面向未来的AI数据基础设施提供了强大支撑。如果你正在考虑选型,可以去试用看看。
第四步:敏捷迭代——从AI试点开始
用过来人的经验告诉你,不要一上来就搞大而全的数据治理工程,从一个高价值AI场景切入,小步快跑。具体怎么做?选一个高价值AI试点场景,比如:制造业AI质检、零售业智能推荐、金融业风控模型、物流业智能调度。
聚焦这个场景做数据治理:
-
梳理该场景需要哪些数据?
-
这些数据的质量现状如何?
-
需要建立哪些数据标准?
-
如何保证数据实时性?
不求完美,先解决80%的核心问题,快速上线,让AI模型跑起来,最终用业务结果说话(准确率提升、成本下降等)。成功后逐步推广,总结经验,形成标准化方法,复制到其他AI场景,逐步覆盖全公司。
第五步:建立长效机制——数据治理不是一次性项目
最后强调一点:数据治理不是一次性项目,而是需要持续投入的基础工程。建议建立三个机制:
机制1:数据治理例会
-
每周或每两周开一次
-
讨论数据质量问题、血缘追踪问题、安全合规问题
-
及时调整治理策略
机制2:数据质量监控
-
建立数据质量仪表盘
-
核心指标每天监控、每周汇报
-
质量问题及时整改
机制3:数据资产运营
-
定期盘点数据资产
-
评估数据价值
-
持续优化数据标准
结语:AI时代,数据治理不是要不要做的问题,而是怎么做得更好的问题。AI的成功将由数据基础设施驱动,而非新模型。再先进的AI算法,没有"好数据"的支撑,也只是空中楼阁。而数据治理,就是打造这个基础设施的核心工程。
说实话,这需要管理和技术的双重保障,缺一不可:
-
管理层面:理念要升级、组织要到位、流程要建立;
-
技术层面:平台要选对、工具要用好、能力要跟上。
您是否正陷入AI落地的数据困境?不妨从一个试点场景切入,用3个月时间验证数据治理的实际价值——数据质量提升所带来的AI效果改善,是实实在在的业务回报。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)