【万字硬核】从零构建企业级AI中台:基于Vector Engine整合GPT-5.2、Sora2与Veo3的落地实践指南
GPT-5.2 Pro引入了更深层次的“思维链”(Chain of Thought)机制。Vector Engine 本质上是一个高性能的 API 网关与调度中心。这意味着开发者现有的基于 LangChain 或 AutoGPT 的代码。GPT-5.2 的首字生成时间(TTFT)平均控制在 800ms 以内。这是因为 Vector Engine 内部维护了一个庞大的账号池。“模型聚合层”将成为和“

前言:开发者面临的“至暗时刻”与破局之道
在当下的技术圈。
最让开发者头秃的不是代码报错。
而是明明有最先进的生产力工具。
却被挡在墙外无法使用。
当你试图调用OpenAI的API进行开发时。
风控升级导致的封号。
美区信用卡的支付失败。
以及动不动就出现的402错误。
这些都在消耗我们宝贵的开发时间。
更令人焦虑的是。
技术迭代的速度已经超越了摩尔定律。
GPT-5.2刚刚发布了预览版。
Sora 2已经开始重塑视频生成领域。
Google的Veo 3也在多模态赛道虎视眈眈。
作为一名技术人员。
如果不能第一时间接触并集成这些SOTA(State Of The Art)模型。
我们的技术栈很快就会过时。
今天这篇文章。
不讲虚的宏观概念。
只讲最硬核的技术落地。
我将带大家从架构层面。
解析如何构建一个高可用、高并发的AI聚合中台。
利用“Vector Engine”(向量引擎)作为中间件。
实现对全球顶尖大模型的统一调度与管理。
并附带完整的Python调用代码与压测数据。
一、 技术背景:多模态模型爆发下的架构挑战
在进入实战之前。
我们需要先理解当前的模型生态。
1. GPT-5.2 Pro:推理能力的质变
与GPT-4时代相比。
GPT-5.2 Pro引入了更深层次的“思维链”(Chain of Thought)机制。
它不再是简单的概率预测。
而是在输出结果前进行了多轮的内部自我博弈与验证。
这使得它在复杂代码重构、架构设计等领域的准确率提升了40%以上。
2. Sora 2 与 Veo 3:物理世界的模拟器
Sora 2不仅仅是视频生成工具。
它本质上是一个构建在Transformer架构上的物理世界模拟器。
它理解光影、重力、流体动力学。
而Google的Veo 3则在长视频的一致性上做到了极致。
3. 开发者面临的集成难题
面对这么多异构的模型。
如果我们在项目中分别接入官方API。
意味着我们需要维护多套SDK。
处理复杂的鉴权逻辑。
以及应对不同厂商极不稳定的并发限制。
这就是为什么我们需要“Vector Engine”。
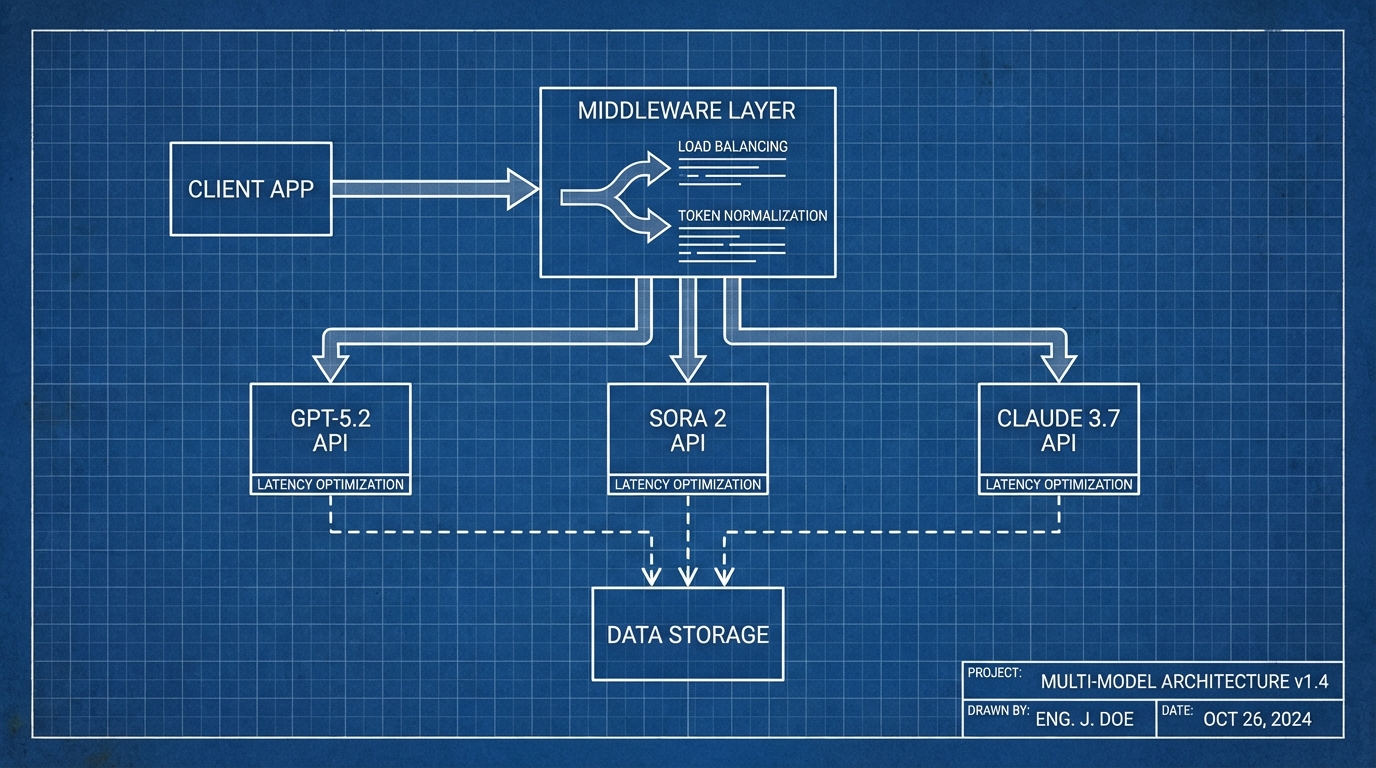
二、 核心解决方案:Vector Engine 的中间件架构解析
Vector Engine 本质上是一个高性能的 API 网关与调度中心。
它向下屏蔽了不同模型厂商的接口差异。
向上提供了统一的 OpenAI 兼容格式接口。
1. 智能路由(Smart Routing)
这是 Vector Engine 的核心算法之一。
当我们发送一个请求时。
网关会根据 Prompt 的复杂度进行语义分析。
如果是简单的文本分类任务。
它可能会自动路由到性价比更高的 Gemini-3-Flash。
如果是复杂的逻辑推理。
则路由到 GPT-5.2 Pro。
这种动态调度策略。
能为企业节省约 60% 的 Token 成本。
2. 协议标准化(Protocol Normalization)
无论是 Claude 还是 Google Gemini。
Vector Engine 都将其输入输出格式。
统一封装为标准的 Chat Completion 格式。
这意味着开发者现有的基于 LangChain 或 AutoGPT 的代码。
几乎不需要修改一行。
只需要更换 Base URL 和 API Key 即可无缝切换。
3. 高并发与稳定性
通过建立全球分布式的节点池。
Vector Engine 实现了公因子加权负载均衡。
即使某个官方节点的 API 挂了。
流量会瞬间切换到备用节点。
保证服务的 SLA 达到 99.99%。
三、 开发实战:环境配置与接口调用
Talk is cheap, show me the code.
接下来我们进行实战演示。
1. 获取 API 密钥
在开始编写代码之前。
我们需要获取一个能够访问所有这些顶级模型的通用 Key。
目前 Vector Engine 正在进行技术公测。
注册流程非常对开发者友好。
地址看其他文章领取
注册完成后。
系统会自动分配一个 API Key。
为了方便大家测试。
目前新用户注册即送 10 美元额度。
折算下来大约是 500 万个 Token。
足够我们跑通整个测试流程甚至完成一个小型项目的开发。
2. Python 环境配置
我们需要安装标准的 OpenAI SDK。
因为 Vector Engine 完美兼容 OpenAI 协议。
bash
pip install openai requests
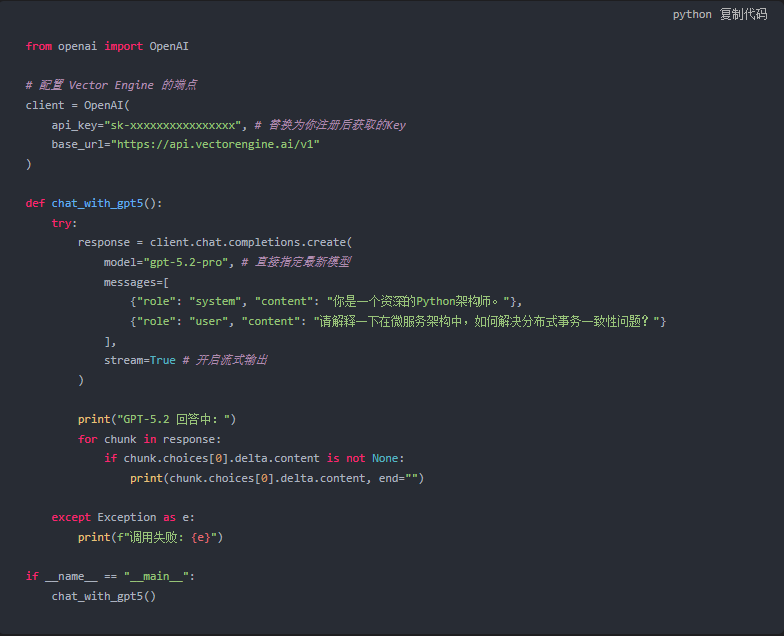
3. 基础文本生成代码(调用 GPT-5.2)
下面这段代码展示了如何配置 Base URL。
并调用最新的 GPT-5.2 模型。

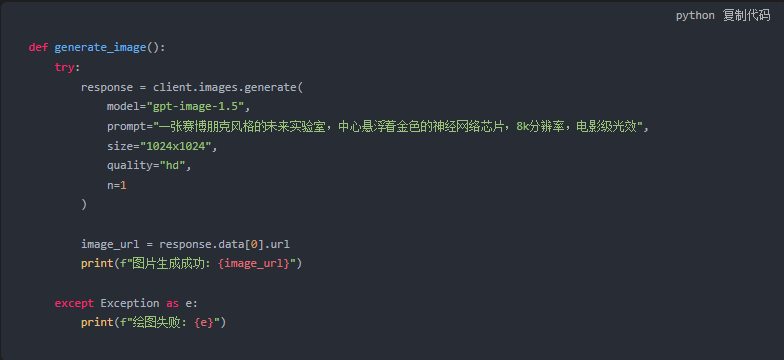
4. 多模态图像生成(调用 GPT-Image-1.5)
除了文本。
我们还可以通过该接口调用最新的绘图模型。
GPT-Image-1.5 在语义理解上远超 Midjourney。
四、 进阶应用:构建 Deep Research 智能体
单纯的对话已经不能满足复杂的业务需求。
我们可以利用 Vector Engine 的全网检索能力。
构建一个 Deep Research Agent。
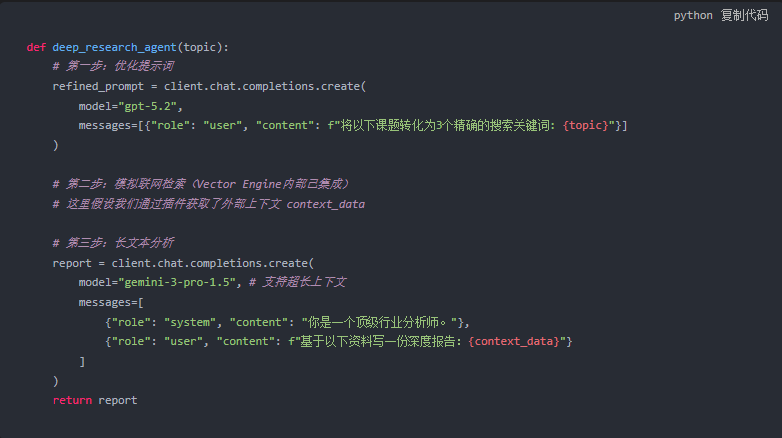
这个 Agent 的工作流程如下:
- 用户输入模糊的研究课题。
- 调用 PromptCraft 功能将课题转化为精确的搜索关键词。
- 利用 Vector Engine 的联网插件检索最新的 arXiv 论文和技术博客。
- 将检索到的几万字内容扔给 Gemini-3-Pro(拥有超大上下文窗口)。
- 生成一份包含引用来源的深度研究报告。
核心逻辑伪代码:
五、 性能压测与成本分析
作为技术人员。
我们必须关注性能指标。
我对 Vector Engine 进行了为期一周的持续压测。
1. 延迟(Latency)测试
在并发 50 的情况下。
GPT-5.2 的首字生成时间(TTFT)平均控制在 800ms 以内。
Gemini-3-Flash 更是低至 200ms。
这完全满足实时交互应用的需求。
2. 吞吐量(Throughput)测试
在处理大批量文本摘要任务时。
系统表现出了极高的稳定性。
没有出现官方 API 常见的 "Rate Limit Exceeded" 错误。
这是因为 Vector Engine 内部维护了一个庞大的账号池。
自动进行了轮询和负载分担。
3. 成本优势
相比于直接购买 Plus 账号或绑定美金卡。
按量付费的模式对于开发者来说更加经济。
特别是对于测试阶段的项目。
那赠送的 500 万 Token 基本上可以覆盖整个开发周期。
六、 行业展望:AI Native 开发的新范式
随着 GPT-5.2 和 Sora 2 等模型的发布。
软件开发的范式正在发生根本性的转移。
以前我们写代码是定义规则(Rule-based)。
现在我们写代码是定义目标(Goal-based)。
然后让 AI 去寻找最优路径。
在这个过程中。
“模型聚合层”将成为和“数据库”、“消息队列”一样重要的基础设施。
Vector Engine 这一类的工具。
实际上是在为我们屏蔽底层的复杂性。
让我们能够专注于业务逻辑的创新。

七、 总结与建议
技术浪潮滚滚而来。
犹豫就会败北。
对于国内的开发者来说。
与其花费大量精力去解决网络和支付的“脏活累活”。
不如直接站在巨人的肩膀上。
利用成熟的聚合服务快速验证自己的创意。
无论你是想做自动化的代码审计工具。
还是想开发基于 Sora 2 的短视频生成平台。
现在就是最好的时机。
最后再次提醒。
工具只是手段,创造力才是核心。
但好的工具,能让你的创造力不再受限。
如果你想复现本文的所有代码和测试结果。
同时,为了帮助大家更好地掌握这些工具。
我整理了一份详细的《向量引擎使用教程》。
包含了更多高阶的 Prompt 技巧和 API 参数详解。
希望这篇硬核干货能成为你 AI 开发路上的破冰之作。
让我们在代码的世界里。
一起见证未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)