AIAAJ | 清华大学张宇飞团队:考虑非当地效应的分离流数据驱动湍流建模
RANS湍流模型在工程中应用广泛,但却常常难以准确计算分离流动。近年来,数据驱动方法被用于训练能准确计算分离流动的RANS湍流模型,但有时它们在分离流中的泛化性有限。本研究旨在通过为数据驱动模型引入非当地性,来提升其在分离流中的泛化性。具体来说,我们为 ω方程的修正乘子β构造额外的输运方程,将平均流线上的历史编码进β。使用NASA Hump(驼峰)和周期山的高精度数据对模型系数进行数据驱动式的标定
考虑非当地效应的分离流数据驱动湍流建模
Data-driven Turbulence Modeling for Separated Flows Considering Nonlocal Effect
吴辰禹,张绍广,郭长鑫,张宇飞*
清华大学,航天航空学院,北京100084

引用格式:
Data-Driven Turbulence Modeling for Separated Flows Considering Nonlocal Effect, Chenyu Wu, Shaoguang Zhang, Changxin Guo, and Yufei Zhang, AIAA Journal, 2025.
摘要
RANS湍流模型在工程中应用广泛,但却常常难以准确计算分离流动。近年来,数据驱动方法被用于训练能准确计算分离流动的RANS湍流模型,但有时它们在分离流中的泛化性有限。本研究旨在通过为数据驱动模型引入非当地性,来提升其在分离流中的泛化性。具体来说,我们为 ω方程的修正乘子β构造额外的输运方程,将平均流线上的历史编码进β。使用NASA Hump(驼峰)和周期山的高精度数据对模型系数进行数据驱动式的标定,最终得到β-Transport模型。经测试,β-Transport模型在曲线后台阶、鼓包、不同坡度周期山和多段翼型算例中表现良好,精度优于基于当地建模方法得到的数据驱动湍流模型(SST-CND模型[1])或与之大致相当。β-Transport模型也可泛化到三维简化车算例中。在基本流动方面,β-Transport模型不仅可以准确计算平板边界层、槽道,还可以较为准确地模拟混合层,这优于基于当地数据训练的湍流模型(SST-CND模型)。因此,在建模阶段考虑非当地效应,有望提升数据驱动湍流模型的泛化性。
一、方法步骤
1. 修正项输运方程的构造
修正项B作用于ω方程的破坏项上:
我们为B构建能反映平均流线上的剪切历史的输运方程模型,形式如下:
其中,为旋转率张量,d为壁面距离,
为Spalart提出的屏蔽函数[2],在边界层内为0,在边界层外为1。
和m为待标定参数。构造β方程时,我们假设:
(1)β沿着流线的增长率与当地的剪切(为避免扩张和压缩的影响,用体现)正相关;
(2)在剪切率较小或没有剪切的流动中,β将被耗散至0(通过来耗散β);
(3)β具有和k以及ω相似的湍流扩散机制。
接下来使用遗传算法,基于高精度数据确定方程中的待标定参数。
2. 使用NASA Hump(驼峰)算例和Re = 10595的周期山算例对常数进行标定
我们利用NASA Hump算例和Re = 10595的周期山算例的表面摩阻数据,对β-Transport模型中的常数(和m)进行标定。此外,在标定过程中,我们还约束β-Transport模型在平板边界层中的摩阻系数和SST模型的摩阻系数相比,误差不超过3.0%。使用遗传算法进行多目标优化实现标定,优化目标和约束为:
分别是周期山和Hump算例的流动再附点,上标为LES和Exp的 为LES的再附点和实验所得再附点。
为的相对绝对误差。经过差分进化算法的优化后,得到Pareto前缘如图1所示。在Pareto前缘上选择
,且距离原点尽量近的个体,得到最终的标定结果:
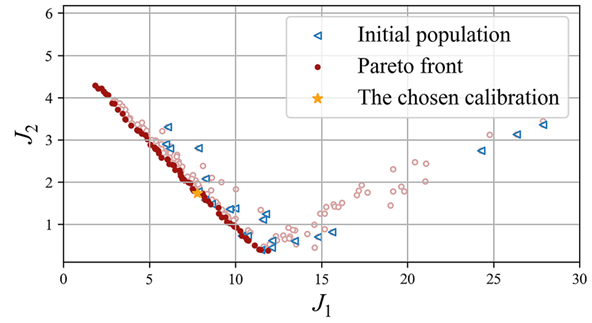
二、结果
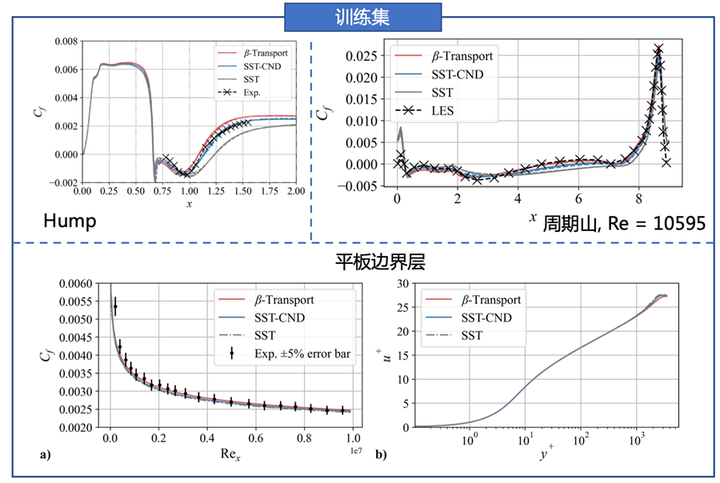
训练集中的结果如图2所示。在Hump和Re = 10595的周期山中,β-Transport模型给出的结果和SST-CND模型相似或明显优于SST-CND模型。在平板边界层算例中,β-Transport模型给出的摩阻系数绝对误差(和SST模型相比)为2.77%,与实验值符合良好,速度剖面与SST模型符合良好,说明β-Transport模型不会恶化零压梯度平板边界层的计算精度。
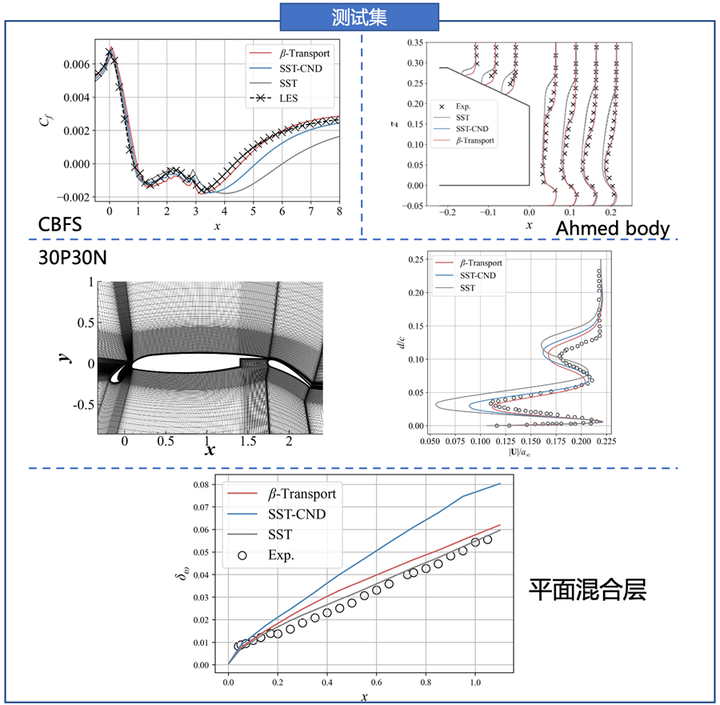
测试集中的结果如图3所示。在CBFS算例中,β-Transport模型的表现明显优于SST-CND模型,预测得到的摩阻系数分布和LES结果更加接近;在三维Ahmed-body算例中,β-Transport模型的结果和SST-CND模型的结果几乎一致,都能更加准确地预测Ahmed-body的尾流。在多段翼型30P30N算例中,β-Transport模型预测出了比SST-CND模型更加准确的速度剖面,表现出了对空气动力学算例良好的泛化性。在平面混合层算例中,相比于SST-CND模型,由于β-Transport模型的生成项在自由剪切流中自动关闭(),而破坏项激活(
),因此在混合层中,β-Transport模型给出的修正量很小,没有非常负面地影响混合层涡量厚度随着流向的增长速度。而由于SST-CND模型的修正只依赖于当地的剪切率,因此SST-CND模型在混合层中激活了修正,造成混合层的涡量厚度发展计算错误。
总结以上结果:通过为修正项构造输运方程,成功将流线上的剪切历史信息编码进修正项中,形成的β-Transport模型在一系列流动中具有优于当地模型(SST-CND模型)的泛化性。因此,为修正项引入非当地效应,有望构造具有更强的泛化能力的数据驱动湍流模型。
参考文献:
[1] Wu C, Zhang S, Zhang Y. Development of a generalizable data-driven turbulence model: Conditioned field inversion and symbolic regression[J]. AIAA Journal, 2025, 63(2): 687-706.
AIAAJ|清华大学张宇飞团队:开发可泛化的数据驱动湍流模型:条件流场反演与符号回归
[2] Spalart P R, Deck S, Shur M L, et al. A new version of detached-eddy simulation, resistant to ambiguous grid densities[J]. Theoretical and computational fluid dynamics, 2006, 20: 181-195.
公众号原文链接(文末附论文资源):
AIAAJ | 清华大学张宇飞团队:考虑非当地效应的分离流数据驱动湍流建模
注:文章由作者原创供稿,并获得作者授权发布。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)