从 7 亿活跃用户数据看 AEO:为什么你的独立站必须抢占 AI 搜索的“第一引用源”?
摘要:本文基于ChatGPT使用报告与多平台内容分发实践,探讨如何在大语言模型(LLM)中获得优先引用。研究发现,49%的用户提问意图直接触发AI检索,而40%的执行意图往往跳过品牌展示环节。通过追踪国内外15个平台发现:1)国内LLM偏好CSDN等专业社区内容;2)国外平台中Perplexity表现最佳,会主动检索中文内容;3)原创性、互动数据(点赞/收藏)和品牌官网内容更易被引用。建议采取&q
摘要:本文基于ChatGPT使用报告与多平台内容分发实践,探讨如何在大语言模型(LLM)中获得优先引用。研究发现,49%的用户提问意图直接触发AI检索,而40%的执行意图往往跳过品牌展示环节。
通过追踪国内外15个平台发现:
1)国内LLM偏好CSDN等专业社区内容;
2)国外平台中Perplexity表现最佳,会主动检索中文内容;
3)原创性、互动数据(点赞/收藏)和品牌官网内容更易被引用。
建议采取"发布权威内容+多平台分发+GSC追踪"的闭环策略,重点优化问答类查询,在AI压缩的购买流程中抢占品牌曝光机会。
目录
一篇符合Google的E-E-A-T文章的大语言模型收录追踪
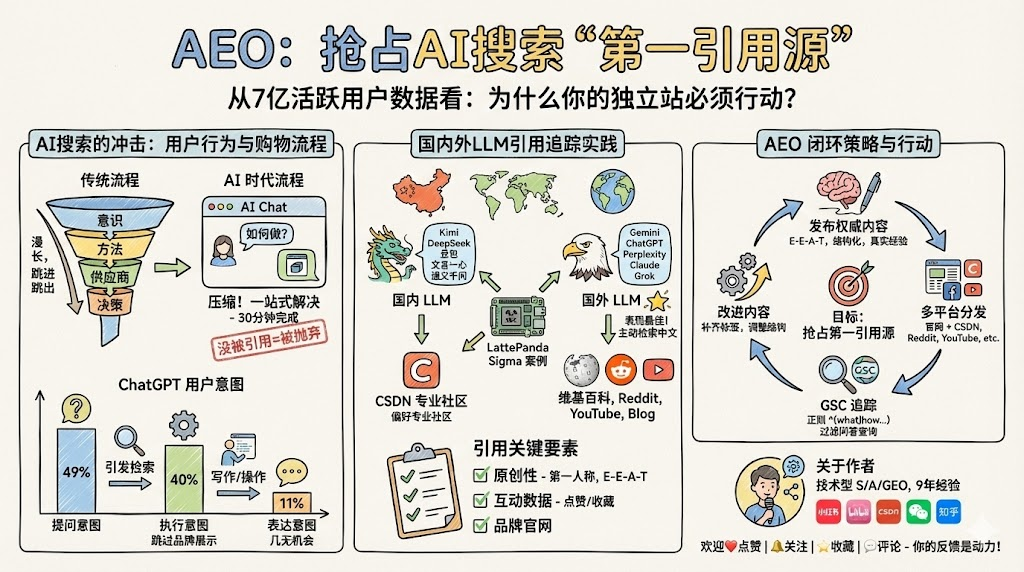
通过从ChatGPT发布的使用报告,结合将一篇最新产生的权威内容发布到自身网站和多平台分发后,追踪在国内外大语言模型平台及搜索引擎的尝试。根据追踪的结果,获得新的见解和经验。改进内容形成闭环。找到实用的经验。完成品牌/产品/服务等在大语言模型中出现和优先被引用。

关键要点
-
ChatGPT发布人们使用报告
-
为什么要抢占在大语言模型中被优先引用?
-
怎么做才能出现在大语言模型/LLM 优先被引用?
ChatGPT发布人们如何使用GPT
ChatGPT用户意图(对7亿周活跃用户数据的报告)
-
49%进行提问意图(Asking Intent)
-
引发检索的查询:针对新信息或核心训练数据未知答案
-
对已知答案不使用检索:直接给出答案 没有引用链接
-
SEO行动:追踪并优化Asking查询
-
使用Google Search Console(GSC)+正则表达式(Regex) ^(what|which|who|where|when|why|how)\s.(best|top|compare|comparison|alternatives|vs|reviews?|pricing|cost|cheap|affordable|near me).
-
或者 GSC 知识问答中查看->你的内容出现在AI概述的数据统计如何查看?
-
在自有网站/Youtube/LinkedIn 等平台提高曝光
-
评估现有资源,决定是集成主题还是新建页面
-
-
-
40%执行意图(Doing Intent)
-
核心用途:写作(Writing)
-
不总是直接展示品牌/产品/服务
-
代表查询: 流程结束阶段/高意图查询
-
I need to set up seat-based billing... Which platforms support this
-

流程结束阶段/高意图查询 AI 提示词
-
-
-
11% 表达意图(Expressing Intent)
-
几乎没有品牌出现的机会
-
AI 搜索对买家购物流程的影响
-
购物流程的压缩
-
整个购买流程可能在一个聊天对话框内完成
-
从一个问题开始到购买结束只(需要30分钟)
-
-
转化漏斗
-
适于:问题意识
-
止于:解决具体问题
-
高转化点:ChatGPT推荐解决方案/产品
-
-
终极目标:驱动品牌搜索
-
核心价值:在AI回复中提高品牌覆盖率
-
品牌搜索的转化率远高于标准查询
-
重点关注商业查询
-
-
与Google的关系
-
并非相互残杀,而是互相补充
-
大多数ChatGPT用户也使用Google(95%)
-
AI 搜索效果追踪与衡量
-
需要追踪的关键指标
-
品牌是否出现在AI中回复
-
品牌在AI回复中的出现位置/排名
-
-
免费追踪机制
-
使用 Google Search Console(GSC)+正则表达式(Regex)
-
方式: 手动/模版化追踪品牌提及和排名
-
-
成功原则
-
优秀的SEO工作对AI 搜索平台仍然有巨大影响
-
无法追踪,就无法改进
-

为什么要抢占在大语言模型中被优先引用?
从上面ChatGPT报告中,我们可以见著知微的发现,
如果AI已经知道答案,就不再使用搜索,直接使用已经训练好的结果。
那么你提供的品牌/产品/服务 根本没有机会在用户与大语言模型对话中出现。客户可能就已经完成购买了。
在大语言模型出现之前 ,如下图Before所示,买家通常从问题 → 方法 → 供应商 → 决策,会在不同阶段跳进跳出,不是一步步顺序完成。在AI阶段,这个路程已经被压缩了。在一个对话过程中就可以完成80-90%的操作,如果你的品牌完全没有出现的机会,你就已经被抛弃了。
| 阶段 | 名称 | 买家行为 / 关注点 | 常见痛点 / 异议 | 卖方 / 营销方 可以做的事情 |
| 1 | Awareness(意识 / 触发) | 买家还未主动搜索解决方案,只是觉察到某个问题或机会;可能因为某个“触发事件”(trigger)使得这个问题被提升为优先议题 | 买家还处于“有没有这个问题?”、“是不是应该处理?”的模糊阶段;可能有“先压一压再说”的心态 | 在目标渠道 / 社区 /行业里提供“思想领导力/观点文章 / 原生内容 / 事件演讲 / 社交影响力”以早期触达买家,抓住触发点。 |
| 2 | Demand Generation(Category Consideration / 类别考量) | 买家开始了解各种“解决思路 / 方法类别”(例如:ABM、漏斗营销、外包 vs 自建) | 买家还没确定“要做哪个方向 / 方法” | 提供教育性内容(白皮书、框架、案例、网络研讨会等),帮助买家确立类别认知,对比不同路径的优劣。 |
| 3 | Demand Generation(Solution / 方案选择) | 买家在确认类别后,开始调研具体供应商 / 解决方案 | 买家对供应商能力、特色、差异化、信任感有疑虑 | 在内容中嵌入你产品的差异、特色、成功案例/客户故事。透过网站、评测平台、同行推荐等方式让你被发现并记住。 |
| 4 | Demand Capture(需求捕获 / “准备下单”阶段) | 部分买家主动接触你(请求 Demo / 试用 / 咨询) | 表单设计不合理、价格隐藏、流程繁琐、团队协调不一致等成为购买摩擦 | 优化转化流程:简化表单、清晰价格、快速安排演示、销售-营销团队紧密配合。 |
| 5 | Activation(推动内部联系 / 决策共识) | 买家内部推动项目(审批、共识达成、论证商业价值) | 内部意见不一致、关键疑问没人能解答、流程拖延 | 利用意图数据识别可推进的账户,做主动激活(ABM)操作;提供内部决策支持内容(商业案例、ROI 模型、参考客户) |
| 6 | Customer Success & Advocacy(客户成功与倡导) | 产品 / 服务交付、实施、客户使用、满意度、推荐意愿 | 如果客户使用不到位、效果不明显,容易流失;客户可能不主动去推广你 | 主动介入客户成功管理,做满意度跟踪、教育培训、主动推介客户做推荐 / 案例 / 口碑。 |
| 7 | Expansions & Upsells(扩展 / 向上销售) | 在已有客户基础上,挖掘新的使用场景 / 模块 / 业务扩张 | 客户可能满足当前最低需求,不愿意投入新模块 | 通过客户访谈 / 定期回顾发现潜在需求,提供新场景/增值解决方案,用成功案例 + 数据支持推动扩张。 |

所以我们不得不创作符合搜索用户意图并传达相关、新鲜或独特的内容。以期引发大语言模型进行训练,这部分和SEO也是契合的。
-
能够为从前从来没有人解决过的问题提供解决方案
-
侧重于垂直细分市场并将自己打造成该领域的领导者
怎么做才能出现在大语言模型/LLM 优先被引用?
这次调研主要是从了解产品、使用关键词、关注问题、产生一篇符合Google的E-E-A-T文章包括(图片、表格、对比)以第一人称的真实经验、好的排版方式正确的使用Headline 发布到自身网站外的多平台后,进行在国内、国外大语言模型、搜索引擎 3个平台进行后续效果的追踪。
国内大语言模型:kimi(K2)、deepseek、豆包(字节)、文言一心、通义千问(阿里)、腾讯元宝、讯飞星火
国外大语言模型:gemini、chatgpt、perplexity、grok、claude
搜索引擎:baidu、google、bing、duckduckgo、brave
国内外LLM对话流程及链接引用分析
使用的对话内容关键词
国内:X86 单板机
国外:X86 SBC
| 引用源 | 回答结构 | 引用网站 | 引用源标题分析 | |
| kimi | 是 | 应用场景 + 总结 | 阿里巴巴、脉脉、知乎、网易、新浪 | 产品、新品发布、对比 |
| deepseek | 无 | 简介+产品对比+购买权衡+应用场景 | 腾讯news.qq.com、ithome.com IT之家、21ic.com、digikey.cn | 新品 |
| 豆包(字节) | 有 | 简介+架构特点+性能优势+常见型号+应用领域 | csdn、eet-china.com | 主流单板机、对比 |
| 通义千问 | 无 | 简介+主要特定和优势+常见品牌与代表型号+与ARM单板机对比+总结 | 国外 | |
| 腾讯元宝 | 有 | 简介+热门x86单板机概览+如何选择x86单板机+x86单板机的优势与挑战+应用场景举例 | 公众号、pconline.com.cn | 新品、入选榜单、可跑windows、中国单板计算机市场研究报告(2023年) |
| gemini | 无 | 两个答案; 总结+关键特征+使用案例 | 训练数据 | |
| chatgpt | 无 | 总结+核心特点+常见品牌与产品+和ARM SBC对比 | 维基百科、explainingcomputers、lattepanda blog | 集合页、对比、具体应用测评、个人见解 |
| perplexity | 有 | 总结 + 流行产品+特征+选择x86 SBC的主要考虑因素 + 总结 LattePanda V1 | reddit、dfrobot blog、youtube、lp forum、udoo、dfrobot topic、youtube | 高度相关首页、分类页、集合页、个人使用场景 |
| grok | 有 | 总结+2025的不同品牌产品列表+如何选择sbc+选择x86 SBC的注意事项+去哪里购买?+附注事项 | 亚马逊、newegg、cnx-software、howtogeek | 2025最好的sbc、分类页、集合页、个人见解 |
| claude | 无 | 总结+ Intel/AMD sbc 分类 + 关键优势+常见案例 | 训练数据 |
主要是从是否有引用源、回答结构、引用网站、引用源标题分析:
引用源:
Gemini 是基于训练数据,没有引用链接,你对话要求它贴出来引用链接也没有。相对其他大语言模型,Gemini可以说比较有个性,它会说已经回答过问题,拒绝再次回答。
回答结构:
简介/总结+特点+常见品牌/型号+对比+使用案例+总结+注意事项。
Chatgpt 有时候会提供2种方案。
引用网站:
国内大语言模型的引用网站,在单板机这个领域,csdn较好。
国外大语言模型:维基百科、reddit、youtube。
引用源标题分析:
大语言模型LLM喜欢新品、榜单、对比 VS、具体测评、个人见解、结合页
一篇符合Google的E-E-A-T文章的大语言模型收录追踪
针对一篇文章发布在自身网站外、csdn、知乎、与非网、LinkedIn、reddit后;
国内大语言模型
基本上当天,稍晚第二天就会被收录,在deepseek和豆包会被引用,速度很快,更倾向于自身网站(原站点)国内各语言模型分属不同生态。会首先从自身生态系统获取结果。如,比如微信更偏向于公众号。
总的来说csdn在大语言模型中被引用较好,以及写作者的正反馈给的更多,文章的浏览量,收藏,点赞以及官方的曝光流量券都要好于其他平台。
国外大语言模型
Gemini 是不提供引用来源的,内容更新较慢
Chatgpt 表现相对稳定
Perplexity 非常牛,还会搜索了中文的帖子
| LLM/问题清单 | LattePanda Sigma(x86 SBC/单板机)的AI边缘计算:用ollama模型批量生成SEO图片alt属性的实践 如果有产品会去官方查询 | LattePanda Sigma的AI边缘计算实践还有哪些案例? | ollama + mini-cpm-v 和 qwen2.5vl seo 的应用 | x86 单板机在 AI边缘计算实践还有哪些案例?/ 推荐一些x86单板机在边缘计算中的应用案例 |
| kimi(K2) | 之前问过,再次提问就会变成回答。没有引用链接 | 是 | ||
| deepseek | 是 | 是 更倾向于原站点 | 是 更倾向于原站点 | |
| 豆包(字节) | 是 | 是 更倾向于原站点 | 是 更倾向于原站点 | |
| 文言一心 | 是 csdn | 是 知乎/csdn | ||
| 通义千问(阿里) | 之前问过,再次提问就会变成回答。没有引用链接 | 否 | ||
| 腾讯元宝 | 否 / 偏向微信公众号 | |||
| 讯飞星火 | 是 | |||
| gemini | 否 | |||
| chatgpt | 之前问过,再次提问就会变成回答。没有引用链接 | 否 | ||
| perplexity | 是 | 是/专业版牛逼 搜索了中文的帖子 | ||
| grok | reddit 帖子 | 否 | ||
| claude | 否 | |||
| baidu | 是 | 是 | 是 | 是 |
| 是 | 是 | 是 | 否 | |
| bing | 是 | 否 | 否 | 否 |
| duckduckgo | 是 | 是 | 否 | 否 |
| brave |
模拟一次真实对话在国内大语言模型中的表现
为了节省时间,国内外大语言模型、搜索引擎 在浏览器的书签建了3个文件夹进行分类。
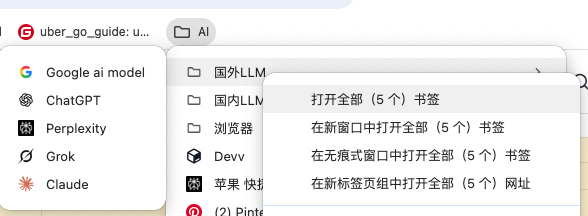
当你对需要某个大语言模型进行追踪时,将鼠标移到具体的文件夹,右击 打开全部(*个)书签。就会一次性打开
依次输入问题,观察回答结果 查看内容在大语言模型中是否出现和位置:
-
我想搭建一个家庭流媒体服务器
-
如果我想买一台单板机来实现,你有什么推荐吗?
| LLM/问题清单 | kimi(K2) | deepseek | 豆包(字节) | 文言一心 | 通义千问(阿里) | 腾讯元宝 | 讯飞星火 |
| 我想搭建一个家庭流媒体服务器 | 硬件方案/软件方案/搭建步骤/可选增强功能/预算参考 | 主流媒体服务器软件选择/搭建步骤详解/实用技巧与主意事项/如何选择 | 明确核心需求/硬件选择/软件与硬件/资源管理/远程访问/避坑指南 | 确定需求与硬件准备/选择流媒体服务器软件/安装与配置服务器/客户端访问/进阶优化/常见问题解决/替代方案 | 你的主要目标是什么?/你有哪些设备需要播放?/你的媒体文件目前存放在哪里?/你的技术背景如何?/你打算用什么设备作为服务器? 目前最流行的方案 | 硬件准备/硬件选择/媒体服务器选择/媒体库配置/网络设置/客户端连接/常见问题解答 | 明确需求&硬件选型/操作系统安装/核心软件部署/网络与远程访问配置/性能优化&安全防护/常见问题解决/扩张玩法 |
| 如果我想买一台单板机来实现,你有什么推荐吗? | 是 LattePanda sigma 来源csdn | 是 LattePanda sigma 来源csdn | 是 LattePanda mu | 否 喜欢10大/好用/榜单/最佳 | 是 LattePanda sigma 来源csdn | 否 没有引用连接 |
总结
无论从国内还是国外大语言模型和SEO策略一样,都喜欢新鲜、独特的内容,当搜索到品牌词的时候,同样的内容发布到不同平台,更倾向于品牌所属网站的内容排在前面。文章的互动数据非常重要,像浏览量、收藏、点赞。也是衡量一篇文章的权威和专业的重要指标。
FAQ:
Q1: 为什么说 AI 搜索(AEO)压缩了买家的购物流程?
答: 在传统 SEO 时代,买家从意识到问题到做出决策需要跨越多个页面和阶段。而在 AI 时代,由于大语言模型能进行多轮对话,买家可以在同一个对话框内完成从“咨询方法”到“推荐产品”再到“品牌对比”的全过程,时间可能从数天缩短至 30 分钟。如果品牌在 AI 检索的第一轮没被引用,就可能失去后续所有曝光机会。
Q2: 如何利用 Google Search Console (GSC) 追踪 AI 搜索的流量?
答: 文中推荐使用正则表达式(Regex)过滤出带有提问意图的关键词。例如使用:^(what|which|who|where|when|why|how)\s.*(best|top|compare|reviews|cost|near me)。这能帮你识别出哪些用户是通过“Asking 查询”进入网站的,从而评估 AI 概述(AIO)对你网站的覆盖程度。
Q3: 针对 ChatGPT 的“执行意图 (Doing Intent)”,站长应该如何应对?
答: “执行意图”占用户行为的 40%,如写代码、改文章。这类意图通常不直接展示品牌。站长应在内容中嵌入解决具体问题的“操作指南”或“集成模版”(如 LattePanda 的边缘计算实践案例)。当用户问到“如何实现某功能”时,你的品牌/产品作为唯一的解决方案示例出现,才能在执行流程中抢占一席之地。
Q4: 国内外大语言模型在引用来源上有何明显差异?
答: 国内平台: 强依赖自身生态(如腾讯元宝偏向公众号,文言一心偏向知乎/百度系)。在单板机领域,CSDN 的引用率和正反馈(流量券、曝光)表现最优。 国外平台: 引用源更广,包括维基百科、Reddit、YouTube 和品牌 Blog。其中 Perplexity 表现最强,它具备跨语言搜索能力,甚至会主动检索中文的高质量帖子作为引用。
Q5: 为什么互动数据(点赞、收藏)对 AI 可见性如此重要?
答: AI 模型在挑选引用源时,不仅看关键词匹配,更看内容的权威度与置信度。浏览量、收藏量和点赞数是衡量文章专业度的重要信号(Signal)。互动率高的文章更容易被 LLM 判定为该领域的“权威共识”,从而在引用排名中靠前。
Q6: 为什么 Gemini 的回答中常常看不到引用链接?
答: 根据文中实验,Gemini 倾向于基于纯训练数据回答,且具有一定的“排他性”(有时拒绝重复回答)。对于这类“闭源引用”倾向的模型,核心策略是通过海量的高质量 E-E-A-T 内容喂养,让品牌进入其底层的训练数据集(Knowledge Graph),而非仅仅依赖实时检索。
Q7: “多平台分发”对于 AEO 的核心贡献是什么?
答: 它不仅是为了增加曝光,更是为了通过高权重平台(如 Reddit, CSDN)为原站内容做背书。实验证明,同一内容发布到多平台,AI 在搜索品牌词时更倾向于引用原站内容,但多平台的互动数据能极大地加速 AI 对原站链接的“发现”和“信任”过程。
Q8: 如何撰写一篇“LLM 友好型”的 E-E-A-T 文章?
答: 文章应包含:第一人称的真实经验、独特的实验数据(如文中提到的 LattePanda 边缘计算实践)、清晰的图片与对比表格、以及正确使用的 Headline(H1-H4)。这种结构化的深度内容极易被 AI 拆解为“回答片段”。
Q9: AI 搜索时代,品牌搜索(Brand Search)的价值变了吗?
答: 价值反而更大了。AI 搜索的终极目标是驱动高转化的品牌搜索。当 AI 在回复中推荐了你的品牌,用户转而去搜索你的品牌名时,其转化率远高于通用的行业关键词搜索。AEO 的本质是“在 AI 推荐中种草,在品牌搜索中收割”。
Q10: 针对 SBC(单板机)等外贸行业,目前最实用的 AEO 闭环策略是什么?
答: 1. 内容生产: 创作新鲜、独特的技术实操文(如 Ollama + x86 SBC 实践)。 2. 分发: 优先布局 CSDN、知乎(国内)及 Reddit、YouTube、LinkedIn(国外)。 3. 追踪: 定期在不同 LLM 中模拟用户提问(如“家庭服务器推荐”),观察品牌出现位置。 4. 改进: 根据 AI 的回答逻辑,补齐缺失的语义标签或调整内容结构,形成持续优化的闭环。
关于作者
我是一名自我探索的技术型S/A/GEO,近9年外贸独立站开发&运维经验。
全平台账号小红书、bilibili 和csdn 同号,微信公众号:Adair 代呆呆,知乎:Adair。
欢迎有同样兴趣的朋友关注我。后续会陆续更新我的AEO探索之旅。
希望我的记录能够给你带来启发。欢迎大家多多和我留言交流~
欢迎 ❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论
你的每一个反馈,对我都很重要,是我持续输出的动力~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 33
33 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)