如何利用强化学习算法训练自主决策 Agent,实现复杂动态环境下的目标优化
强化学习为自主决策 Agent 提供了一种面向长期目标的优化范式,使其能够在复杂、动态且不确定的环境中,通过持续交互逐步形成稳定有效的决策策略。与传统规则或监督学习方法相比,强化学习更强调环境反馈驱动与策略自适应,在状态难以穷举、奖励具有延迟性的场景下具备明显优势。在实际工程落地过程中,算法本身只是基础,更关键的是对环境建模、奖励设计、训练稳定性以及系统协同能力的综合把控。只有将强化学习与工程约束
如何利用强化学习算法训练自主决策 Agent,实现复杂动态环境下的目标优化
一、问题背景:为什么需要“自主决策 Agent”
在真实世界中,Agent 往往运行在高度动态、部分可观测、存在不确定性的环境中,例如:
- 自动驾驶中的复杂交通流
- 智能调度系统中的实时资源分配
- 游戏 AI 或仿真环境中的多目标博弈
- 智能体工作流中对工具、策略的自主选择
在这类场景下,规则驱动或监督学习存在明显局限:
- 难以枚举所有状态
- 环境反馈具有延迟性
- 最优策略需要通过长期试错获得
**强化学习(Reinforcement Learning, RL)**正是解决此类问题的核心技术,它通过“试错 + 奖励反馈”的方式,训练 Agent 在复杂环境中逐步形成最优决策策略。
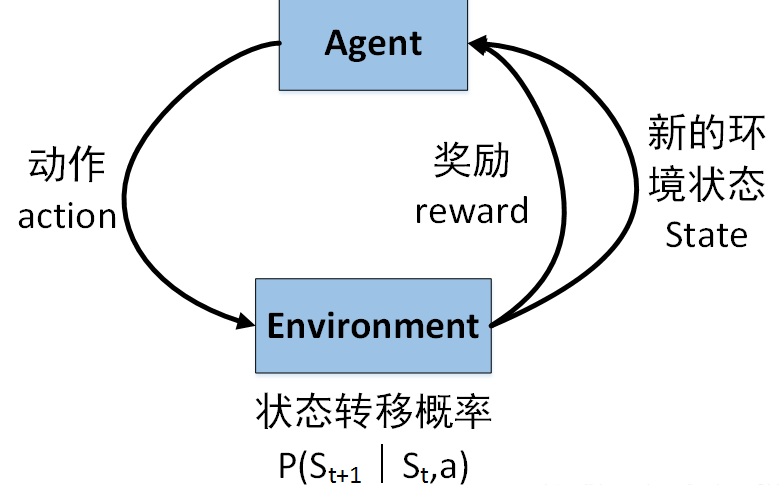
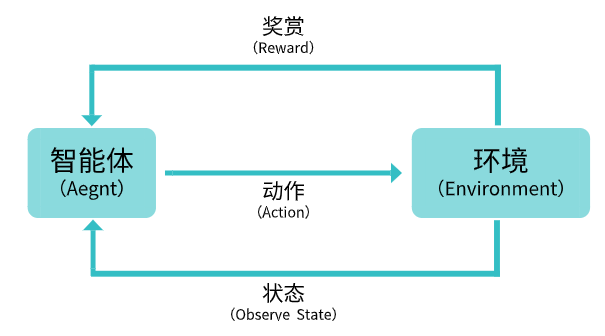
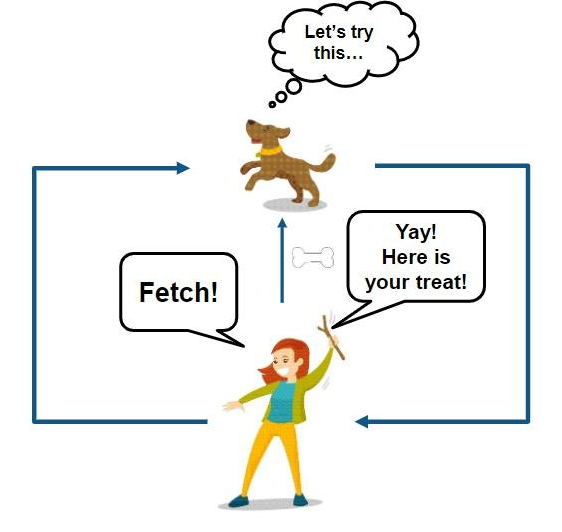
二、强化学习视角下的 Agent 决策闭环
从工程角度看,一个强化学习 Agent 的运行逻辑可以抽象为以下闭环:
- 感知环境状态(State)
- 基于当前策略选择动作(Action)
- 执行动作,环境发生变化
- 获得奖励反馈(Reward)
- 更新策略,使未来决策更优
这一过程强调两个关键特征:
- 在线交互:数据来自 Agent 与环境的持续交互
- 长期收益优化:当前决策服务于未来整体目标,而非即时收益
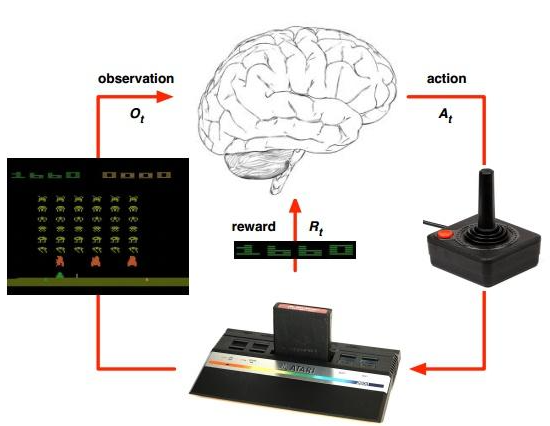
三、算法选择:从 Q-Learning 到深度强化学习
在实际项目中,算法选择取决于状态空间规模与复杂度:
| 场景 | 推荐方法 |
|---|---|
| 状态空间小、离散 | Q-Learning |
| 状态空间大、高维 | DQN |
| 连续动作空间 | Policy Gradient / Actor-Critic |
| 高稳定性需求 | PPO |
下面以**DQN(Deep Q-Network)**为例,展示如何训练一个自主决策 Agent。
四、工程实现:基于 DQN 的自主决策 Agent
4.1 环境定义(示例)
我们假设一个简化的动态环境,例如:
- Agent 在环境中移动
- 目标是尽可能获得高奖励
- 环境状态为连续向量
这里使用 gymnasium 风格接口。
import gym
import numpy as np
4.2 构建 Q 网络
使用神经网络近似“状态 → 动作价值”的映射关系。
import torch
import torch.nn as nn
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, action_dim)
)
def forward(self, x):
return self.net(x)
4.3 Agent 设计
Agent 负责三件事:
- 动作选择
- 经验存储
- 策略更新
import random
from collections import deque
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.action_dim = action_dim
self.memory = deque(maxlen=10000)
self.q_net = QNetwork(state_dim, action_dim)
self.target_net = QNetwork(state_dim, action_dim)
self.target_net.load_state_dict(self.q_net.state_dict())
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=1e-3)
def act(self, state, epsilon=0.1):
if random.random() < epsilon:
return random.randrange(self.action_dim)
state = torch.FloatTensor(state).unsqueeze(0)
return torch.argmax(self.q_net(state)).item()
def store(self, transition):
self.memory.append(transition)
4.4 策略更新逻辑
通过经验回放机制,提高训练稳定性。
def train_step(agent, batch_size=64):
if len(agent.memory) < batch_size:
return
batch = random.sample(agent.memory, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions).unsqueeze(1)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.FloatTensor(dones)
current_q = agent.q_net(states).gather(1, actions).squeeze()
next_q = agent.target_net(next_states).max(1)[0].detach()
target_q = rewards + (1 - dones) * next_q
loss = nn.MSELoss()(current_q, target_q)
agent.optimizer.zero_grad()
loss.backward()
agent.optimizer.step()
4.5 训练主循环
env = gym.make("CartPole-v1")
agent = DQNAgent(env.observation_space.shape[0], env.action_space.n)
for episode in range(500):
state, _ = env.reset()
total_reward = 0
while True:
action = agent.act(state)
next_state, reward, done, _, _ = env.step(action)
agent.store((state, action, reward, next_state, done))
train_step(agent)
state = next_state
total_reward += reward
if done:
break
agent.target_net.load_state_dict(agent.q_net.state_dict())
print(f"Episode {episode}, Reward: {total_reward}")
五、在复杂动态环境中的关键工程问题
在真实业务中,强化学习 Agent 通常需要解决以下挑战:
1. 奖励设计
- 奖励过于稀疏 → 学习缓慢
- 奖励设计不当 → 策略偏移
2. 状态建模
- 如何压缩高维状态
- 是否引入历史上下文(RNN / Transformer)
3. 稳定性与安全性
- 策略震荡
- 冷启动风险
- 在线学习的安全约束
4. 与大模型 / 规则系统协同
- RL Agent 负责决策优化
- LLM 负责高层规划与解释
- 规则系统提供安全边界
六、总结
强化学习为自主决策 Agent提供了一种从环境反馈中持续进化的能力,使其能够在复杂、动态、不确定的环境中实现长期目标优化。
在工程实践中,成功的强化学习系统往往并非“纯算法胜利”,而是:
合理建模 + 稳定训练 + 系统协同 + 持续迭代
当强化学习 Agent 与仿真环境、业务规则、大模型能力深度融合时,它将不再只是一个“学习算法”,而是一个真正具备自主决策与策略进化能力的智能系统。
强化学习为自主决策 Agent 提供了一种面向长期目标的优化范式,使其能够在复杂、动态且不确定的环境中,通过持续交互逐步形成稳定有效的决策策略。与传统规则或监督学习方法相比,强化学习更强调环境反馈驱动与策略自适应,在状态难以穷举、奖励具有延迟性的场景下具备明显优势。在实际工程落地过程中,算法本身只是基础,更关键的是对环境建模、奖励设计、训练稳定性以及系统协同能力的综合把控。只有将强化学习与工程约束、业务目标和其他智能模块有机结合,才能构建出真正具备自主决策与持续优化能力的智能 Agent。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)