用 Java 玩转本地大模型:Spring AI + Ollama 实现网页端实时对话
今天我就分享一下,如何用 Spring AI 1.0.0-M8 搭配 Ollama,快速搭建一个 流式问答的 HTML 页面。
之前的文章里已经教会了大家怎么在本地安装ollama以及运行模型。接下来要开始做真正的JAVA AI应用了,大家准备好了吗?
最近玩本地大模型的朋友越来越多,但大多数人都是在命令行里和模型对话。说实话,这种方式有点反人类
——体验远不如在网页里直接聊天舒服。
那有没有办法,既能用上本地的 Ollama 模型,又能做一个像 ChatGPT 那样的网页,回答还能一字一字“流”出来?
答案是:可以,而且很简单。今天我就分享一下,如何用 Spring AI 1.0.0-M8 搭配 Ollama,快速搭建一个 流式问答的 HTML 页面。
为什么要搞一个流式页面?
命令行交互虽然轻量,但:
- 回答出来是“一坨文字”,不直观;
- 不方便做界面交互,更别提加点样式;
- 给非技术朋友用,劝退指数 100%。
而流式问答的页面:
- 回答会像打字机一样逐字出现,体验更自然;
- 网页界面简单易用,谁都能上手;
- 后面可以随便扩展功能,比如多轮对话、模型切换、知识库对接。
一句话:有了网页,才是真正可用的产品形态。
Ollama 作为本地模型引擎
Ollama 的定位很清晰:让本地大模型跑起来尽可能简单。
- 安装后会在本地开一个服务,默认端口 11434;
- 你只要
ollama run qwen:14b,模型就能下载并运行; - Spring AI 刚好可以无缝调用这个本地服务。
所以这次我们不需要复杂的配置,只要把 Spring Boot 和 Ollama“连起来”,就能玩。
Spring AI 1.0.0-M8 的作用
Spring AI 相当于给大模型封了一层 Java 接口,我们不用管复杂的 HTTP 请求,也不用自己拼 JSON,直接用现成的客户端。
最关键的是,它支持 流式输出。
也就是说,模型生成的内容不会一次性返回,而是源源不断推过来,你前端就能一字一字显示。
这一点,正好满足我们要的“网页打字机”体验。
项目思路
整个流程其实很清晰:
- Ollama 本地服务 → 提供大模型 API。
- Spring Boot 应用 → 作为中间层,请求模型并做流式输出。
- HTML 页面 → 前端通过
EventSource订阅流式回答,并实时渲染。
换句话说,Spring Boot 是“大脑”,Ollama 是“引擎”,HTML 是“界面”。
实现效果
- 浏览器里打开一个简单的聊天页面;
- 输入问题,比如“给我写一首关于秋天的诗”;
- 回答会像 ChatGPT 一样一字一字流出来;
- 体验完全离线,不花一分钱。
-------------------------好了,废话不多说,上代码-----------------
一、准备工作
首先确保:
这一步没有的,请到我之前的文章里学习。
-
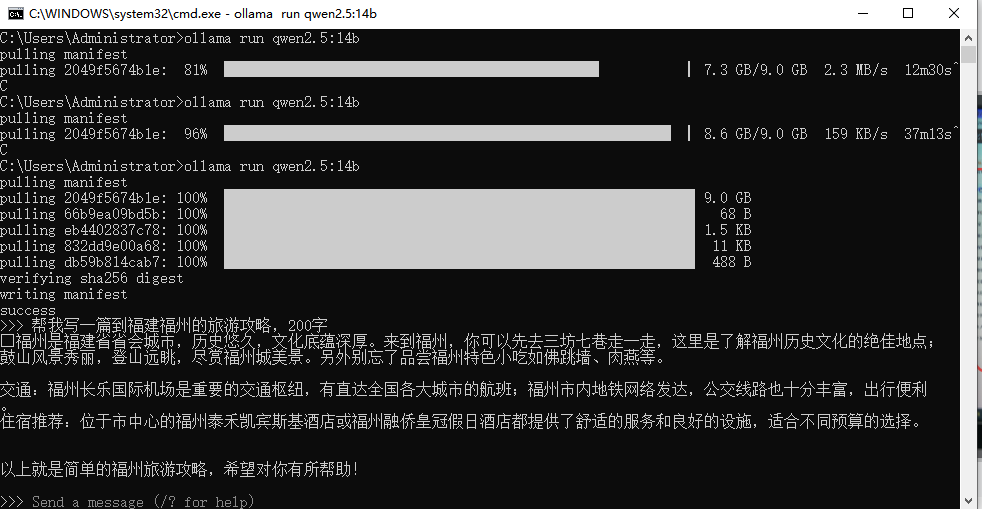
你已经安装好 Ollama,并能正常运行模型,例如:
ollama run qwen:14b如果能在命令行和模型对话,就说明 Ollama 环境没问题
二、Spring Boot 项目依赖
在 pom.xml 中加入 Spring AI 的 Ollama starter:
以下是我的配置,大家可以复制参考,用的是JDK17
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.botongsoft</groupId>
<artifactId>botong-ai</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>botong-ai</name>
<description>Spring AI + Ollama Demo</description>
<properties>
<java.version>17</java.version>
<spring-boot.version>3.2.5</spring-boot.version>
<spring-ai.version>1.0.0-M8</spring-ai.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<!-- Spring Boot Web (可选: 如果只用 WebFlux 可删) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- WebFlux: 必须,用于流式输出 (SSE) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- Spring AI Ollama -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- Lombok (可选) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!-- Spring Boot BOM -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
<!-- Spring Boot 打包插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
</plugin>
</plugins>
</build>
<repositories>
<!-- Spring Milestone 仓库: 用于 Spring AI M 版本 -->
<repository>
<id>spring-milestones</id>
<name>Spring Milestone Repository</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>
</project>
三、配置 application.properties
在配置文件里声明 Ollama 的地址和默认模型:
server.port=9999
spring.ai.ollama.chat.model=qwen2.5:14b
spring.ai.ollama.chat.options.num-predict=4096
spring.ai.ollama.chat.options.num-ctx=8192
四、编写后端接口
这里是关键部分,我们要写一个支持流式输出 + 记忆的接口。
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
import java.util.List;
import java.util.Map;
@RestController
@RequiredArgsConstructor
@RequestMapping("/ai")
public class OllamaController {
private final ChatModel chatModel; // 或 StreamingChatModel
private final ChatMemory chatMemory; // 注入内存管理器
@PostMapping(value = "/chat", consumes = MediaType.APPLICATION_JSON_VALUE,
produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chat(@RequestBody Map<String, String> body) {
String conversationId = body.getOrDefault("conversationId", ChatMemory.DEFAULT_CONVERSATION_ID);
String messageText = body.getOrDefault("message", "");
// 1. 构建用户消息
Message userMessage = new UserMessage(messageText);
// 2. 加入记忆
chatMemory.add(conversationId, userMessage);
// 3. 获取上下文历史(包括用户消息和 AI 回复)
List<Message> history = chatMemory.get(conversationId);
// 4. 用历史构建 Prompt
Prompt prompt = new Prompt(history);
// 5. 调用模型(流式返回)
return chatModel.stream(prompt)
.map(resp -> {
String text = resp.getResult().getOutput().getText();
// 记得把 AI 回复也加入记忆
chatMemory.add(conversationId, resp.getResult().getOutput());
return text;
});
}
}
五、HTML 页面
写一个简单的前端页面放到src/main/resources/static/index.html,订阅流式回答:
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8" />
<title>Markdown 渲染 SSE 示例</title>
<!-- 你指定的版本 -->
<script src="knowledge/markdown.js"></script>
<style>
body { font-family: system-ui, -apple-system, Segoe UI, Roboto, Arial; margin: 20px; background:#f5f7fb; }
h2 { margin: 0 0 10px; }
.toolbar { display:flex; gap:10px; align-items:center; }
#messageInput { flex:1; height:36px; padding:0 10px; border:1px solid #d0d7de; border-radius:8px; background:#fff; }
#sendBtn { height:36px; padding:0 14px; border:none; border-radius:8px; background:#2263ff; color:#fff; font-weight:600; cursor:pointer; }
#sendBtn:hover { filter:brightness(.95); }
#output { margin-top:12px; background:#fff; border:1px solid #e5e7eb; border-radius:8px; padding:14px; height:520px; overflow:auto; }
/* 一点常用的 Markdown 样式 */
#output h1 { font-size:22px; margin: .8em 0 .4em; }
#output h2 { font-size:18px; margin: .8em 0 .4em; border-bottom:1px solid #eee; padding-bottom:4px; }
#output p { margin: .5em 0; }
#output ul { padding-left: 1.2em; }
#output li { margin: .25em 0; }
#output pre { background:#0b1220; color:#e5e7eb; padding:10px; border-radius:6px; overflow-x:auto; }
#output code { background:#f6f8fa; border-radius:4px; padding:0 4px; }
</style>
</head>
<body>
<h2>Markdown 渲染回答</h2>
<div class="toolbar">
<input id="messageInput" type="text" placeholder="请输入你的问题(服务器返回 Markdown 文本)" />
<button id="sendBtn">发送</button>
</div>
<div id="output">请输入问题并点击发送</div>
<script>
const input = document.getElementById('messageInput');
const outputDiv = document.getElementById('output');
const sendBtn = document.getElementById('sendBtn');
marked.setOptions({ gfm: true, breaks: true, smartLists: true });
let markdownBuffer = "";
// 把流式拼起来后做“轻量归一化”,解决:
// 1) “markdown# 标题”前缀;2) “##/###/1./-”不在行首;3) “#”后没空格。
function normalizeMd(md) {
if (!md) return '';
// HTML 实体反转义
md = md.replace(/ /g, ' ')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/&/g, '&');
// 去掉开头的 "```markdown" 或 "```"
md = md.replace(/^```(?:markdown)?\s*/i, '');
// 去掉结尾的 "```"
md = md.replace(/```$/i, '');
// 去掉开头的 "markdown#"
md = md.replace(/^(\s*)markdown\s*#/i, '$1#');
// 把行中间的标题/列表标记换到行首
md = md.replace(/(?<!^)(?<!\n)\s*(#{1,6}\s)/g, '\n$1');
md = md.replace(/(?<!^)(?<!\n)\s*((?:\d+[.)]|[-*•·])\s)/g, '\n$1');
// # 后补空格
md = md.replace(/(^|\n)(\s{0,3}#{1,6})([^\s#])/g, '$1$2 $3');
// 合并多余空行
md = md.replace(/\n{3,}/g, '\n\n');
return md;
}
sendBtn.onclick = async () => {
const message = input.value.trim();
if (!message) return;
outputDiv.textContent = "连接中…";
markdownBuffer = "";
const resp = await fetch("/ai/chat", {
method: "POST",
headers: { "Content-Type": "application/json", "Accept": "text/event-stream" },
body: JSON.stringify({ message,"conversationId":"xxx1" })
});
if (!resp.ok || !resp.body) {
outputDiv.textContent = "连接失败";
return;
}
outputDiv.innerHTML = ""; // 清空占位
const reader = resp.body.getReader();
const decoder = new TextDecoder();
let sseBuffer = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
sseBuffer += decoder.decode(value, { stream: true });
// 逐行解析 SSE:每行形如 "data: xxx"
let idx;
while ((idx = sseBuffer.indexOf("\n")) >= 0) {
const line = sseBuffer.slice(0, idx);
sseBuffer = sseBuffer.slice(idx + 1);
if (!line) continue;
if (line.startsWith("data:")) {
const chunk = line.slice(5); // 不人为加 \n
markdownBuffer += chunk;
// 实时渲染(带归一化)
const mdFixed = normalizeMd(markdownBuffer);
outputDiv.innerHTML = marked.parse(mdFixed);
outputDiv.scrollTop = outputDiv.scrollHeight;
}
}
}
// 收流后再做一次最终归一化与渲染(确保尾部语法也被吃到)
const mdFinal = normalizeMd(markdownBuffer);
outputDiv.innerHTML = marked.parse(mdFinal);
};
</script>
</body>
</html>
六、运行与效果
- 启动 Spring Boot 项目;访问http://127.0.0.1:9999
- 打开 HTML 页面;
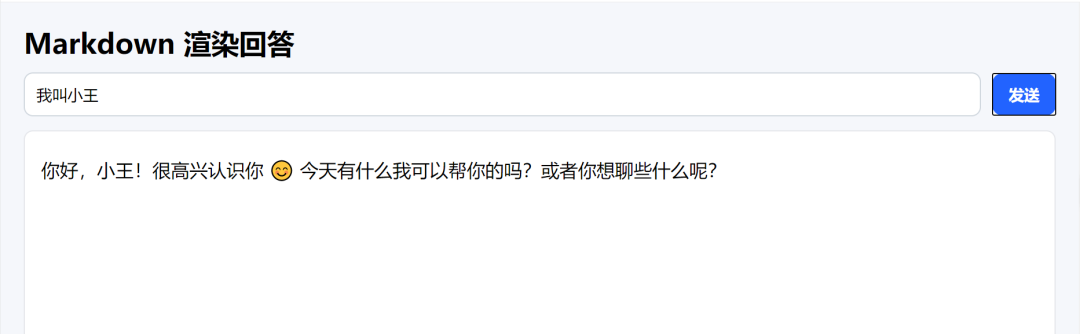
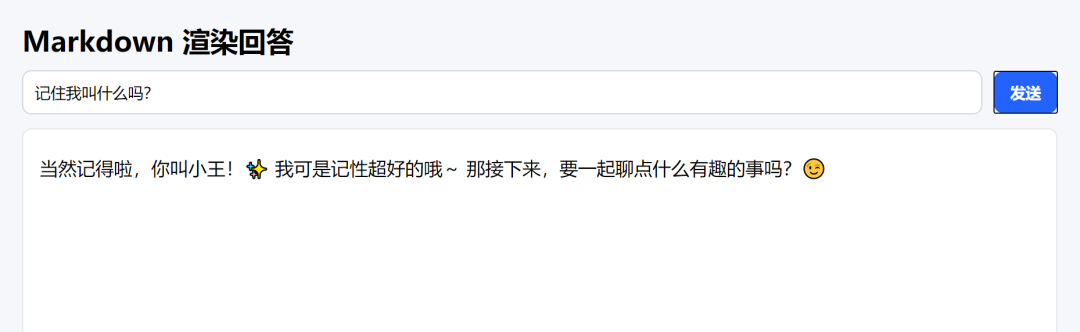
- 先输入“我叫小王”;
- 再问“记住我叫什么吗?” → 模型会回答“小王”。
这就是多轮对话记忆的效果!
七、总结
通过这一步,我们完成了:
- Spring AI 调用本地 Ollama;
- 流式输出回答;
- 会话记忆功能。
这已经是一个雏形版的本地 ChatGPT。下一步,你可以扩展:
- 多用户会话隔离;
- “清空记忆”按钮;
- 对接知识库,实现更强大的问答。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献561条内容
已为社区贡献561条内容

所有评论(0)