【AI实战日记-手搓情感聊天机器人】Day 10:更精准的投喂,防止AI被不确切的信息“迷惑”!使用 Cross-Encoder 实现文档重排序 (Re-ranking)
Day 9 我们通过 Multi-Query 极大提升了检索的广度,但也引入了无关文档的“噪音”。今天是 Day 10,我们将引入 Re-ranking (重排序) 技术,这是 RAG 系统从“可用”迈向“高精度”的关键分水岭。本文将深度解析 Bi-Encoder 与 Cross-Encoder 的区别,并使用 HuggingFace CrossEncoder 构建重排序器,清洗检索结果,确保大模
Day 9 我们通过 Multi-Query 极大提升了检索的广度,但也引入了无关文档的“噪音”。今天是 Day 10,我们将引入 Re-ranking (重排序) 技术,这是 RAG 系统从“可用”迈向“高精度”的关键分水岭。本文将深度解析 Bi-Encoder 与 Cross-Encoder 的区别,并使用 HuggingFace CrossEncoder 构建重排序器,清洗检索结果,确保大模型只看最精准的“干货”。
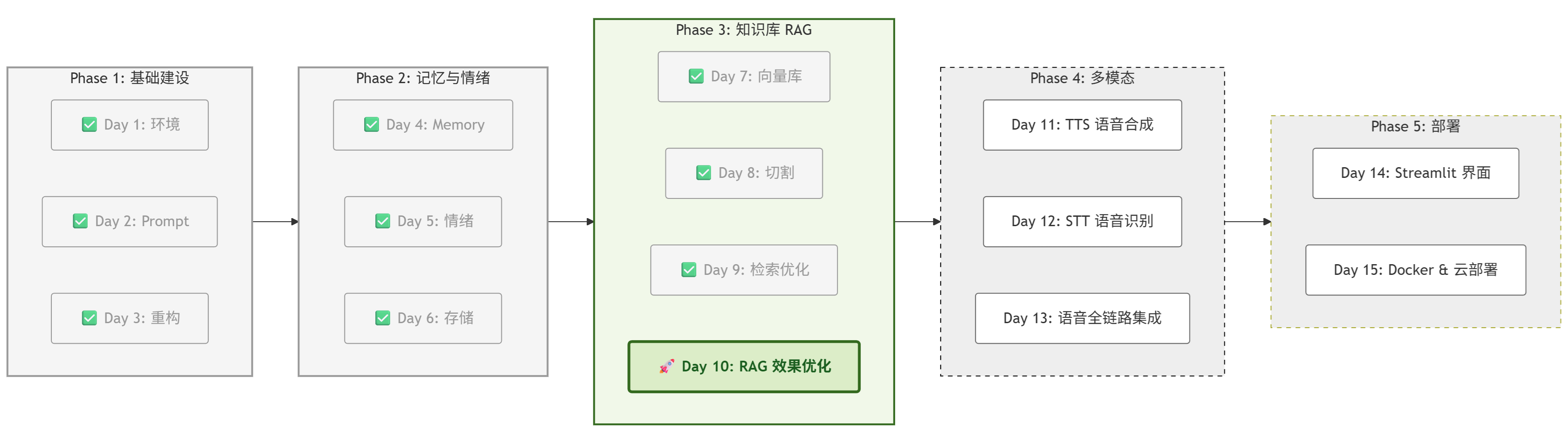
一、 项目进度:Day 10 启动
根据项目路线图,今天是 Phase 3 的最后一天。
完成这一步,我们的 RAG 知识库就是一个完全体了。
二、 核心原理:精细化筛选——Re-ranking (重排序) 技术
在 Day 9,我们要么搜不到,要么利用 Multi-Query 搜回了一大堆文档。这就好比撒网捕鱼,网是撒出去了,但捞上来的不仅有鱼,还有靴子、水草和石头。
如果把这些“噪音”一股脑塞给大模型,不仅浪费 Token,还会导致 “迷失中间” (Lost in the Middle) 现象——大模型因为干扰信息太多,反而找不到正确答案。
我们需要一个严苛的**“质检员”**。
1. 深度解析:Bi-Encoder vs Cross-Encoder
为什么向量库(Bi-Encoder)不够准,而重排序(Cross-Encoder)准但慢?
(1) Bi-Encoder (双塔模型) —— 向量库在用的
-
原理:它像两个独立的画师。一个画师画“问题”的像(向量),另一个画师画“文档”的像(向量)。最后比较两幅画像不像(计算余弦相似度)。
-
局限:因为画的时候是各画各的,“问题”和“文档”没有发生交互。
-
例子:用户问“我不喜欢吃苹果”,向量库可能会把“我喜欢吃苹果”排在很前面,因为它们共享了大部分词汇,向量很像,但含义完全相反。
-
(2) Cross-Encoder (交互模型) —— 重排序在用的
-
原理:它像一个阅卷老师。它把“问题”和“文档”拼接在一起 ([CLS] 问题 [SEP] 文档),作为一个整体输入给 BERT 模型进行深层注意力计算。
-
优势:模型能看到每一个字在另一个句子中的上下文。它能精准识别“不”、“但是”这种逻辑词。
-
例子:Cross-Encoder 会发现“不”字否定了喜欢,给“我喜欢吃苹果”打一个极低的分数。
-
-
代价:计算量大。如果你有 100 万条数据,不能用它全库扫描,只能用来处理粗排后的几十条数据。
2. 漏斗架构:从“海选”到“精选”
成熟的 RAG 系统通常采用 “两阶段检索” (Two-Stage Retrieval) 的漏斗架构:
-
第一阶段:粗排 (Retrieval / Recall)
-
工具:ChromaDB (向量搜索)。
-
目标:召回率 (Recall) 优先。宁可错杀一千,不可放过一个。从 100,000 条数据中快速捞出 Top 50 及其相似的文档。
-
特点:速度极快(毫秒级),但精度较低,只看大致语义。
-
-
第二阶段:精排 (Re-ranking / Precision)
-
工具:Cross-Encoder 模型 (如 BGE-Reranker)。
-
目标:准确率 (Precision) 优先。对这 50 条文档进行逐一精读打分,只保留得分最高的 Top 3。
-
特点:速度较慢,但精度极高,能理解复杂的逻辑关系。
-
这张流程图展示了引入 Re-ranking(重排序) 后,RAG 系统如何像漏斗一样,将海量文档层层过滤,最终只把精华留给大模型:
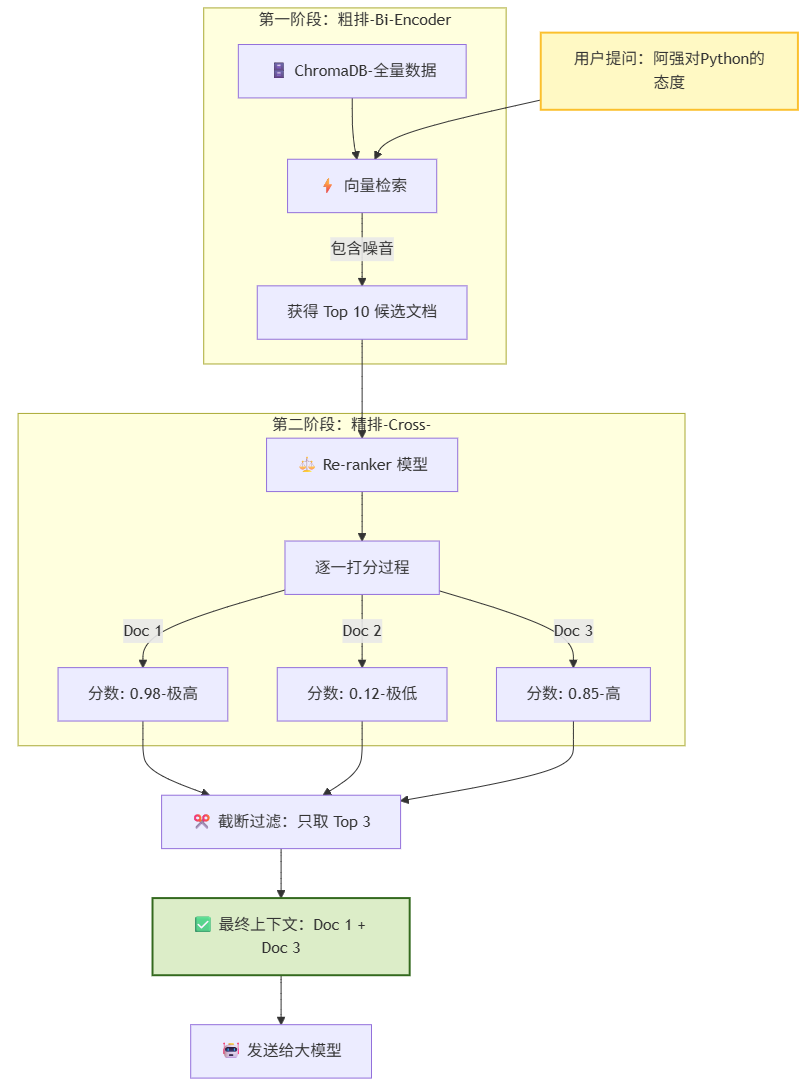
1. 顶部入口:用户提问
-
一切始于用户的提问:“阿强对Python的态度”。这是一个典型的语义查询,既包含了实体(阿强、Python),也包含了意图(态度)。
2. 第一阶段:粗排 (Stage 1 - Recall)
-
动作:ChromaDB 出马。它使用的是 Bi-Encoder 技术,追求速度。它迅速计算向量距离,从成千上万条数据中,粗略地捞出了 Top 10 条候选文档。
-
现状:这一步是“广撒网”。捞上来的结果中,既有真正的答案(阿强喜欢写代码),也混入了噪音(比如“阿强讨厌蟒蛇”——因为蟒蛇英文也是 Python,向量距离可能很近)。
3. 第二阶段:精排 (Stage 2 - Re-rank)
-
动作:Re-ranker (Cross-Encoder) 介入。它像一位严苛的阅卷老师,不再只看大概,而是把“用户问题”和“这 10 个文档”逐一拼接,进行深度阅读和逻辑判断。
-
打分:
-
Doc 1:“阿强最爱用 Python 写脚本” -> 语义高度匹配 -> 得分 0.98。
-
Doc 2:“阿强看到蟒蛇(Python)吓得腿软” -> 虽然有关键词,但语义无关 -> 得分 0.12。
-
Doc 3:“Python 是他吃饭的家伙” -> 语义相关 -> 得分 0.85。
-
4. 底部出口:截断与生成
-
过滤:系统根据分数进行排序,大笔一挥,切掉低分文档(Doc 2 被无情淘汰)。
-
最终输出:只将得分最高的 Top 3 文档(Doc 1 + Doc 3)打包发送给大模型。
-
结果:通义千问拿到的是纯净的、无歧义的上下文,从而给出了精准的回答,完全避免了被“讨厌蟒蛇”这条干扰信息带偏。
3 核心组件:HuggingFaceCrossEncoder
在理解了 Cross-Encoder 的理论优势后,我们需要一个具体的工具将其落地。在 Day 10 的代码中,我们使用了 LangChain 提供的 HuggingFaceCrossEncoder 类。
(1) 什么是 HuggingFaceCrossEncoder ?
简单来说,它是 LangChain 为 Hugging Face sentence-transformers 库 提供的一个 “连接器” (Wrapper)。
-
身份:它不是一个算法,而是一个模型加载器。
-
功能:它负责从 Hugging Face Hub 下载指定的重排序模型(如 BAAI/bge-reranker-base),并在本地运行推理。
-
输入输出:你给它一对文本 (用户问题, 候选文档),它吐出一个 0~1 之间的 相关性分数。
(2) 为什么要用它?
你可能会问:“为什么不直接让通义千问(LLM)帮我给文档打分?为什么非要下载一个额外的本地模型?”
这里涉及架构设计的三个关键考量:
-
术业有专攻 (Specialization)
-
LLM (通义千问) 是“生成式模型”,擅长写文章、续写句子。虽然也能打分,但那是“兼职”。
-
HuggingFaceCrossEncoder 加载的是 BERT 架构 的判别式模型。它生来就是为了做“分类”和“打分”的。在判断“这两句话是否相关”这个任务上,它比通用的 LLM 更敏锐、更专业。
-
-
成本与速度 (Cost & Latency)
-
用 LLM 打分:你需要把粗排搜到的 20 篇文档全部发给 API。这会消耗大量 Token(钱),而且网络传输+生成等待会让用户等很久。
-
用本地模型打分:bge-reranker-base 只有几百兆,在本地 CPU/GPU 上运行毫秒级就能出结果,而且 完全免费。
-
总结:HuggingFaceCrossEncoder 是 RAG 系统中 性价比最高 的组件。它用极低的本地算力成本,换取了检索精度的巨大提升。
三、 实战:代码实现
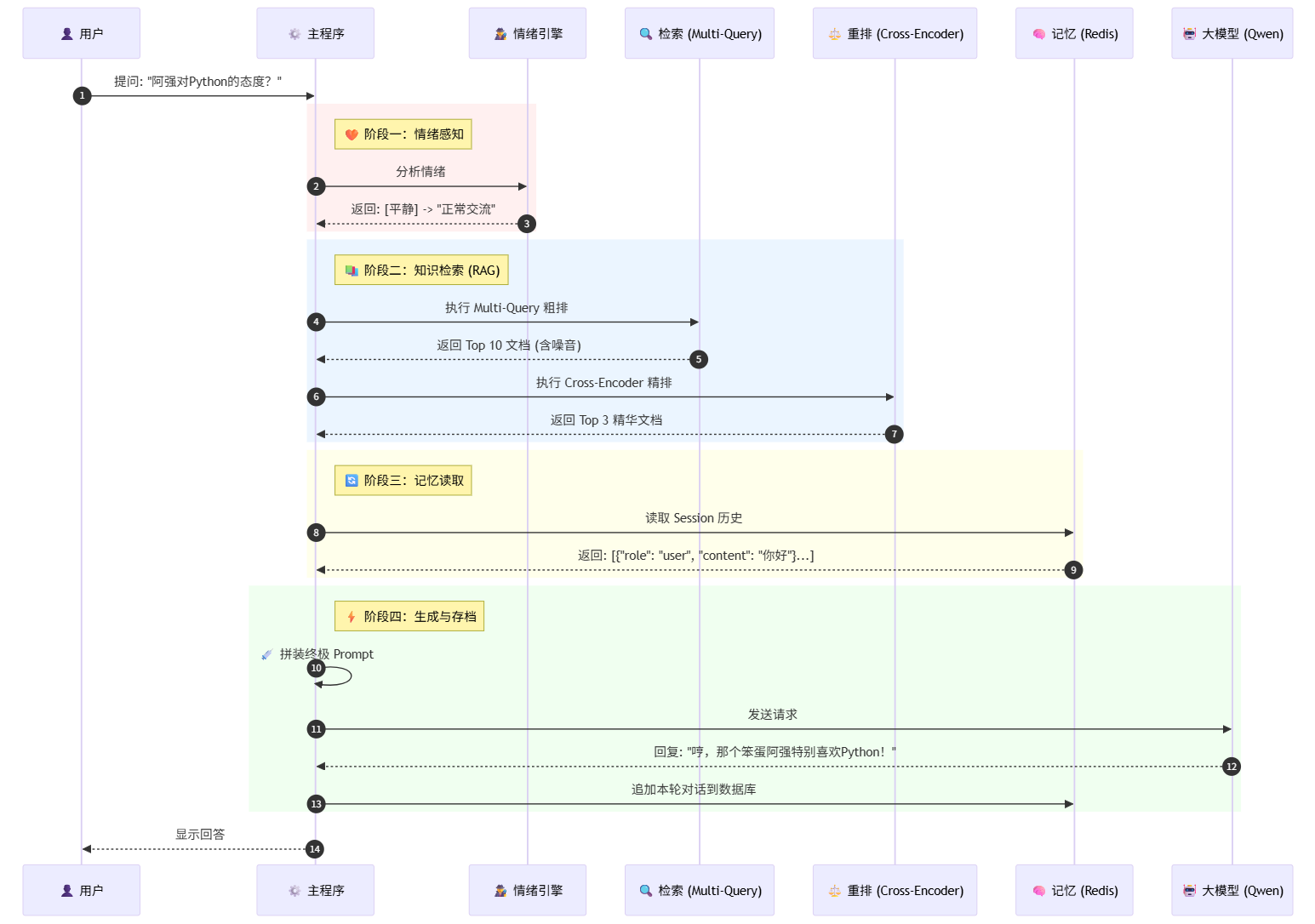
1. 全链路序列图
2. 安装依赖
我们需要安装 sentence-transformers 来运行 Cross-Encoder 模型。
pip install sentence-transformers langchain-community3. 编写重排序器 (src/core/reranker.py)
我们将封装一个 RerankEngine。为了演示方便且不消耗 API 费用,我们使用 BGE-Reranker(目前开源界最强的重排模型之一)。
新建文件:src/core/reranker.py
# src/core/reranker.py
"""
重排序引擎 - 使用 HuggingFace Cross-Encoder 对检索结果进行精排
使用 sentence-transformers 库直接实现,不依赖 LangChain 的不稳定 API
"""
from sentence_transformers import CrossEncoder
from typing import List
from langchain_core.documents import Document
from src.utils.logger import logger
class RerankEngine:
def __init__(self, model_name="BAAI/bge-reranker-base", top_n=3):
"""
初始化重排序引擎
Args:
model_name: Cross-Encoder 模型名称,默认使用 BAAI 的中文重排序模型
top_n: 返回前 N 个最相关的文档
"""
logger.info(f"⚡ 正在加载 Re-ranking 模型: {model_name}...")
try:
self.model = CrossEncoder(model_name, max_length=512)
self.top_n = top_n
logger.info(f"✅ Re-ranking 模型加载成功 (top_n={top_n})")
except Exception as e:
logger.error(f"❌ 模型加载失败: {e}")
raise
def rerank(self, query: str, documents: List[Document]) -> List[Document]:
"""
对文档列表进行重排序
Args:
query: 用户查询
documents: 待排序的文档列表
Returns:
按相关度排序后的前 top_n 个文档
"""
if not documents:
return []
# 准备输入对 (query, doc_content)
pairs = [[query, doc.page_content] for doc in documents]
# 计算相关度分数
scores = self.model.predict(pairs)
# 按分数排序,获取 top_n
sorted_indices = scores.argsort()[::-1][:self.top_n]
# 返回排序后的文档
reranked_docs = [documents[i] for i in sorted_indices]
logger.debug(f"🎯 重排序完成: {len(documents)} -> {len(reranked_docs)} 个文档")
return reranked_docs
def get_rerank_function(self):
"""
返回一个可调用的重排序函数,用于 LCEL 链
"""
def rerank_wrapper(inputs):
"""
包装器函数,用于在 LCEL 链中使用
预期输入: {'query': str, 'documents': List[Document]}
"""
query = inputs.get('query', '')
documents = inputs.get('documents', [])
return self.rerank(query, documents)
return rerank_wrapper4. 升级主程序 (main.py)
我们需要在 Day 9 的基础上,把 retriever 替换为经过 RerankEngine 包装后的增强版检索器。
修改文件:main.py
# ==============================================================================
# Project Echo Day 9: Multi-Query RAG Integration
# 集成特性: Redis记忆 + 情绪识别 + Multi-Query知识库检索
# ==============================================================================
# LangChain LCEL 核心组件
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from operator import itemgetter # 【修复】用于从字典中提取字段
# 项目核心模块
from src.core.llm import LLMClient
from src.core.prompts import PROMPTS
from src.utils.logger import logger
from src.config.settings import settings
from src.core.emotion import EmotionEngine # Day 5: 情绪
from src.core.knowledge import KnowledgeBase # Day 7-9: 知识库
from src.core.reranker import RerankEngine # Day 10: 重排序
# --- Redis 历史记录工厂 (Day 6) ---
def get_session_history(session_id: str) -> BaseChatMessageHistory:
return RedisChatMessageHistory(
session_id=session_id,
url=settings.REDIS_URL,
ttl=3600 * 24 * 7 # 记忆保留 7 天
)
# --- 辅助函数:格式化文档 ---
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
def main():
logger.info("🚀 --- Project Echo: Day 9 集成版启动 ---")
# ==========================================
# 1. 初始化组件
# ==========================================
# 1.1 大模型 (Brain)
client = LLMClient()
llm = client.get_client()
# 1.2 情绪引擎 (Heart)
emotion_engine = EmotionEngine()
# 1.3 知识库 (Book)
kb = KnowledgeBase()
# 【Day 9 核心】获取多重查询检索器
# 这里我们将 LLM 传进去,让检索器具备"思考"能力
base_retriever = kb.get_multiquery_retriever(llm)
# 【Day 10 新增】重排序引擎:对粗排结果进行精排
reranker = RerankEngine(model_name="BAAI/bge-reranker-base", top_n=3)
# 封装成 LCEL Runnable:先粗排,再精排
def retriever_with_rerank(query: str):
docs = base_retriever.invoke(query)
return reranker.rerank(query, docs)
retriever = RunnableLambda(retriever_with_rerank)
# ==========================================
# 2. 构建 Prompt 模板
# ==========================================
sys_prompt_base = PROMPTS["tsundere"]
prompt = ChatPromptTemplate.from_messages([
("system", sys_prompt_base), # 1. 基础人设 (傲娇)
("system", "{emotion_context}"), # 2. 情绪指令 (动态注入)
("system", "【参考资料(必须基于此回答)】:\n{context}"), # 3. 知识库资料 (RAG)
MessagesPlaceholder(variable_name="history"), # 4. 历史记忆 (Redis)
("human", "{input}") # 5. 用户输入
])
# ==========================================
# 3. 组装 LCEL 流水线
# ==========================================
rag_chain = (
{
# 分支 A: 智能检索 (用户输入 -> 裂变3个问题 -> 并行检索 -> 汇总 -> 格式化)
"context": itemgetter("input") | retriever | format_docs, # 【修复】使用 itemgetter 提取 input
# 分支 B: 透传参数 (直接传递给 Prompt)
"input": itemgetter("input"), # 【修复】提取 input 字段
"emotion_context": itemgetter("emotion_context"), # 【修复】提取 emotion_context 字段
"history": itemgetter("history") # 【修复】提取 history 字段
}
| prompt # 填入模板
| llm # 大模型推理
)
# ==========================================
# 4. 挂载持久化记忆
# ==========================================
final_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
print("\n✨ 系统就绪!试试问得模糊一点,比如“那个写代码的人爱吃啥?”\n")
session_id = "user_day9_demo"
# ==========================================
# 5. 对话循环
# ==========================================
while True:
user_input = input("You: ")
if user_input.lower() in ["quit", "exit"]:
break
if user_input.strip():
# --- Phase A: 情绪侦探 ---
current_emotion = emotion_engine.analyze(user_input)
emotion_instruction = "用户情绪平稳。"
if "[愤怒]" in current_emotion:
emotion_instruction = "⚠️ 警告:用户很生气!请示弱道歉。"
elif "[悲伤]" in current_emotion:
emotion_instruction = "⚠️ 提示:用户很难过。请温柔安慰。"
try:
# --- Phase B: 执行 RAG 主链 ---
# 这一步会自动触发 Multi-Query 检索
logger.info("🔍 正在进行多重检索与思考...")
response = final_chain.invoke(
{
"input": user_input,
"emotion_context": emotion_instruction
},
config={"configurable": {"session_id": session_id}}
)
print(f"Bot ({current_emotion}): {response.content}\n")
except Exception as e:
logger.error(f"❌ 调用失败: {e}")
if __name__ == "__main__":
main()四、 效果验证:去伪存真
为了验证 Re-rank 的效果,我们需要一个干扰项。
-
准备数据:在 resources 里加两句话:
-
A: "阿强最喜欢的编程语言是 Python。" (真答案)
-
B: "阿强非常讨厌蟒蛇 (Python),看到就跑。" (干扰项,字面包含 Python)
-
-
运行 ETL (ingest.py) 入库。
-
提问:“阿强对 Python 的看法?”
-
没有 Re-rank (Day 9):
-
可能同时返回 A 和 B。
-
AI 可能会困惑:“资料说他喜欢 Python,又说他讨厌蟒蛇...”
-
-
有 Re-rank (Day 10):
-
Cross-Encoder 会分析语义:
-
(问题, A) -> 分数 0.98 (非常相关)
-
(问题, B) -> 分数 0.12 (虽然有 Python 这个词,但语义是动物,不相关)
-
-
结果:B 被过滤掉,只会把 A 发给大模型。
-
AI 回答:非常坚定地说他喜欢 Python 语言。
-
五、 总结与预告
今天我们完成了 Phase 3 的最后一块拼图。
现在的“傲娇酱”,拥有了 Multi-Query (广度) 和 Re-rank (精度) 的双重加持,在聊天上变得更加的准确,接下来将给她装上更多的高端能力。
Phase 4 预告 (Day 11):
文字聊得再开心,终究是冷冰冰的屏幕。
明天我们将进入激动人心的 Phase 4:多模态交互。我们要给 AI 装上 TTS (语音合成) 模块,让傲娇酱不仅能打字,还能开口说话!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)