LLM - 从通用对话到自治智能体:Agent / Skills / MCP / RAG 三层架构实战
本文提出了一种三层智能体系统架构,使大模型从通用聊天工具升级为专业自治系统。架构包含:感知层(Agent负责任务拆解与RAG检索)、决策层(Skills封装领域知识与流程)、执行层(MCP标准化连接外部系统)。MCP作为统一接口协议,通过Tools/Resources/Prompts三种原语连接业务系统;Skills则将专家经验结构化,通过渐进式加载平衡性能与成本。该架构通过分层协作实现"
文章目录
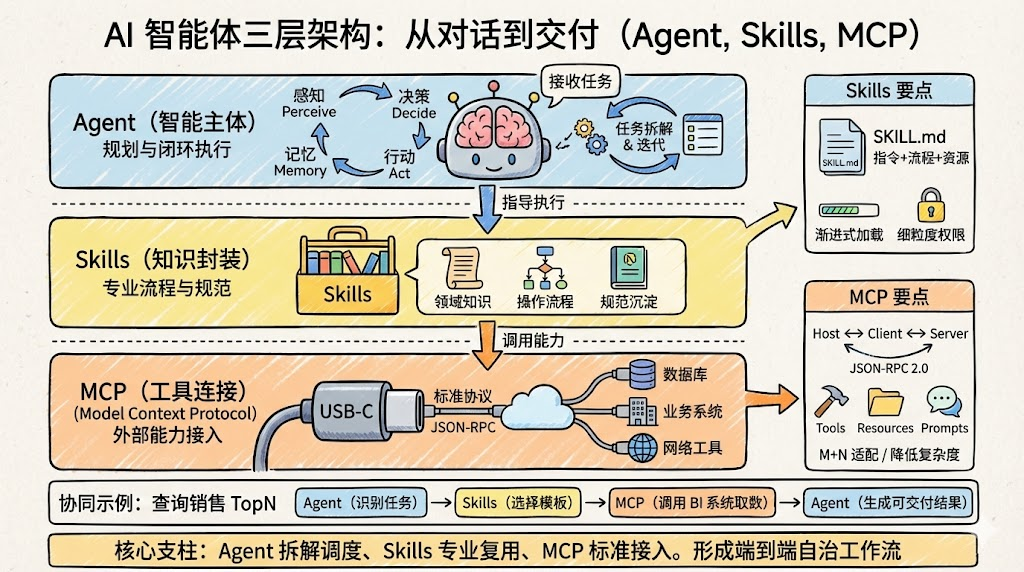
概述
在大模型从“能聊天”的通用工具,演进到“能负责结果”的专业自治系统的过程中,一个越来越清晰的共识是:光有一个强大的 LLM 远远不够,需要一整套围绕 Agent、Skills、MCP、RAG 构建的系统化架构。
这套架构既要能连接真实世界的系统与数据,又要能沉淀领域经验、可控地调度外部能力,并在长周期内稳定地产生“可交付结果”。
接下来我将从从架构与产品视角拆解一个三层智能体系统:感知 / 决策 / 执行三层之上,分别落位 Agent、Skills、MCP 与 RAG,并通过真实业务故事说明如何从“一个对话框”进化到“一个能胜任岗位的数字员工”。
从宏观视角看,一个可落地的智能体系统,至少要闭合三件事:看得懂输入、做得出决策、调用得动外部世界。
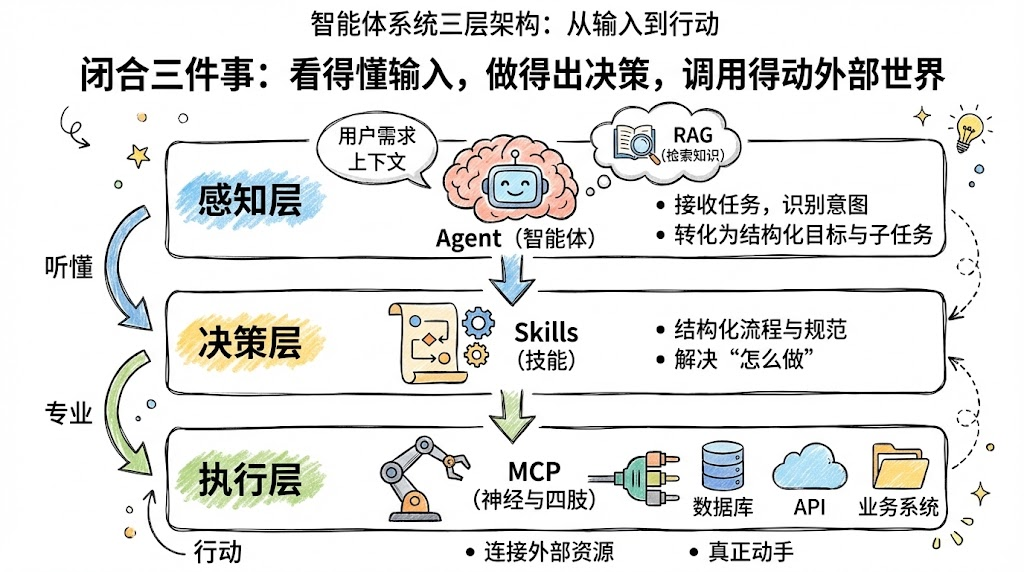
可以抽象为三层架构:
-
感知层:
- 以 Agent 为核心入口,接收自然语言任务,识别意图、理解上下文,并结合 RAG 检索长期知识。
- 负责“听懂用户的需求”,并将其转化为结构化目标与子任务。
-
决策层:
- 由 Skills 作为主要承载,把“怎么做这件事”以结构化的流程与规范固化下来。
- 解决“面对一个任务,正确且专业的做法是什么”。
-
执行层:
- 由 MCP 连接数据库、业务系统、API、文件等外部资源,是智能体的“神经与四肢”。
- 决定“能不能真正对业务系统动手,而不是只给建议”。
在这个视角中,Agent 是调度与大脑,Skills 是行业经验,MCP 是执行肌肉,RAG 则是一整套持续更新的长期记忆系统。
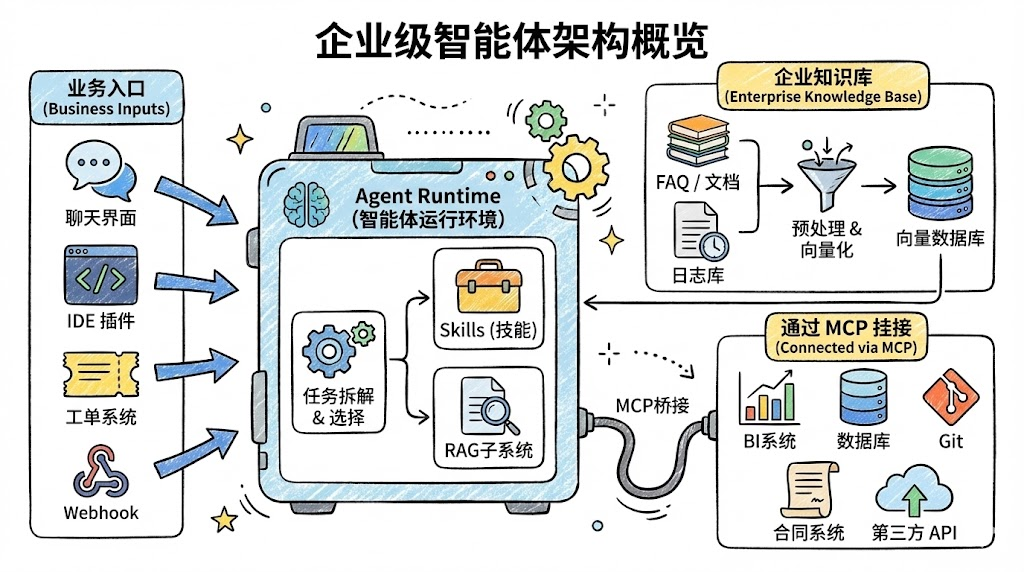
架构上可以想象这样一幅图:
- 左侧:各种业务入口(聊天界面、IDE 插件、工单系统、Webhook)。
- 中间:一个 Agent Runtime,内部挂载多个 Skills 以及 RAG 子系统,负责任务拆解与工具/技能选择。
- 右侧下方:通过 MCP 挂接的 BI 系统、数据库、Git、合同系统、第三方 API 等。
- 右侧上方:企业知识库、日志库、FAQ 文档等,被 RAG 预处理并接入向量数据库。
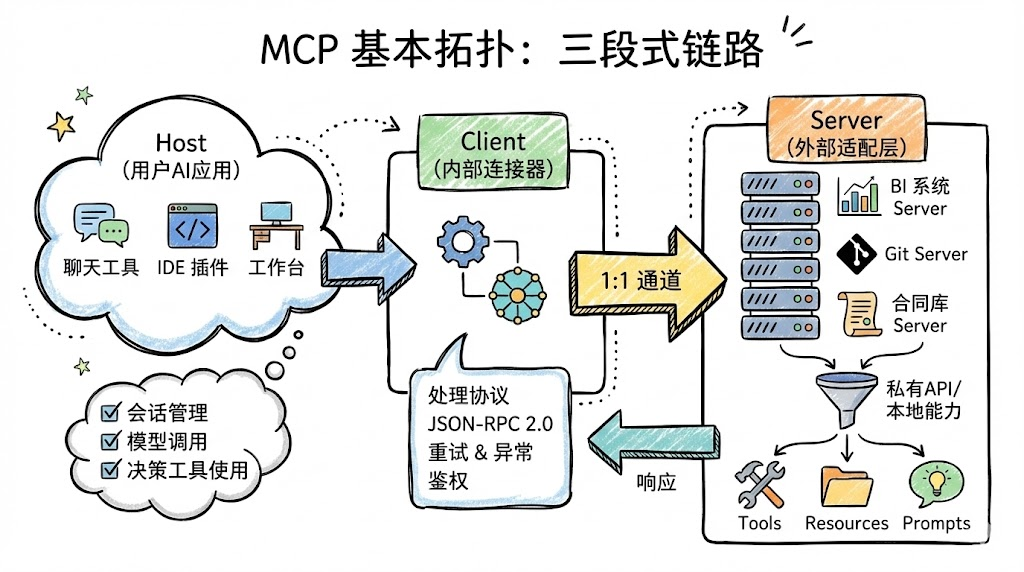
MCP:AI 的“USB-C 接口”,统一连接外部世界

如果把大模型视作 CPU,那么 MCP(Model Context Protocol)就像是 AI 世界里的“USB-C 标准接口”:解决的是“AI 如何稳定、标准化地接入各种外部能力”的问题。
协议架构:Host / Client / Server 三元模型
MCP 的基本拓扑可以理解为一个三段式链路:
-
Host
- 面向用户的 AI 应用本身,可能是聊天工具、IDE 插件、工作台等。
- 负责:会话管理、模型调用、决定要不要使用 MCP 工具。
-
Client
- Host 内部的连接器,负责与具体的 MCP Server 建立 1:1 通道。
- 处理协议细节:JSON-RPC 2.0 消息、重试、异常处理、鉴权等。
-
Server
- 每个外部系统或工具的适配层,比如“BI 系统 Server”、“Git Server”、“合同库 Server”。
- 把私有 API 或本地能力抽象成 MCP 标准原语:Tools / Resources / Prompts。
这意味着,在产品与架构视角下可以获得两点关键收益:
- 对 Host 开发者:不关心具体外部系统的 API 差异,只需做一次 MCP 接入能力。
- 对工具/系统方:只要实现一个 MCP Server,就能被所有支持 MCP 的 Host 调用。
标准原语:Tools、Resources、Prompts
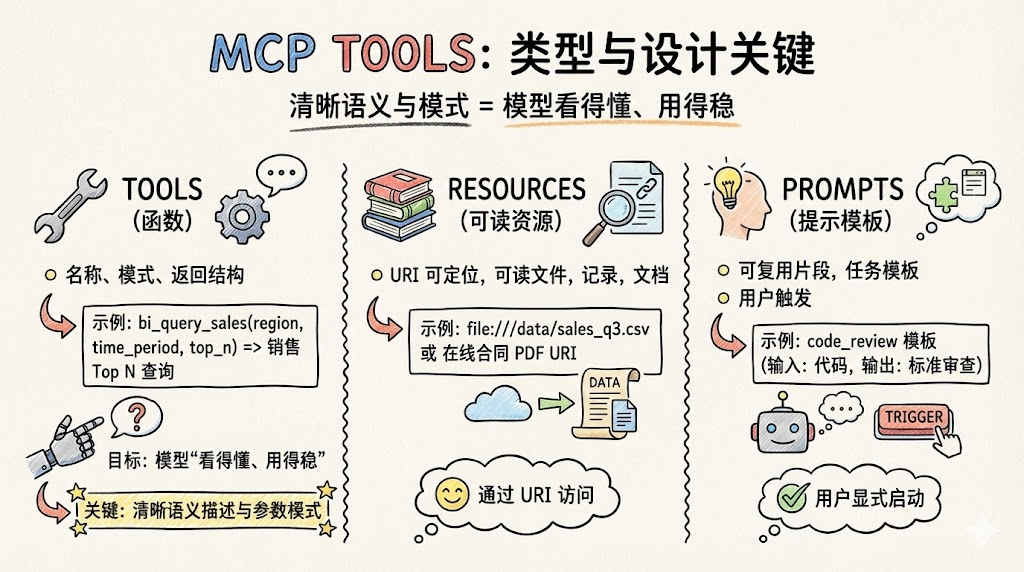
MCP 把“外部能力”抽象成三种统一原语,帮助大模型更稳定地使用这些能力。
-
Tools(可执行工具)
- 形态:有名称、参数 schema、返回结构的“函数”。
- 例子:
bi_query_sales(region, time_period, top_n)查询某区域指定时间段的销售 Top N。
-
Resources(可读资源)
- 形态:通过 URI 定位,可被读取的文件、数据记录、报表、文档等。
- 例子:
file:///data/sales_q3.csv、某份在线合同 PDF 的资源地址。
-
Prompts(提示模板)
- 形态:可复用的“提示词片段”或任务模板,由用户显式触发(如“代码审查模式”)。
- 例子:
code_review模板,要求输入代码片段,输出统一格式的审查意见。
在这一层,产品设计的关键是:给每一个 MCP Tool 设计清晰的语义描述与参数 schema,让模型“看得懂、用得稳”。
通信方式:适配不同部署形态
为适配不同形态的工具与部署环境,MCP 支持多种传输方案: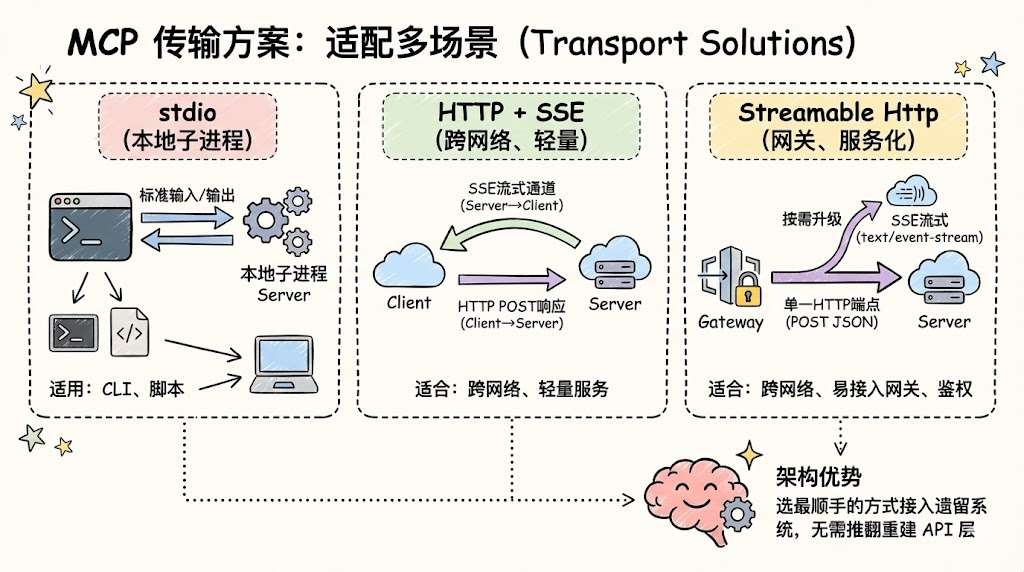
-
stdio:
- 通过标准输入输出与本地子进程 Server 通信,适合本地 CLI 工具、脚本。
-
HTTP + SSE:
- 通过 SSE 维持流式通道,用 HTTP POST 做响应,适合跨网络、轻量服务。
-
Streamable Http:
- 通过单一 HTTP 端点承载 MCP 通信,默认用 POST 返回 JSON,需要流式/多消息时按需升级为 SSE(text/event-stream),适合跨网络、易接入网关与鉴权的服务化部署
从架构角度看,这意味着你可以按系统特点“选最顺手的方式”把遗留系统接进智能体网络,而不用推翻重建已有 API 层。
Skills:把“资深同事的经验”变成可复用能力包
单靠一段长 Prompt,已经难以支撑复杂业务流程。Skills 的核心思想,是把经验、规范和脚本组织成一个结构化的“能力包”,让 Agent 能够可控地调用。
目录结构:一个 Skill 长什么样
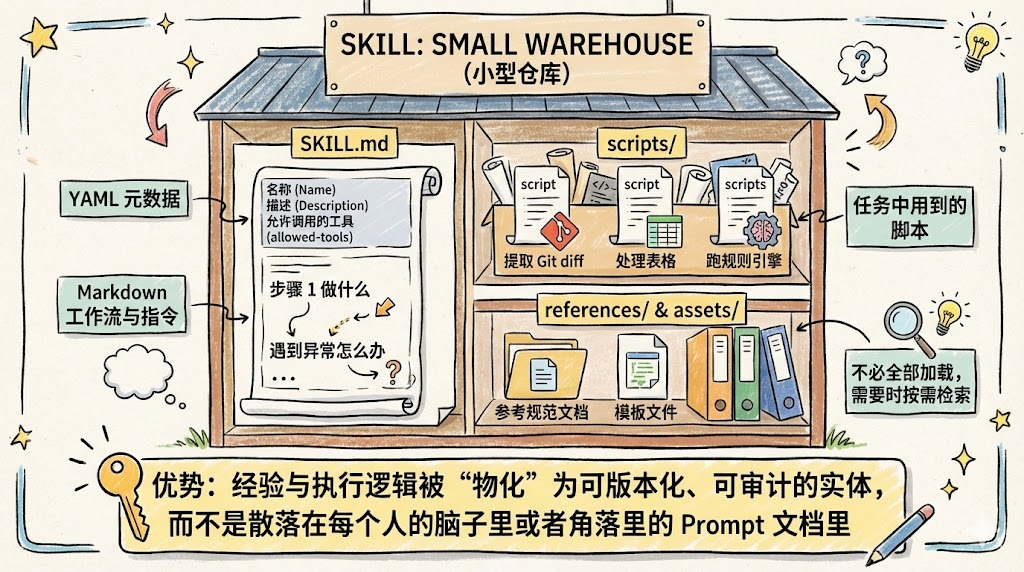
git-commit-helper/ # 技能文件夹(名称与skill name一致)
├── SKILL.md # 核心入口(必需)
│ ├── YAML元数据 # name/description/allowed-tools(<100 tokens)
│ │ name: git-commit-helper
│ │ description: 生成符合团队规范的Git提交信息
│ │ allowed-tools: Bash
│ └── Markdown指令 # 工作流/规范/异常处理(<5k tokens)
│ 1. 运行git diff --staged获取变更
│ 2. 首行≤50字(现在时),第二行空行
│ 3. 关联Jira编号(如PROJ-123)
├── scripts/ # 可执行脚本(可选,Python/shell)
│ └── extract-staged.py # 提取暂存区变更的脚本
├── references/ # 参考文档(可选,按需加载)
│ └── commit-spec.md # 团队提交规范细则
└── assets/ # 静态资源(可选,不加载到上下文)
└── commit-template.txt # 提交信息模板
典型 Skill 可以想象为一个小型仓库,至少包含三类内容:
-
SKILL.md:
- 顶部是 YAML 元数据:名称、描述、允许调用的工具(
allowed-tools)。 - 下方是 Markdown 格式的工作流与指令,如“步骤 1 做什么、遇到异常怎么办”。
- 顶部是 YAML 元数据:名称、描述、允许调用的工具(
-
scripts/:
- 任务中用到的脚本,如提取 Git diff、处理表格、跑规则引擎。
-
references/ 与 assets/:
- 参考规范文档、模板文件等,不必全部加载到上下文,需要时再按需检索。
这种结构的优势在于:经验与执行逻辑被“物化”为一个可版本化、可审计的实体,而不是散落在每个人的脑子里或者角落里的 Prompt 文档里。
渐进式加载:不把模型“喂撑”
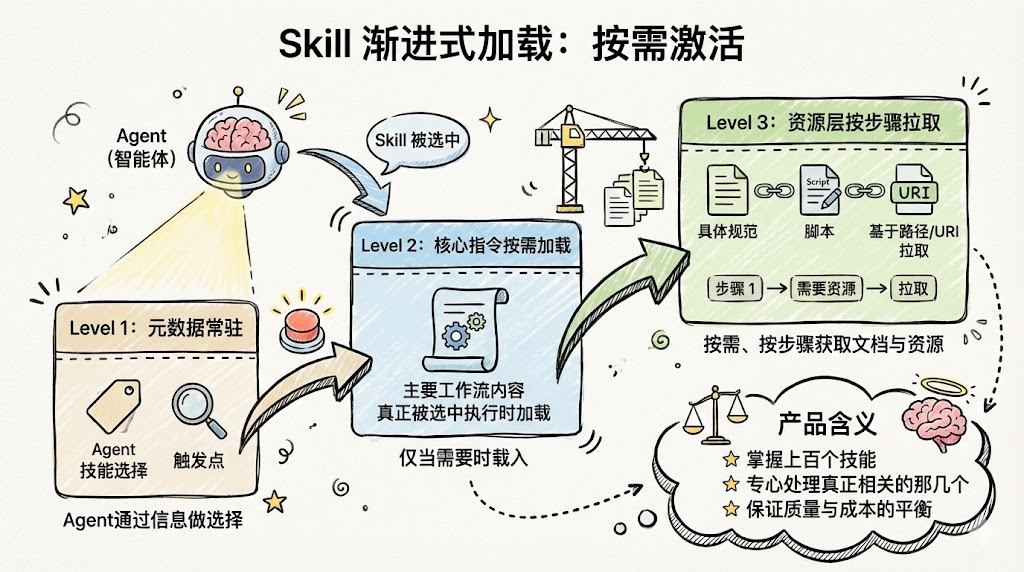
Skill 在运行时并不会一次性把所有内容塞给模型,而是采用“渐进式加载”:
-
Level 1:元数据常驻
- Agent 通过这些信息做技能选择与触发。
-
Level 2:核心指令按需加载
- 当某个 Skill 真正被选中执行时,才把其主要工作流内容送入上下文。
-
Level 3:资源层按步骤拉取
- 某一步需要具体规范或脚本时,再基于路径或 URI 拉取对应文档或资源。
产品含义是:你可以让一个 Agent 掌握上百个技能,但在某次具体任务中,只让它“专心处理真正相关的那几个”,保证质量与成本的平衡。
安全与边界:allowed-tools 的意义
对于企业与高风险场景,一个重要问题是:智能体到底能做什么,不能做什么?
Skills 的 allowed-tools 正是“能力边界”的声明,例如:
-
某个审计 Skill:
allowed-tools: Read, Grep→ 只能读文件与检索,不能写文件、更不能访问网络。
-
某个分析 Skill:
allowed-tools: Python, SQLite→ 可以跑计算与查本地库,但不能调用任意 HTTP。
这给产品与安全团队提供了一个“可控旋钮”,既能释放智能体能力,又能防止越权执行高危操作。
RAG:从“知识截止”到“持续进化的长期记忆”
大模型天然存在知识截止、缺少领域细节的限制,RAG(检索增强生成)是智能体补上“事实依据”与“长期记忆”的关键技术。
技术链路:三步构建“知识管道”
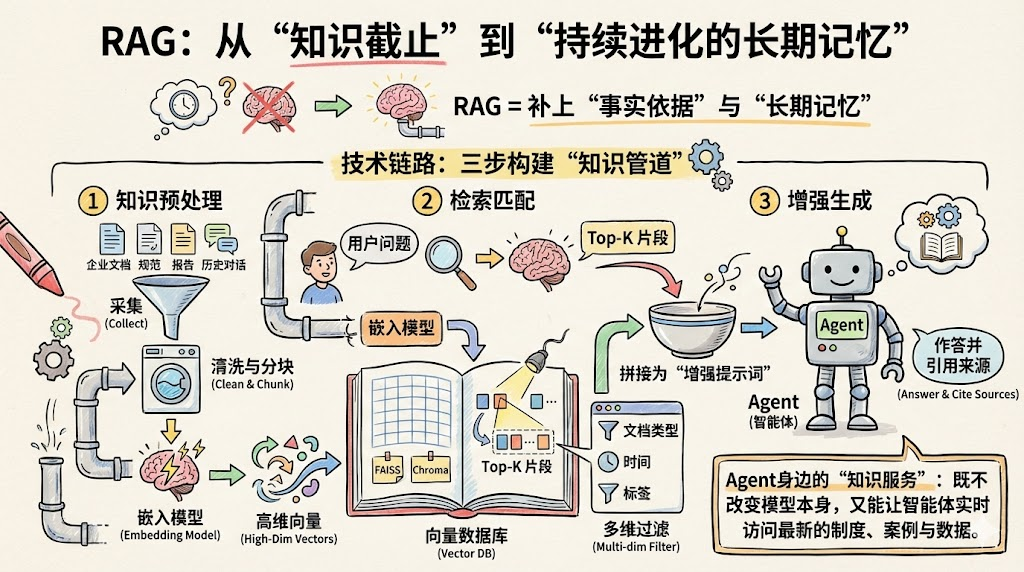
一个典型的 RAG 流程可以拆成三段:
-
知识预处理
- 采集企业文档、规范、报告、历史对话等,做清洗与分块。
- 用嵌入模型把文本转成高维向量,构建索引后写入向量数据库(如 FAISS、Chroma 等)。
-
检索匹配
- 用户提出问题,智能体将其转为向量,在库中按相似度检索出 Top-K 片段。
- 可以按文档类型、时间、标签等做多维过滤,控制召回质量。
-
增强生成
- Agent 将用户问题与命中的片段拼接为“增强提示词”,显式要求模型“基于这些内容作答并引用来源”。
在架构图中,RAG 像是 Agent 身边的“知识服务”:既不改变模型本身,又能让智能体实时访问最新的制度、案例与数据。
对产品的价值:可信、可追溯、易维护
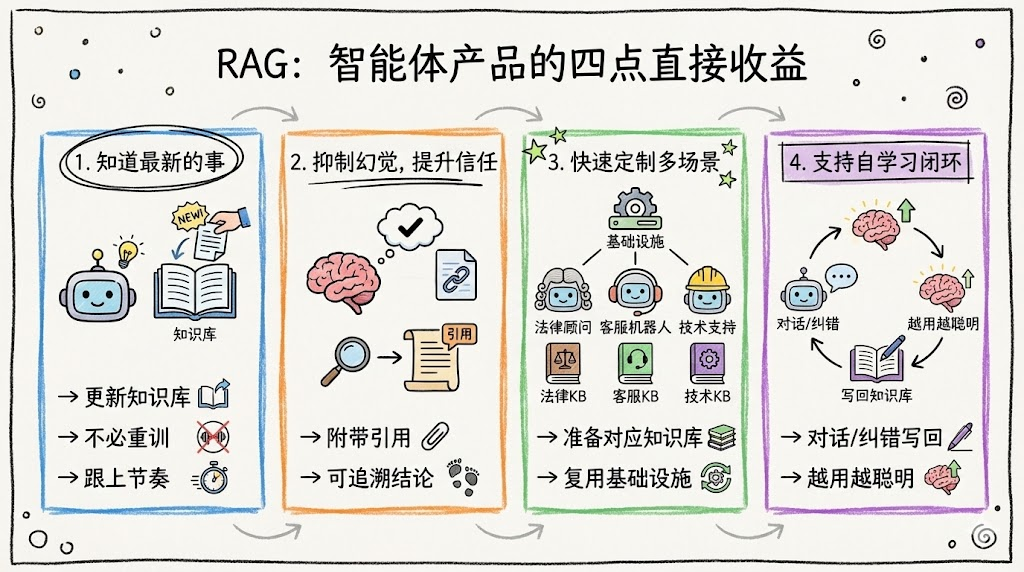
RAG 给智能体产品带来至少四点直接收益:
-
让智能体“知道最新的事”:
- 不必每次变更都重训模型,只需更新知识库,就能让智能体跟上政策 / 产品的更新节奏。
-
抑制幻觉,提升信任:
- 回答可以附带引用的条款、文档链接,用户能追溯“你依据什么给出这个结论”。
-
快速定制多场景智能体:
- 法律顾问、客服机器人、技术支持等,只需准备对应知识库,复用同一套 Agent / MCP / Skills 基础设施。
-
支持自学习闭环:
- 智能体在长期使用中还能持续把高价值对话、纠错案例写回知识库,让整体“越用越聪明”。
Agent:决策引擎与运行时,串起三层闭环
如果说 MCP 是“外设接口”、Skills 是“应用程序”、RAG 是“数据库”,那么 Agent 就是把这一切串起来的“操作系统级运行时与调度器”。
决策流程:以“销售 Top3 查询”为例
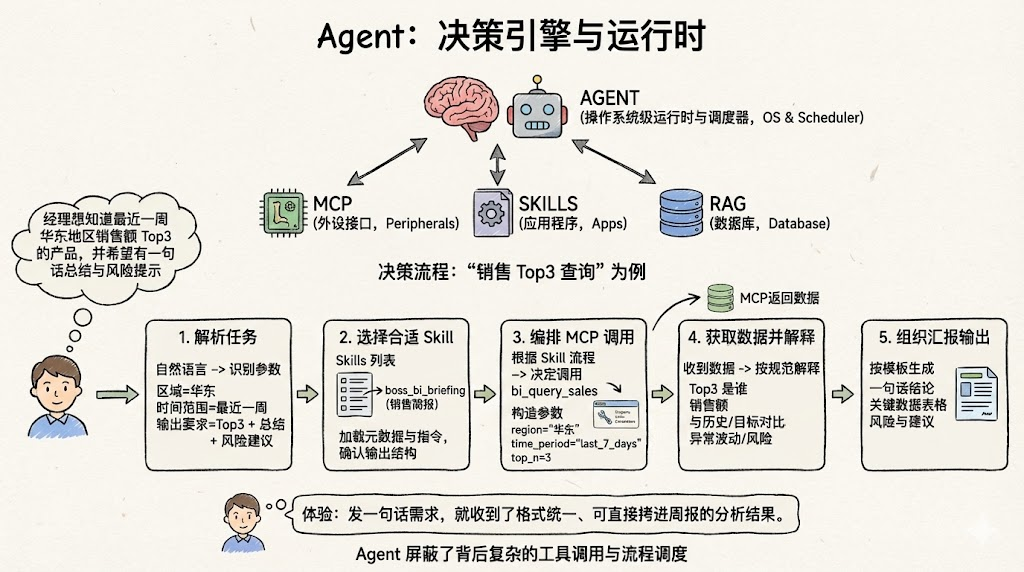
“经理想知道最近一周华东地区销售额 Top3 的产品,并希望有一句话总结与风险提示”。
一个成熟 Agent 的工作流大致如下:
-
解析任务
- 从自然语言中识别出:区域=华东,时间范围=最近一周,输出要求=Top3 + 总结 + 风险建议。
-
选择合适 Skill
- 在 Skills 列表中,找到适配场景的
boss_bi_briefing或类似“销售简报” Skill。 - 加载 Skill 元数据与指令,确认输出结构(如“一句话结论 + 关键指标 + 风险项列表”)。
- 在 Skills 列表中,找到适配场景的
-
编排 MCP 调用
- 根据 Skill 中的流程说明,决定调用哪个 MCP Tool,如
bi_query_sales。 - 构造参数:region=“华东”、time_period=“last_7_days”、top_n=3。
- 根据 Skill 中的流程说明,决定调用哪个 MCP Tool,如
-
获取数据并解释
- 收到 MCP 返回的数据后,根据 Skill 的规范解释数据:
- 谁是 Top3,各自销售额是多少;
- 与历史同期/目标对比如何;
- 有哪些异常波动或库存风险。
- 收到 MCP 返回的数据后,根据 Skill 的规范解释数据:
-
组织汇报输出
- 按 Skill 定义的模板生成最终报告:
- 一句话结论:当前华东销售整体态势如何;
- 关键数据表格;
- 可能的风险与建议动作。
- 按 Skill 定义的模板生成最终报告:
对业务方而言,体验是:“发一句话需求,就收到了格式统一、可直接拷进周报的分析结果”,背后复杂的工具调用与流程调度被完全屏蔽。
运行时能力:上下文与执行环境
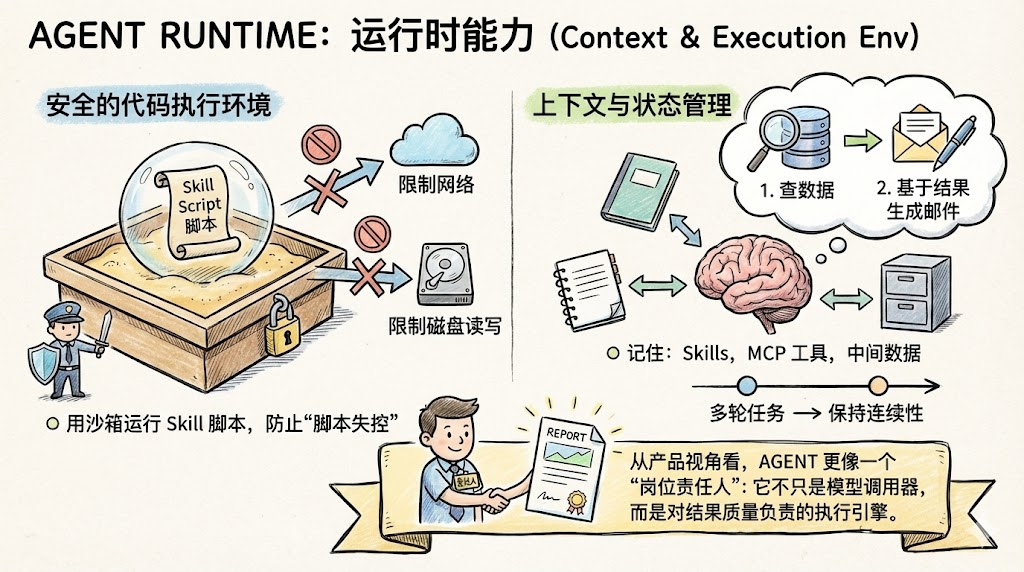
为了支撑上述能力,一个 Agent Runtime 通常至少要具备两项基础设施:
-
安全的代码执行环境
- 用沙箱运行 Skill 附带的脚本,限制网络权限、磁盘读写范围等,防止“脚本失控”。
-
上下文与状态管理
- 记住当前任务涉及了哪些 Skills、调用过哪些 MCP 工具、拿到了哪些中间数据。
- 对多轮任务保持连续性,例如先“查数据”,再“基于刚才的结果生成邮件草稿”。
从产品视角看,Agent 更像一个“岗位责任人”:它不只是模型调用器,而是对结果质量负责的执行引擎。
三者协同:三个典型业务故事
下面用三个具体场景,串起来看 Agent / Skills / MCP / RAG 如何协同工作。
场景一:销售 BI 简报
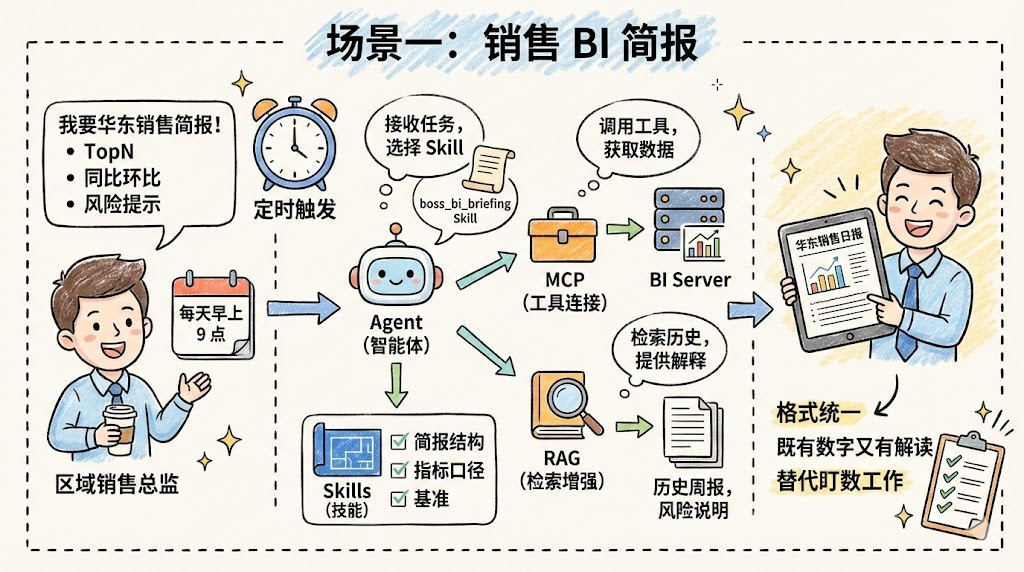
- 角色:区域销售总监、经营分析团队。
- 诉求:每天早上 9 点自动收到一份“华东销售简报”,包含 TopN 产品、同比环比、风险提示。
协同方式:
-
Agent:
- 接收定时触发任务或自然语言提问,选择
boss_bi_briefingSkill。
- 接收定时触发任务或自然语言提问,选择
-
Skills:
- 定义简报内容结构、指标口径、基准(如同比对比上月同日)。
-
MCP:
- 通过 BI Server 工具调用,获取原始销售数据与看板截图等。
-
RAG:
- 检索历史周报与风险说明,让智能体知道类似波动在过去是如何被解释的。
最终:经理收到一份格式统一的日报,既有数字又有解读,大量“要人盯数”的工作被自动化替代。
场景二:代码审查助手
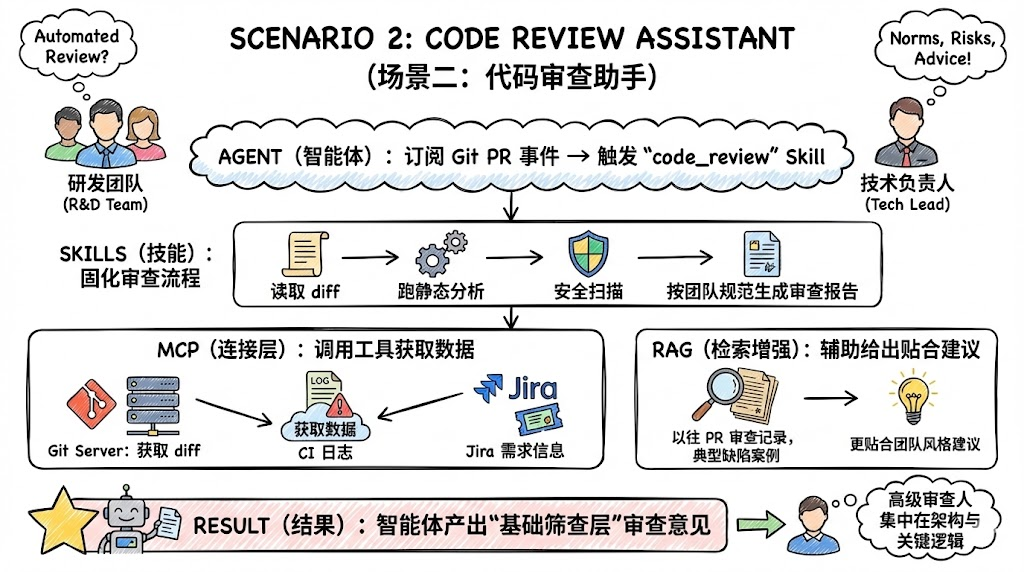
- 角色:研发团队、技术负责人。
- 诉求:对每个合并请求进行自动化的基础审查,给出规范、风险与建议。
协同方式:
-
Agent:
- 订阅 Git 仓库的 PR 事件,触发
code_review类 Skill。
- 订阅 Git 仓库的 PR 事件,触发
-
Skills:
- 固化“读取 diff → 跑静态分析 → 安全扫描 → 按团队规范生成审查报告”的流程。
-
MCP:
- 调 Git Server 获取 diff、调用 CI 日志、关联 Jira 需求信息。
-
RAG:
- 检索以往 PR 审查记录、典型缺陷案例,帮助给出更贴合团队历史风格的建议。
结果:智能体产出的审查意见可以成为“基础筛查层”,让高级审查人把时间集中在架构与关键逻辑上。
场景三:合规文档审核
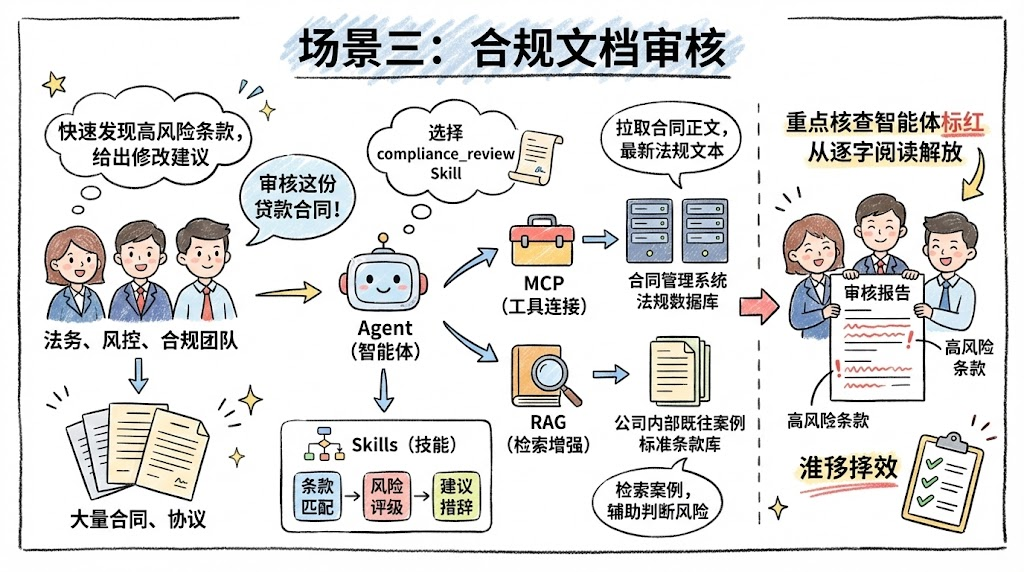
- 角色:法务、风控、合规团队。
- 诉求:在大量合同、协议中快速发现高风险条款并给出修改建议。
协同方式:
-
Agent:
- 接收“审核这份贷款合同”的指令,选择
compliance_reviewSkill。
- 接收“审核这份贷款合同”的指令,选择
-
Skills:
- 把“条款匹配 → 风险评级 → 建议措辞”的流程封装成结构化步骤。
-
MCP:
- 连接合同管理系统、法规数据库接口,拉取合同正文与最新法规文本。
-
RAG:
- 检索公司内部既往案例、标准条款库,辅助判断当前合同的风险等级。
最终:合规人员从“逐字阅读所有合同”变成“重点核查智能体标红的高风险条款”。
结语:从技术组合到产品能力
回到开头的问题:如何让一个大模型真正变成“能承担岗位职责的数字员工”?
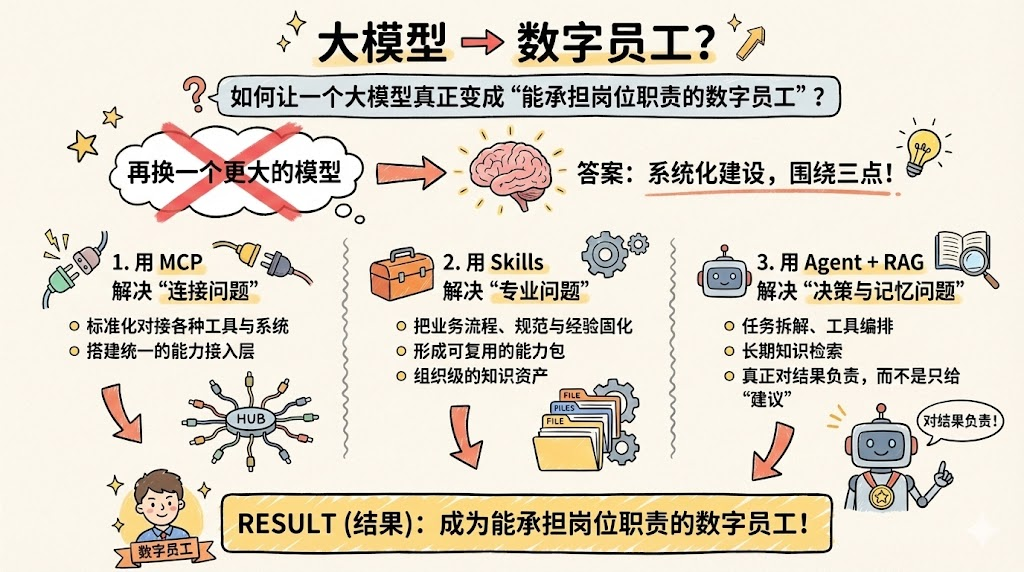
这个问题的答案,并不是“再换一个更大的模型”,而是围绕以下三点进行系统化建设:
-
用 MCP 解决“连接问题”:
- 标准化对接各种工具与系统,搭建统一的能力接入层。
-
用 Skills 解决“专业问题”:
- 把业务流程、规范与经验固化为可复用的能力包,形成组织级的知识资产。
-
用 Agent + RAG 解决“决策与记忆问题”:
- 通过任务拆解、工具编排与长期知识检索,让智能体真正对结果负责,而不是只给“建议”。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 47
47 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)