【珍藏必备】云原生大模型推理实战:从单机到多机多卡的企业级部署
2025年云原生与大模型推理的融合趋势:本文探讨了VLLM分布式推理引擎与Kubernetes云原生架构的深度结合,为企业提供高性能LLM推理解决方案。文章系统分析了单机单卡、单机多卡和多机多卡三种部署方案的技术原理、配置方法及适用场景,重点阐述VLLM的PagedAttention机制和分布式并行策略(张量并行与流水线并行),以及Kubernetes的核心组件如何支撑企业级需求。通过云原生技术实
本文详细介绍了2025年云原生与大模型推理的融合趋势,重点解析VLLM分布式推理引擎与Kubernetes云原生架构的结合应用。文章从企业级需求出发,系统阐述了单机单卡、单机多卡、多机多卡三种部署方案的实现原理、配置步骤、参数调优及适用场景,为企业落地高性能、高可靠的LLM推理服务提供全链路解决方案。
第一章 引言:云原生与大模型推理的融合趋势(2025视角)
1.1 大模型推理服务的企业级核心诉求
2025年,大语言模型(LLM)已从技术探索阶段全面走向企业级规模化应用,覆盖智能客服、代码生成、数据分析、自动驾驶决策等关键业务场景。
企业在部署LLM推理服务时,核心诉求已从早期的“能用”升级为“稳定、高效、可扩展、低成本、合规安全”的多维目标:
- 高性能:要求低推理延迟(SLA承诺通常低于100ms)、高吞吐量(支持万级并发请求),以应对业务高峰期的流量冲击;
- 高可用性:服务可用性需达到99.99%以上,具备故障自动转移、容灾备份能力,避免单点故障导致业务中断;
- 弹性扩展:能够根据业务流量动态调整资源配置,在流量低谷时释放资源降低成本,高峰时快速扩容保障服务质量;
- 资源高效利用:GPU作为核心昂贵资源,需通过精细化调度、共享部署等方式提升利用率,降低单位推理成本;
- 合规与安全:满足数据隐私保护法规(如GDPR、中国个人信息保护法),实现模型访问权限管控、推理数据加密传输与存储;
- 可观测性:具备全链路监控、日志追踪、告警预警能力,快速定位推理服务中的性能瓶颈与故障点。

在这样的诉求下,传统的单机部署模式已无法满足企业级需求,而基于Kubernetes的云原生架构凭借其容器化、编排调度、自动扩缩容、服务网格等核心能力,成为LLM推理服务的理想部署载体。
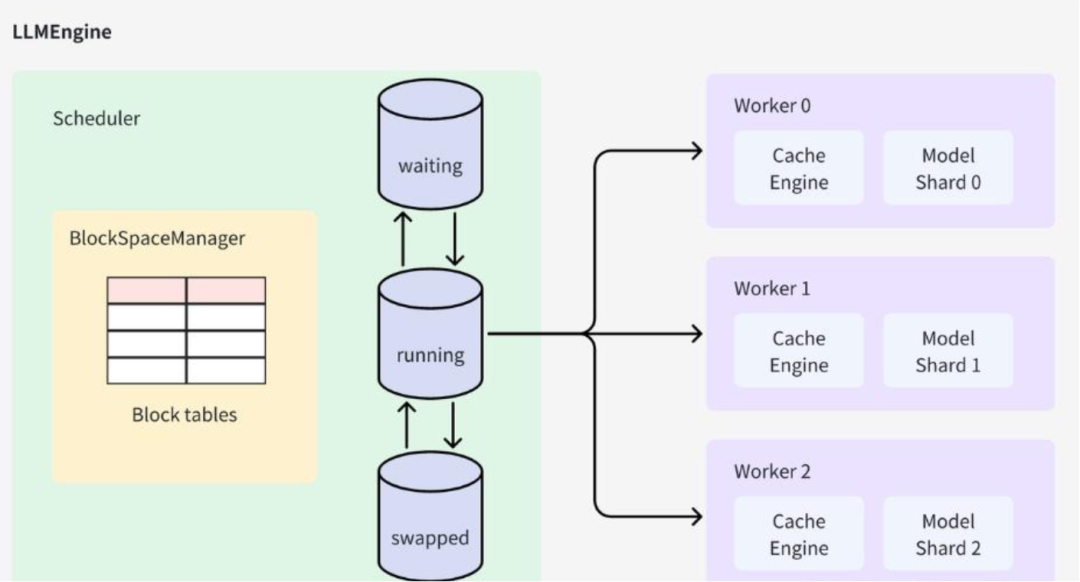
1.2 VLLM:企业级LLM推理的优选引擎
VLLM作为基于PagedAttention机制的高性能LLM推理引擎,自发布以来凭借其卓越的性能优势(吞吐量较传统TensorFlow Serving、PyTorch Serve提升10-100倍)、丰富的分布式部署能力(支持张量并行、流水线并行)、广泛的模型兼容性(支持Llama 3、Qwen、GPT-4等主流模型),已成为2025年企业级LLM推理服务的首选引擎。其核心优势包括:
-
PagedAttention机制:借鉴操作系统分页管理思想,将模型的KV缓存划分为固定大小的块(Block),实现KV缓存的高效复用与动态分配,大幅提升内存利用率与吞吐量;
-
完善的分布式支持:原生支持单节点多GPU张量并行、多节点多GPU张量并行+流水线并行,适配不同规模的模型部署需求;
-
灵活的运行时管理:支持Python原生多进程(mp)、Ray等分布式运行时,可根据部署环境灵活选择,降低运维复杂度;
-
标准化协议兼容:原生兼容OpenAI API协议,可无缝对接现有基于OpenAI生态的应用系统,降低迁移成本;
-
云原生友好:支持容器化部署,可与Kubernetes、Helm、KServe等云原生工具深度集成,适配企业级云原生架构。
VLLM推理过程
1.3 本文核心内容与价值
本文立足2025年企业级生产环境需求,以Kubernetes云原生集群为部署载体,围绕VLLM分布式推理服务展开全面剖析,核心内容包括:
- VLLM分布式推理核心原理与Kubernetes云原生部署基础;
- 单机单卡、单机多卡、多机多卡三种部署方案的详细实现(含架构设计、部署步骤、参数调优)与适用场景;
- 国内外一线互联网公司(Meta、Google、字节跳动、阿里巴巴等)GPU部署策略对比分析;
- 企业级生产环境保障机制(高可用、可观测性、安全合规、成本优化);
- 2025年最新实践案例与技术趋势展望。
本文旨在为企业级用户提供一套“理论+实践+优化”的全链路VLLM分布式推理服务部署解决方案,助力企业快速落地高性能、高可靠的LLM推理服务,支撑业务数字化转型。
第二章 核心技术基础:VLLM分布式推理与Kubernetes云原生架构
2.1 VLLM分布式推理核心原理
VLLM的分布式推理能力是支撑大模型(如100B+参数模型)部署的关键,其核心依赖两种并行策略:张量并行(Tensor Parallelism)与流水线并行(Pipeline Parallelism),两种策略可单独使用或组合使用,以适配不同规模的模型与硬件资源。
2.1.1 张量并行(Tensor Parallelism)
张量并行的核心思想是将模型的张量(权重、偏置等)在多个GPU之间进行拆分,每个GPU仅持有部分张量,推理时通过GPU间的通信协同完成计算。该策略适用于模型单卡无法容纳,但单节点多GPU可容纳的场景(如13B模型无法单卡部署,但4卡GPU可部署)。
VLLM采用Megatron-LM的张量并行实现方案,主要针对Transformer架构的关键层(如注意力层、FeedForward层)进行拆分:
- 注意力层:将查询(Q)、键(K)、值(V)的线性投影层权重按列拆分,每个GPU计算部分Q、K、V的乘积,最后通过All-Reduce操作聚合结果;
- FeedForward层:将两层线性投影的权重分别按列和行拆分,中间结果通过All-Gather操作传递,最终完成计算。
张量并行的优势是通信开销相对较小(主要在GPU间进行短距离通信),推理延迟较低;劣势是并行度受单节点GPU数量限制,无法跨节点扩展。
VLLM多模态推理过程
2.1.2 流水线并行(Pipeline Parallelism)
流水线并行的核心思想是将模型的层(Layer)在多个GPU(或节点)之间进行拆分,每个GPU(或节点)仅持有部分层,推理时输入数据按顺序在不同GPU(或节点)的层中流转,形成流水线式计算。该策略适用于模型单节点多GPU无法容纳,需要跨节点部署的场景(如175B模型无法单节点部署,需多节点联合部署)。
VLLM的流水线并行支持均匀拆分与不均匀拆分两种模式:
- 均匀拆分:将模型层平均分配到各个GPU(或节点),适用于GPU数量能整除模型层数的场景;
- 不均匀拆分:当GPU数量无法整除模型层数时,可将不同数量的层分配到各个GPU,提升资源利用率。
流水线并行的优势是可跨节点扩展,支持超大模型部署;劣势是存在“气泡”开销(部分GPU在等待前一阶段数据时处于空闲状态),可能导致吞吐量下降,需通过批量推理优化缓解。
2.1.3 混合并行(Tensor + Pipeline Parallelism)
混合并行是将张量并行与流水线并行结合的策略:在每个节点内部采用张量并行(拆分模型张量),在节点之间采用流水线并行(拆分模型层)。该策略适用于超大规模模型(如1T参数模型)的部署,可充分利用单节点多GPU的算力与多节点的扩展能力。
例如,2个节点、每个节点8个GPU部署175B模型时,可设置张量并行大小为8(每个节点内8卡张量并行),流水线并行大小为2(2个节点流水线并行),实现16卡联合部署。
2.2 Kubernetes云原生部署核心组件
Kubernetes作为容器编排平台,为VLLM分布式推理服务提供了完整的资源调度、服务编排、自动运维能力。在企业级部署中,核心依赖以下组件:
2.2.1 容器运行时
推荐使用containerd(2025年主流容器运行时),配合NVIDIA Container Toolkit(用于GPU资源调度)或AMD ROCm Container Runtime(用于AMD GPU),实现VLLM容器对GPU资源的直接访问。
2.2.2 核心编排组件
-
Pod:VLLM推理服务的最小部署单元,每个Pod可包含一个或多个容器(如VLLM容器+监控Sidecar容器),通过资源限制(resources.limits)声明GPU、CPU、内存需求;
-
Deployment:用于部署无状态的VLLM推理服务,支持多副本部署、滚动更新、回滚,适用于单机单卡、单机多卡(单节点内)的部署场景;
-
StatefulSet:用于部署有状态的VLLM推理服务(如多节点流水线并行部署),提供稳定的网络标识(Pod名称、DNS)与持久化存储,确保节点故障恢复后数据一致性;
-
Service:用于暴露VLLM推理服务,实现Pod的负载均衡与服务发现,支持ClusterIP(集群内部访问)、NodePort(外部访问)、LoadBalancer(云厂商负载均衡)三种类型;
-
PersistentVolumeClaim(PVC):用于申请持久化存储,存储VLLM模型文件、缓存数据等,避免Pod重建后数据丢失;
-
ConfigMap/Secret:ConfigMap用于存储VLLM部署的配置参数(如模型路径、并行策略参数),Secret用于存储敏感信息(如Hugging Face Token、API密钥)。
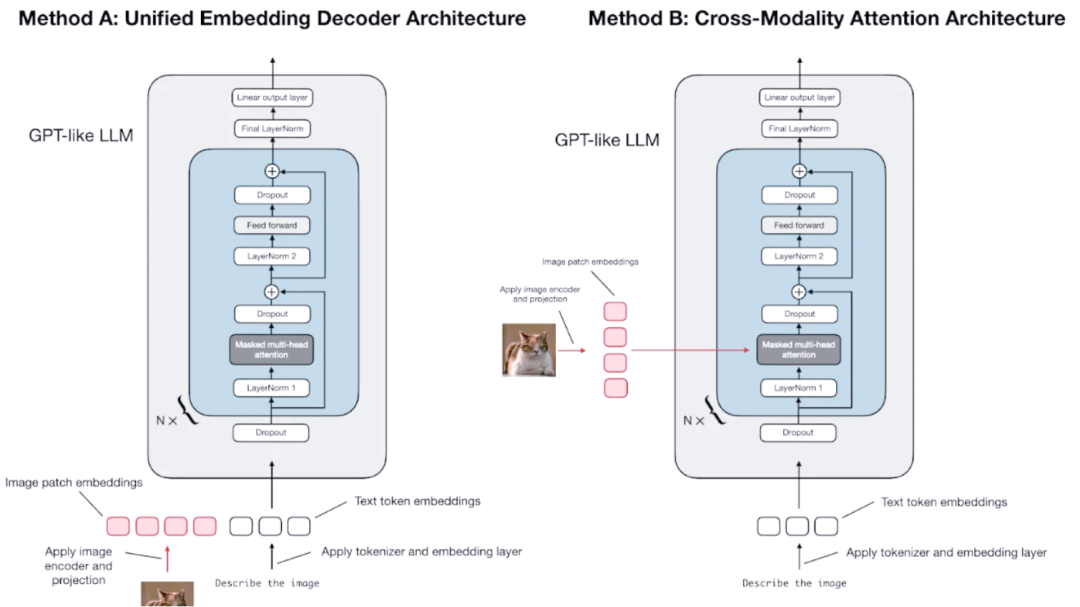
多模态llm:两种主流架构详解
2.2.3 扩展组件
- GPU Operator:NVIDIA提供的GPU管理组件,自动化部署GPU驱动、容器运行时、设备插件,简化GPU集群的运维管理;
- Ray Operator:用于在Kubernetes上部署和管理Ray集群,支撑VLLM多节点分布式推理;
- KServe/llmaz:云原生模型服务平台,提供模型管理、推理服务编排、流量控制等能力,可与VLLM深度集成,提升部署效率与服务可用性;
- Higress:云原生API网关,可作为AI网关实现VLLM推理服务的流量控制、故障转移、可观测性等企业级能力;
- Prometheus + Grafana:监控告警组件,用于采集VLLM推理服务的性能指标(GPU利用率、推理延迟、吞吐量)、资源使用情况,实现可视化监控与告警。
2.3 企业级部署前置条件
在部署VLLM分布式推理服务前,需完成以下前置准备工作:
- Kubernetes集群环境:推荐使用Kubernetes 1.28+版本(2025年稳定版本),集群节点需包含至少1个控制平面节点与多个计算节点(GPU节点),节点间网络互通;
- GPU资源准备:根据部署方案选择合适的GPU型号(如NVIDIA H100、AMD MI300X),确保GPU驱动已正确安装,Kubernetes可通过设备插件识别GPU资源;
- 存储环境:部署分布式文件系统(如NFS、Ceph)或使用云厂商对象存储(如AWS S3、阿里云OSS),用于存储模型文件(需确保所有节点可访问);
- 容器镜像:准备VLLM容器镜像(推荐使用官方镜像vllm/vllm-openai:latest,或基于业务需求自定义镜像,集成监控、日志等工具);
- 网络环境:多节点部署时,推荐使用高速网络(如Infiniband)提升节点间通信效率,确保NCCL(NVIDIA Collective Communications Library)可正常工作;
- 权限配置:创建必要的Kubernetes ServiceAccount、Role、RoleBinding,确保部署组件具备足够的权限(如创建Pod、访问PVC、操作Ray集群等)。
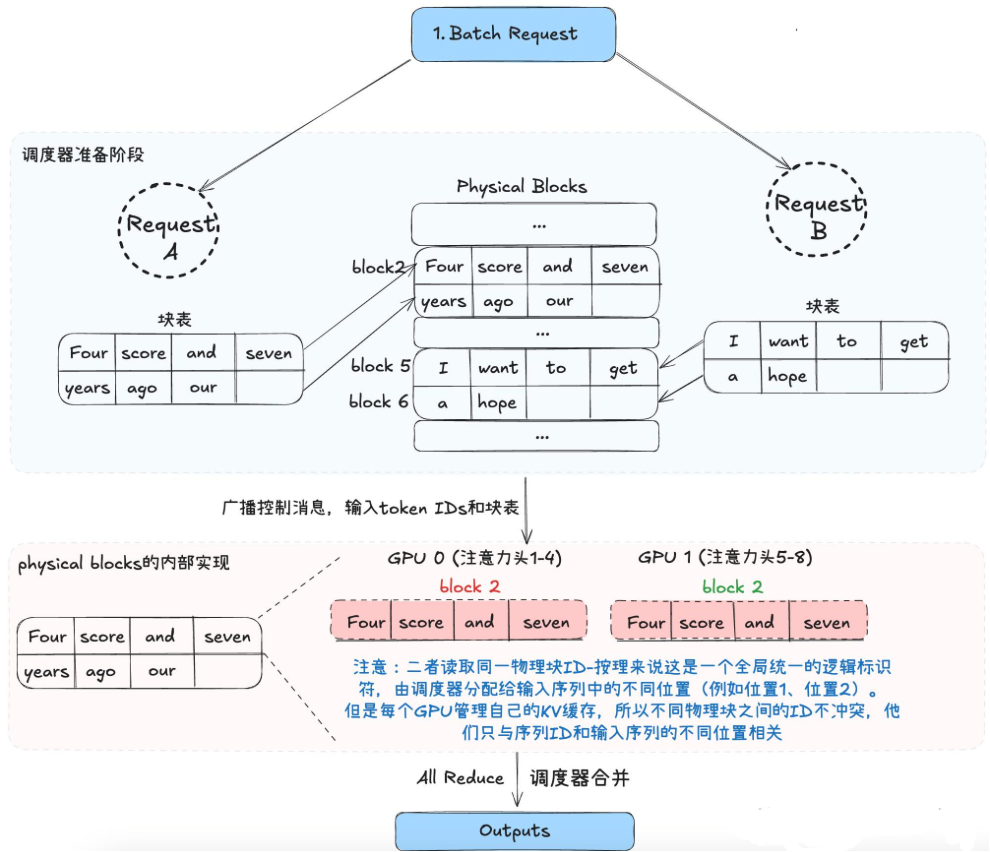
VLLM分布式推理过程
第三章 企业级VLLM分布式部署解决方案详解
根据模型规模、硬件资源、业务需求的不同,企业级VLLM分布式推理服务可分为三种部署方案:单机单卡、单机多卡、多机多卡。本节将详细剖析每种方案的部署架构、实现步骤、参数调优、适用场景,并结合2025年最新实践补充企业级优化策略。
3.1 方案一:单机单卡部署(基础方案)
单机单卡部署是最基础的VLLM推理服务部署方案,适用于小规模模型(如7B及以下参数模型)、低并发业务场景(如内部测试、小型应用)。该方案架构简单、运维成本低,是企业入门LLM推理服务的首选。
3.1.1 部署架构
单机单卡部署架构核心由“Kubernetes Pod + VLLM容器 + 本地/共享存储”组成:
- Pod内运行单个VLLM容器,容器挂载持久化存储(PVC),用于加载模型文件;
- 通过Kubernetes Deployment管理Pod,支持多副本部署实现简单的负载均衡;
- 通过Service暴露服务端口(默认8000),供集群内部或外部应用访问;
- 可选集成监控Sidecar容器(如Prometheus Node Exporter),采集GPU利用率、推理性能等指标。
3.1.2 详细部署步骤
步骤1:创建持久化存储(PVC)
创建PVC用于存储VLLM模型文件(如Llama 3.2-1B-Instruct),确保Pod重建后模型文件不丢失。YAML配置如下(pvc-vllm-model.yaml):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models
namespace: vllm-system # 建议创建独立命名空间管理VLLM服务
spec:
accessModes:
- ReadWriteOnce # 单机单卡场景,单节点访问即可
volumeMode: Filesystem
resources:
requests:
storage: 50Gi # 根据模型大小调整,7B模型约需15Gi,1B模型约需2Gi
storageClassName: default # 需提前创建对应StorageClass
---
# 创建Hugging Face Token Secret(访问受限模型时需配置)
apiVersion: v1
kind: Secret
metadata:
name: hf-token-secret
namespace: vllm-system
type: Opaque
stringData:
token: "YOUR_HUGGING_FACE_TOKEN" # 替换为你的Hugging Face Token
执行部署命令:
kubectl create namespace vllm-system
kubectl apply -f pvc-vllm-model.yaml
步骤2:创建VLLM Deployment
创建Deployment部署VLLM推理服务,指定GPU资源限制、模型路径、服务端口等参数。YAML配置如下(deployment-vllm-single-gpu.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-single-gpu
namespace: vllm-system
labels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: single-gpu
spec:
replicas: 2 # 多副本部署,实现负载均衡
selector:
matchLabels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: single-gpu
template:
metadata:
labels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: single-gpu
spec:
containers:
- name: vllm
image: vllm/vllm-openai:latest # 2025年最新官方镜像
imagePullPolicy: Always
command: ["/bin/sh", "-c"]
args: [
"vllm serve meta-llama/Llama-3.2-1B-Instruct \
--port 8000 \
--trust-remote-code \
--max_num_batched_tokens 1024 \ # 批处理最大token数,根据GPU内存调整
--gpu_memory_utilization 0.8 # GPU内存利用率阈值,避免OOM
"]
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token-secret
key: token
ports:
- containerPort: 8000
name: http
protocol: TCP
resources:
limits:
cpu: "8" # 根据业务需求调整,建议为GPU核心数的2倍
memory: "32Gi"
nvidia.com/gpu: "1" # 单机单卡,指定1个GPU
requests:
cpu: "4"
memory: "16Gi"
nvidia.com/gpu: "1"
volumeMounts:
- name: model-storage
mountPath: /root/.cache/huggingface # Hugging Face模型缓存路径
# 健康检查配置(企业级必选,确保服务可用性)
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60 # 模型加载时间较长,延迟检查
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 5
timeoutSeconds: 3
successThreshold: 1
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: vllm-models
执行部署命令:
kubectl apply -f deployment-vllm-single-gpu.yaml
步骤3:创建Service暴露服务
创建Service暴露VLLM推理服务,支持集群内部访问。YAML配置如下(service-vllm-single-gpu.yaml):
apiVersion: v1
kind: Service
metadata:
name: vllm-single-gpu-service
namespace: vllm-system
spec:
selector:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: single-gpu
ports:
- name: http
port: 80
targetPort: 8000
protocol: TCP
type: ClusterIP # 集群内部访问,外部访问可改为NodePort或LoadBalancer
执行部署命令:
kubectl apply -f service-vllm-single-gpu.yaml
步骤4:部署验证
- 检查Pod状态,确保所有Pod处于Running状态:
kubectl get pods -n vllm-system
# 预期输出:
# NAME READY STATUS RESTARTS AGE
# vllm-single-gpu-7f9d6f8b45-2xqzk 1/1 Running 0 5m
# vllm-single-gpu-7f9d6f8b45-5r7vs 1/1 Running 0 5m
- 查看Pod日志,验证VLLM服务是否正常启动:
kubectl logs -n vllm-system vllm-single-gpu-7f9d6f8b45-2xqzk
# 预期输出包含:
# INFO: Started server process [1]
# INFO: Waiting for application startup.
# INFO: Application startup complete.
# INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
- 测试推理服务,发送请求验证功能:
# 在Kubernetes集群内部节点执行curl命令
curl http://vllm-single-gpu-service.vllm-system.svc.cluster.local/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3.2-1B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 20,
"temperature": 0.7
}'
# 预期返回包含生成文本的响应
3.1.3 参数调优策略(企业级关键)
单机单卡部署的性能优化核心是合理配置VLLM参数,充分利用GPU资源,平衡延迟与吞吐量:
- –max_num_batched_tokens:批处理最大token数,是影响吞吐量的关键参数。需根据GPU内存大小调整,例如16Gi GPU可设置为1024,32Gi GPU可设置为2048。过大可能导致OOM,过小则吞吐量不足;
- –gpu_memory_utilization:GPU内存利用率阈值,建议设置为0.7-0.8,预留部分内存用于动态生成的KV缓存,避免OOM;
- –enable-chunked-prefill:启用分块预填充,适用于长文本prompt场景,可减少预填充阶段的内存占用,提升长序列推理性能;
- –tensor-parallel-size:单机单卡场景设置为1(默认),无需修改;
- –scheduler-delay:调度延迟,默认0.001秒,可根据并发量调整。高并发场景可适当增大(如0.005秒),提升批处理效率;低延迟场景可减小(如0.0005秒),降低推理延迟。
3.1.4 适用场景与局限性
适用场景:
- 小规模模型(7B及以下参数,如Llama 3.2-1B、Qwen2-1.5B)部署;
- 低并发业务场景(并发请求数≤100),如内部办公助手、小型应用的AI功能;
- 测试环境验证,用于验证VLLM模型兼容性、推理功能;
- 资源预算有限的中小企业,无需投入多GPU硬件资源。
局限性:
- 不支持大规模模型(13B及以上参数)部署,单卡GPU内存不足;
- 吞吐量有限,无法应对高并发业务场景(如电商大促、公共服务AI接口);
- 单节点故障会导致服务中断,高可用性不足(需通过多副本部署缓解,但受单节点资源限制)。
3.2 方案二:单机多卡部署(张量并行)
单机多卡部署采用张量并行策略,将模型张量拆分到单节点的多个GPU上,适用于中大规模模型(13B-100B参数)、中高并发业务场景。该方案可充分利用单节点多GPU资源,提升模型容量与推理吞吐量,是企业级生产环境的主流部署方案之一。
3.2.1 部署架构
单机多卡部署架构核心由“Kubernetes Pod + 多GPU VLLM容器 + 共享存储 + 本地共享内存”组成:
- 单个Pod内运行VLLM容器,容器通过张量并行占用单节点的多个GPU(如4卡、8卡);
- Pod挂载共享存储(PVC)加载模型文件,同时配置本地共享内存(emptyDir medium: Memory)用于GPU间通信,提升张量并行效率;
- 通过Kubernetes Deployment管理Pod,支持多副本部署(每个副本占用多个GPU),实现跨节点负载均衡;
- VLLM默认使用Python原生多进程(mp)管理分布式运行时,无需依赖Ray,简化部署复杂度;
- 集成监控组件,采集每个GPU的利用率、推理性能等指标,实现多GPU状态可视化。
3.2.2 详细部署步骤
步骤1:创建持久化存储与Secret(复用3.1.2步骤1)
如需部署不同模型,可创建新的PVC,配置如下(pvc-vllm-model-13b.yaml):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models-13b
namespace: vllm-system
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 100Gi # 13B模型约需30Gi,预留足够空间
storageClassName: default
执行部署命令:
kubectl apply -f pvc-vllm-model-13b.yaml
步骤2:创建VLLM Deployment(单机多卡)
创建Deployment部署VLLM张量并行服务,指定多个GPU资源、张量并行大小等参数。YAML配置如下(deployment-vllm-multi-gpu.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-multi-gpu
namespace: vllm-system
labels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: multi-gpu
spec:
replicas: 1 # 单副本占用4卡GPU,根据节点GPU数量调整
selector:
matchLabels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: multi-gpu
template:
metadata:
labels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: multi-gpu
spec:
# 节点亲和性:将Pod调度到拥有4个GPU的节点
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu.count
operator: In
values:
- "4"
containers:
- name: vllm
image: vllm/vllm-openai:latest
imagePullPolicy: Always
command: ["/bin/sh", "-c"]
args: [
"vllm serve facebook/opt-13b \
--port 8000 \
--trust-remote-code \
--tensor-parallel-size 4 \ # 张量并行大小=GPU数量(4卡)
--max_num_batched_tokens 2048 \ # 批处理大小根据4卡内存调整
--gpu_memory_utilization 0.8 \
--enable-chunked-prefill \
--distributed-executor-backend mp # 使用Python多进程管理分布式运行时
"]
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token-secret
key: token
- name: NCCL_DEBUG
value: "INFO" # 开启NCCL调试日志,便于排查GPU通信问题
ports:
- containerPort: 8000
name: http
protocol: TCP
resources:
limits:
cpu: "32" # 4卡GPU建议配置32核CPU
memory: "128Gi"
nvidia.com/gpu: "4" # 指定4个GPU
requests:
cpu: "16"
memory: "64Gi"
nvidia.com/gpu: "4"
volumeMounts:
- name: model-storage-13b
mountPath: /root/.cache/huggingface
- name: shm # 本地共享内存,用于GPU间通信
mountPath: /dev/shm
# 健康检查配置
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 120 # 13B模型加载时间较长,延长延迟检查
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 120
periodSeconds: 5
timeoutSeconds: 3
successThreshold: 1
volumes:
- name: model-storage-13b
persistentVolumeClaim:
claimName: vllm-models-13b
- name: shm # 配置共享内存,大小根据GPU数量调整(4卡建议2Gi)
emptyDir:
medium: Memory
sizeLimit: "2Gi"
执行部署命令:
kubectl apply -f deployment-vllm-multi-gpu.yaml
步骤3:创建Service暴露服务(复用3.1.2步骤3,调整selector)
YAML配置如下(service-vllm-multi-gpu.yaml):
apiVersion: v1
kind: Service
metadata:
name: vllm-multi-gpu-service
namespace: vllm-system
spec:
selector:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: multi-gpu
ports:
- name: http
port: 80
targetPort: 8000
protocol: TCP
type: ClusterIP
执行部署命令:
kubectl apply -f service-vllm-multi-gpu.yaml
步骤4:部署验证
- 检查Pod状态,确保Pod处于Running状态:
kubectl get pods -n vllm-system
# 预期输出:
# NAME READY STATUS RESTARTS AGE
# vllm-multi-gpu-6f7d5c4b32-9zqkp 1/1 Running 0 10m
- 查看Pod日志,验证张量并行是否正常启动:
kubectl logs -n vllm-system vllm-multi-gpu-6f7d5c4b32-9zqkp
# 预期输出包含:
# Using distributed executor backend: mp
# Tensor parallel size: 4
# Initializing model...
# Loading weights...
# INFO: Started server process [1]
# INFO: Application startup complete.
- 检查GPU使用情况,确保4个GPU均被占用:
# 在Pod所在节点执行nvidia-smi命令
kubectl debug -it -n vllm-system vllm-multi-gpu-6f7d5c4b32-9zqkp --image=nvidia/cuda:12.1.1-base-ubuntu22.04 --share-processes -- sh
nvidia-smi
# 预期输出显示4个GPU的Memory Usage和GPU Utilization均有占用
- 测试推理服务,验证高吞吐量性能:
# 使用压测工具(如locust)发送并发请求
# 或执行多次curl请求验证
for i in {1..10}; do
curl http://vllm-multi-gpu-service.vllm-system.svc.cluster.local/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "facebook/opt-13b",
"prompt": "Artificial intelligence is",
"max_tokens": 30,
"temperature": 0.5
}' &
done
# 预期所有请求均能正常返回,无超时或错误
3.2.3 特殊场景处理:非均匀模型拆分
当模型可放入单节点多个GPU,但GPU数量无法均匀拆分模型大小时(如3卡GPU部署13B模型),可采用“张量并行大小=1+流水线并行大小=GPU数量”的策略,通过流水线并行实现非均匀拆分。部署时需调整参数:
vllm serve facebook/opt-13b \
--port 8000 \
--trust-remote-code \
--tensor-parallel-size 1 \
--pipeline-parallel-size 3 \ # 流水线并行大小=GPU数量(3卡)
--max_num_batched_tokens 2048 \
--gpu_memory_utilization 0.8
该策略通过沿着模型层拆分实现非均匀部署,提升资源利用率,但会引入一定的流水线“气泡”开销,需通过增大批处理大小缓解。
3.2.4 参数调优策略
-
–tensor-parallel-size:必须与单节点GPU数量一致(如4卡设置为4,8卡设置为8),确保模型张量均匀拆分;
-
–max_num_batched_tokens:根据单节点GPU总内存调整,4卡32Gi GPU可设置为2048-4096,8卡32Gi GPU可设置为4096-8192,最大化吞吐量;
-
–gpu_memory_utilization:建议设置为0.75-0.85,平衡模型权重与KV缓存的内存占用;
-
–distributed-executor-backend:单节点多卡优先使用mp(Python多进程),无需安装Ray,简化部署;如需与Ray集成,可改为ray;
-
共享内存大小:根据GPU数量调整,4卡建议2Gi,8卡建议4Gi,确保GPU间通信高效。
3.2.5 适用场景与局限性
适用场景:
- 中大规模模型(13B-100B参数,如Opt-13B、Llama 3-70B)部署;
- 中高并发业务场景(并发请求数100-1000),如企业级智能客服、电商AI推荐;
- 对推理延迟要求较高的场景(张量并行通信开销小,延迟低于流水线并行);
- 硬件资源限制为单节点多GPU,无法扩展多节点的场景。
局限性:
- 不支持超大规模模型(100B+参数)部署,单节点GPU总内存不足;
- 单节点故障会导致服务中断,高可用性依赖多副本部署(需多个单节点多GPU节点);
- GPU数量受单节点硬件限制(通常单节点最大8-16卡),扩展性有限。
3.3 方案三:多机多卡部署(张量并行+流水线并行)
多机多卡部署采用“张量并行+流水线并行”的混合并行策略,在每个节点内部使用张量并行,节点之间使用流水线并行,适用于超大规模模型(100B+参数,如GPT-4、Llama 3-400B)、超高并发业务场景。该方案可充分利用多节点多GPU资源,实现模型容量与吞吐量的大幅提升,是2025年大型企业核心业务LLM推理服务的首选方案。
3.3.1 部署架构
多机多卡部署架构核心由“Kubernetes StatefulSet + Ray集群 + 多节点多GPU VLLM容器 + 分布式存储 + 高速网络”组成:
- 采用StatefulSet部署VLLM服务,提供稳定的网络标识与持久化存储,确保多节点部署的一致性;
- 通过Ray集群管理多节点分布式运行时,VLLM依赖Ray实现跨节点通信与协同计算;
- 每个节点内部采用张量并行(拆分模型张量),节点之间采用流水线并行(拆分模型层),形成混合并行架构;
- 使用分布式存储(如Ceph)存储模型文件,确保所有节点可高效访问;
- 部署高速网络(如Infiniband)提升节点间通信效率,降低流水线并行的“气泡”开销;
- 集成AI网关(如Higress)实现流量控制、故障转移,集成监控系统采集全链路指标。
示例架构:2个节点,每个节点8个GPU,部署175B模型,张量并行大小=8(每个节点内8卡张量并行),流水线并行大小=2(2个节点流水线并行)。
3.3.2 详细部署步骤步骤1:
部署Ray集群(多节点分布式运行时)
使用Ray Operator在Kubernetes上部署Ray集群,包含1个头节点(Head Node)和多个工作节点(Worker Node)。
- 安装Ray Operator:
helm repo add ray https://ray-project.github.io/kuberay-helm/
helm install kuberay-operator ray/kuberay-operator --namespace ray-system --create-namespace
- 创建Ray集群配置(ray-cluster-vllm.yaml):
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ray-cluster-vllm
namespace: vllm-system
spec:
rayVersion: "2.10.0" # 2025年稳定版本
headGroupSpec:
serviceType: ClusterIP
replicas: 1
rayStartParams:
dashboard-host: "0.0.0.0"
num-cpus: "32"
num-gpus: "0" # 头节点不占用GPU
template:
spec:
containers:
- name: ray-head
image: rayproject/ray-ml:2.10.0-py39-cuda12.1.1
resources:
limits:
cpu: "32"
memory: "64Gi"
requests:
cpu: "16"
memory: "32Gi"
env:
- name: RAY_DISABLE_DOCKER_CPU_WARNING
value: "true"
- name: LC_ALL
value: "en_US.UTF-8"
ports:
- containerPort: 6379 # Ray GCS服务端口
name: gcs
- containerPort: 8265 # Ray Dashboard端口
name: dashboard
- containerPort: 10001 # Ray Client端口
name: client
workerGroupSpecs:
- groupName: worker-group-gpu
replicas: 2 # 2个工作节点,对应多机部署需求
minReplicas: 2
maxReplicas: 4 # 支持弹性扩容
rayStartParams:
num-cpus: "32"
num-gpus: "8" # 每个工作节点8个GPU
node-ip-address: "$MY_POD_IP"
template:
spec:
affinity:
# 避免工作节点调度到同一物理节点
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: ray.io/group
operator: In
values:
- worker-group-gpu
topologyKey: "kubernetes.io/hostname"
containers:
- name: ray-worker
image: rayproject/ray-ml:2.10.0-py39-cuda12.1.1
resources:
limits:
cpu: "32"
memory: "128Gi"
nvidia.com/gpu: "8" # 每个节点8卡GPU
requests:
cpu: "16"
memory: "64Gi"
nvidia.com/gpu: "8"
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NCCL_SOCKET_IFNAME
value: "eth0" # 指定通信网卡,适配高速网络
- name: NCCL_DEBUG
value: "INFO"
volumeMounts:
- name: shm
mountPath: /dev/shm
volumes:
- name: shm
emptyDir:
medium: Memory
sizeLimit: "8Gi" # 8卡节点共享内存配置
---
# 创建Ray集群服务,用于节点间通信
apiVersion: v1
kind: Service
metadata:
name: ray-cluster-vllm-head-svc
namespace: vllm-system
spec:
selector:
ray.io/cluster: ray-cluster-vllm
ray.io/role: head
ports:
- name: gcs
port: 6379
targetPort: 6379
- name: dashboard
port: 8265
targetPort: 8265
type: ClusterIP
步骤2:部署VLLM StatefulSet(混合并行)
多机多卡部署需使用StatefulSet保障有状态服务的稳定性,配置中需指定Ray集群连接参数、混合并行策略及分布式存储挂载。YAML配置如下(statefulset-vllm-hybrid-parallel.yaml):
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: vllm-hybrid-parallel
namespace: vllm-system
spec:
serviceName: vllm-hybrid-parallel-svc
replicas: 2 # 与Ray工作节点数量一致
selector:
matchLabels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: hybrid-parallel
template:
metadata:
labels:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: hybrid-parallel
ray.io/cluster: ray-cluster-vllm
spec:
serviceAccountName: ray-service-account
affinity:
# 与Ray工作节点绑定调度
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: ray.io/cluster
operator: In
values:
- ray-cluster-vllm
- key: ray.io/group
operator: In
values:
- worker-group-gpu
topologyKey: "kubernetes.io/hostname"
containers:
- name: vllm
image: vllm/vllm-openai:latest
imagePullPolicy: Always
command: ["/bin/sh", "-c"]
args: [
"vllm serve meta-llama/Llama-3-400B \
--port 8000 \
--trust-remote-code \
--tensor-parallel-size 8 \ # 单节点内8卡张量并行
--pipeline-parallel-size 2 \ # 2个节点流水线并行
--distributed-executor-backend ray \ # 使用Ray分布式运行时
--ray-address ray://ray-cluster-vllm-head-svc.vllm-system.svc.cluster.local:6379 \
--max_num_batched_tokens 4096 \
--gpu_memory_utilization 0.8 \
--enable-chunked-prefill \
--disable-log-requests # 高并发场景关闭请求日志,提升性能
"
]
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token-secret
key: token
- name: RAY_USE_MULTIPROCESSING_CPU_COUNT
value: "false"
ports:
- containerPort: 8000
name: http
protocol: TCP
resources:
limits:
cpu: "32"
memory: "128Gi"
nvidia.com/gpu: "8"
requests:
cpu: "16"
memory: "64Gi"
nvidia.com/gpu: "8"
volumeMounts:
- name: model-storage-hybrid
mountPath: /root/.cache/huggingface
- name: shm
mountPath: /dev/shm
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 300 # 超大规模模型加载时间长,延长检查延迟
periodSeconds: 20
timeoutSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 300
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
volumes:
- name: shm
emptyDir:
medium: Memory
sizeLimit: "8Gi"
volumeClaimTemplates:
- metadata:
name: model-storage-hybrid
spec:
accessModes:
- ReadWriteMany # 分布式存储,多节点共享访问
volumeMode: Filesystem
resources:
requests:
storage: 500Gi # 400B模型约需150Gi,预留足够空间
storageClassName: cephfs # 使用Ceph分布式存储
执行部署命令:
kubectl apply -f statefulset-vllm-hybrid-parallel.yaml
步骤3:创建Service与AI网关
- 创建Headless Service保障StatefulSet Pod间通信:
apiVersion: v1
kind: Service
metadata:
name: vllm-hybrid-parallel-svc
namespace: vllm-system
spec:
selector:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: hybrid-parallel
ports:
- name: http
port: 8000
targetPort: 8000
clusterIP: None # Headless Service
- 创建ClusterIP Service暴露服务:
apiVersion: v1
kind: Service
metadata:
name: vllm-hybrid-parallel-public-svc
namespace: vllm-system
spec:
selector:
app.kubernetes.io/name: vllm
app.kubernetes.io/instance: hybrid-parallel
ports:
- name: http
port: 80
targetPort: 8000
type: ClusterIP
- 部署Higress AI网关(企业级必选):用于流量控制、负载均衡与故障转移,配置如下(gateway-higress-vllm.yaml):
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: vs-vllm-hybrid
namespace: vllm-system
spec:
hosts:
- "llm-api.example.com" # 企业自定义域名
gateways:
- higress-system/higress-gateway
http:
- route:
- destination:
host: vllm-hybrid-parallel-public-svc.vllm-system.svc.cluster.local
port:
number: 80
retries:
attempts: 3
perTryTimeout: 30s
timeout: 60s
执行部署命令:
kubectl apply -f service-vllm-hybrid-headless.yaml
kubectl apply -f service-vllm-hybrid-public.yaml
kubectl apply -f gateway-higress-vllm.yaml
步骤4:部署验证
- 检查Ray集群状态:
# 进入Ray头节点Pod
kubectl exec -it -n vllm-system ray-cluster-vllm-head-0 -- sh
# 执行Ray集群状态命令
ray status
# 预期输出包含:2 workers (each with 32 CPUs, 8 GPUs)
- 检查VLLM StatefulSet Pod状态:
kubectl get pods -n vllm-system -l app.kubernetes.io/instance=hybrid-parallel
# 预期输出2个Pod均为Running状态:
# NAME READY STATUS RESTARTS AGE
# vllm-hybrid-parallel-0 1/1 Running 0 20m
# vllm-hybrid-parallel-1 1/1 Running 0 20m
- 验证GPU资源占用:
# 在每个工作节点执行nvidia-smi
kubectl debug -it -n vllm-system vllm-hybrid-parallel-0 --image=nvidia/cuda:12.1.1-base-ubuntu22.04 --share-processes -- sh
nvidia-smi
# 预期8个GPU均有内存占用和算力消耗
- 测试推理服务:
curl http://vllm-hybrid-parallel-public-svc.vllm-system.svc.cluster.local/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3-400B",
"prompt": "Explain the principle of hybrid parallelism in LLM inference",
"max_tokens": 50,
"temperature": 0.6
}'
# 预期返回符合要求的生成文本
3.3.3 参数调优策略(混合并行核心)
多机多卡部署的优化核心是平衡张量并行与流水线并行的协同效率,降低通信开销与气泡效应:
- 并行大小搭配:张量并行大小建议等于单节点GPU数量(如8卡节点设为8),流水线并行大小等于节点数量(如2节点设为2),确保资源均匀分配;
- –max_num_batched_tokens:超大规模模型建议设置为4096-8192,通过增大批处理量缓解流水线气泡开销,提升吞吐量;
- –pipeline-parallel-chunk-size:流水线并行块大小,建议设置为32-64,减小块间通信频率,提升流水线效率;
- 网络优化:启用NCCL高速通信,配置
NCCL_SOCKET_IFNAME=eth0(或高速网卡名),多节点部署优先使用Infiniband网络; - 内存优化:启用
--enable-sliding-window(滑动窗口注意力),减少长序列推理的KV缓存占用;设置--gpu_memory_utilization=0.85,在超大规模模型场景下平衡内存使用。
3.3.4 适用场景与局限性
适用场景:
- 超大规模模型(100B+参数,如Llama 3-400B、GPT-4)部署;
- 超高并发业务场景(并发请求数1000+),如大型互联网公司的公共AI接口、金融行业的智能风控平台;
- 核心业务场景(要求99.99%以上可用性),如自动驾驶决策、医疗AI诊断;
- 企业级规模化部署,需充分利用多节点GPU资源实现成本与性能平衡的场景。
局限性:
- 部署复杂度高,需配置Ray集群、StatefulSet、分布式存储、高速网络等组件,对运维能力要求高;
- 节点间通信开销较大,需依赖高速网络(如Infiniband),否则会导致推理延迟上升;
- 资源投入成本高,需多个多卡GPU节点及配套存储、网络设备,中小企业难以承担;
- 流水线气泡效应无法完全消除,在低并发场景下吞吐量提升不明显。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献196条内容
已为社区贡献196条内容

所有评论(0)