机器人算法与设计-复习
机器人学导论复习笔记(原书第四版,斯坦福大学John J.Craig)
教材:机器人学导论(原书第四版,斯坦福大学John J.Craig)
必背
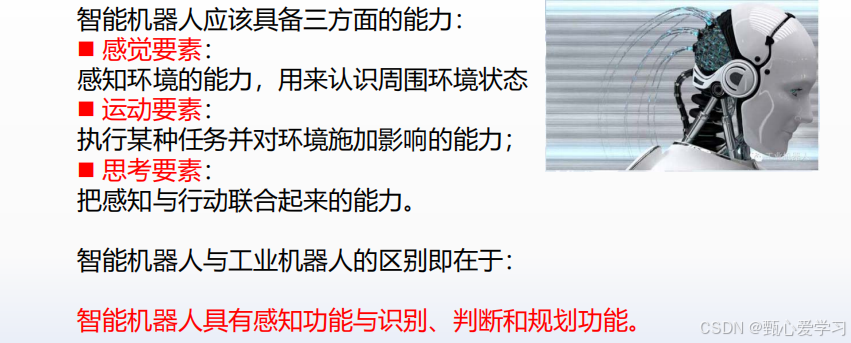
1.什么是机器人,什么是智能机器人
机器人:可编程和多功能的操作机;或是为了执行不同的任务而具有可用电脑改变和可编程动作的专门系统
(工业机器人)特点:可编程;代替人类的部分功能或技能;特定领域的应用;机电一体化的产物
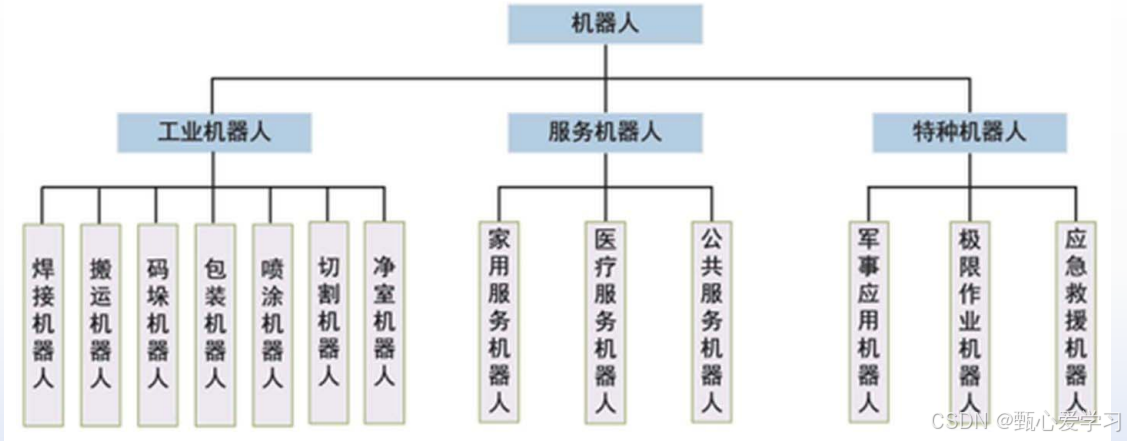
分类以及示例
智能机器人:智能机器人是像人类一样具有自我意识的机器人。其核心在于人工智能 (AI) 技术,即对人的意识、思维的信息过程的模拟。
自由度定义:操作臂所拥有的自由度数目,是为了确定机构所有部件位置而必须指定的独立位置变量的数目,对于典型的工业机器人(开链机构),自由度数目等于关节(Joints)的数目

2.位姿计算
位置描述:建一个坐标系后,用3*1的位置矢量表示

平移:
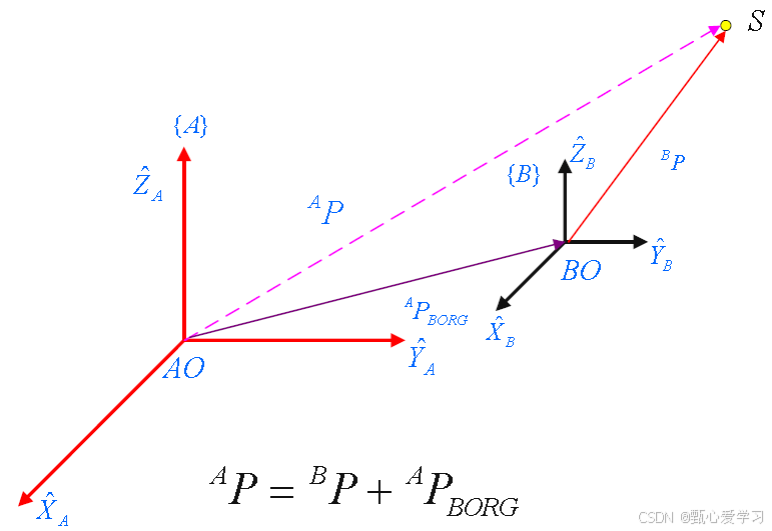

姿态描述:我们在物体上固定一个坐标系 B,描述 B 相对于 A 的姿态,本质上就是描述 B 的三个主轴单位矢量 在 A 中的投影,即旋转矩阵:
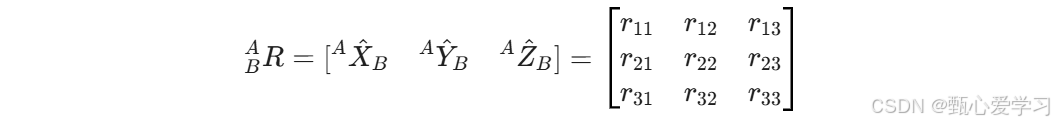

旋转矩阵的性质

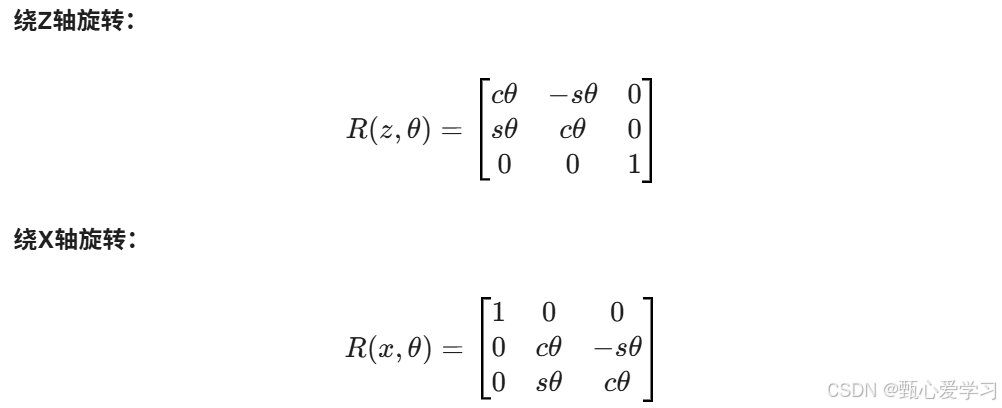
绕y轴旋转

一般映射:(先旋转到相同位姿,再平移)
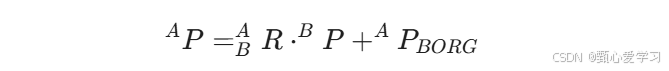
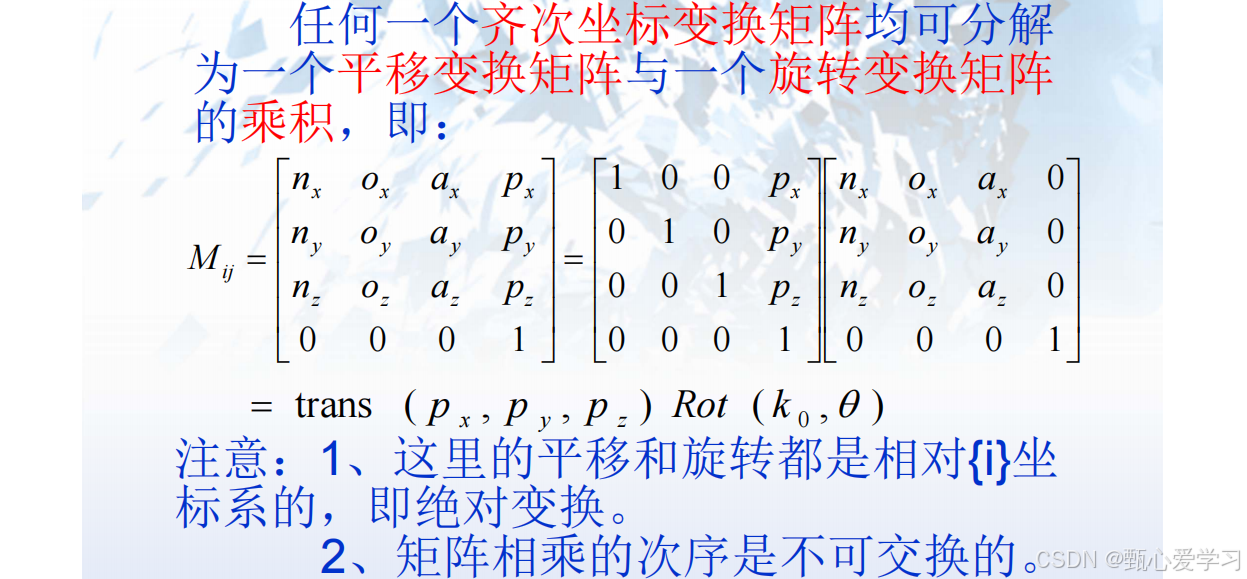
引入齐次变换矩阵
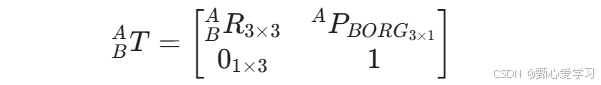
可简化为:
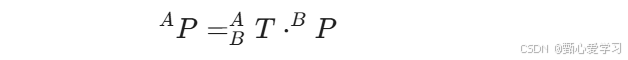
描述->映射->算子:对矢量P在某个坐标系下进行旋转或平移变换
复合变换:
![]()
(下面有点绕,理解即可)


注意上述旋转矩阵公式的坐标都是这个方向

3.运动学(正)
操作臂运动学:研究操作臂的运动特性,而不考虑使操作臂产生运动时施加的力。操作臂运动学研究的是手臂各连杆间的位移关系,速度关系和加速度关系。 本章只讨论位移关系

正运动学的任务:建立映射函数f

建立连杆坐标系

连杆描述:D-H参数(按照图理解记忆比较容易)

(注意连杆的符号i-1)
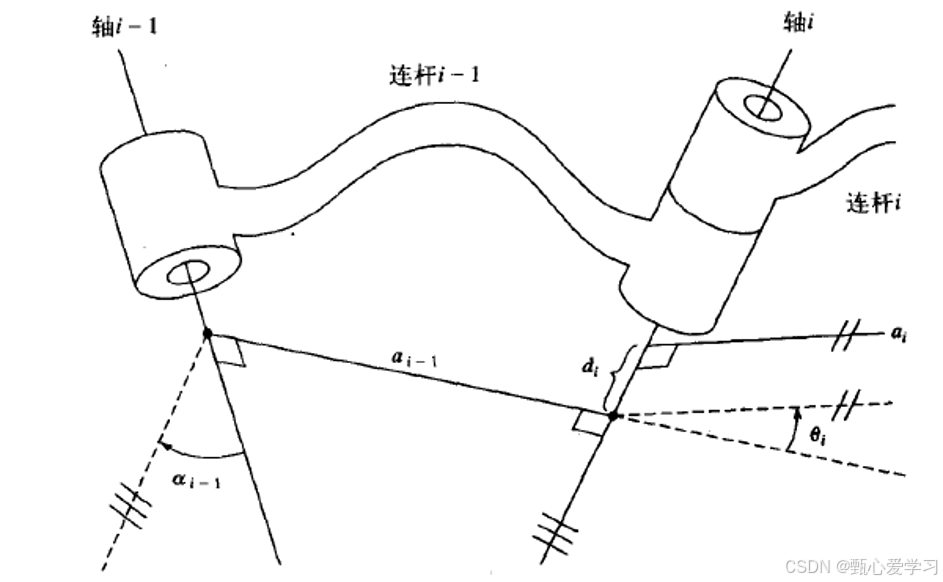
连杆变换矩阵推导

(这里公式不太标准,课本上T的小标都写在了左边)
(两次旋转与平移,可以理解为:第一次找到相应的轴,第二次准备好与下一个杆衔接)
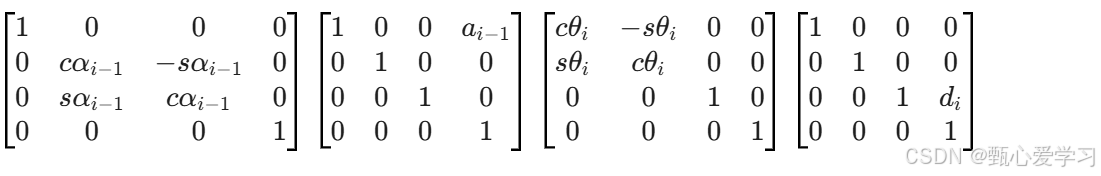

连乘后即运动学方程:(末端相对于基座的变换)
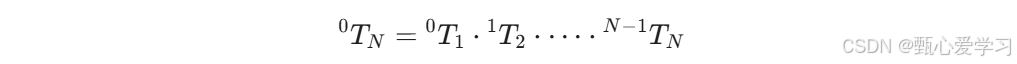

4 逆运动学
逆运动学概念

解是否存在:取决于工作空间,若目标点在工作空间外,无解;若在工作空间边界,通常是奇异点
工作空间是操作臂末端执行器所能到达的范围
灵巧工作空间:机器人能以任意位姿到达的空间区域
可达工作空间:机器人能以至少一种姿态到达的空间区域
多解性:对于非线性方程组,解通常不唯一。
-
例如:PUMA 560 机械臂通常有 8组解(手臂的左/右、肘部的上/下、手腕的翻转/不翻转组合)。
-
选择策略:通常选择距离当前关节位置最近的解(“最短路径”原则),或者避开障碍物的解
确定n自由度操作臂子空间的一种方法就是给出腕部坐标系或工具坐标系的表达式,它是含有n个变量的函数
解法:分为封闭解与数值解

求封闭解:代数法和几何法


数值解法:

-
它是一个迭代过程,需要很多步计算。
-
如果初始猜测点离真值太远,可能不收敛。
-
在奇异点附近,因为 J 不可逆,算法会失效。
解耦思想:先求位置(前3轴),再求姿态(后3轴)

5.速度与静力
速度的定义(点位置的变化率)

角速度:(刚体姿态的变化率)线速度描述了点的一种属性,角速度描述了刚体的一种属性。坐标系总是固联在被描述的刚体上,所以可以用角速度来描述坐标系的旋转运动。
角速度递推:(旋转关节)
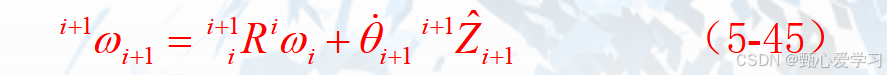
线速度递推:(旋转关节)
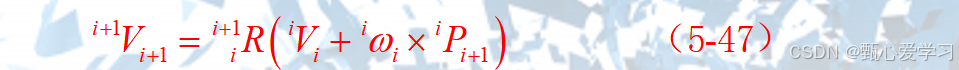
雅可比矩阵
物理意义:雅可比矩阵是一个线性变换,它将关节空间的速度映射到笛卡尔空间的速度。




雅克比矩阵的行数等于操作臂在笛卡尔空间的自由度数量,雅克比矩阵的列数等于操作臂的关节数量

考虑雅可比矩阵是否可逆,很多时候我们求解的是这个:
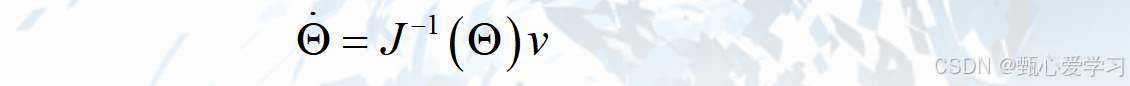
奇异位形:大多数操作臂都有使得雅克比矩阵出现奇异的Θ值。这些位置就称为机构的奇异位形或简称奇异状态,此时J不是满秩(秩亏)。所有操作臂在工作空间的边界都存在奇异位形,并且大多数操作臂在它们的工作空间内也有奇异位形
(1)工作空间边界的奇异位形:出现在操作臂完全展开或者收回使得末端执行器处于或非常接近工作边界的情况。 (2)工作空间内部的奇异位形:出现在远离工作空间的边界,通常是由于两个或两个以上的关节轴线共线引起的
当一个操作臂处于奇异位形时,它会失去一个或多个自由度(在笛卡尔空间中观察)。这也就是说,在笛卡尔空间的某个方向上(或某个子空间中),无论选择什么样的关节速度,都不能使机器人手臂运动。显然,这种情况也会在机器人的工作空间的边界发生。
(总是感觉AI写的更清楚明了)


力的递推公式

力域中的雅可比
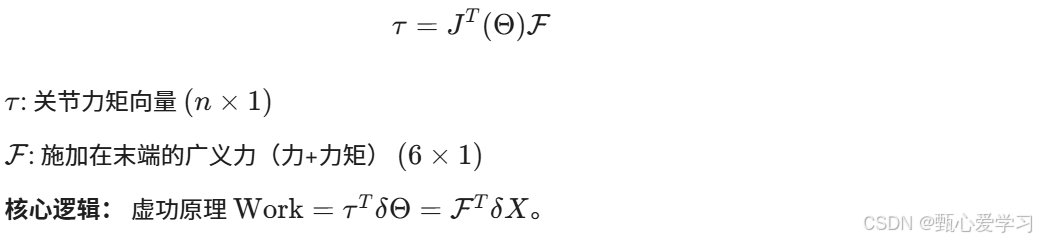
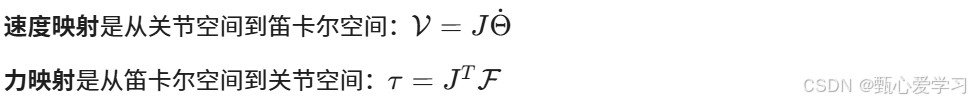

6 操作臂动力学

线加速度与角加速度
线加速度
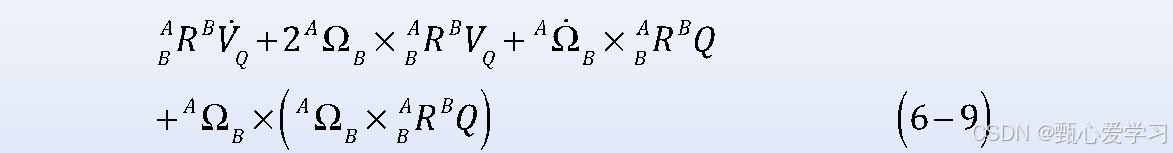
角加速度
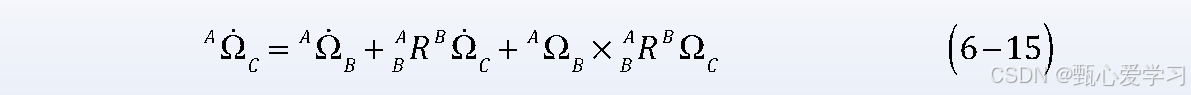

质量分布与惯性张量
在一个刚体绕任意轴作旋转运动时,我们需要一种能够表征刚体质量分布的方法。在这里,我们引入惯性张量,它可以被看作是对一个物体惯量的广义度量。

(注意惯性张量的正负号)
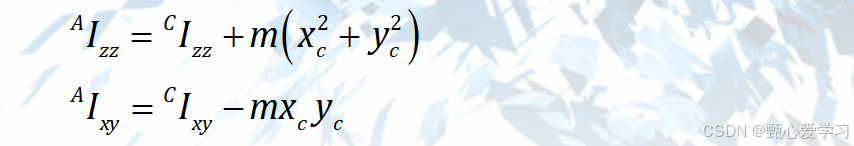

惯性张量与惯性矩区别
(惯性张量的对角线的三个元素就是惯性矩)
(1)惯量矩是描述刚体作定轴转动时的转动惯性大小,而惯性张量是描述刚体作定点转动时的转动惯性的一组惯性量,其表现形式为由9个分量构成的矩阵。
(2)对惯量矩而言,当刚体转动的转轴确定 (定轴) 以后,惯量矩 J 就为一个常量 (确定值),J的量值与轴上的坐标系无关,而对惯性张量而言 ,当刚体转动的定点取定以后 ,因通过该点可以建立多个乃至无穷个坐标系 ,所以惯性张量 I 对仅确定的定点转动刚体是一组 (9 个) 变量。

牛顿欧拉方程
牛顿方程以及描述旋转运动的欧拉方程描述了力、惯量和加速度之间的关系


简述机器人动力学的定义以及机器人动力学分析的意义

(计算惯性张量的例题)

7 轨迹
轨迹指的是每个自由度的位置,速度和加速度的时间历程
路径与轨迹的关系:

轨迹描述可能需要:期望中间点(过渡点),路径点(初始点,中间点,最终点),各中间点之间的时间间隔

关节空间规划方法:以关节角θ的函数来描述轨迹在时间和空间的轨迹生成方法。将中间点转换成一组期望关节角。得到经过中间点并终止于目标点的n个关节的光滑函数

三次多项式,四个约束条件:初始关节角,终止关节角,初始关节速度为0,终止关节速度为0
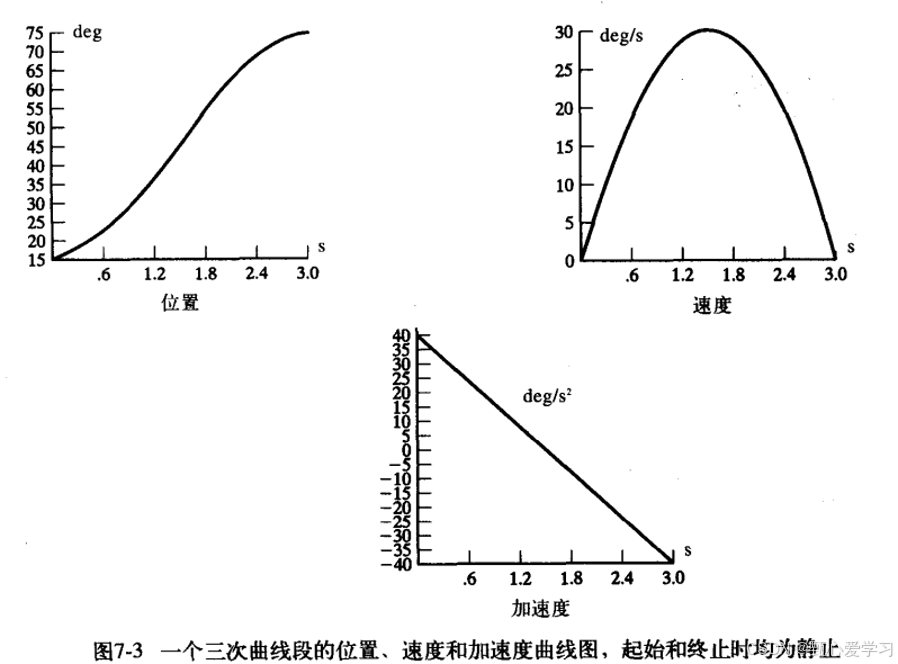
(注意图像的画法)
具有中间点路径的三次多项式,还是4个约束条件,但是初始关节速度与终止关节速度不一定为0,为了保证平滑要与分别与前一段的速度和后一段的速度相等(第一段(A->B)的终点速度,必须严格等于第二段(B->C)的起点速度)
确定每个中间点的瞬时期望速度,也有三种方法 (1)根据工具坐标系的笛卡尔线速度和角速度确定每个中间点的瞬时期望速度。利用在中间点上计算出的操作臂的雅克比逆矩阵,把中间点的笛卡尔期望速度“映射”为期望的关节速度。(若某中间点位于奇异位置,则无法在此处指定任意速度。) (2)在笛卡尔空间或关节空间使用适当的启发式方法,系统自动选取中间点速度。(3)采用使中间点处的加速度连续的方法,系统自动选取中间点速度。根据中间点处的加速度为连续的原则选取各点的速度。在这种样条曲线中设置一组数据,在两条三次曲线的连接处,用速度和加速度均为连续的约束条件替换两个速度约束条件。
高阶多项式如5阶,加入约束另外的2个约束:规定起始点和终止点的加速度
抛物线过渡的线性插值,
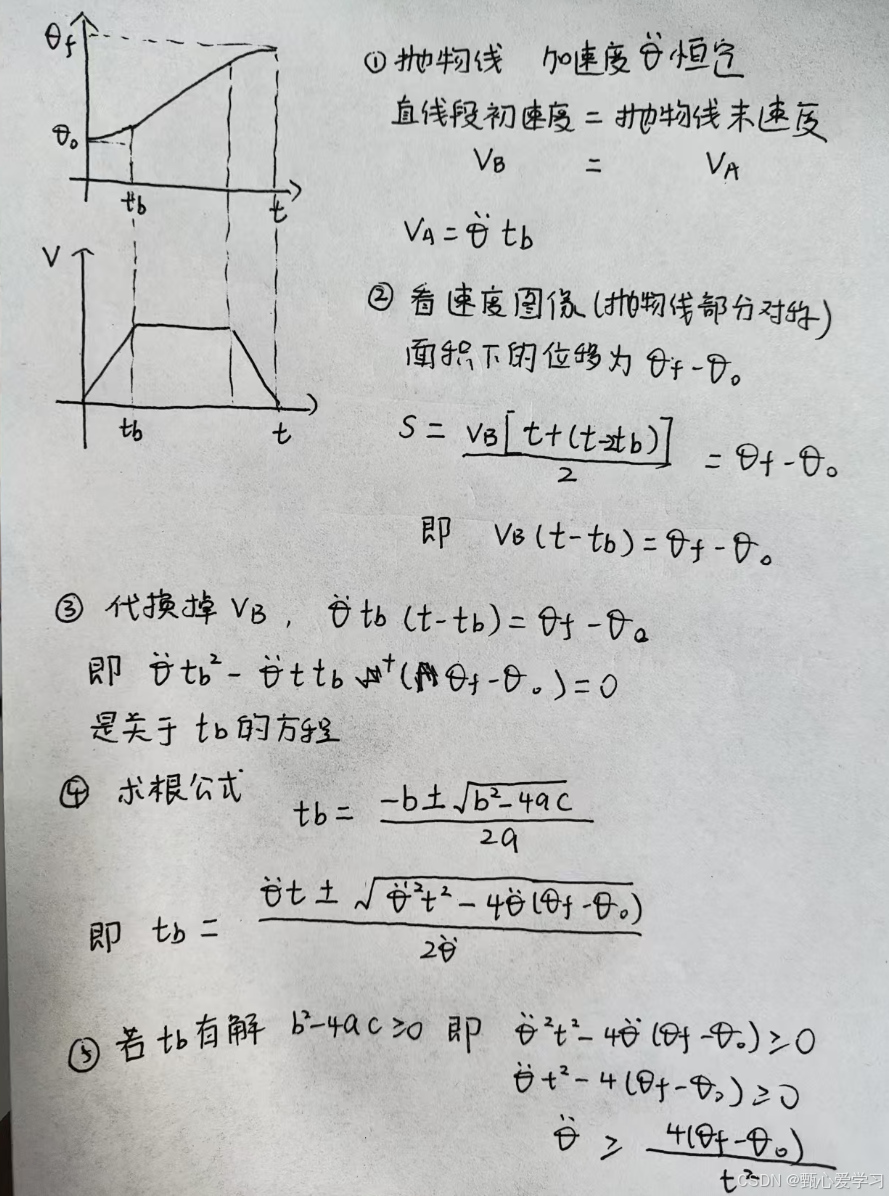
加速度的约束:这里的约束可以理解为,给定时间和距离的情况下,加速度要足够大

具有中间点路径与抛物线拟合的线性函数



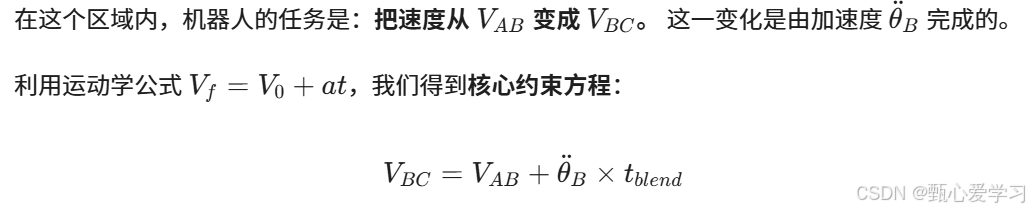

笛卡尔空间规划的几何问题:无法到达中间点;在奇异点附近关节速度增大;起始点和终止点有不同的解
轨迹的定义常用描述方法(考试题):
轨迹是路径 (Path) 与时间律 (Time Law) 的结合。
-
路径只描述机器人位姿在空间中的几何曲线(走什么路线);
-
轨迹则是明确了机器人在每一个时间点具体处于路径的哪个位置,包含位置、速度和加速度随时间变化的历史。


8 强化学习
强化学习与监督学习/非监督学习的区别:(1)没有监督者,只有奖励信号 (2)反馈是延迟的,不是顺时的 (3)时序性强,不适用于独立分布的数据 (4)自治智能体(agent)的行为会影响后续信息的接收
马尔科夫性:所谓马尔科夫性是指系统的下一个状态s(t+1)仅与当前状态s(t)有关,而与以前的状态无关

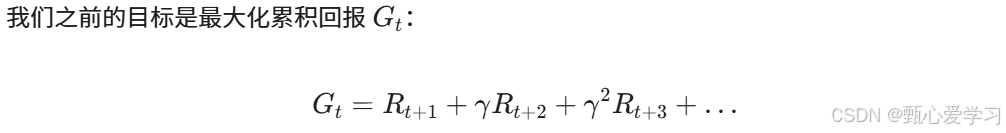
价值V是G的期望值
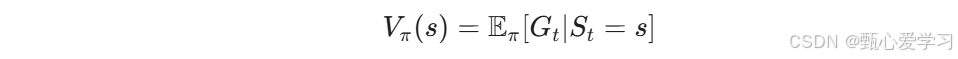
贝尔曼方程

什么是强化学习?
强化学习就是agent(又称智能系统或智能体)通过与环境的交互学习一个从环境状态到行为映射,学习的目标是使其累积折扣回报值最大。
传统的强化学习依赖于组合人工特征和线性价值函数(value function)或策略表达来实现。
什么是什么深度强化学习?
结合深度学习的感知能力和强化学习的决策能力,直接从高维原始数据学习控制策略。
马尔可夫决策过程的五个元素

Q-learning算法
(也是传统方法)离线学习,维护一个Q表

用贪婪策略,最大化动作a';自举:用一个(未来的)估计值来更新另一个(当前的)估计值
DQN

用神经网络代替表格
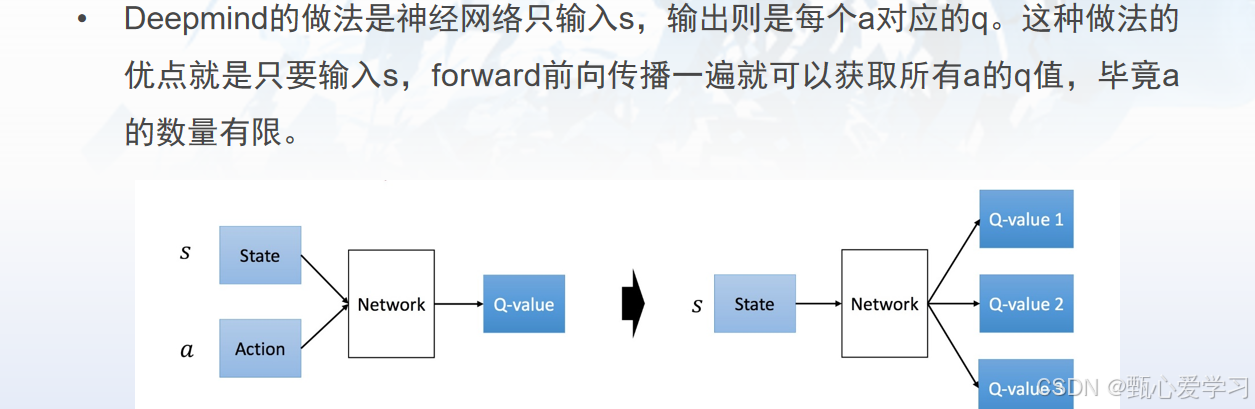
经验回放:建立一个记忆库,放入机器人的每一步(st,at,rt,st+1),训练的时候,从库力随机抽取一批数据来训练
目标网络:提供目标值,很久才更新一次(把当前网络(实时更新参数)复制给它)
基于策略的方法:训练一个神经网络(策略网络 Policy Network),输入状态 s,直接输出动作 a 的概率分布或具体数值

控制抓取算法设计:
(1)明确任务,确定输入输出(状态、动作)(2)制定奖赏规则(3)更新Q值函数(4)制定动作策略,平衡探索与利用
编写程序->训练->应用

强化学习的流程?一个不断的试错过程:

动目标抓捕:机器人不断根据看到的球的位置(S),调整自己的速度和手爪(A),通过获得的距离反馈(R)来优化控制策略,最终学会如何最快地抓住球
AlphaGO:AlphaGo 观察当前棋局(S),通过策略网络和价值网络计算出胜率最高的落子点(A),环境(对手)落子后进入下一局面(S'),最终通过整盘棋的胜负(R)来更新网络参数。这里的R为延迟奖励,因为只有下完这篇棋才知道赢没赢。

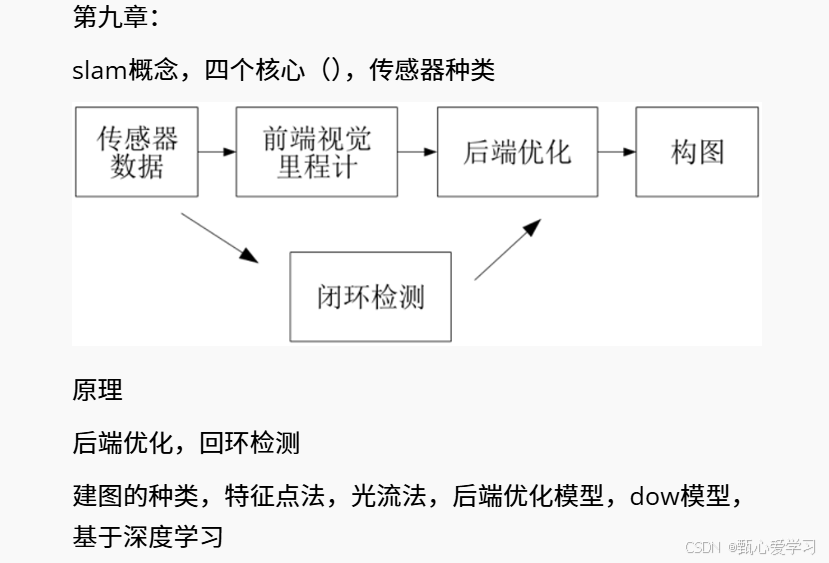
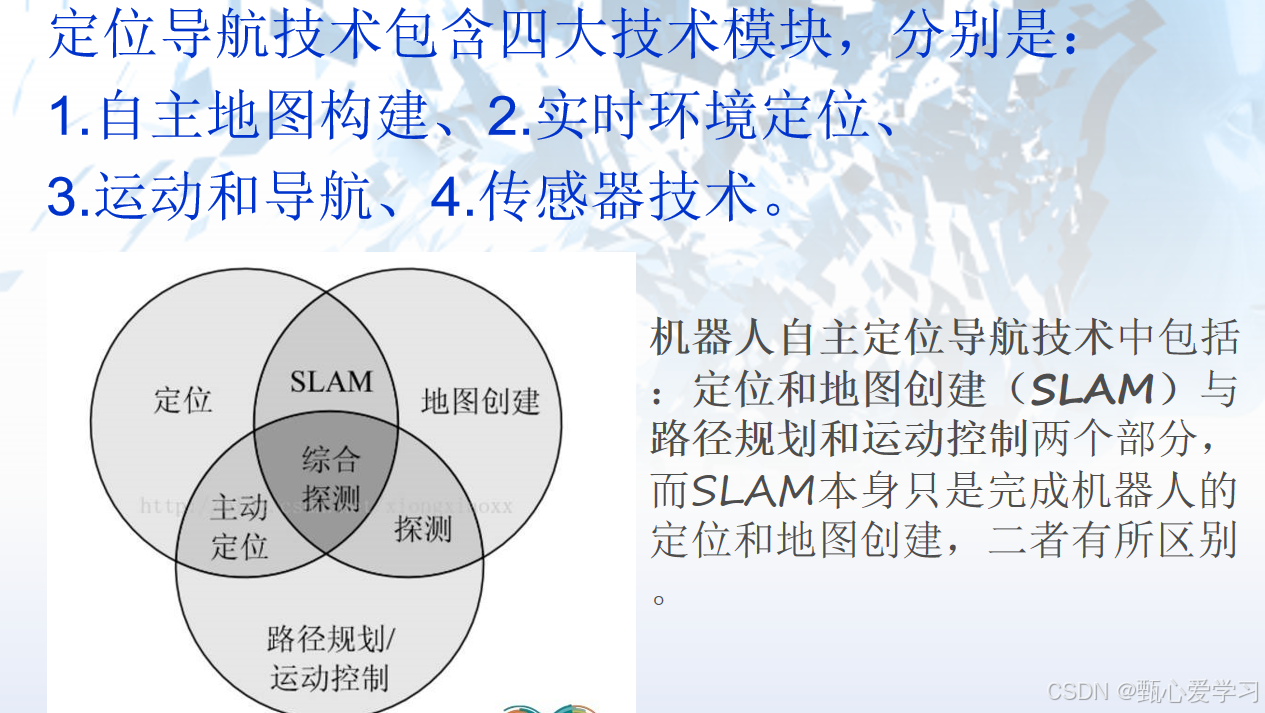
9 slam
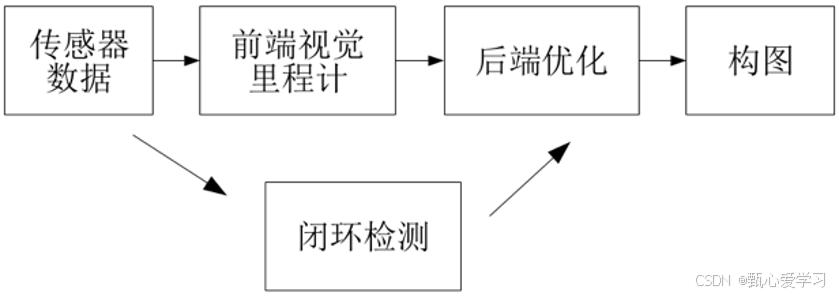
经典的vSLAM系统一般包含前端视觉里程计、 后端优化、 闭环检测和构图四个主要部分
两类传感器 1.安装于环境中的: 二维码 Marker/ GPS/ 导轨/磁条 2.携带于机器人本体上的 IMU /激光/ 相机(视觉传感器)
相机分为单目、双目(能测深度)、RGBD
1.前端视觉里程计
相邻图像估计相机运动,通过两张图像计算运动和结构
基于特征的方法:提取图像中的特征,常用点特征,如Harris角点、SIFT、SURF、ORB
(提取关键点,计算描述子,匹配,求解相机运动,通常最小化重投影误差)
直接法:把图像中所有像素写进一个位姿估计方程,求出帧间相对运动
(光流:它不提特征,直接利用像素的灰度值信息。 基于灰度不变假设)
2.后端优化
从带有噪声的数据中优化轨迹和地图 状态估计问题 最大后验概率估计 MAP 前期以EKF为代表,现在以图优化为代表(BA算法)
3.回环检测
是指机器人识别曾到达场景的能力
识别到达过的场景 计算图像间的相似性 方法:词袋模型BOW
4.建图
根据估计的轨迹建立与任务要求对应的地图
RGB-D进行稠密建图
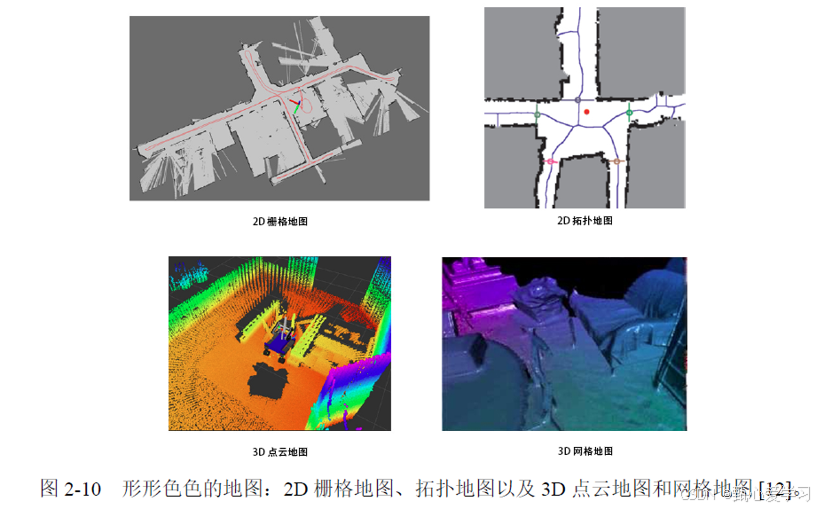
地图的表示:栅格地图、直接表征法、拓扑地图以及特征点地图这4种
BOW方法:

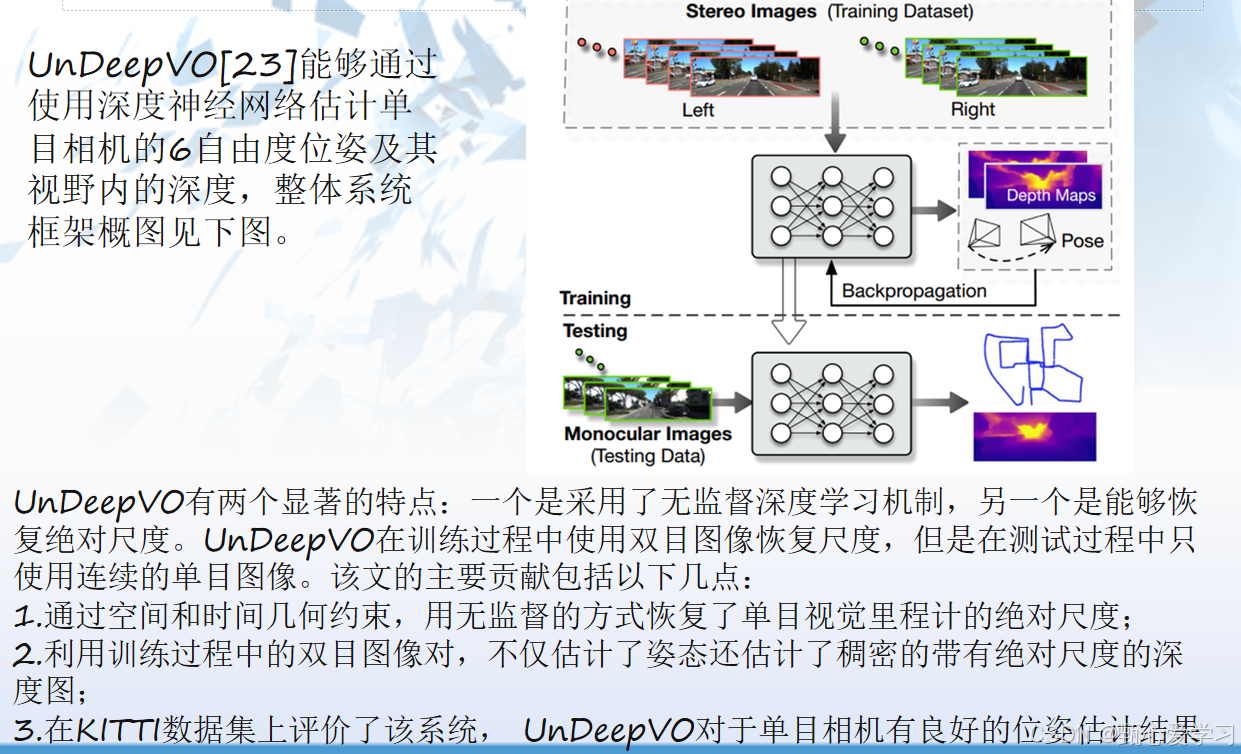
深度学习方法:LIFT,UNDeepVO
10 路径规划
路径规划分类:

路径规划方法:

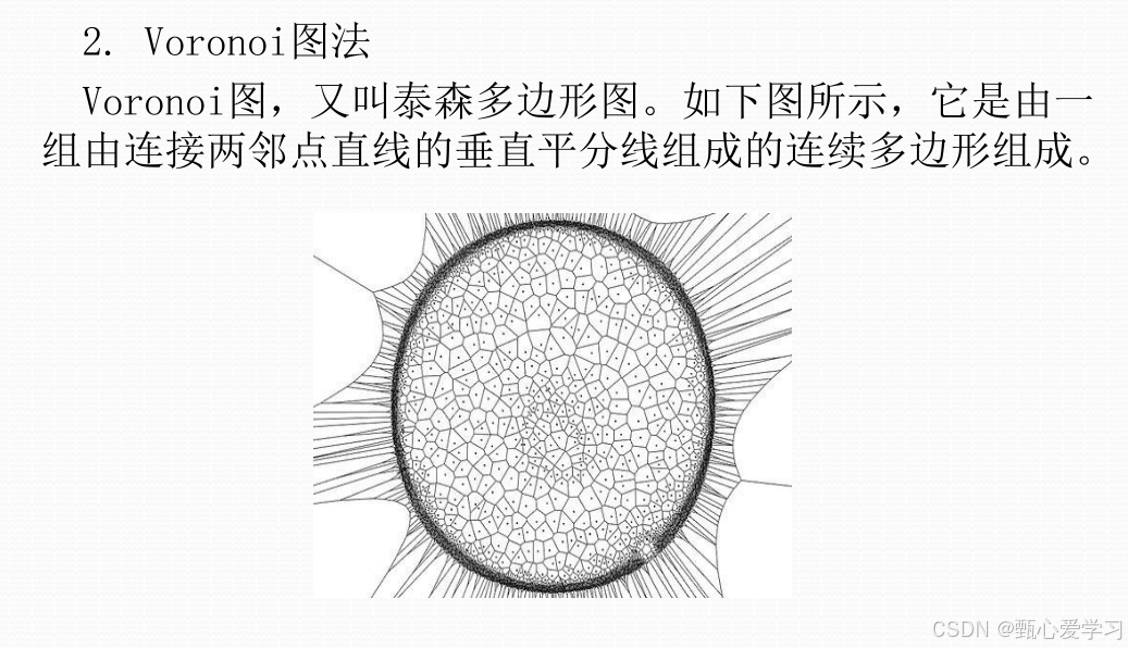



5.A*算法




栅格法
把连续的物理空间问题,转化为离散的图论问题




11 语音识别
(盲猜只考选择)
语音识别定义:利用数字信号处理与模式识别方法,自动从语音信号中提取最基本、最有意义的信息,并将其转换为对应的文字或符号序列的技术。

分类:

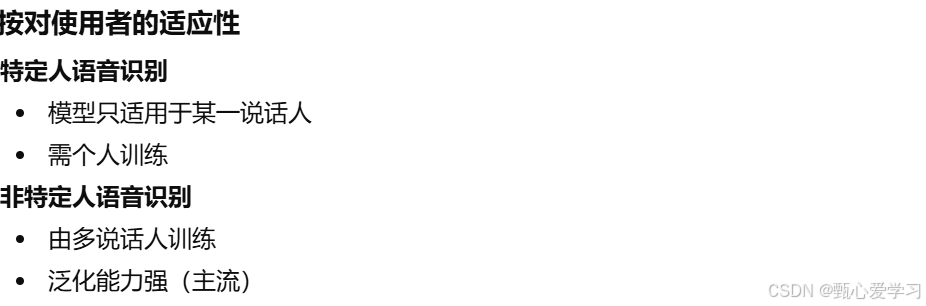

语音识别的实现
声学模型:把语音转化为声学表示的输出,即找到给定的语音源于某个声学符号的概率
语言模型:直接从声学特征输入可以得到识别的词序列,代表为CTC模型(还有Transformer等)

语音识别难点:
-
连续语音边界不清晰
-
协同发音导致音素不稳定
-
个体差异与环境噪声
-
自然语言本身复杂多变

习题
2 位姿
习题1:齐次变换

解答:
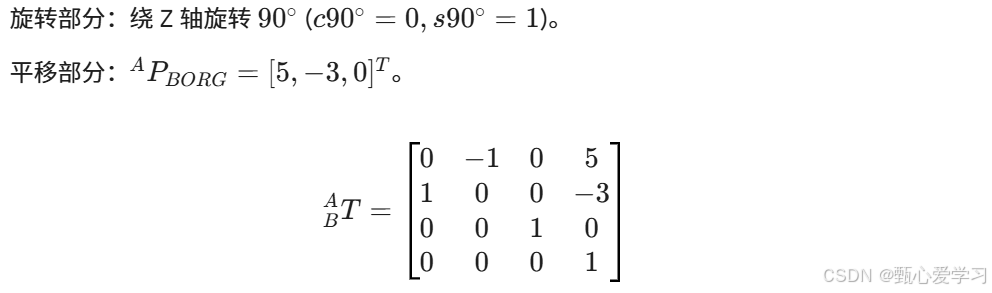
注意第二问中,B坐标要增广为[1,2,0,1]T
第三问就是求逆矩阵
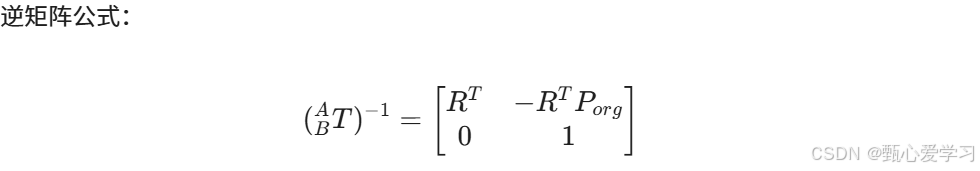

在 B系看,A 的原点确实在 B 的正 X 轴方向 3 单位,正 Y 轴方向 5 单位处
习题2:复合变换

注意平移矩阵在对角上要填上1



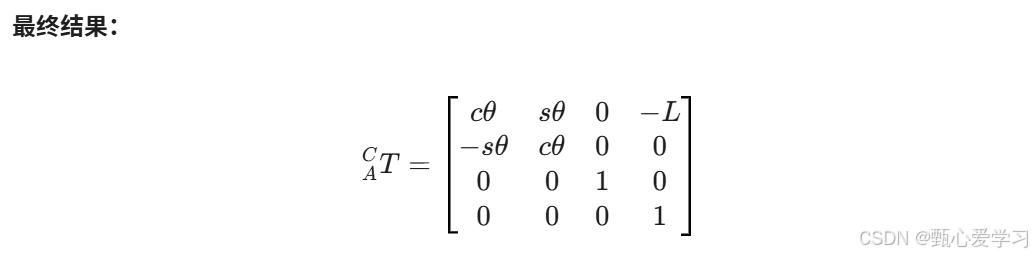
区分左乘与右乘

(之前的定义的混合的齐次坐标,默认是自身坐标系,先旋转后平移)
3 运动学(正)
(盲猜这部分不考具体的连杆变换)
可能会考4个连杆参数的描述?或是给图写出参数?
5 速度与静力
(盲猜不考)





6 操作臂动力学
长方体
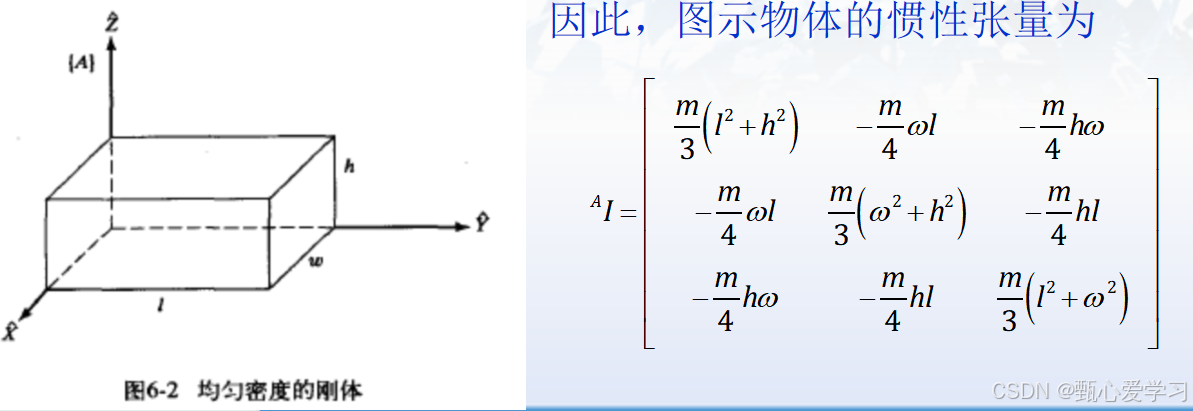
若原点在质心
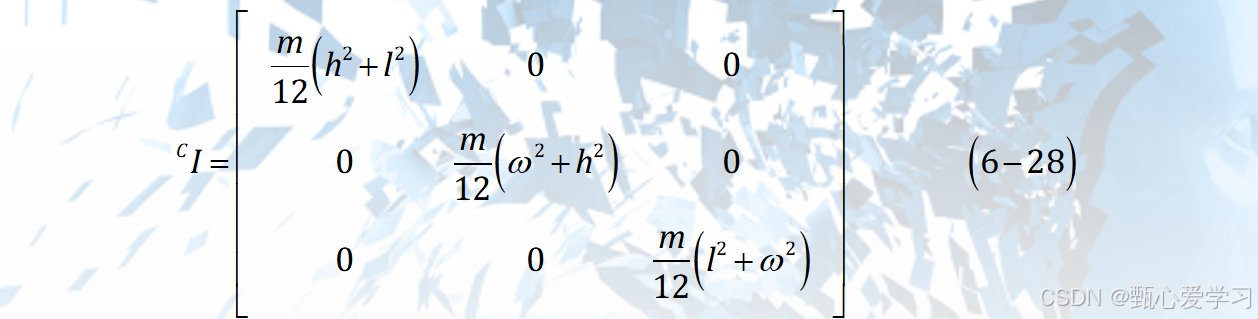
圆柱体

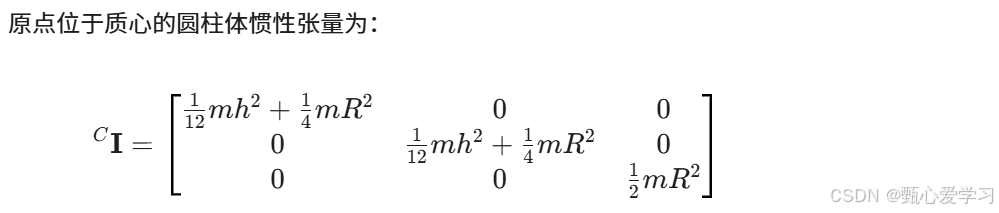
对于前两项,若圆柱体的半径R为无穷小,退化为杆
杆
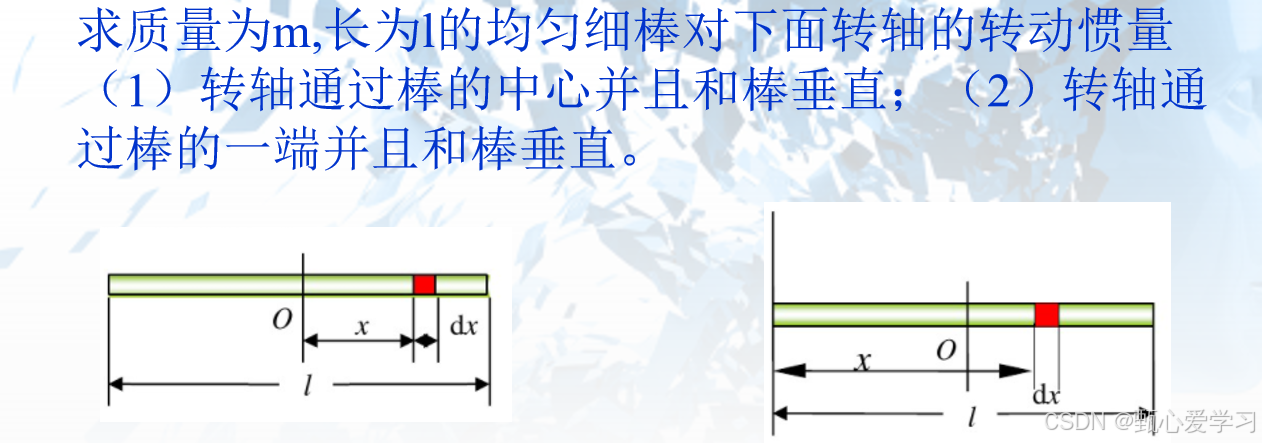

(2)在棒的一端时:
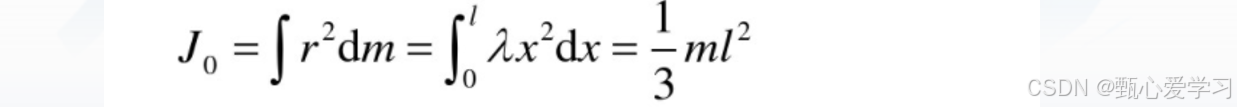
对于之前的惯性张量公式,也可以理解为对质量进行的积分:dm = ρdV
之前的 也可以看作是
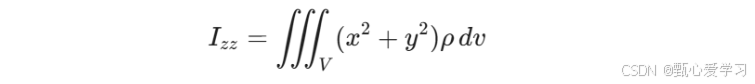
圆管(原点在质心)

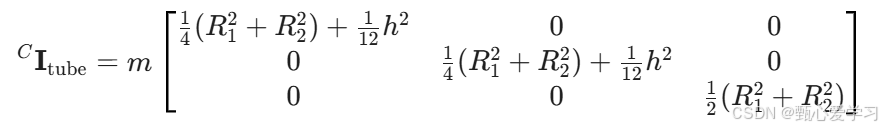
球体
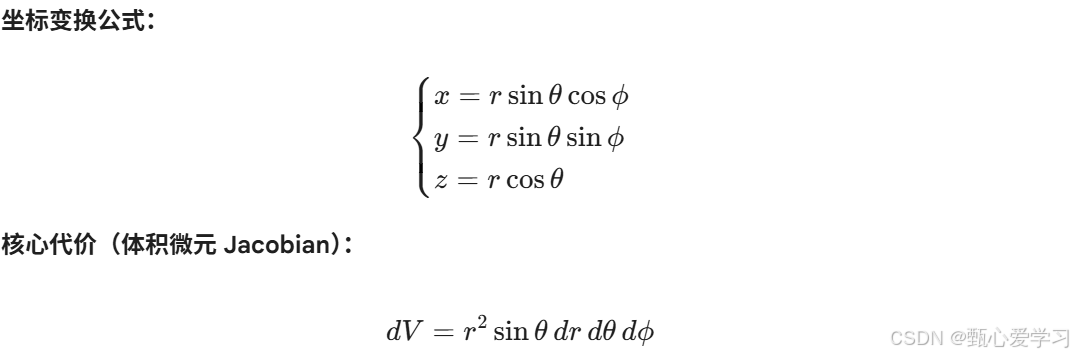
7 轨迹

一些细节
3 正运动学

教材中用的改进版D-H

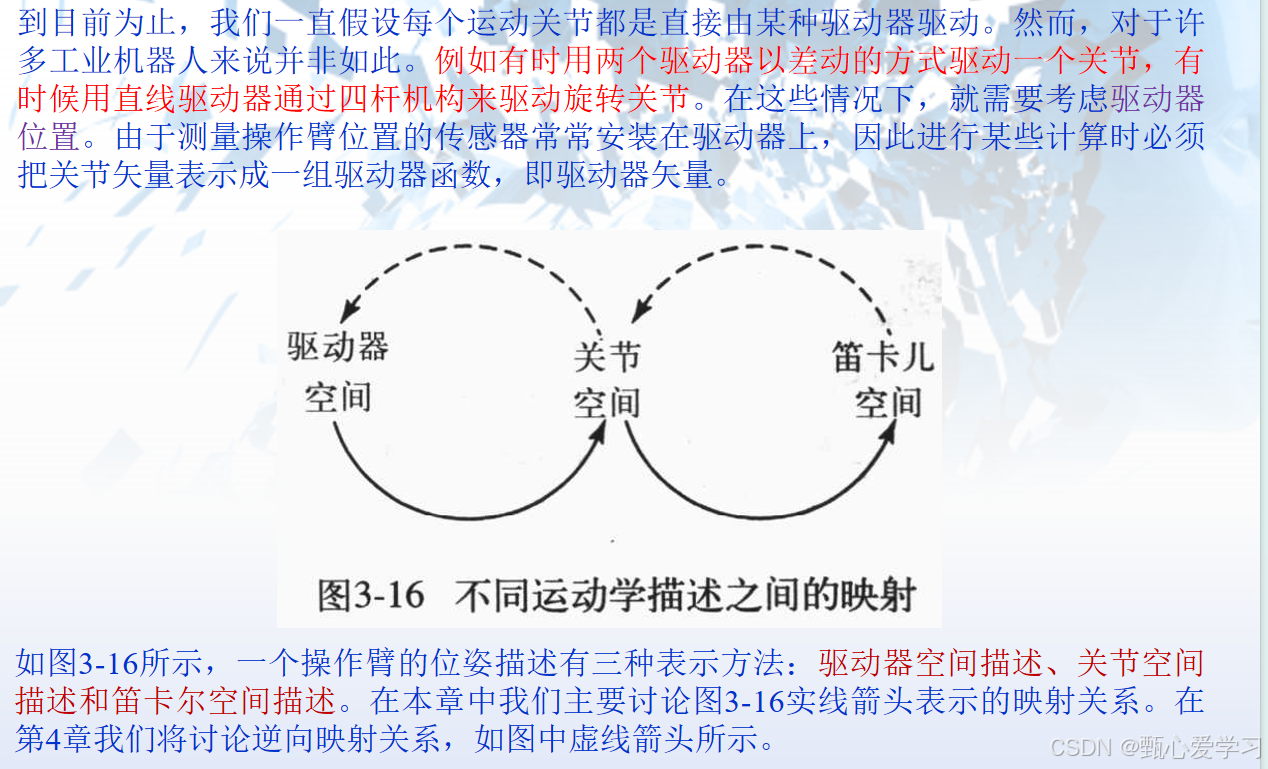
4 逆运动学



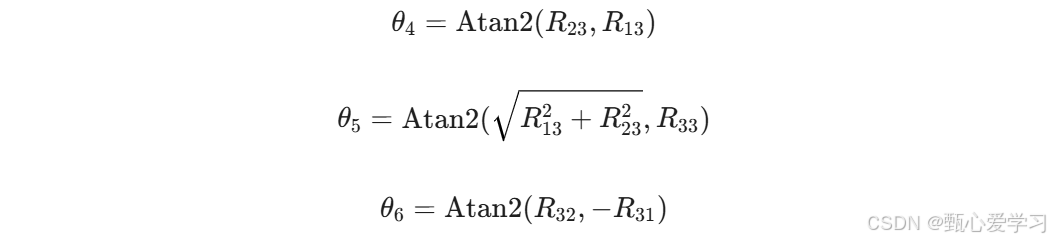
5 速度与静力
v的表示

角速度的表示
平移旋转的组合公式
v只有平移

v只有旋转

v有旋转与平移

若为刚体上一点,即相对于坐标系B是静止的,,公式变为:

理解



雅可比矩阵推导









力的递推公式推导




力的雅可比矩阵推导



根据力的雅可比矩阵理解奇异位形

反过来的话,需要先转置后求逆
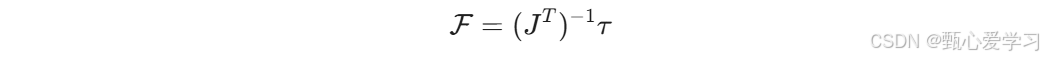
6 操作臂动力学
转动惯量理解


求解积分时的小技巧:



拉格朗日

操作臂动力学方程结构


8 强化学习
区分:马尔可夫过程/马尔可夫奖励过程/马尔可夫决策过程



9 slam


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)