6B 也能打!Z-Image-Turbo 部署指南:速度、质量双在线
阿里巴巴通义实验室开源轻量级AI生图模型Z-Image-Turbo,仅6B参数却实现20B级模型的性能。该模型采用创新的S3-DiT单流架构,将文本、语义和图像信息统一处理,解决了传统双流架构的算力浪费问题。在4090/A100显卡上,1080P图3秒生成,4K图15秒完成,显存占用降低40%。模型还具备92%的中文理解率和稳定的极速采样能力,兼容主流框架并采用Apache2.0开源许可。教程详细
前言
2025 年的 AI 生图赛道卷到极致!海外巨头 Flux 2 即便搭配 32G 显存,生成一张高清图依旧需要漫长等待,创作者的时间成本被不断吞噬——难道高端显卡的性能,只能被庞大臃肿的模型“拖慢脚步”吗?
答案是:绝不!
2025 年 11 月下旬,阿里巴巴通义实验室低调开源 Z-Image-Turbo,直接让专业算力“解锁核动力模式”。这款仅 6B 参数的轻量级旗舰,凭借独创架构硬刚 20B 级别模型;在 Bitahub 的 4090 / A100 专业显卡加持下,1080P 高清图最快 3 秒生成,4K 大图也能在 15 秒内落地,彻底打破“模型越大,速度越慢”的行业魔咒。
Z-Image-Turbo 之所以能做到“小模型大爆发”,核心来自其创新性的 S3-DiT 单流扩散 Transformer 架构:
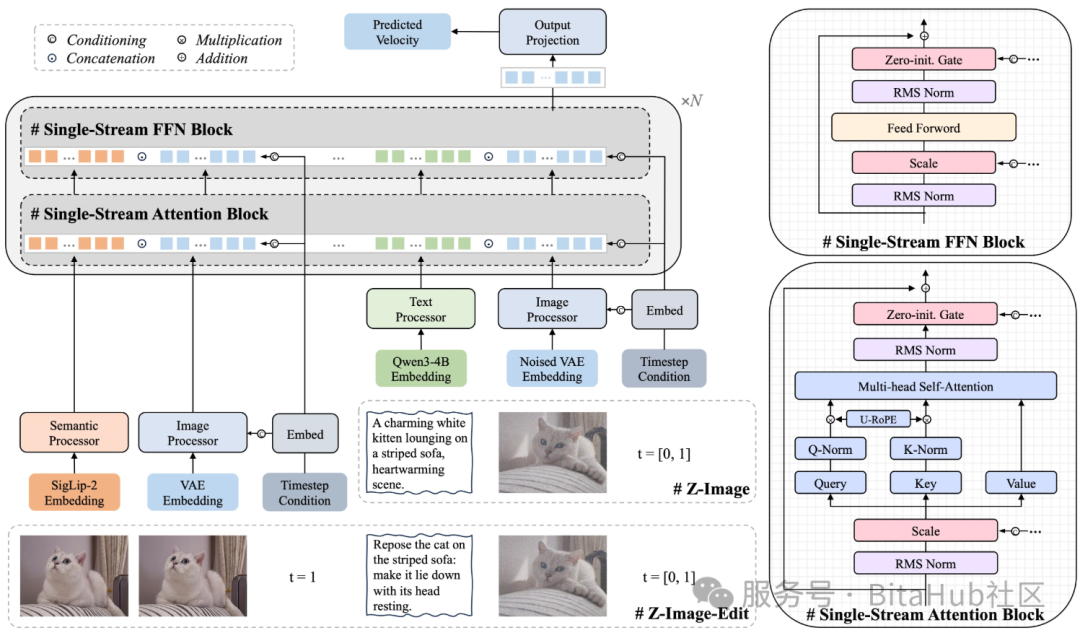
来源:https://arxiv.org/pdf/2511.22699
它将文本指令、语义嵌入、图像 latent 统一到同一条“信息生产线”中,彻底解决传统双流架构中信息割裂、算力利用率低的问题,让 6B 参数实现近乎极限的性能释放。实际效果上,其细节建模能力直逼 20B 级旗舰,同时显存占用降低 40% 以上——在 4090/A100 上不仅能高速生成,还能轻松支持批量渲染、多任务并行,整体效率直接翻倍。
更强的是,Z-Image-Turbo 还引入 DMD 解耦蒸馏 与 DMDR 强化学习奖励模型 两大关键技术,使模型在8 步极速采样下依旧保持稳定高画质;搭配 Qwen 中文底座,中文指令理解率高达 92%。不论是“赛博朋克风故宫夜景”,还是复杂的商业级海报,模型都能准确还原语义、保持细节清晰,彻底告别“中文崩坏”“细节糊化”等老问题。
更令人惊喜的是,它采用 Apache 2.0 开源许可,可完全商用;兼容 ComfyUI/Diffusers 全链路,Hugging Face 访问峰值超过 10 万,稳坐轻量化文生图模型的头部阵营,被不少专业创作者称为真正的“效率神器”。
如果你正拥有 Bitahub 的 4090/A100 高端算力,却苦于没有能充分释放性能的生图模型;如果你想摆脱漫长渲染,让高清创作进入“秒出图”时代;如果你需要在商业项目中实现高质量、高效率交付,那这篇教程一定不能错过。
接下来,我们将带你 手把手在 Bitahub 上部署 Z-Image-Turbo,让高端算力与轻量旗舰模型完美组合,彻底点燃你的创作生产力!
一.准备工作
1.ComfyUI准备
克隆 ComfyUI到本地
git clone https://github.com/comfyanonymous/ComfyUI.git打开BitaHub工作台,将ComfyUI代码仓库上传至文件存储。
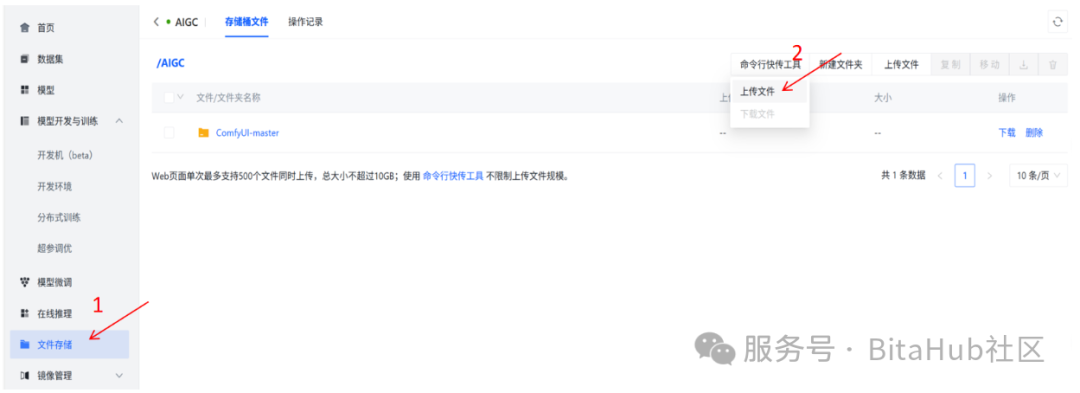
2.下载模型文件
进入 BitaHub 官方网站模型库,搜索:Z-Image-Turbo,将下图中的模型转存到云端并移动至刚刚创建的 ComfyUI 项目对应的文件夹中
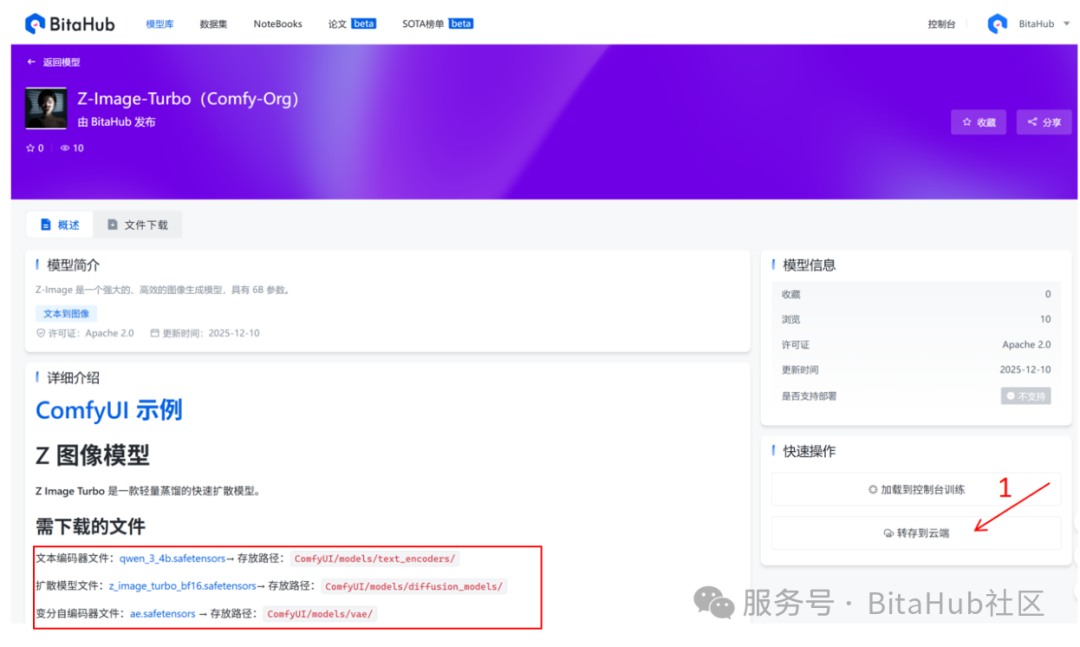
其中: (1)z_image_turbo_bf16.safetensors
👉 Z-Image-Turbo 的核心扩散模型权重(Diffusion Transformer)
-
包含 S3-DiT 主体结构:Transformer Block、Cross-Attention、时间步嵌入、残差卷积等。
-
用于执行噪声预测、扩散反推、图像 token 生成等主要文生图步骤。
-
数据类型为 bf16,兼顾速度与显存占用,是整个生成流程的“大脑”。
一句话总结:负责从文本语义到图像潜空间的生成,是最核心的生图权重。
(2)qwen_3_4b.safetensors
👉 文本编码器(Text Encoder)权重,基于 Qwen_3_4B
-
用于处理 Prompt 文本,将自然语言转成语义 Token 序列。
-
输出将作为输入序列的一部分,与图像 Token 一起进入 S3-DiT 单流架构。
-
决定文本理解能力、指令对齐能力以及“提示词风格响应能力”。
一句话总结:负责把输入的 Prompt 变成模型能理解的语义信息。
(3)ae.safetensors
👉 图像自编码器(AutoEncoder,VAE / AE)权重
-
在推理后阶段,将扩散模型生成的潜空间图像 Token 解码成真正的 RGB 图。
-
控制图像细节复原程度、纹理质量、色彩一致性。
-
Z-Image-Turbo 使用轻量化、高压缩率的 AE,配合高效 Transformer 推理。
一句话总结:负责把生成的“潜空间图”还原成最终可见的高质量图像。
3.创建开发环境
将上述准备好的 ComfyUI 文件夹挂载到 BitaHub 开发机任务的的文件存储中。此外,我们还需要定义容器端口,BitaHub 平台通过自定义容器端口功能,让外部能发 HTTP 请求到容器服务(如 ComfyUI),实现开发验证(功能调试、接口测试等 )。ComfyUI 默认情况下使用端口号 8188 进行访问。
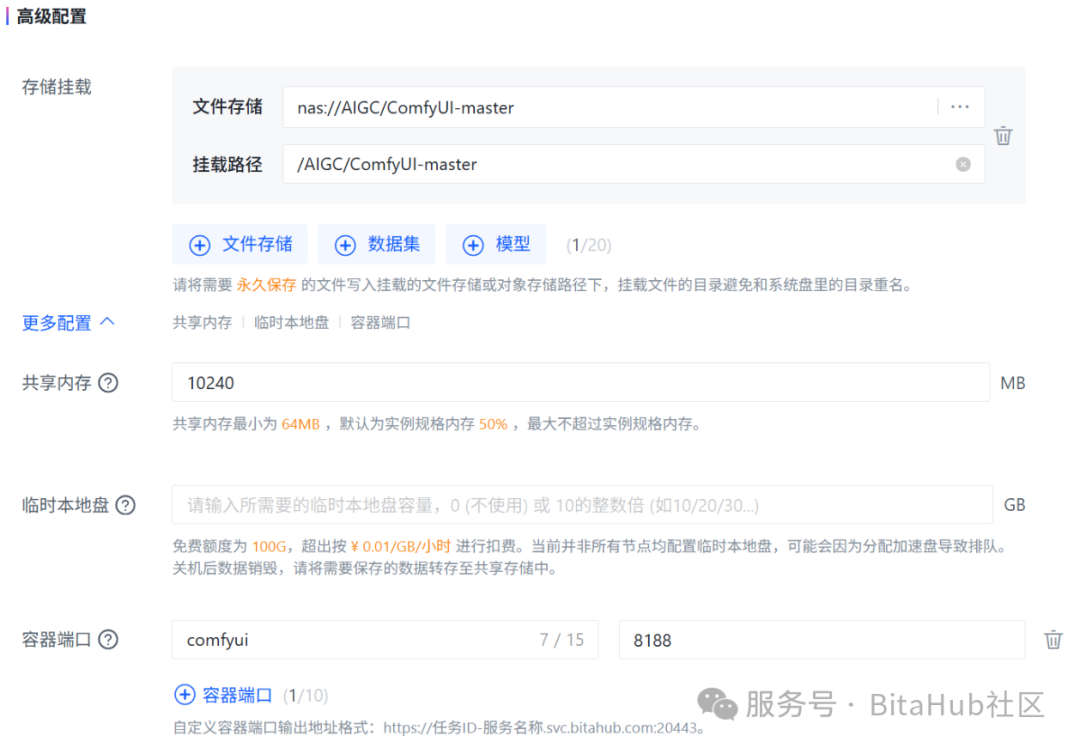
最后,选择单卡4090 GPU,并通过JupyterLab访问方式进入开发环境。
二.环境配置
1.打开终端,通过venv创建虚拟环境→激活环境→进入项目目录→安装依赖这一系列操作为 ComfyUI 搭建起独立运行环境。(/AIGC/ComfyUI-master 是示例路径,实际要替换成你 ComfyUI 代码所在的真实路径)
python3 -m venv comfy_env
source comfy_env/bin/activate
cd /AIGC/ComfyUI-master
pip install -r requirements.txt2.运行 ComfyUI 服务,在项目根目录下执行以下命令启动:
python main.py --listen 0.0.0.0 --port 8188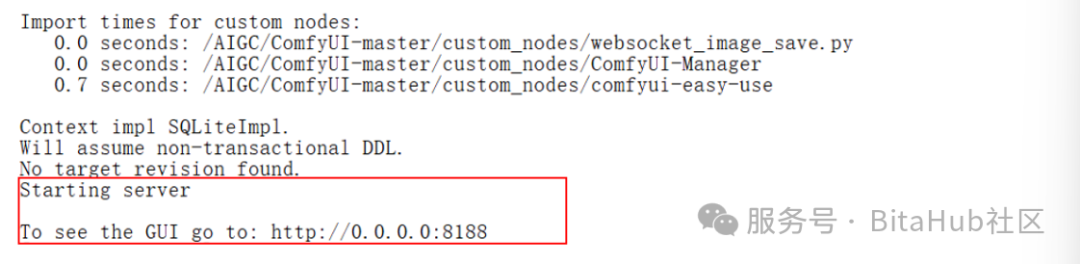
当日志输出上图红框中的信息说明你已成功部署 ComfyUI 并启动服务。
3.随后回到开发机,复制完整的地址并用浏览器打开即可看到 ComfyUI Web 界面。

三.ComfyUI 工作流配置
1.加载扩散模型
在 UNet 加载器(Load Diffusion Model) 节点中,选择并加载:z_image_turbo_bf16.safetensors
2.加载文本编码器
在 加载 CLIP(Load CLIP) 节点中,确保以下模型正确加载:qwen_3_4b.safetensors
3.加载 VAE 模型
在 Load VAE 节点中,选择:ae.safetensors
4.设置图像尺寸
在 空 Latent(SD3) 节点中,设置图像生成尺寸
5.编辑提示词
在 CLIP Text Encode 节点中填写你的提示词(Prompt)。⚠️ 当前模型支持中文提示词,你可以直接输入自然且详细的中文描述。
6.运行工作流
检查所有节点连接无误后,点击顶部的 运行(Run)按钮即可生成图像。
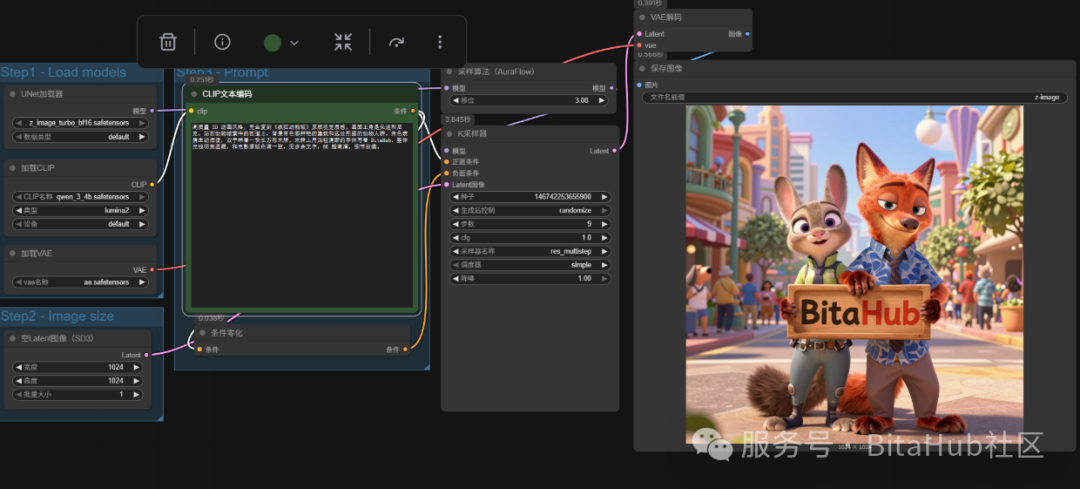
若效果不满意,你也可以通过调整 prompt、改采样参数等方式进行调整。
四.总结
通过本次教程,我们在 BitaHub 上完成了 Z-Image-Turbo 的完整部署流程,并了解了其核心架构、关键权重文件及模型在轻量化扩散领域的优势。得益于 S3-DiT 单流结构和高效推理设计,Z-Image-Turbo 在仅 6B 参数下依旧具备接近大模型的生成质量,同时显存需求友好、响应速度快,十分适合作为科研实验与工程应用的基础模型。希望本教程能够帮助你更快搭建属于自己的高效文生图平台,未来也欢迎你基于此模型探索微调、控制生成等更多可能性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)