超越 Bloomberg、LSEG 的 API 与 MCP:为什么金融数据需要一个多智能体的未来
金融数据领域的多视角困境与智能体协同的未来 本文揭示了金融数据领域存在的结构性矛盾:用户、开发者和数据供应商各自看到的是完全不同的图景。作者通过自身作为数据使用者、开发者和金融数据公司员工的三重经历,指出熟悉感正在替代真正的数据可见性,导致决策局限在狭窄但熟悉的视野中。 文章提出真正的多智能体解决方案应建立在三个关键认知上: 每个智能体天生不完整,仅代表其所有者的专长和利益 用户智能体与供应商智能
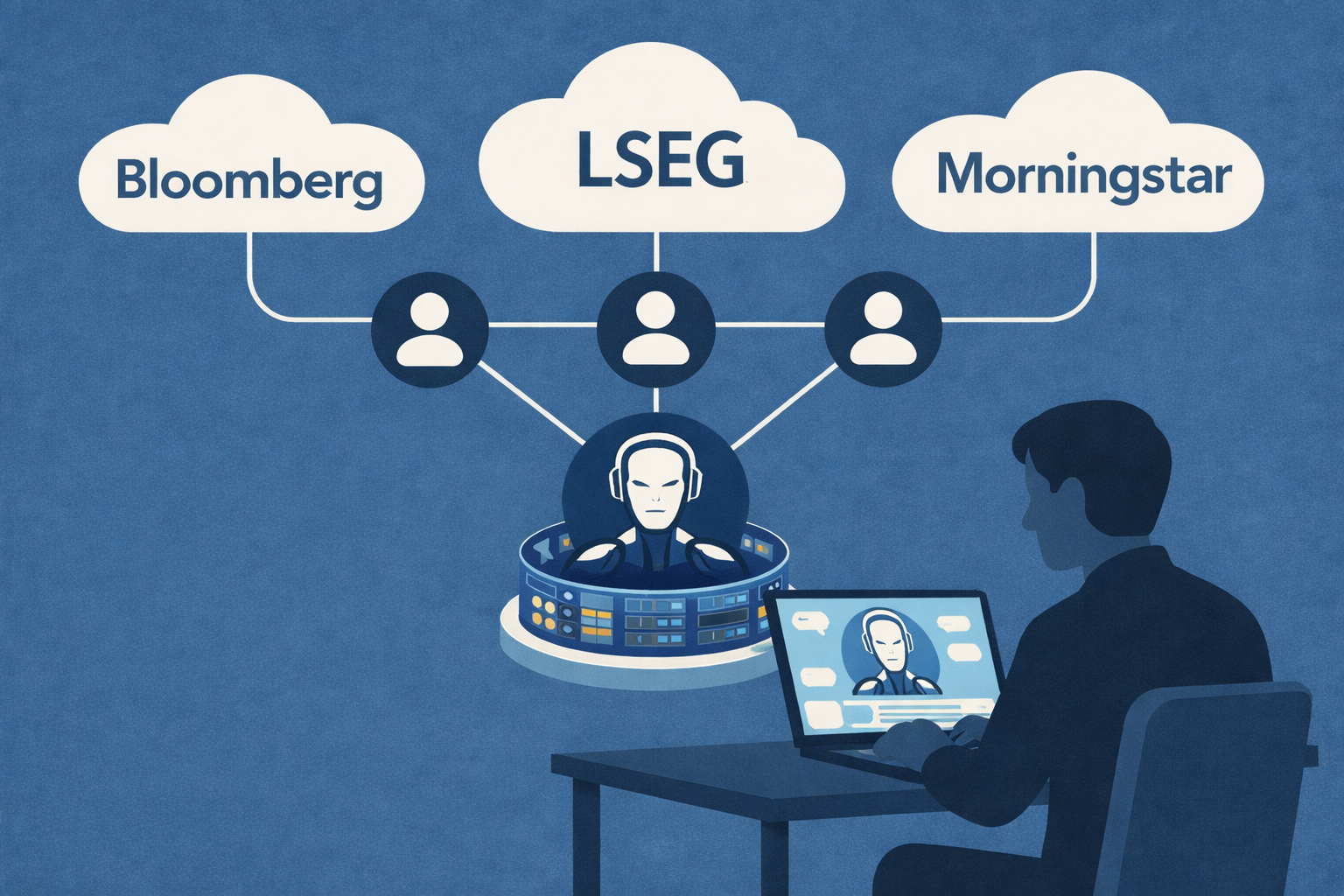
我从金融数据的所有角度走过一遍。
我当过数据使用者,在真实约束下依赖数据做决策;
我当过开发者,对接 API、构建系统,亲身感受抽象在现实中是如何“漏水”的;
我也曾是世界级金融数据公司的员工,看到数据在进入终端或 API 之前,是如何被生产、校验、限制和保护的。
每一个角色教会我的东西都不同,但它们最终指向同一个不太舒服的事实:
用户以为自己看到的、开发者以为自己暴露的、以及数据供应商真正管理的,从来都不是同一幅图景。
很长一段时间里,我以为熟练掌握一个平台,就等于理解了市场。
我知道快捷键,知道该信哪些数据,也知道当数字被质疑时该如何为它们辩护。久而久之,这种熟悉感被误认为是能力,甚至是一种掌控感。
但我后来才意识到:
熟悉,正在悄悄取代“可见性”。
在我之前的文章《Bloomberg、LSEG 与 MCP 缺口:为什么尚未发布完整的 MCP 服务器,以及多智能体系统如何解決这问题》中,我分析了为什么像 Bloomberg、LSEG 这样最强大的金融数据供应商,依然不会通过 MCP 或无限制 API 暴露“一切”。
原因并不是技术犹豫,也不是野心不足。
而是一个结构性现实:
不存在一个接口,可以同时代表所有人的利益。
这篇文章沿着这个思路继续往前走,但更进一步:
即便 MCP 是完美的,即便 API 没有任何限制,核心问题依然存在——
没有任何一个智能体,能够看到完整的全貌。
熟悉数据背后的“隐形边界”

大多数金融数据用户,并不是在整个数据宇宙中做选择。
他们只是在自己能看到的范围内选择。
而“能看到什么”,通常由授权、系统集成、内部流程和组织习惯决定。时间一久,这些边界会变得非常牢固。边界之外,也许有更便宜的、更准确的、或者更适合某个特定用途的数据,但它们之所以不存在于决策中,只是因为——不熟悉。
这通常不是有意为之,而是结构性的结果。
而且因为现有工具“还能用”,这种缺失并不会被感知为问题,反而被当成经验。
用户并不是完全看不见,他们只是半盲——在一个狭窄但熟悉的视野中自信前行,却不知道外面还有多少世界。
智能体代表的是利益,而不是全知

一个真正的多智能体未来,必须从一个并不舒服的前提出发:
每一个智能体,天生都是不完整的。
不存在“主智能体”,也不存在一个中立的、能看到一切的观察者。
每一个智能体,都只代表其创建者的最佳利益和最深专长——仅此而已。
用户侧的智能体,理解的是意图。
它知道用户想解决什么问题,哪些取舍是可以接受的,哪些风险是关键的。它并不假装理解整个数据世界,也不需要这样做。它的职责,是把“目的”表达清楚。
数据供应商侧的智能体,理解的是数据本身。
它知道方法论、覆盖盲区、延迟、不确定性和历史弱点,也知道自己的数据在什么情况下不该被使用。它不会揣测用户的目标,它的职责,是如实说明数据的能力和边界。
没有哪一个更高级。
也没有哪一个更完整。
这种对等关系不是缺陷,而是基础。
这并不是今天所谓的“Agentic AI”

今天大多数所谓的“Agentic AI”,都构建在单一平台之内,由单一公司拥有,并被单一激励结构塑造。
它们或许看起来模块化、灵活,也能高效编排工具、自动化流程,但本质上,它们始终只在用一个声音说话。
它们擅长执行,却不擅长协商。
因为在系统结构中,并不存在真正独立的利益方。
所谓的多视角,更多是一种模拟。
真正的多智能体系统,恰恰相反。
它从一开始就承认:没有任何智能体能看到全局,也不该假装能看到。
智能并非来自集中,而是来自多个有偏见、有立场、有局限的视角之间的协调。
当智能体开始直接对话

当用户智能体可以直接与多个供应商智能体对话时,决策的性质会发生变化。
同一个问题,会得到不同的回答、不同的限制条件、不同的不确定性表达。分歧不再被隐藏或平均掉,而是被明确呈现出来。
用户拿到的不再是一个“标准答案”,而是一种态势感知。
他们开始看到地形,而不是一张被精修过的地图。
在那一刻,继续使用某个熟悉的供应商,才真正变成了一个主动选择,而不是路径依赖。
经纪(Broker)智能体:可选,但有价值

在多智能体系统中,经纪智能体并不是必需的。
用户智能体和供应商智能体本身,就已经可以直接交流、交换上下文、暴露分歧。
即便如此,这也已经比今天的单平台模式前进了一大步。
但现实中还有一个更隐蔽的限制:
用户只能探索他们知道“存在”的东西。
用户智能体天然锚定在具体应用场景中,
供应商智能体天然专注于解释自己的数据,
但几乎没有任何一方,会主动退后一步,展示整个选择空间。
经纪智能体的价值,就在这里。
它并不忠于某个数据集,也不服务于某个具体应用,而是专注于比较与发现。通过长期观察多个用户与多个供应商的互动,它可以揭示那些平时很难看到的信息:哪些数据集其实高度重叠,哪些区域性供应商在特定细分市场里长期优于全球巨头,方法论的变化如何影响下游模型,以及成本、延迟和覆盖率在现实中的真实取舍。
经纪智能体不做决策,也不替用户下结论。
它的作用,是扩大视野,而不是收窄选择。
最终判断,仍然掌握在用户智能体手中,并通过与供应商智能体的直接对话来完成。
和系统中的其他智能体一样,经纪智能体也代表其开发者的视角与激励。它不是中立的,也不是完美的,但正因为它专注于“让不可见变得可见”,才显得有价值。
MCP 的位置:重要,但不是银弹
MCP 很重要。
它提升了互操作性,降低了摩擦,也标准化了接入方式。
但 MCP 仍然隐含着一个假设:暴露,等于理解。
事实并非如此。
数据永远伴随着视角,而视角一定属于某个主体。
供应商无法替用户发声,用户也无法替数据发声。
没有任何平台,可以替所有人发声。
这不是 MCP 的失败,而是它的边界。
多智能体世界并不是要取代 MCP,而是为它提供上下文。
为什么金融数据需要一个多智能体的未来

金融市场从来不是中立系统。
它们由激励、约束、不对称信息和相互竞争的解释共同塑造。
任何假装“中立”的系统,最终都会隐藏更多东西。
多智能体的方法,并不承诺完美答案。
它承诺的是更重要的东西:对取舍、边界和视角的可见性。
它接受碎片化,并把碎片化转化为力量。
为什么我在构建 Prompits
Prompits,是我对这一现实的回应。
它是一个多智能体框架,基于一个简单但严格的原则:
每一个智能体,只代表其所有者的最佳利益和专长——不多,也不少。
用户智能体、供应商智能体,以及可选的经纪智能体,作为对等个体共存。它们彼此发现、沟通、分歧、协调。
不是因为协调很容易,而是因为假装不存在协调需求,代价更高。
Prompits 不再问“如何暴露更多工具”,
而是问一个更难的问题:
我们如何让彼此独立的智能,诚实地协同工作?
展望未来
这并不是一篇反对 Bloomberg、LSEG、API 或 MCP 的文章。
它反对的,是这样一种想法:
任何单一的智能体、平台或接口,都能看到完整的世界。
金融数据的未来,不会是一个完美系统。
它将是多个智能体并存的世界——
每一个,都清楚地看到自己该看到的部分,并终于被允许发声。
这,就是金融数据需要多智能体未来的原因。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)