第 10 篇 Dify 知识库手把手案例
本文介绍了如何利用Dify平台构建《阿里巴巴Java开发手册》智能助手。首先详细讲解了知识库创建的完整流程,包括文档上传、分段设置(推荐父子分段+段落上下文)、索引方式选择(高质量+混合检索)等关键步骤。随后指导用户进行分段质量检查和召回测试,强调TopK和Score参数的调优策略。接着演示了Chatflow应用开发过程,通过知识检索节点和LLM节点的配置,实现从知识库智能获取答案的功能。最后展示
文章目录
🚀 目标:创建一个知识库的入门案例,实现《阿里巴巴 Java 开发手册》小助手。
⭐ DSL:阿里巴巴Java开发手册小助手.yml
准备知识库
下面,我们创建一个新的知识库,并在后续的 Chatflow 中引用它。
第 1 步:上传文档
首先,我们点击“创建知识库”按钮。
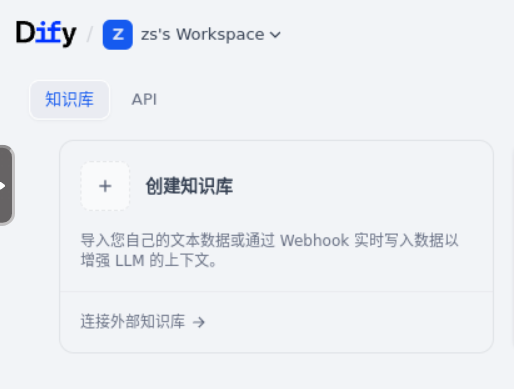
其次,我们将《阿里巴巴 Java 开发手册 1.4.0.pdf》文档上传。
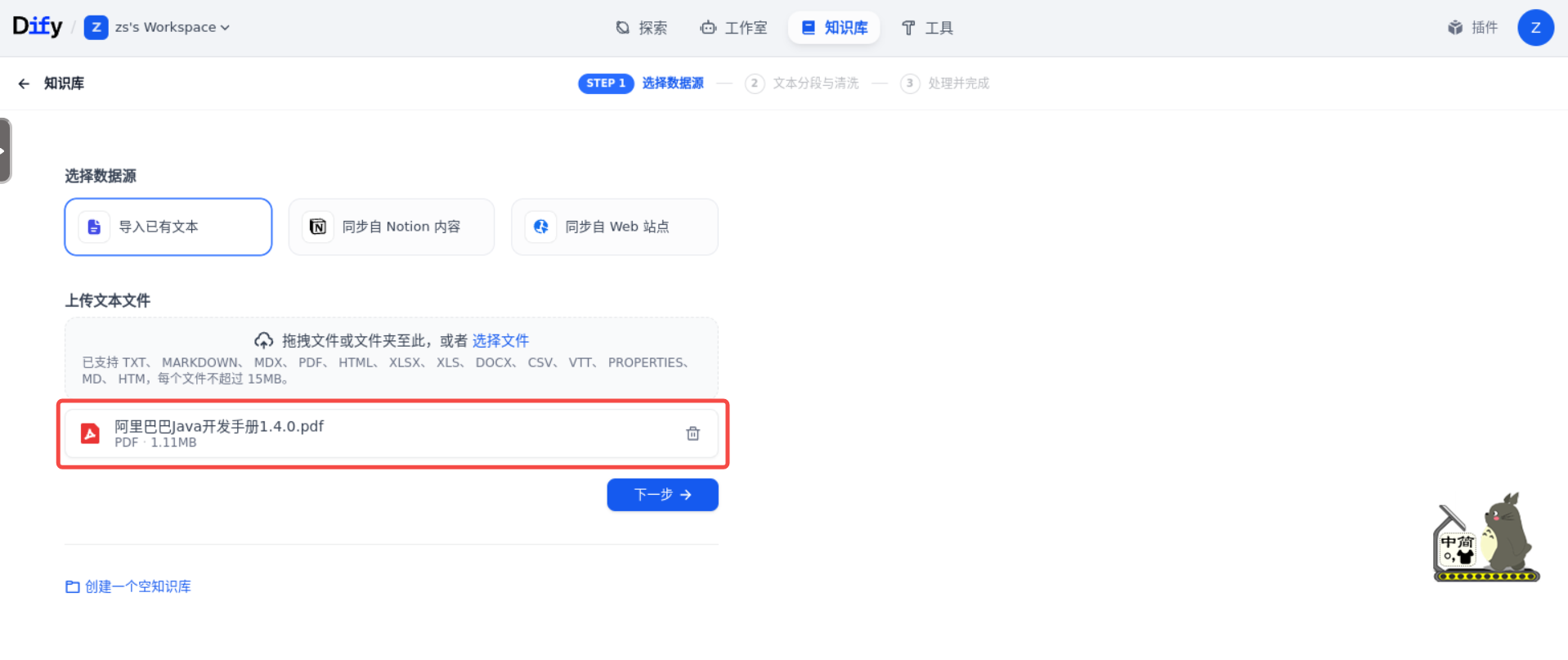
然后,点击“下一步”。
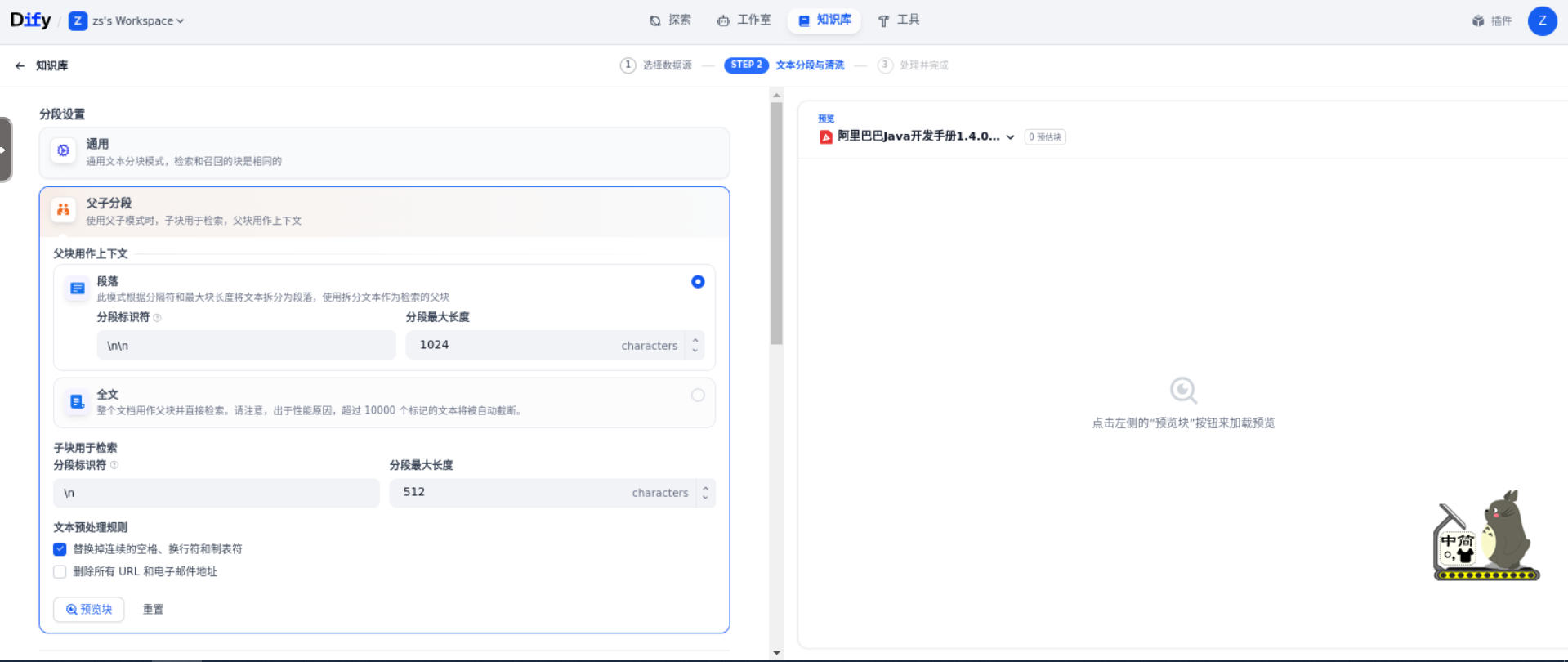
第 2 步:文本分段与清洗
分段设置:选择父子分段 + 段落作为上下文。在相同文档中,采用父子检索提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。同时,在父子模式中,如果文本量较大,内容清晰且段落相对独立,则使用段落作为父分段,如果文本量较小,但段落间互有关联,需要完整检索全文,则采用全文作为父分段。
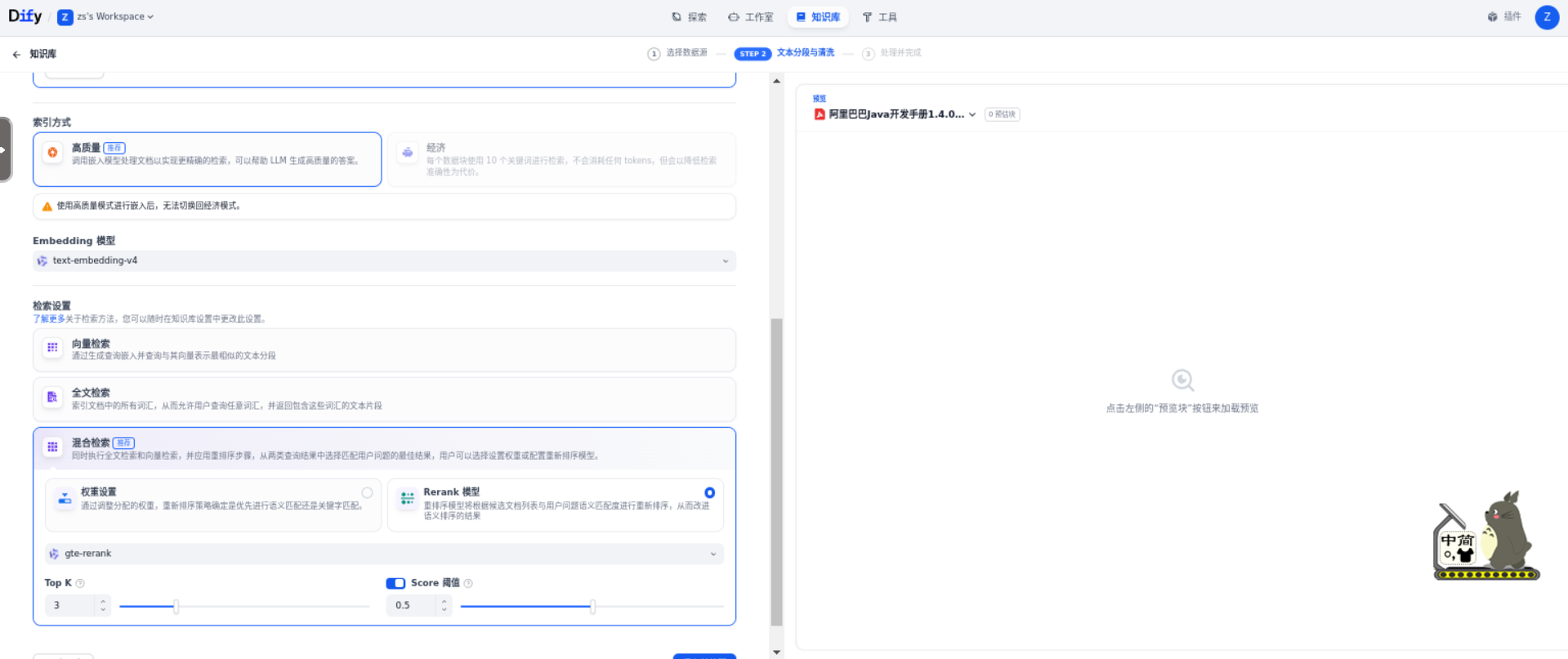
索引方式:选用高质量 + 混合检索方式。使用 Embedding 嵌入模型将已分段的文本块转换为数值向量,帮助更加有效地压缩与存储大量文本信息;使得用户问题与文本之间的匹配能够更加精准。将内容块向量化并录入至数据库后,需要通过有效地检索方式调取与用户问题相匹配的内容块。注意:选择高质量索引方式后,无法降级到经济索引模式。如需切换,只能重建。
第 3 步:查看创建的知识库
刚创建的知识库,还需要调用 Embedding 模型做向量化及存储,需要一点时间才能完成。
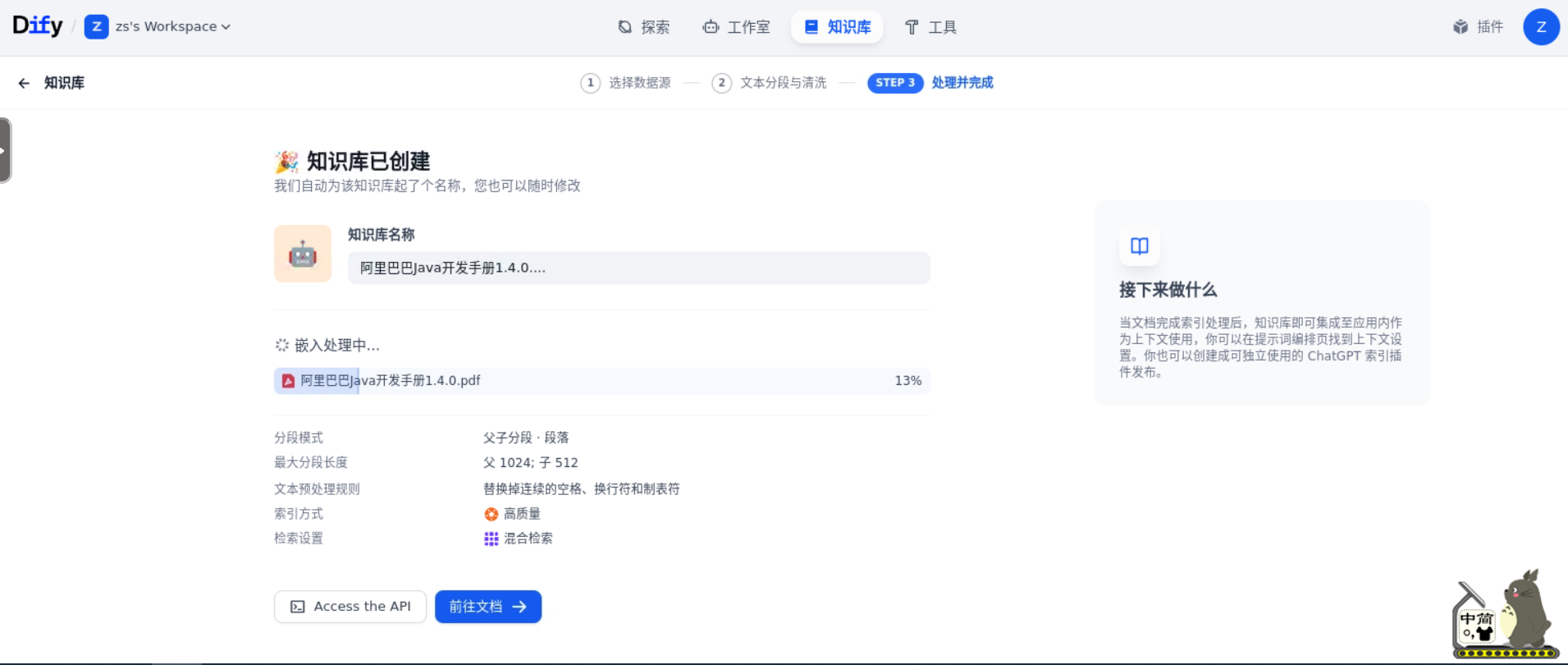
嵌入完成后的知识库如下:
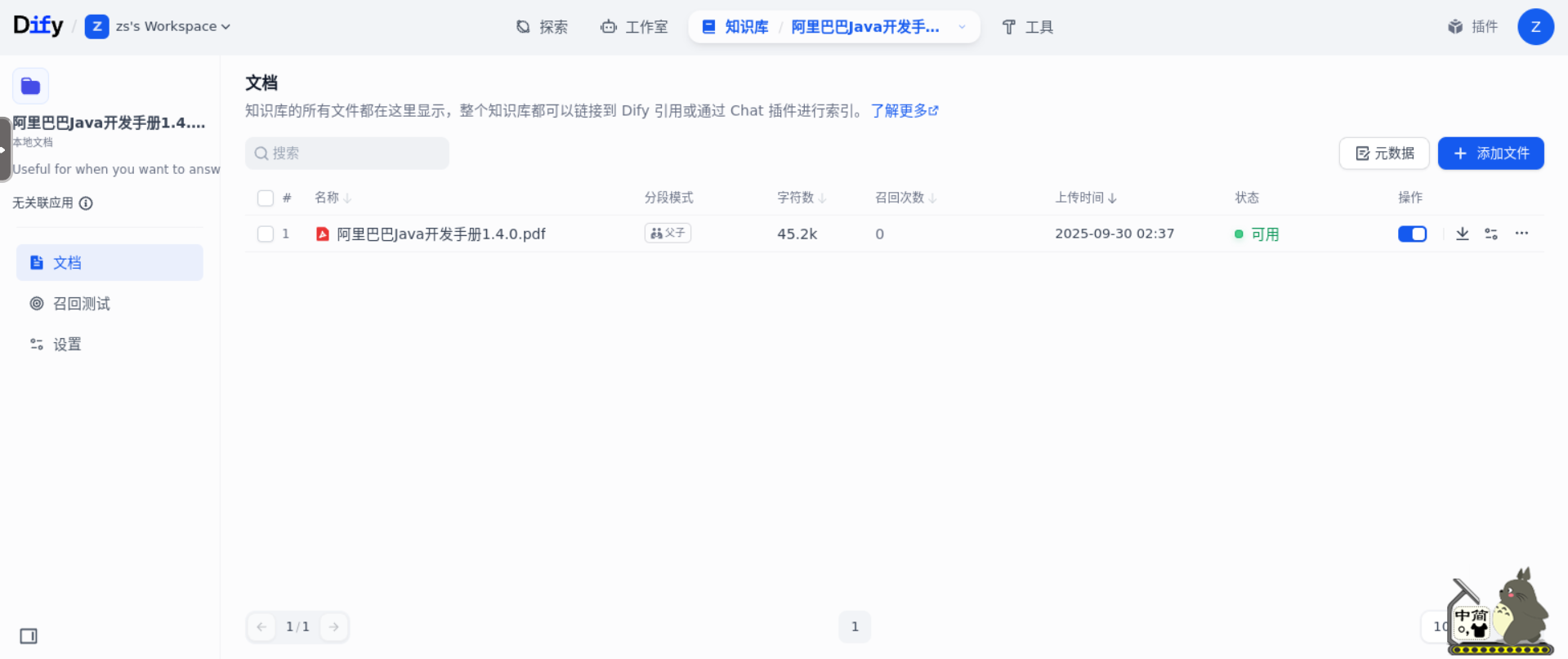
第 4 步:检查分段
检查分段的目的:保证分段的质量。
- 过短的文本分段,会导致语义缺失。
- 过长的文本分段,导致语义噪音影响匹配准确性。
- 明显的语义截断,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时内容缺失。
通过下面的步骤来检查分段。点击文档所在行后面的“分段设置”图标:

然后,进入到分段设置页面,点击“预览块”按钮,即可预览分块效果。
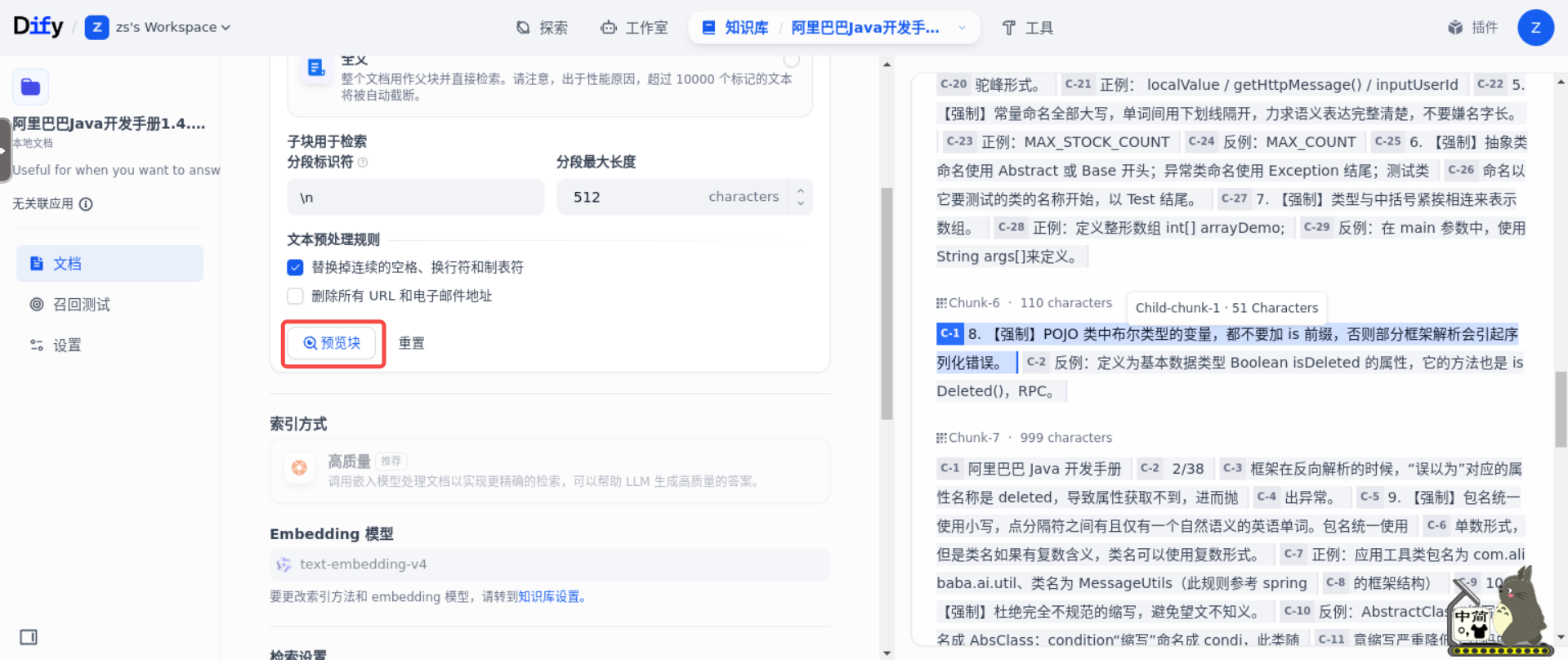
从检查结果来看,分段还算合理。
第 5 步:召回测试
召回测试的目的:检测分段质量,确定是否能召回合适的分段。
召回测试步骤
首先,召回测试也是测试的范畴,遵循基本的测试原理,即编写测试用例、执行测试用例等操作。
因此,召回测试的步骤如下:
1、设计和整理能够覆盖用户常见问题的测试用例/测试问题集/指引内容;
2、根据内容特点和使用常见(是否为问答内容、是否涉及多语言问答等),选择合适的索引策略;
3、调整召回分段数量(TopK)和召回分数阈值(Score),根据实际的应用常见、包括文档本身的质量来选择合适的参数组合。
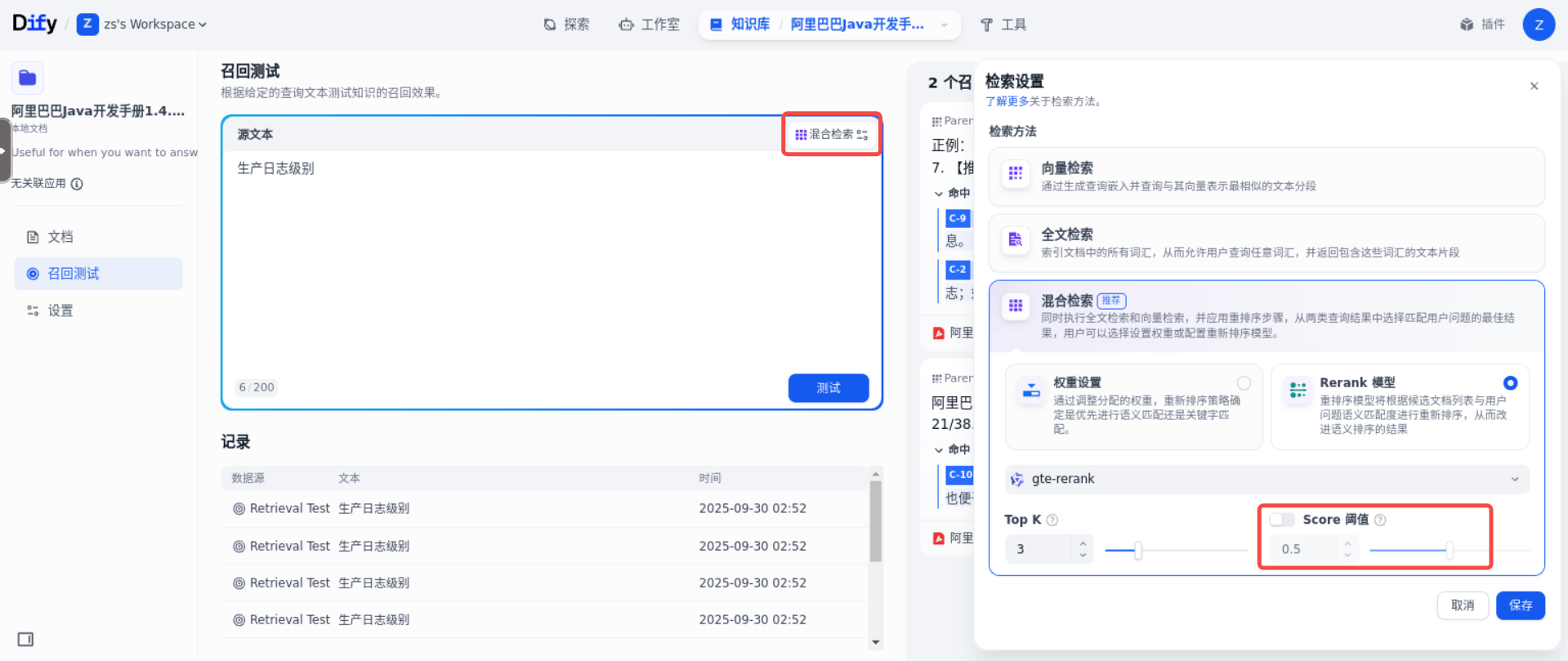
如何配置 TopK 和 Score 参数
这两个参数调大或者调小,都会影响召回的质量,并对最终结果产生影响。
1️⃣ TopK 表示按相似度分数倒排时召回分段的最大个数。
- TopK 调小,将召回越少的分段,可能导致召回的相关文本不全;
- TopK 调大,将召回更多的分段,但可能找到召回语义相关性较低的分段,使得 LLM 回复质量降低
2️⃣ **Score **召回分数阈值,表示运行召回分段的最低相似分数。
- Score 调小,将会召回更多分段,可能导致召回相关度较低的分段;
- Score 调大,将召回更少分段,过大可能会导致无法召回分段;
实际案例
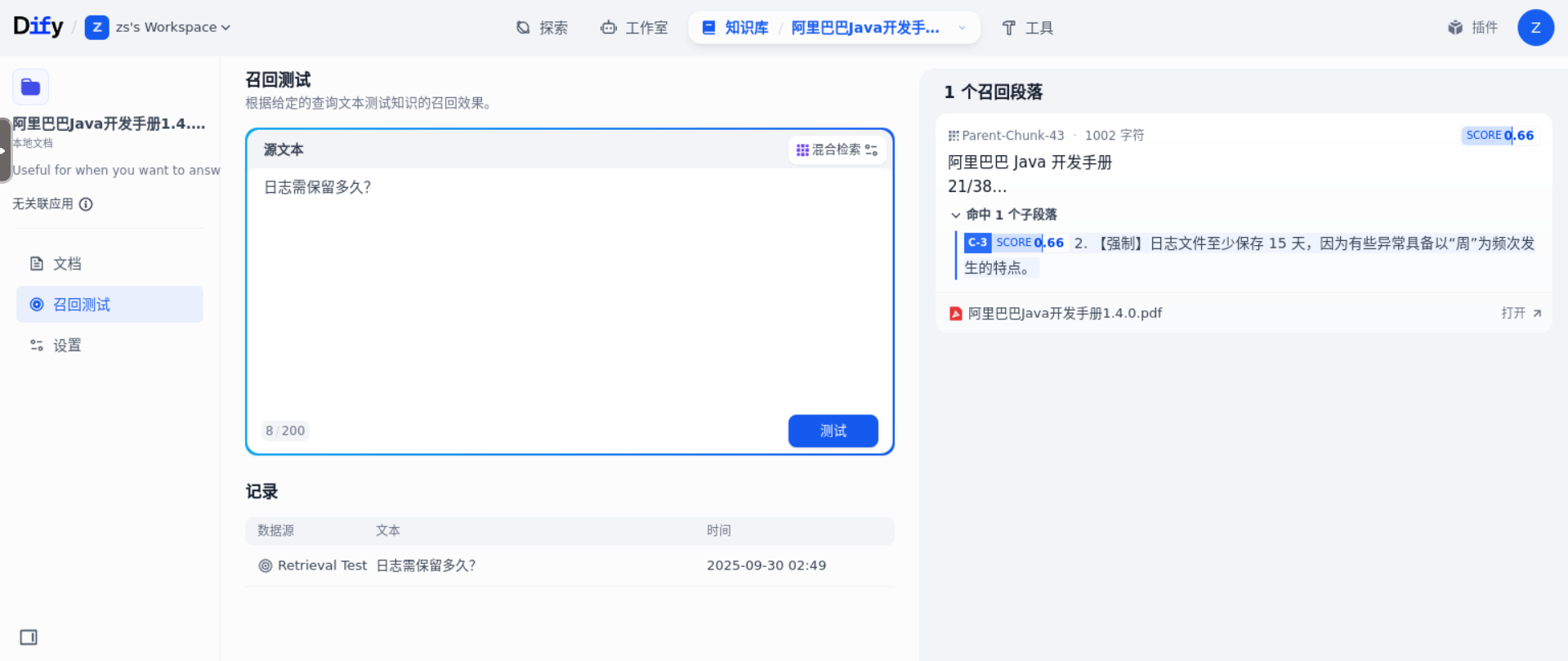
前面,我们设置了 TopK 为 3,Socre 阈值为 0.5。即召回 3 个分段,且分数必须高于 0.5。
示例 1:“日志需保留多久?”召回了 1 个子分段,Score 为 0.66。
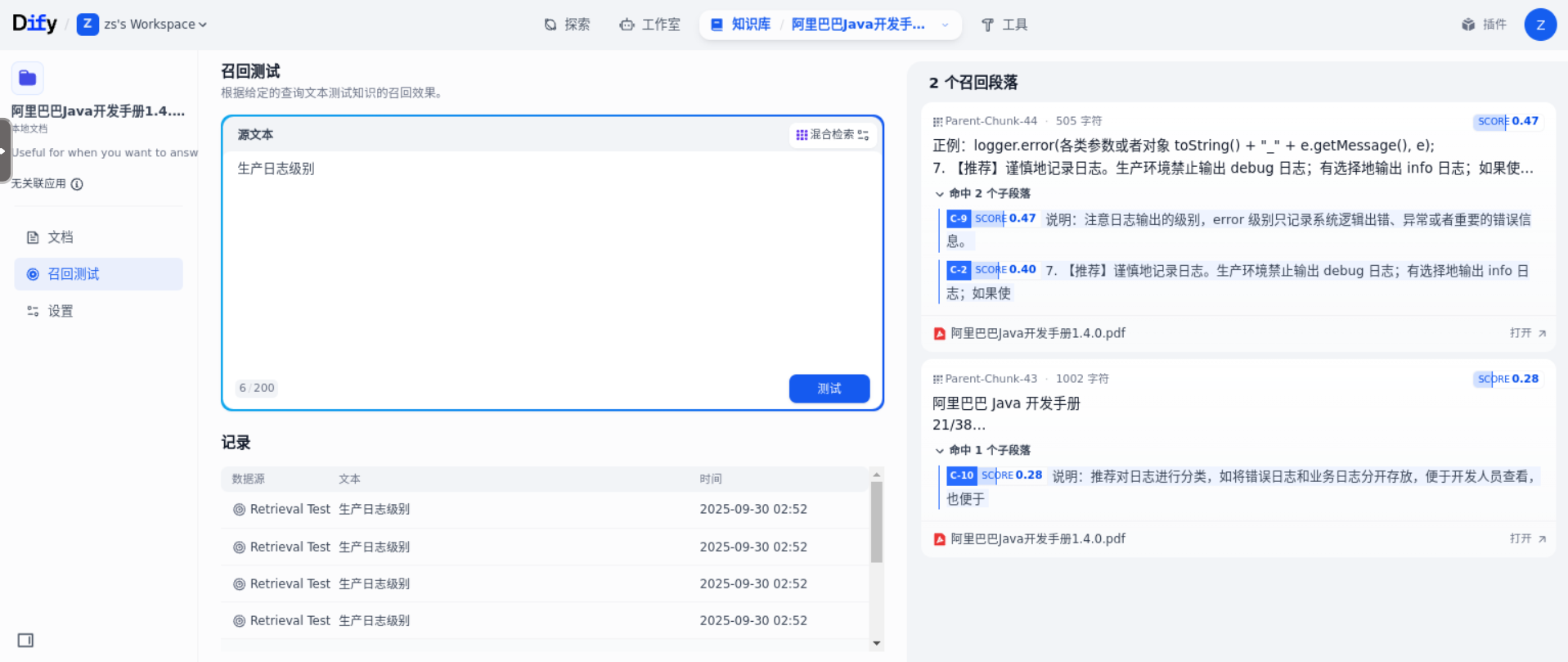
示例 2:取消 Score 阈值限制,即不管 Score 是多少。可以看到,“生产日志级别”返回了两个子分段,一个 score 为 0.47,一个 score 为 0.28。
创建 Chatflow 应用
下面,创建一个 Chatflow,实现从知识库中检索并回复用户。
完整的工作流截图如下:

创建空白应用
首先,创建一个 Chatflow 应用。
配置“知识检索”节点
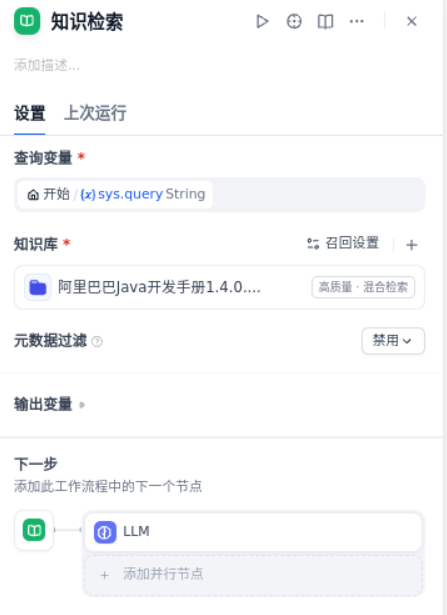
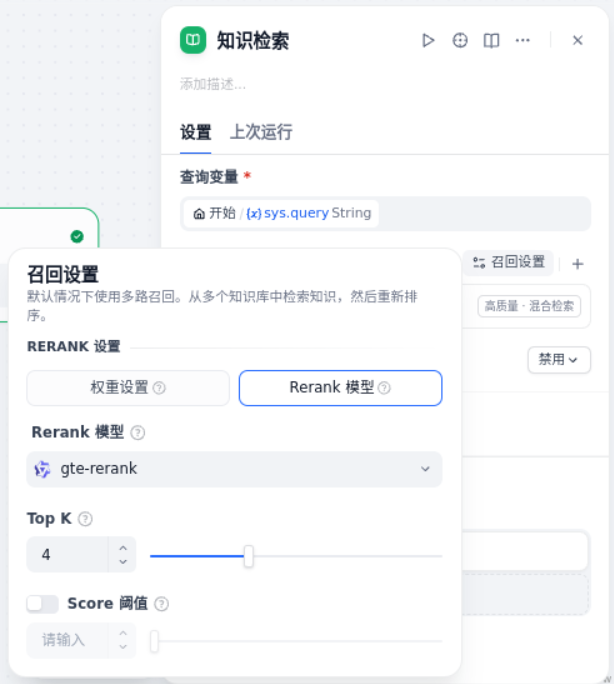
在“开始”节点后,添加“知识检索”节点并配置。
1、查询变量:使用 sys.query,即用户输入的内容。
2、知识库:引用《阿里巴巴 Java 开发手册 1.4.0》知识库
3、知识库召回设置:使用 Rerank 模型重排序,TopK 设置为 4,不限制 Score 阈值。
配置“LLM”节点
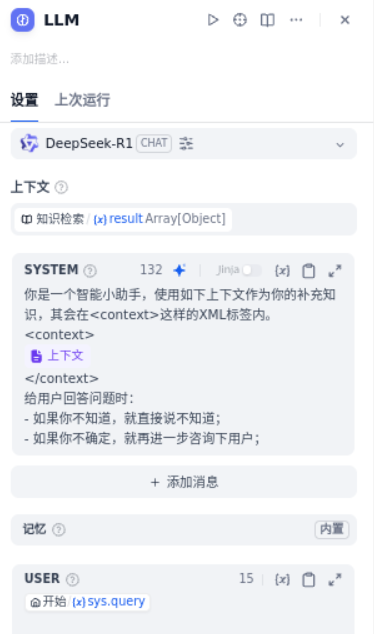
在“知识检索”节点后新增“LLM”节点并设置。
1、大模型:选择 DeepSeek-R1。
2、上下文:引用知识库的返回结果。
3、SYSTEM 提示词:告诉 LLM 要引用知识库,不知道的就说不知道。
4、USER 提示词:直接使用用户提出的问题。
配置“直接回复”节点
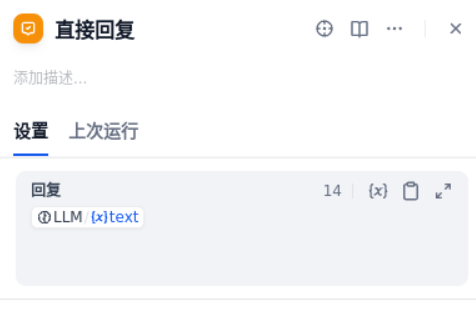
最后,在“LLM”节点后,配置“直接回复”节点,即直接将 LLM 的输出返回给用户。
配置“归属与引用”
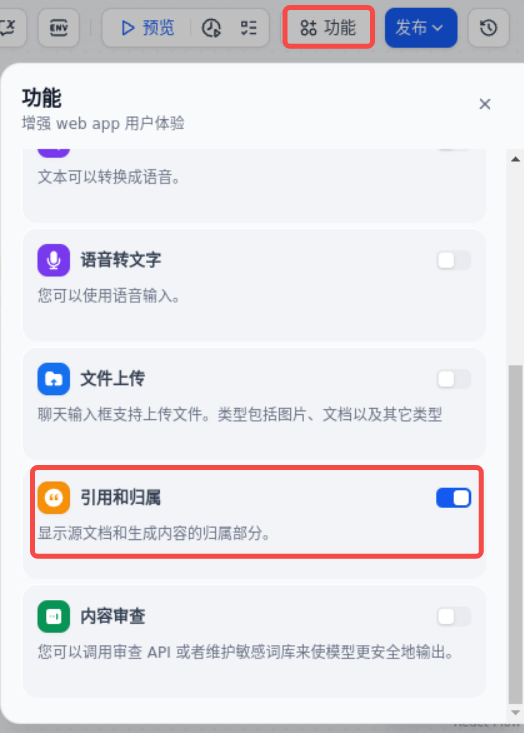
点击“功能”,勾选“引用和归属”,这样回答用户的时候,就能把知识库的引用部分也显示出来。
预览应用
点击“预览”按钮,即可预览应用。输入“日志需保留多久?”即可调试。
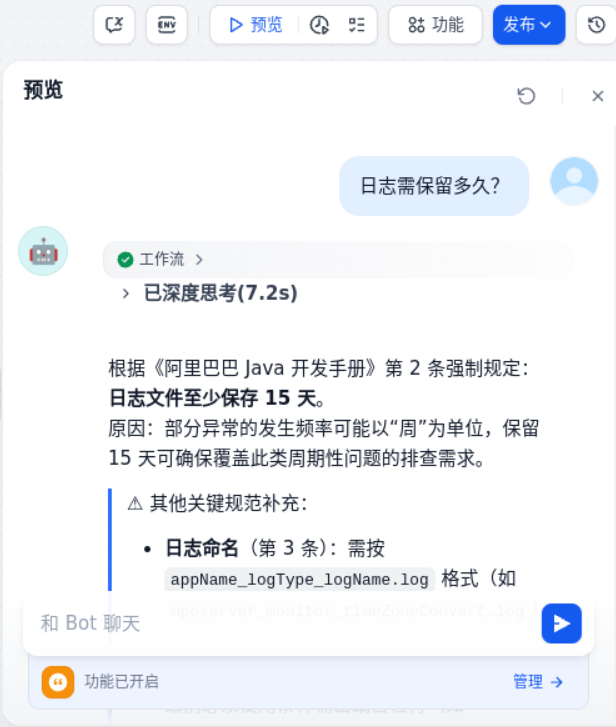
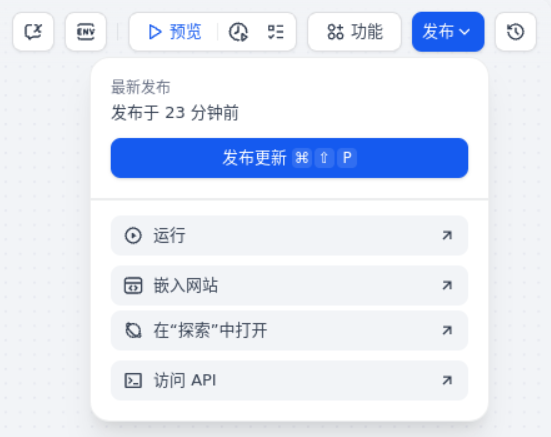
发布应用
最后,点击“发布”,可将应用发布。点击“运行”,即可打开一个新页面,即当前 Chatflow 应用。
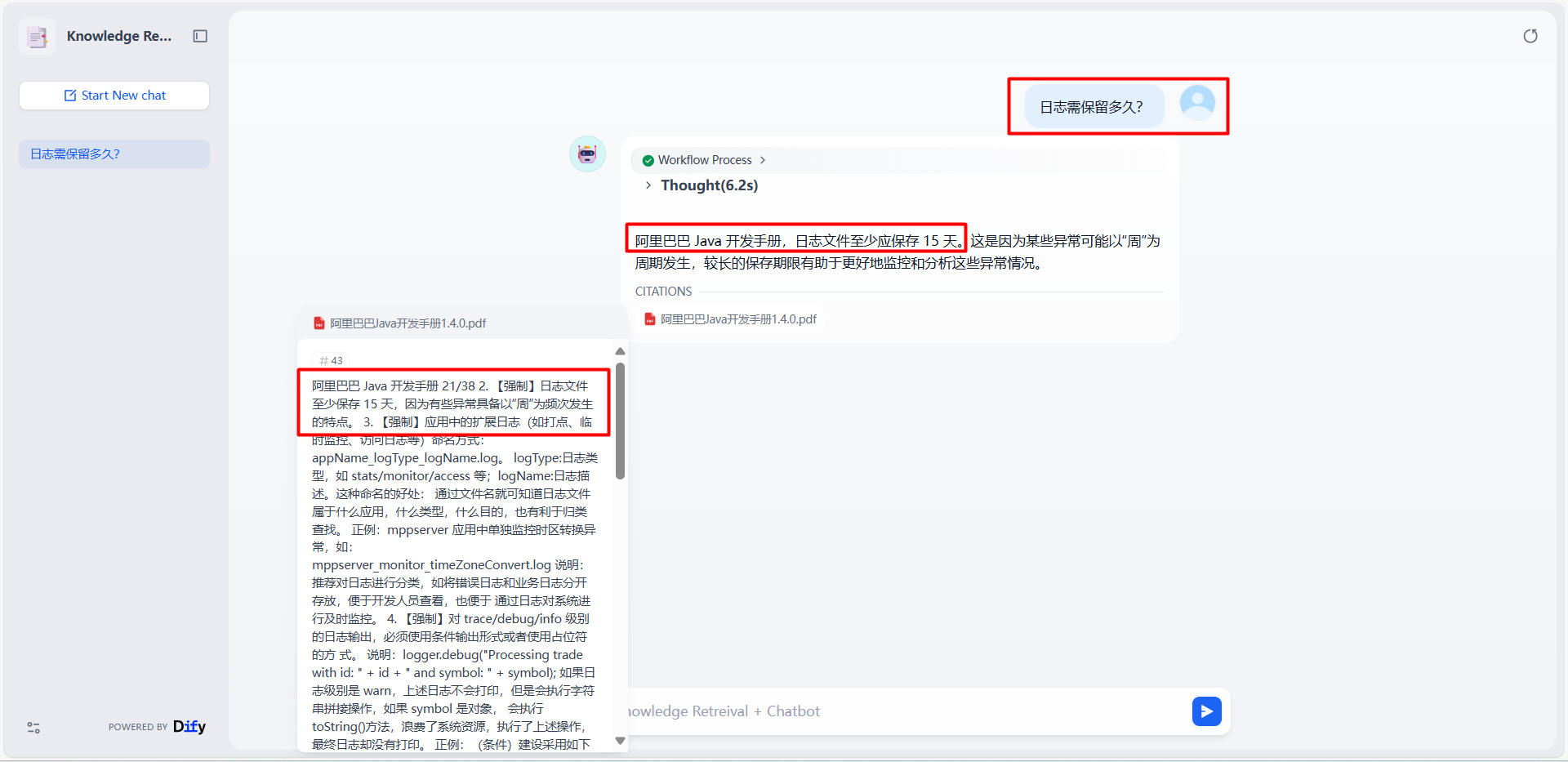
使用 Chatflow
点击“运行”,即可打开一个新页面,即当前 Chatflow 应用。如下图所示:

输入“日志需保留多久”,然后就会运行工作流并返回知识库的引用结果。
至此,Dify 知识库案例介绍完毕!🚀
参考
1.Dify: Leading Agentic AI Development Platform
相关博文
1.第 1 篇 Linux 下部署 Dify 1.7.1
2.第 2 篇 Dify 插件离线安装
3.第 3 篇 Dify 入门示例 - 聊天助手
4.第 4 篇 Dify 示例:数据库执行Agent
5.第 5 篇 Dify 报错解决:The length of output variable xxx must be less than 30 elements
6.第 6 篇 Dify 接入大模型并使用
7.第 7 篇 Dify 应用介绍 + 聊天助手&Agent 应用关键点说明
8.第 8 篇 RAG 必知概念及原理详解
9.第 9 篇 Dify 知识库原理详解
10.第 10 篇 Dify 知识库手把手案例
11.第 11 篇 Dify 入坑记录:插件安装报错,[ERROR]init environment failed_ failed to install dependencies
12.第 12 篇 Dify 入坑记录:database插件连接未关闭
13.第 13 篇 Dify 工作流 详解
14.第 14 篇 Dify 知识库检索,如何返回完整文档?
15.第 15 篇 Dify 应用发布与被集成的7种方式
16.第 16 篇 Dify 记忆 & mem0 插件实战
17.第 17 篇 Dify 1.7.1 → 1.11.1 完整升级指南:避开那些必踩的坑
18.第 18 篇 Dify 工具调用报错:tool invoke error validation error for VariableMessage_n Value error, Only basic
19.第 19 篇 手把手教你开发 Dify 插件:从零实现一个时间工具
20.第 20 篇 Dify插件开发进阶:常规开发 & 反向调用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)