大模型微调不再是“烧钱游戏“:揭秘QLoRA黑科技,单卡70B模型落地全指南
摘要:通用大模型在实际业务场景中面临行业壁垒,微调成为定制化的关键。PEFT技术(如LoRA和QLoRA)显著降低了微调成本,使消费级显卡也能完成企业级微调。LoRA通过旁路矩阵实现高效学习,而QLoRA采用4-bit量化进一步压缩显存。实践步骤包括算力准备、环境配置、数据构建和模型训练。QLoRA虽牺牲部分速度,但性能接近全参数微调,显存节省高达59%。未来,微调技术将推动AI应用"百
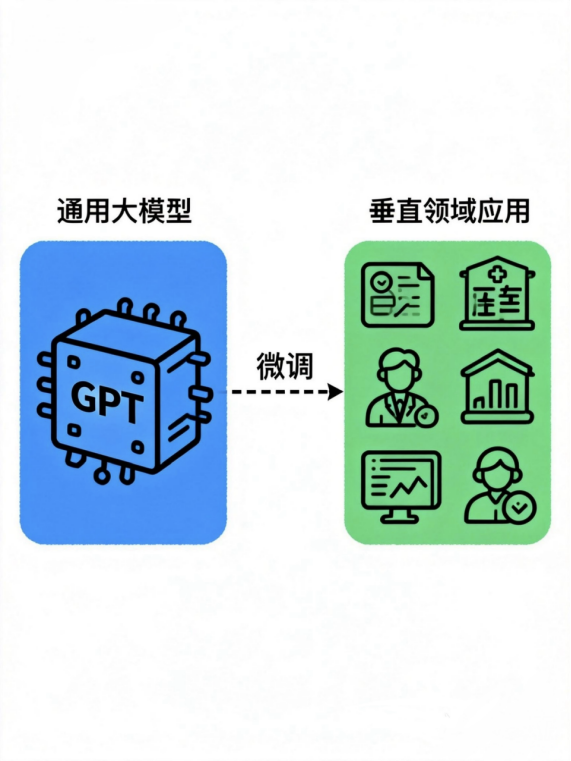
一、当通用大模型遇到"行业壁垒"
ChatGPT和Llama的横空出世,让我们见证了通用人工智能的曙光。然而,当真正试图将这些"通才"引入具体业务场景——无论是医疗问诊、法律文书撰写,还是企业内部的智能客服时,我们往往会发现理想与现实的落差。通用模型就像一个博学的教授,但他不懂你们公司的"黑话",也不了解特定的业务流程。这时候,微调就成为了必经之路。
过去,微调大模型是只有科技巨头才能玩得起的"烧钱游戏"。全参数微调动辄需要数十张A100显卡,成本高不可攀。但今天,随着PEFT技术的爆发,尤其是LoRA和QLoRA的出现,游戏规则被彻底改变。本文将带你深入探究如何利用这些技术,用消费级显卡的成本,完成企业级大模型的定制化微调。
二、技术原理:给大模型做"微创手术"
在动手之前,我们需要理解为什么现在微调变便宜了。
全参数微调与PEFT的区别
如果把大模型比作一座装修好的摩天大楼,全参数微调相当于为了换个风格,把整栋楼拆了重盖,费时费力。而PEFT则像是只装修其中一个房间,或者给大楼加装一个外挂电梯。在PEFT家族中,Prefix-Tuning和Adapter曾各领风骚,但目前最主流的当属LoRA。
LoRA:旁路上的智慧
LoRA的核心思想非常精妙。它冻结了预训练模型原本巨大的参数矩阵,而是在旁边增加了一个非常小的"旁路"矩阵来学习特定任务。想象一下,原本的模型是一个巨大的水管系统,我们不敢乱动。LoRA就是在主管道旁边接了一根细水管,通过调节细水管里的水流来影响最终输出。这样,我们只需要训练这根"细水管"的参数,参数量通常只有原模型的千分之一甚至万分之一。
QLoRA:极限压缩的艺术
如果说LoRA是省钱,那QLoRA就是"抠门"到了极致。QLoRA相比LoRA能进一步降低59%的显存消耗。它的秘诀在于三个黑科技:4-bit NormalFloat量化,把原本庞大的数据精度极其精妙地压缩到4bit;双重量化,连量化常数本身也进行量化,榨干每一滴显存;分页优化器,利用CPU内存来辅助GPU显存,防止显存溢出。这意味着,以前需要8张卡才能跑的任务,现在可能一张卡就能搞定。
三、实践步骤:从零构建你的专属模型
Talk is cheap,show me the code。接下来,我们将基于LoRA技术,梳理一套适合零基础入门的标准流程。
第一步:算力资源准备
虽然LoRA降低了门槛,但你仍然需要一张NVIDIA显卡。对于7B参数左右的模型,一张24G显存的3090或4090足矣;如果是QLoRA,甚至12G至16G显存的显卡也能尝试。
如果你本地没有高性能显卡,或者不想承担硬件折旧风险,强烈推荐使用LLaMA-Factory Online这种低门槛大模型微调平台。他们提供开箱即用的训练环境,特别适合初学者进行微调实验。即使没有代码基础,也能轻松跑完微调流程,在实践中理解怎么让模型"更像你想要的样子"。
第二步:环境配置
工欲善其事,必先利其器。你需要配置Python环境,并安装核心库:PyTorch作为深度学习框架基石;Transformers是Hugging Face的神器,用于加载模型;PEFT专门用于加载LoRA等微调配置;Bitsandbytes实现QLoRA量化功能的关键库。建议使用Conda创建独立环境,避免版本冲突。
第三步:数据集构建
微调效果好不好,数据质量占七成。你需要准备"指令-输出"对。对于垂直领域,你需要收集行业文档、客服记录等,并将其清洗、格式化。一个典型的数据格式示例如下:指令部分描述任务要求,输入部分提供上下文信息,输出部分给出标准答案。
第四步:模型加载与LoRA配置
代码层面,你不需要手写复杂的矩阵运算。只需要在加载底座模型后,定义LoRA配置:r参数决定了LoRA秩的大小;lora_alpha是缩放系数;target_modules指定需要微调的模块,如注意力机制中的q_proj和v_proj。
在实际操作中,如果只是停留在"了解大模型原理",其实很难真正感受到模型能力的差异。我个人比较推荐直接上手做一次微调,比如用[LLaMA-Factory Online]
(https://www.llamafactory.com.cn/register?utm_source=jslt_csdn_ldd)这类低门槛平台,把自己的数据真正"喂"进模型里,生产出属于自己的专属模型。这本质上是在把GPU资源、训练流程和模型生态做成"开箱即用"的能力,让用户可以把精力放在数据和思路本身,而不是反复折腾环境配置。
第五步:开启训练与推理
配置好参数后,点击运行,看着损失曲线缓缓下降,就是最快乐的时刻。训练完成后,你可以将LoRA权重合并回原模型,或者在推理时动态加载。
四、效果评估:LoRA与QLoRA终极对局
很多同学会问:QLoRA压缩得这么狠,效果会不会打折?让我们用数据说话。
显存占用对比
在微调LLaMA-7B时,LoRA全精度加载可能需要24G以上显存,而QLoRA配合4-bit量化,显存可以直接压到10G左右。对于更大的65B或70B模型,QLoRA更是唯一能让单张48G显卡跑起来的方案,显存节省高达59%。
训练速度对比
由于需要进行量化和反量化计算,QLoRA的训练速度会比标准LoRA慢20%至30%左右。这是为了换取低显存而必须付出的时间代价。
模型性能对比
最令人惊讶的是,在各项基准测试中,QLoRA微调后的模型性能与全参数微调几乎持平,达到99%以上的效果。这说明模型参数中存在大量的冗余,4-bit的精度足以承载大部分垂直领域的知识。
选择建议
如果你的显存捉襟见肘,或者想微调超大参数模型,QLoRA是唯一解;如果你算力充裕且追求极致的训练速度,标准LoRA依然是不错的选择。
五、总结与展望
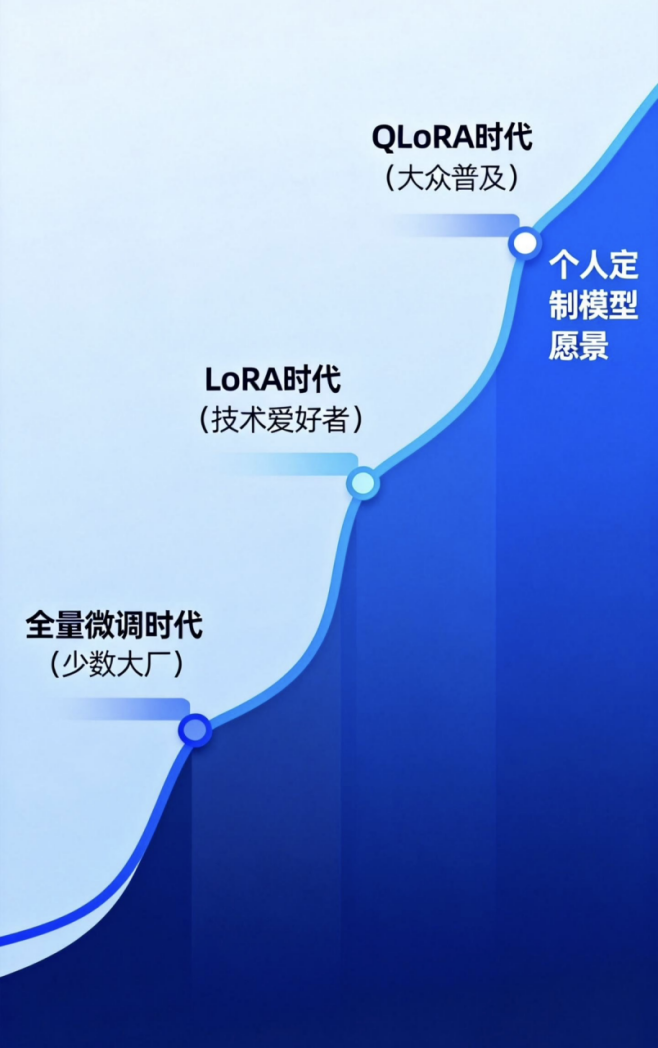
大模型微调技术的发展速度远超我们的想象。从Adapter到LoRA,再到QLoRA,技术的演进正在不断打破算力的垄断。这意味着,未来的AI格局将不是"一家独大",而是"百花齐放"。每一个细分行业、每一家公司,甚至每一个个人,都可以拥有懂自己业务、懂自己风格的专属大模型。
对于技术人员来说,掌握微调技术,不仅仅是学会跑通代码,更是掌握了通向AI时代的船票。与其在岸上观望,不如亲自下水,去训练那个属于你的超级大脑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)