【数据库】时序数据智能基座:Apache IoTDB 选型与深度实践指南
Apache IoTDB作为物联网时序数据库,创新性地引入AINode模块,支持在数据库内部直接执行机器学习模型推理,实现“数据不动模型动”的智能分析模式。该架构采用云边端一体化设计,包含轻量级边缘实例、专有TsFile存储格式和AINode推理节点。用户可通过SQL语句注册、管理和调用PyTorch模型,实现电力预测、异常检测、数据填补等场景的实时分析。IoTDB还支持与Flink等大数据生态集
引言:时序数据处理的新范式
随着工业4.0、智能制造和能源互联网的快速发展,企业面临海量设备产生的高并发、高频率时序数据处理难题。传统架构中“采集—存储—导出—分析”的链路存在数据迁移成本高、实时性差、系统耦合复杂等问题。
Apache IoTDB 作为 Apache 软件基金会的顶级项目,专为物联网(IoT)场景设计,具备高压缩比、低写入延迟、原生时序计算能力,并创新性地引入 AINode(AI Node)模块,支持在数据库内部直接执行机器学习模型推理,实现“数据不动模型动”的智能分析新模式。
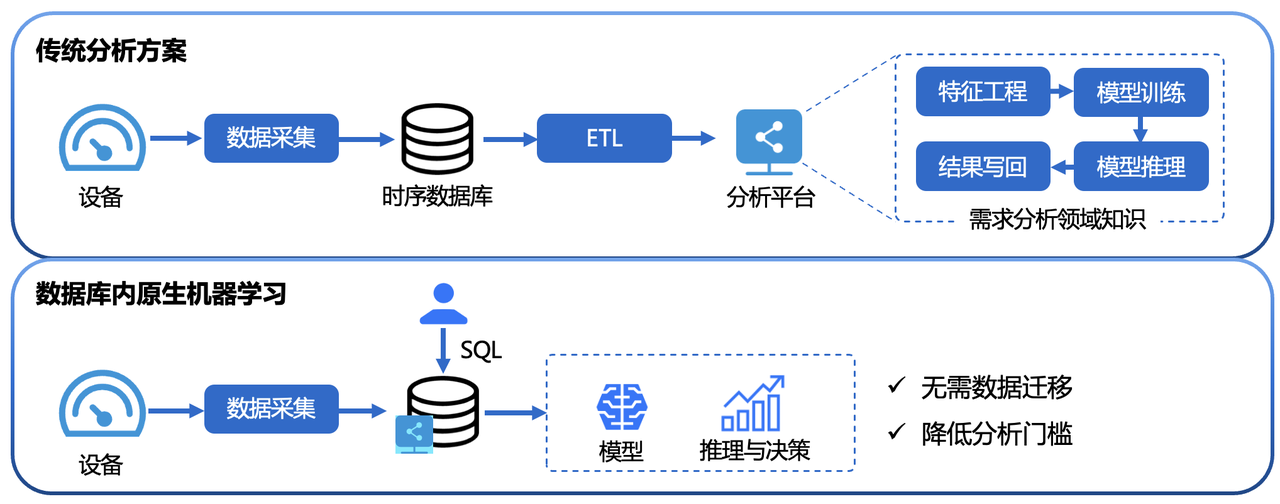
本指南从大数据选型视角出发,系统解析 IoTDB 的架构优势,并结合代码、图表与实战流程,展示其在智能分析中的深度应用。
一、核心架构解析:云边端协同 + 内生AI能力
1.1 系统整体架构
IoTDB 采用“云边端一体化”架构,支持从设备边缘到数据中心的全链路数据流转与处理。
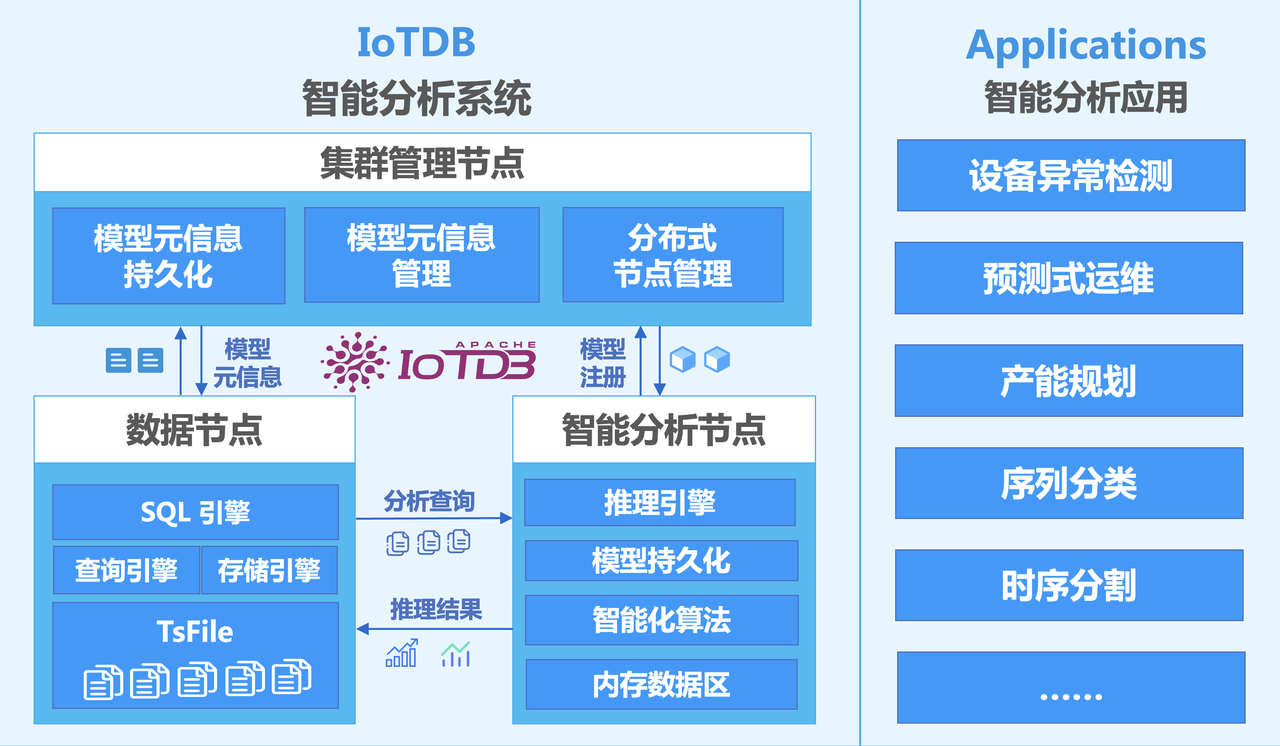
关键组件说明:
- Edge/Device Layer:部署轻量级 IoTDB 实例,支持断点续传、本地缓存。
- TsFile:专有时序存储格式,支持高效压缩与行列混合访问。
- ConfigNode:负责集群元数据管理、节点协调、模型注册信息维护。
- DataNode:处理原始数据读写、执行 SQL 解析、完成数据预处理(如归一化、滑窗)。
- AINode:承载 AI 模型加载与推理任务,支持 PyTorch JIT 模型原地执行。
1.2 AINode 工作机制
AINode 是 IoTDB 实现“数据库即分析平台”的核心模块。它通过以下流程实现模型与数据的深度融合:
- 用户将训练好的模型注册至 IoTDB;
- AINode 下载并加载模型;
- 在 SQL 查询中调用
INFERENCE()函数,触发实时推理; - 结果以标准表结构返回,可直接用于可视化或下游系统。
二、实战操作:AINode 模型管理与推理
2.1 环境准备
确保已部署 IoTDB 集群(建议版本 ≥ 1.0),且 AINode 服务已启动。
# 启动 AINode 服务(示例)
cd $IOTDB_HOME
bin/ainode-start.sh -c 127.0.0.1:10730 -d 127.0.0.1:10720
注意:
-c指向 ConfigNode 地址,-d指向 DataNode 地址。
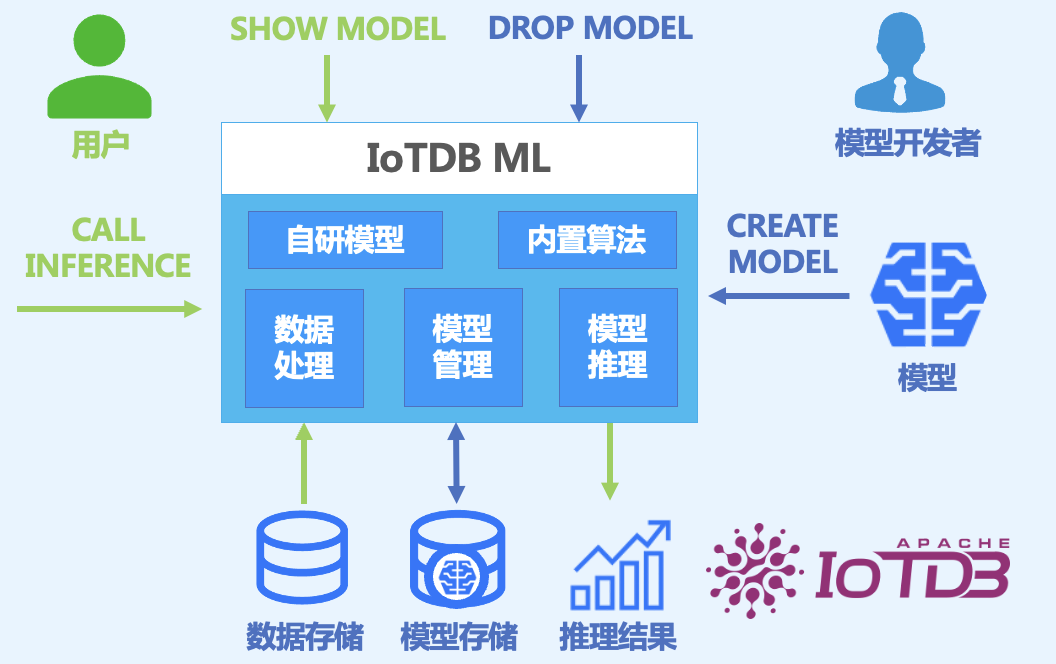
2.2 模型注册:CREATE MODEL
使用 SQL 将外部训练好的模型注册到 IoTDB 中。支持本地文件或远程 URI(如 HuggingFace)。
SQL 语法
CREATE MODEL <model_id> USING URI '<uri>';
参数说明
| 参数 | 说明 |
|---|---|
model_id |
模型唯一标识符,全局唯一 |
uri |
模型文件路径,支持 file://, http://, https:// 协议 |
操作示例:从 HuggingFace 注册 DLinear 模型
CREATE MODEL dlinear_power_forecast
USING URI 'https://huggingface.co/IoTDBML/dlinear/resolve/main/dlinear.pt';
✅ 前提条件:模型必须为 PyTorch JIT 格式(
.pt),且包含config.yaml描述输入输出结构。
config.yaml 示例
model_name: "DLinear"
input_shape: # 输入:96个时间步,2个特征
output_shape: # 输出:预测24步,1个目标
input_type: ["float32", "float32"]
attributes:
prediction_length: 24
context_length: 96
2.3 模型管理:SHOW & DROP
查看当前注册的所有模型
SHOW MODELS;
预期返回结果:
| ModelId | ModelType | Status | CreateTime |
|---|---|---|---|
| dlinear_power_forecast | DLinear | ACTIVE | 2026-01-06 14:23:11 |
🔁 状态说明:
ACTIVE:模型已就绪,可推理LOADING:正在下载或加载中FAILED:加载失败,需检查 URI 或格式
删除不再使用的模型
DROP MODEL dlinear_power_forecast;
⚠️ 警告:删除操作不可逆,请谨慎执行。
三、智能分析实战:SQL 驱动的实时推理
3.1 推理调用语法
CALL INFERENCE(
<model_id>,
inputSql => '<SQL 查询语句>',
param1 => value1,
param2 => value2,
...
);
参数说明:
inputSql:指定用于推理的数据源查询语句- 支持窗口函数:
HEAD(),TAIL(),COUNT(),适用于流式场景
3.2 典型应用场景与代码示例
场景一:电力负载预测(多变量输入,单变量输出)
业务目标:基于过去7天的电网负载与温度数据,预测未来24小时的负载变化。
数据结构:
Path: root.energy.grid
Fields: load (FLOAT), temperature (FLOAT)
推理 SQL:
CALL INFERENCE(
'dlinear_power_forecast',
inputSql => 'SELECT load, temperature FROM root.energy.grid WHERE time > NOW() - 7d',
predict_length => 24
);
返回结果示例:
| time | load_prediction |
|---|---|
| 2026-01-08 00:00:00 | 102.3 |
| 2026-01-08 01:00:00 | 98.7 |
场景二:工业设备异常检测(实时流式推理)
业务目标:对振动传感器数据进行每分钟滑动窗口分析,检测异常波动。
推理 SQL:
CALL INFERENCE(
'vibration_anomaly_detector',
inputSql => 'SELECT TAIL(100) FROM root.machine.vibration',
threshold => 0.85
);
📌
TAIL(100)表示取最近100条记录进行推理。
返回字段扩展建议:
| field_name | data_type | description |
|---|---|---|
| is_anomaly | BOOLEAN | 是否检测到异常 |
| anomaly_score | FLOAT | 异常得分(0~1) |
| confidence | FLOAT | 模型置信度 |
场景三:传感器数据缺失值填补(Gap Filling)
业务目标:修复因通信中断导致的数据断点,提升数据完整性。
推理 SQL:
CALL INFERENCE(
'tsfill_model',
inputSql => 'SELECT load FROM root.energy.grid WHERE time BETWEEN 2026-01-05 AND 2026-01-06',
method => 'gan'
);
返回结果字段建议:
| field_name | data_type | description |
|---|---|---|
| original | FLOAT | 原始值(缺失处为 NULL) |
| filled | FLOAT | 模型填补后的值 |
| method | TEXT | 使用的填补算法(如 GAN、LSTM) |
四、大数据生态集成能力
4.1 与 Apache Flink 集成:实现实时降采样与预处理
通过 Flink SQL 连接器,可将 IoTDB 作为流处理系统的源表或结果表。
Flink SQL 示例:创建 IoTDB 输入表
CREATE TABLE IoTDB_Source (
device STRING,
ts TIMESTAMP(3),
temperature FLOAT,
vibration FLOAT
) WITH (
'connector' = 'iotdb',
'node-urls' = 'localhost:6667',
'sql' = 'SELECT * FROM root.sensors.* WHERE time > NOW() - 1d',
'fetch-size' = '1024'
);
实时降采样写回 IoTDB
CREATE TEMPORARY VIEW hourly_agg AS
SELECT
device,
TUMBLE_START(ts, INTERVAL '1' HOUR) AS hour,
AVG(temperature) AS avg_temp,
MAX(vibration) AS max_vibe
FROM IoTDB_Source
GROUP BY device, TUMBLE(ts, INTERVAL '1' HOUR);
-- 写回 IoTDB
INSERT INTO IoTDB_Sink
SELECT * FROM hourly_agg;
4.2 可视化集成:Grafana 实时监控大屏
IoTDB 提供官方 Grafana 数据源插件,支持:
- 多维度时序查询
- 模型推理结果展示
- 动态告警规则配置
配置步骤:
- 安装 IoTDB Data Source Plugin
- 添加数据源,填写 ConfigNode 地址
- 创建 Dashboard,使用变量动态切换设备与模型
五、选型建议与性能参考
| 维度 | 说明 |
|---|---|
| 数据写入吞吐 | 支持百万级/秒点写入,适合高密度设备接入 |
| 存储压缩率 | TsFile 压缩率可达 10:1 ~ 20:1,显著降低存储成本 |
| 查询延迟 | 简单查询 ✅ 推荐适用场景: |
- 工业制造(设备监控、预测性维护)
- 智慧能源(电力负荷预测、光伏优化)
- 智能交通(车联网数据处理)
- 科研实验(长时间序列记录与分析)
六、获取方式与学习资源
- 🌐 官方下载:https://iotdb.apache.org/zh/Download/
- 💼 企业版官网:https://timecho.com

附录:术语表
| 术语 | 解释 |
|---|---|
| TsFile | IoTDB 专用列式存储文件格式,支持高效压缩与时序查询 |
| AINode | AI 计算节点,负责模型加载与推理 |
| ConfigNode | 集群元数据管理节点 |
| DataNode | 数据存储与 SQL 执行节点 |
| JIT 模型 | PyTorch 的 Just-In-Time 编译格式,用于部署 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)