TO COT OR NOT TO COT? CHAIN-OF-THOUGHT HELPS MAINLY ON MATH AND SYMBOLIC REASONING
本文通过系统性元分析和多模型实验,揭示了思维链(CoT)提示策略的适用边界。研究发现:1) CoT仅在数学、逻辑等符号运算任务中带来显著性能提升(如MMLU数据集中95%的增益来自含"="的题目),非符号类任务收益有限;2) CoT的优势主要源于优化符号执行过程,但其表现仍不及"语言模型+专用符号求解器"的组合方案。这表明CoT应选择性应用于符号类任务以节省
论文地址:思维链2024
摘要
思维链(Chain-of-Thought, CoT)提示策略已成为激发大型语言模型(LLMs)推理能力的主流方法。但这种额外的“思考过程”究竟对哪些类型的任务真正有效?为解答这一问题,我们开展了一项涵盖100余篇相关论文的定量元分析,并在14个模型上对20个数据集进行了自主评估。结果表明,思维链主要在涉及数学或逻辑的任务中带来显著性能提升,而在其他类型任务上的增益则小得多。在MMLU数据集上,除非问题或模型响应中包含等号(表明涉及符号运算与推理),否则不使用思维链直接生成答案的准确率与使用思维链几乎一致。基于这一发现,我们通过分离规划与执行过程,并与工具增强型大型语言模型进行对比,分析了思维链在这类问题上的表现。思维链的大部分性能提升源于符号执行能力的改善,但相较于使用专门的符号求解器,其表现仍显不足。研究结果表明,思维链可选择性应用,在维持性能的同时降低推理成本。此外,这些发现也意味着,我们需要超越基于提示的思维链范式,转向能在各类大型语言模型应用中更充分利用中间计算过程的新范式¹。
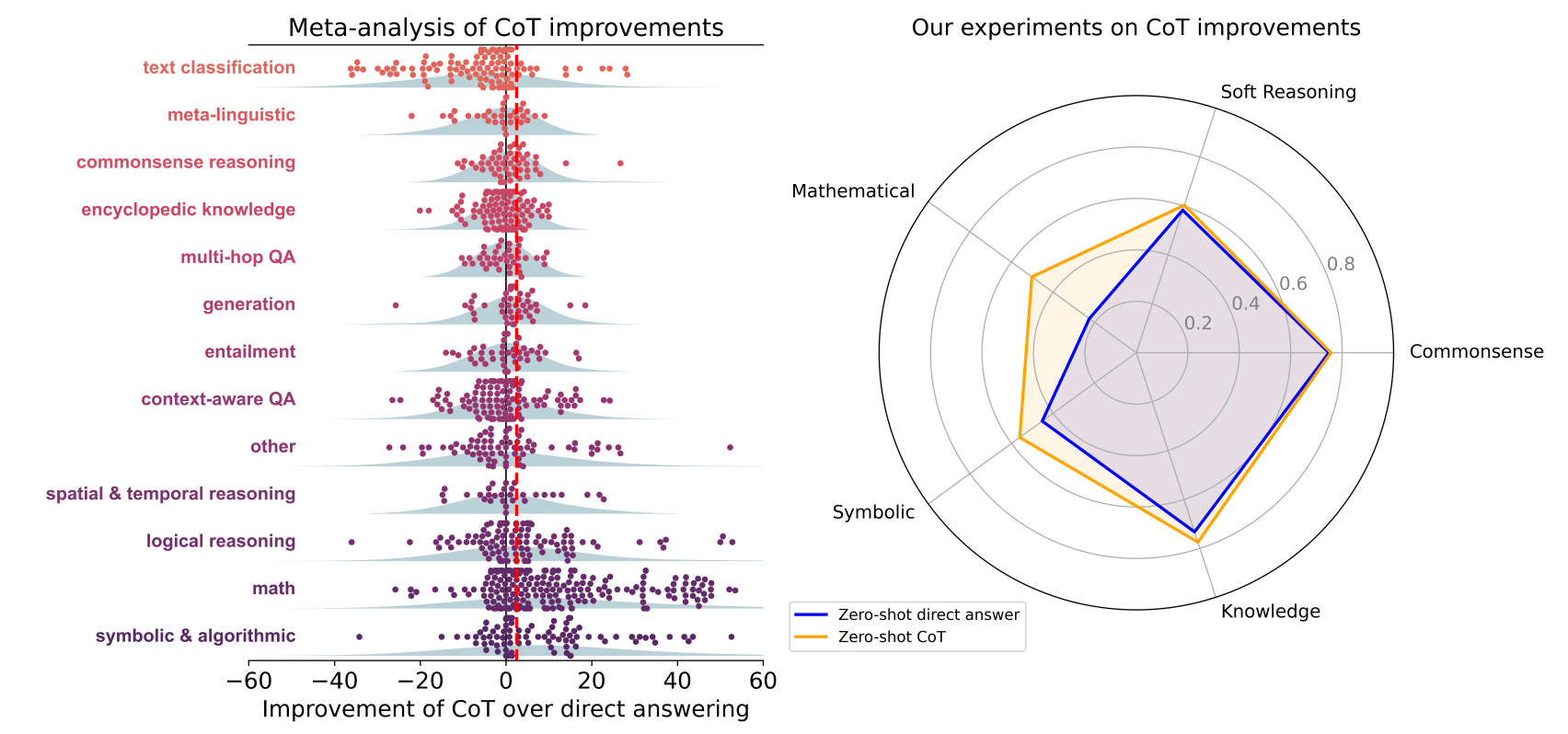
图 1:左图:思维链(CoT)相关文献的元分析结果;每个数据点代表某一(大型语言模型、任务)组合下,思维链相较于直接回答的性能差异(delta 值)。右图:零样本思维链与直接回答提示策略在五大通用推理类别中的平均性能对比,涵盖 20 个数据集,每个数据集均基于 14 个大型语言模型进行评估。两组结果均显示,数学推理及其他各类符号推理是思维链能持续带来显著性能提升的领域(红色虚线表示所有实验中思维链的平均性能提升幅度)。
总结
- 核心结论:思维链的性能增益具有显著任务依赖性,仅在数学、逻辑等涉及符号运算的任务中效果突出,其他任务中优势微弱,可选择性使用以节省推理成本。
- 关键发现:
- 任务适配性:数学/逻辑任务是思维链的核心适用场景,非符号类任务(如简单问答、文本理解)中,思维链与直接生成答案的准确率差异极小;
- 符号运算关键:MMLU数据集上的实验显示,“等号”(符号运算标识)是思维链能否发挥作用的重要信号,无符号运算时思维链价值有限;
- 性能来源与局限:思维链的增益主要来自优化符号执行过程,但在符号运算上的表现仍不及专门的符号求解器。
- 研究意义:
- 实践价值:为思维链的应用提供明确边界(优先用于符号类任务),避免无差别使用导致的推理成本浪费;
- 未来方向:指出需突破传统提示式思维链,探索能更高效利用中间计算的新范式,适配更广泛的大型语言模型应用场景。
1 引言
思维链(Chain-of-Thought, CoT)(Nye等人,2022;Wei等人,2022)已成为激发语言模型推理能力的主流提示技术。思维链能为问题求解过程提供人类可理解的解释(Joshi等人,2023;Lanham等人,2023),但更常见的用途是通过中间计算提升大型语言模型(LLM)解答复杂问题的能力(Madaan & Yazdanbakhsh,2022;Wang等人,2023a;Dziri等人,2023)。当前大型语言模型的训练后方案普遍将思维链能力深度融入模型:ChatGPT或Llama 3.1等系统在遇到推理类问题时,会默认采用思维链策略(OpenAI,2023;Dubey等人,2024)。
思维链的应用范围广泛,但相关研究大多集中于数学推理领域(Zhou等人,2023a;Fu等人,2023;Chae等人,2024;Xu等人,2024b;Qi等人,2024)。事实上,许多针对大型语言模型的“推理”方法仅在数学领域进行评估:例如,Lightman等人(2024)将其论文主题定为“复杂多步推理”,Mixtral-Large²的版本发布则提及“增强模型的推理能力”,但两者均仅报告了在GSM8K和MATH数据集上的性能。尽管众多研究声称思维链具有广泛有效性,但其中多数研究仅聚焦于狭窄的任务范围。在数学之外的领域,研究结果显示思维链的作用有限(Kambhampati等人,2024a),甚至可能损害性能(Wang等人,2024)。
本研究旨在评估基于提示的思维链在哪些场景下有效,以及为何有效。首先,我们对近期比较思维链与直接回答(DA)性能的文献进行了系统性元分析;随后,在零样本和少样本提示设置下,基于20个数据集和14个主流大型语言模型开展实验,进一步完善研究结论。研究发现1:思维链仅在需要数学推理、逻辑推理或算法推理的问题上带来显著提升。图1显示,这一结论在现有文献和我们的自主实验中均成立。我们发现,在其他类型任务中,思维链带来大幅性能提升的案例极少,且这些例外案例大多包含符号推理组件。例如,在MMLU(Hendrycks等人,2021a)和MMLU Pro(Wang等人,2024)数据集上,我们对思维链的性能提升进行分析后发现,思维链仅在数据集的数学子集上有效。在MMLU数据集上,思维链带来的性能提升中,高达95%源于问题或生成输出中包含“=”的题目。对于非数学问题,我们未发现能指示思维链是否有效的特征。
如何更好地理解思维链为何仅能在这类问题上带来提升?我们所研究的数学和形式逻辑推理数据集,其处理过程可拆解为两个阶段:规划阶段(例如,将问题解析为方程式)和执行阶段(生成中间输出并逐步推进至解决方案)(Ye等人,2023;Wang等人,2023b;Sun等人,2024)。研究发现2:思维链主要对执行阶段(涉及计算和符号操作)有帮助,但性能不及工具增强型大型语言模型。我们发现,通过提示启用思维链的语言模型,在生成可执行的形式化解题方案及执行该方案方面,表现优于直接回答。但对于这类任务,采用“语言模型生成解题方案+外部符号求解器执行方案”的组合方式,性能优于思维链同时负责两个阶段的模式。
这些结果表明,思维链的效用往往受限于工具增强技术:在思维链有效的问题上,我们已有比思维链更强大的可用工具;而在常识推理等无专用工具的“软性推理”问题上,思维链的收益有限。这一结论具有两大核心意义。其一,思维链在许多被广泛应用的场景中并非必需:存在更高效的提示策略,能以更低的推理成本实现相当的性能。其二,我们迫切需要超越基于提示的思维链,转向基于搜索、交互智能体或经过深度微调的思维链专用模型等更复杂的方法。未来研究可探索如何更好地利用中间计算,解决数学和符号推理领域之外的挑战性问题。
总结
- 研究背景与动机:思维链是大型语言模型推理的主流技术,但现有研究多局限于数学领域,其在跨任务场景的有效性存疑,本研究旨在明确思维链的适用边界及核心作用机制。
- 两大核心发现:
- 适用场景边界:思维链仅对数学、逻辑、算法类任务(含符号操作)有效,非符号类任务(如常识推理)中收益微弱或无效;MMLU数据集上95%的性能提升来自含“=”的符号类题目,印证了符号操作是思维链的核心适配场景。
- 作用机制与局限:思维链的优势集中在“执行阶段”(计算与符号操作),但“语言模型+外部符号求解器”的组合性能更优,说明思维链在符号执行上仍不及专用工具。
- 核心启示:
- 实践层面:无需在所有任务中盲目使用思维链,可针对性应用于符号类任务以节省推理成本;
- 研究层面:需突破传统提示式思维链,探索搜索、交互智能体等新范式,拓展中间计算在非符号领域的应用。
| 核心维度 | 关键内容 |
|---|---|
| 研究目标 | 明确基于提示的思维链的适用场景及作用机制 |
| 研究方法 | 1. 文献元分析(对比思维链与直接回答的性能);2. 多数据集(20个)、多模型(14个)实验(覆盖零样本/少样本设置) |
| 核心发现1(适用场景) | 仅对数学、逻辑、算法类任务(含符号操作)有效,非符号任务收益有限;符号标识(如“=”)是思维链生效的关键信号 |
| 核心发现2(作用机制) | 主要优化“执行阶段”(计算/符号操作),但性能不及“语言模型+外部符号求解器”的组合 |
| 实践启示 | 1. 选择性使用思维链(优先符号类任务),降低推理成本;2. 替代方案:符号类任务采用“模型生成方案+专用工具执行” |
| 未来研究方向 | 突破传统提示式思维链,探索搜索、交互智能体、深度微调模型等新范式;拓展中间计算在非符号领域的应用 |
2 研究背景:思维链(Chain-of-Thought)
本文研究的任务包含两个核心要素:一是基于词汇表 Σ \Sigma Σ构建的问题 q ∈ Σ ∗ q \in \Sigma^* q∈Σ∗;二是基于标签集合 L ( q ) L(q) L(q)得到的答案 a ∈ L ( q ) a \in L(q) a∈L(q)。标签集合 L ( q ) L(q) L(q)的取值类型多样,可涵盖布尔值、整数等基础数据类型、分类任务标签,或是从问题 q q q中提取的实体名称这类任务相关标签。本研究存在一个例外场景——BiGGen基准数据集(Kim et al., 2024),该数据集不直接定义标签集合,而是借助大语言模型评判器(LLM-as-a-judge)(Dubois et al., 2023; Zheng et al., 2024b),为模型生成的开放式长文本响应标注标签。
推理任务中的提示词与思维链技术
大语言模型会对字符串空间 Σ ∗ \Sigma^* Σ∗中的所有字符串 y y y赋予概率分布,其表达式为 p ( y ) = ∏ i = 1 n p LM ( y i ) p(y) = \prod_{i=1}^n p_{\text{LM}}(y_i) p(y)=∏i=1npLM(yi)。在实际应用中,这一概率分布可被解释为条件概率分布 p ( y ∣ x ) p(y \mid x) p(y∣x),其中 x x x代表用户输入的提示词。
大语言模型的典型调用流程包含三步:
- 构建提示词 I ( q ) I(q) I(q):将问题 q q q与额外指令进行封装;
- 生成模型响应:从条件概率分布 p ( y ∣ I ( q ) ) p(y \mid I(q)) p(y∣I(q))中采样得到输出 y ~ \tilde{y} y~;
- 提取目标答案:通过答案提取器(answer extractor)执行函数 a = extract ( y ~ ) a = \text{extract}(\tilde{y}) a=extract(y~),得到最终答案。
在本文研究的任务中,模型输出 y ~ \tilde{y} y~存在两种形式:
- 直接答案(Direct Answer):输出仅包含答案 a a a对应的字符串。例如,输出令牌序列 y = ( 185 , 4 ) y = (\text{185}, \text{4}) y=(185,4),经过令牌解析后得到答案 a = 1854 a = 1854 a=1854。
- 思维链(Chain of Thought):输出是包含答案及额外推理令牌的长序列。例如,输出令牌序列 y = ( 185 , 6 , minus , 2 , equals , 185 , 4 ) y = (\text{185}, \text{6}, \text{minus}, \text{2}, \text{equals}, \text{185}, \text{4}) y=(185,6,minus,2,equals,185,4)。
两种输出形式均需通过extract函数完成解析与令牌还原;区别在于,思维链输出需要额外定位答案在推理序列中的位置。
本文定义两种提示词策略,分别用于引导模型生成直接答案或思维链推理过程,对应的提示词记为 I d a I_{da} Ida(直接答案提示词)与 I c o t I_{cot} Icot(思维链提示词):
- 引导思维链推理的典型策略是在提示词中加入指令,例如“逐步推理(think step by step)”(Kojima et al., 2022);
- 引导直接输出答案的提示词则会包含类似“直接生成答案(immediately generate the answer)”的指令。
为验证直接答案提示词能让模型在输出开头位置给出答案,我们在附录 F.3 中统计了直接答案提示词与思维链提示词两种策略下,答案在模型输出序列中的平均位置。同时,针对实验中使用的所有模型、提示词与数据集组合,我们均针对性地优化了extract函数,以确保各类模型与任务的答案解析失败率处于较低水平³。所有数据集在各模型上的提示词与输出结果均已上传至 Hugging Face,部分提示词示例详见附录 J。此外,我们还测试了少样本思维链提示词的效果,发现其性能与零样本思维链提示词相近,相关细节见附录 E。
符号推理
本文研究的核心重点之一,是判断任务是否涉及符号推理。我们将符号推理任务定义为:可基于一套通用且公认的形式化系统建模的任务。例如,算术题 12 × 4 12 \times 4 12×4就是典型的符号推理任务,其形式化系统为数学运算规则;其他形式化系统还包括一阶逻辑(Saparov & He, 2023; Hua et al., 2024)、规划语言(Liu et al., 2023a; Valmeekam et al., 2023)等。
从形式化角度看,对于符号推理任务,可定义映射函数 f f f,将问题 q q q转化为符号表达式 S = f ( q ) S = f(q) S=f(q);再将符号表达式 S S S输入求解器,得到答案 a ^ = solve ( S ) \hat{a} = \text{solve}(S) a^=solve(S)。
与之相对的是非符号推理任务。例如,常识问答数据集 CommonsenseQA(Talmor et al., 2019)中的问题“晴天时,在河流的哪个位置可以直立杯子接水?”,就属于非符号推理任务。尽管这类问题可通过谓词逻辑(Zhou et al., 2022; Quan et al., 2024; Zhou et al., 2024)或物理仿真(Hao et al., 2023; Wong et al., 2023)进行形式化建模,但目前尚无通用且公认的标准化求解框架。
我们认为,非符号推理与符号推理并非二元对立,而是构成一个连续的光谱。例如,MuSR 数据集(Sprague et al., 2024)属于“半符号”数据集:该数据集包含底层形式化系统(如在谋杀谜案任务中,遵循逻辑规则 motive ( X ) ∧ means ( X ) ∧ opportunity ( X ) ⟹ murderer ( X ) \text{motive}(X) \land \text{means}(X) \land \text{opportunity}(X) \implies \text{murderer}(X) motive(X)∧means(X)∧opportunity(X)⟹murderer(X)),但同时需要大量无法被形式化系统覆盖的常识推理。对于这类半符号任务,虽然仍可定义函数 f f f生成符号表达式 S = f ( q ) S = f(q) S=f(q),但函数 f f f的构建高度依赖大语言模型,且需要为 S S S补充问题 q q q中未直接体现的新信息。
现有研究普遍认为,思维链提示词 I c o t I_{cot} Icot在几乎所有推理任务中,性能均优于直接答案提示词 I d a I_{da} Ida,无论任务属于符号推理还是非符号推理。然而,本文的实验证据并不支持这一猜想。我们将证明:思维链技术的性能优势在符号推理与半符号推理任务中最为显著;而在非符号推理任务中,思维链技术几乎无法带来性能提升,甚至可能导致性能下降。
Table 1: A few categories for experimental comparisons. Full list in Appendix B
总结
- 任务定义:本文研究的推理任务由问题 q ∈ Σ ∗ q \in \Sigma^* q∈Σ∗和答案 a ∈ L ( q ) a \in L(q) a∈L(q)构成,唯一例外是 BiGGen 数据集,需借助大语言模型评判器为长文本输出标注标签。
- LLM 推理调用流程:封装问题得到提示词 I ( q ) I(q) I(q)→ 从条件概率分布 p ( y ∣ I ( q ) ) p(y \mid I(q)) p(y∣I(q))采样输出 y ~ \tilde{y} y~→ 用
extract函数提取答案 a a a;模型输出分为直接答案和思维链两种形式,后者需额外定位答案位置。 - 两种提示词策略:直接答案提示词 I d a I_{da} Ida引导模型直接输出结果,思维链提示词 I c o t I_{cot} Icot以“逐步推理”等指令引导模型生成推理过程;实验验证了少样本与零样本 CoT 性能相近,且已开源相关提示词与输出数据。
- 推理任务分类:提出符号推理、半符号推理、非符号推理的连续光谱分类法。符号任务可基于公认形式化系统建模(如算术运算);非符号任务无标准化求解框架(如部分常识问答);半符号任务兼具形式化逻辑与常识推理需求(如 MuSR 数据集)。
- 核心研究结论:挑战了“思维链技术对所有推理任务均有效”的传统认知,证明其优势仅体现在符号与半符号推理任务中,在非符号推理任务中效果有限甚至会降低性能。
3 文献研究结果
筛选标准与流程
我们调研了机器学习领域代表性会议ICLR 2024,以及自然语言处理领域代表性会议EACL 2024、NAACL 2024(含发现论文与 workshop 论文)的所有论文,共得到4642篇论文。通过自动与人工筛选,最终保留了对比思维链提示词 I c o t I_{cot} Icot与直接回答提示词 I d i r e c t I_{direct} Idirect实验效果的论文,共110篇,包含1218组实验对比。随后,我们将这些对比结果按任务类型与数据集类型进行分组。关于自动/人工筛选流程及分类方法的更多细节,详见附录A与附录B。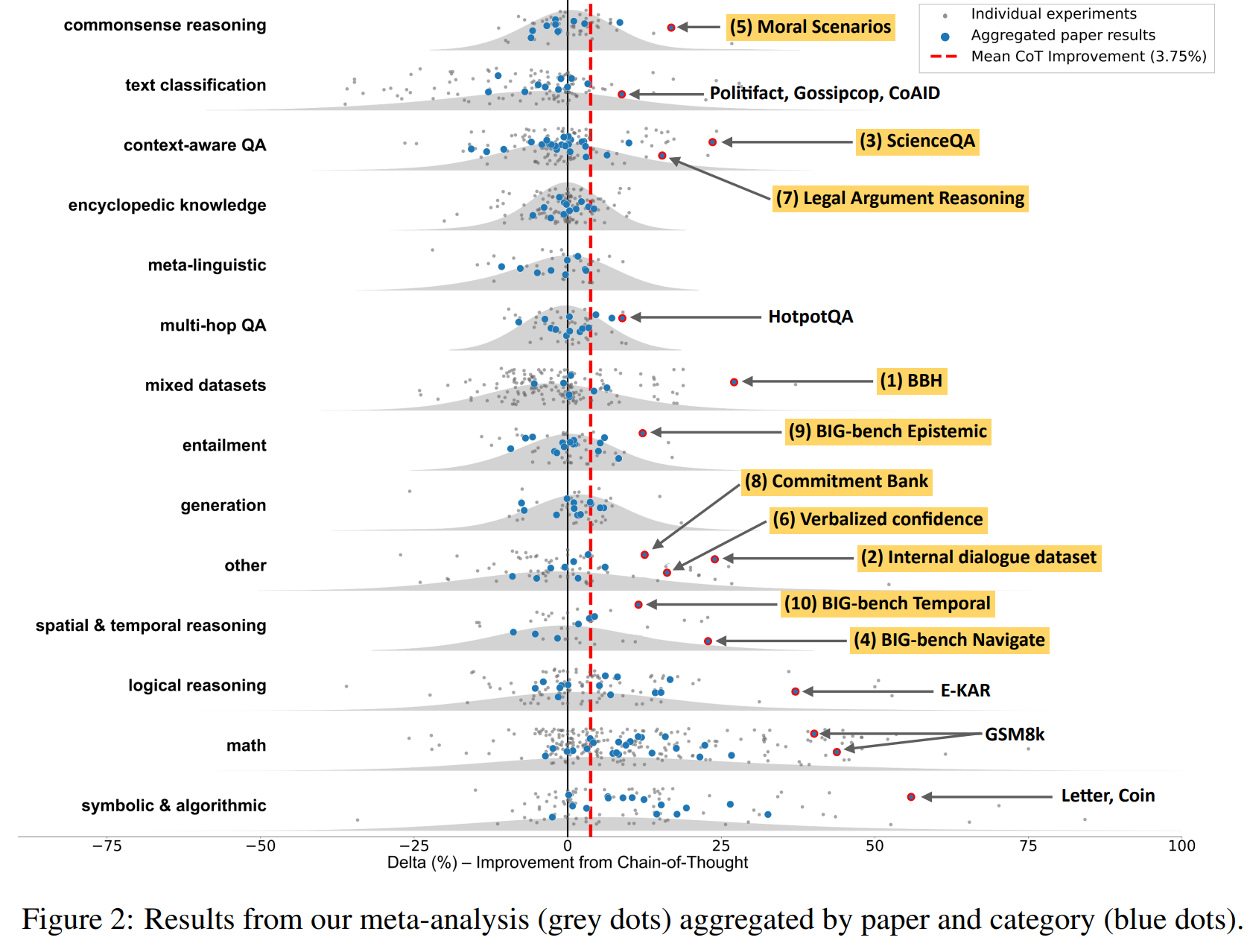
结果分析
图2展示了不同任务类型下,思维链技术的性能增量(即“思维链提示词性能 - 直接回答提示词性能”)的分布情况。与图1不同,此处我们以蓝色圆点表示每篇论文在对应类别下的平均结果,以此体现文献中各论文的趋势。任务类别按“思维链性能增量的中位数”升序排列:
- 思维链技术受益最显著的三类任务是符号推理、数学运算、逻辑推理,平均性能提升分别为14.2、12.3、6.9;
- 这三类任务在使用思维链技术时的平均性能为56.9,未使用时为45.5。
对于其他任务类别,使用思维链技术的平均性能为56.8,未使用时为56.1——这一微小提升不足以证明思维链技术的优势:思维链推理的计算成本高于直接回答,若要公平对比两种方法,需匹配二者的计算资源(例如对多个提示词进行集成)。
非数学类数据集是否受益于思维链技术?
在图2的右侧,我们展示了偏离整体趋势的前10个“异常值”——即非数学、非符号、非逻辑推理类任务中,思维链性能增量较高的论文。尽管这些任务未被归类为数学或逻辑类,但其中多数仍与逻辑、数学或符号推理存在关联:
- 受益最显著的数据集是BIG-bench Hard(BBH)(Suzgun et al., 2023),该基准主要包含需要算法、算术或逻辑推理的问题。例如,BIG-bench Navigate是空间推理任务,但高度依赖“统计步数”这一数学基础操作;BIG-bench Temporal是时间推理任务(回答事件发生的时间),但需要演绎推理才能解决。
- 法律论证推理(SemEval-2024 Task 5)(Bongard et al., 2022)被归类为“上下文感知问答”,但也需要较强的推理能力。
- MMLU-道德场景(Hendrycks et al., 2021a)需要同时回答两个独立问题,本质上是对两个简单问题的符号化组合。
总结
- 筛选范围与结果:调研了ICLR、EACL、NAACL 2024的4642篇论文,最终筛选出110篇对比 I c o t I_{cot} Icot与 I d i r e c t I_{direct} Idirect的论文,共1218组实验。
- 思维链技术的受益任务:符号推理、数学运算、逻辑推理是受益最显著的三类任务,平均性能提升超6.9;其他任务中思维链的性能提升仅0.7,且未匹配计算资源的对比不够公平。
- 非数学类任务的“异常值”分析:看似受益于思维链的非数学类任务(如BBH、法律论证推理),实际仍依赖逻辑/数学/符号推理能力;这进一步验证了“思维链的优势局限于需形式化推理的任务”的结论。
4 实验结果
4.1 实验设置
数据集、模型与提示词
本实验使用的所有数据集、模型及提示词的详细信息,可参见附录C的表3、表4与表5。我们将实验限定于英语大语言模型(这类模型在通用推理数据集上的基准测试较为常见),数据集则选取了思维链与推理领域的常用数据集,涵盖非符号、半符号与符号推理三类任务,格式包括选择题、简答题与开放式回答(但多数为选择题/简答题,因思维链技术通常不用于长文本回答场景)。
我们将每个数据集按所需推理类型归为五大类:常识推理、知识推理、符号推理、数学推理、软推理(软推理指依赖常识与自然语言、但需超越简单推断的问题)。
此外,我们测试了多种引导模型推理的提示词策略(过往研究强调提示词的重要性(Yang et al., 2024)),但发现不同策略的性能差异较小(详见附录D)。因此,我们主要采用与Kojima et al. (2022)、Wei et al. (2022) 相近的提示词(分别对应零样本与少样本场景),并对格式进行微调以提升模型输出的可解析性。所有模型、提示词策略对应的提示词与输出结果均已上传至Hugging Face⁴。
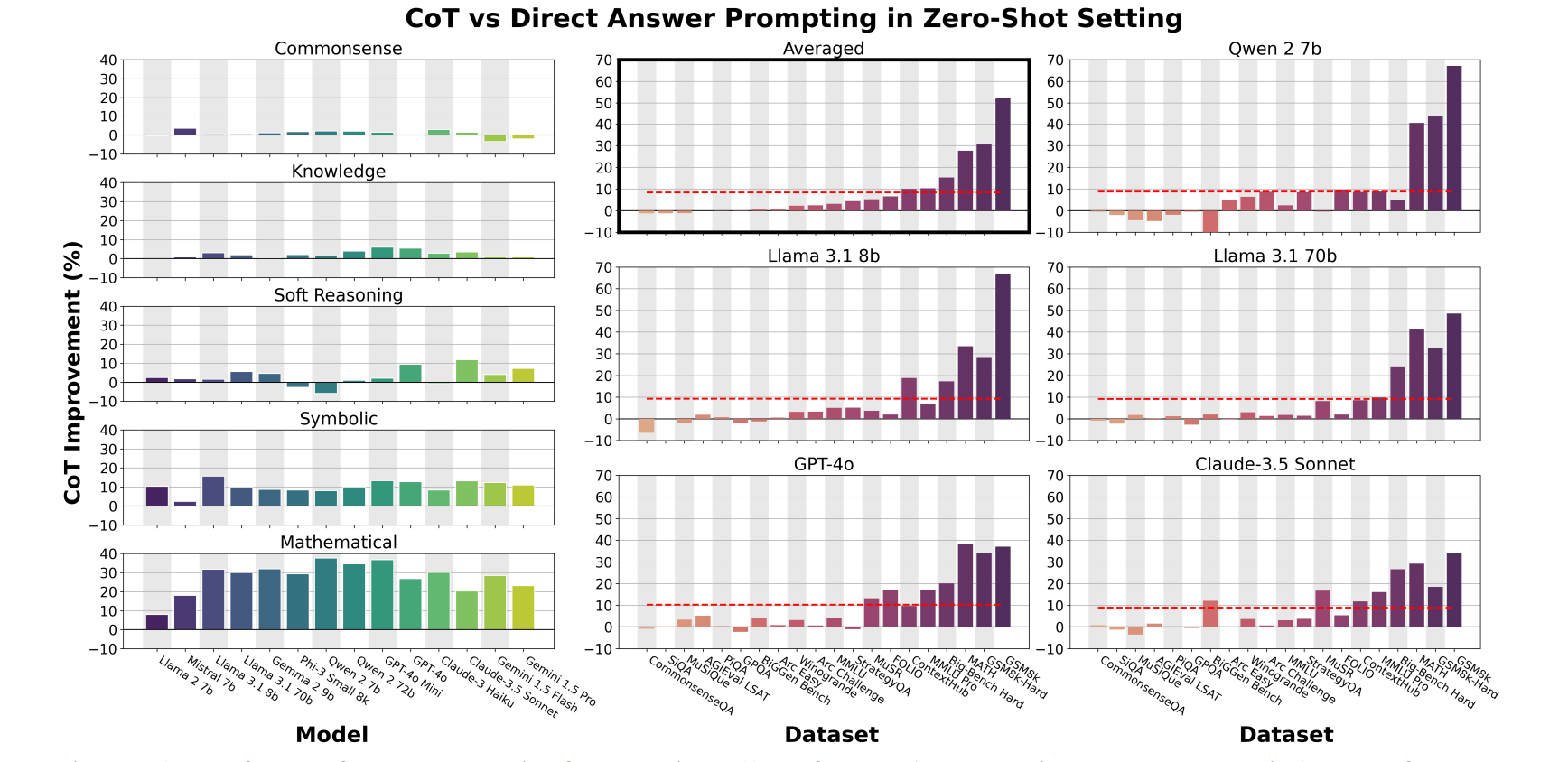
图3:左图:展示了在每种推理类别中使用思维链提示方法所带来的性能增益。右图:展示了在每个数据集上使用思维链提示方法的性能增益(该结果是各模型性能的平均值),并拆解展示了五个代表性模型的具体情况。图中的红线表示性能提升的中位数。从两幅图中我们观察到一个一致的趋势:使用思维链带来的性能提升,大部分来自数学推理和符号推理任务。
实现细节
模型推理过程使用高吞吐量推理工具包vLLM(Kwon et al., 2023),所有模型均采用贪心解码策略。提示词优先选用Llama 3.1评估任务中的标准提示词(Dubey et al., 2024),并做少量调整以统一策略;其他数据集的提示词则取自原论文的标准版本,或由我们自行设计。答案解析器(extract)针对每个数据集与模型进行了定制化适配,具体细节见附录C。
4.2 实验结果
零样本思维链在哪些场景下优于直接提示词?
仅在**需要数学运算(MATH、GSM8K)或形式逻辑推理(ContextHub、MuSR,后者提升较弱)**的数据集上,零样本思维链的性能更优。
图3左侧展示了图1右侧各推理类别的思维链平均性能提升(原始数据见附录表6);右侧则展示了每个数据集在所有模型及部分单个模型上的思维链性能增益:
- 在非符号推理类任务/数据集(如常识推理(CSQA、PIQA、SiQA)、语言理解(WinoGrande)、阅读理解(AGI LSAT、ARC-Easy、ARC-Challenge))中,零样本思维链与零样本直接回答的性能几乎无差异——尽管这些任务涉及推理,但思维链并未带来提升。
- 而在数学与符号推理类任务/数据集中,思维链的性能提升更为显著:MATH与GSM8K的性能增益分别高达41.6%与66.9%;半符号数据集(如ContextHub、MuSR谋杀谜案)也获得了中等程度的提升(这类数据集需要应用逻辑规则解题,例如从自然语言中解析出的一阶逻辑(ContextHub),或复杂常识语句对应的逻辑(MuSR谋杀谜案))。
所有结果详见附录F.1,思维链与直接回答的完整数值结果见附录表7。我们也测试了少样本场景,发现其对“思维链的适用范围”无显著影响(详见附录E)。
答案格式是否会影响思维链的效果?
影响较小。BiGGen Bench所需的开放式回答场景,可能无法从“提前规划”中受益。
多数非数学类常用数据集为选择题,此处我们重点分析两个非选择题、且包含不同程度非符号推理的数据集:
- MuSiQue(Trivedi et al., 2022):短文本多跳问答任务,属于半符号数据集(问题具有明确的多跳结构)。由于该数据集的答案可被多种方式改写,我们使用GPT-4o判断两个答案是否等价——尽管属于半符号任务,思维链未带来整体性能提升。
- BiGGen Bench(Kim et al., 2024):开放式回答任务,由大语言模型评判器对回答进行1-5分的评分。由于开放式回答模糊了“思维链”与“直接回答”的边界,我们设计了新提示词引导模型“先规划回答再输出”,并仅将最终回答提交给评判器(本实验使用GPT-4o-mini),同时排除了包含“逐步推理”指令的问题。我们以“回答得分≥4的次数”衡量性能:尽管该数据集包含大量推理题(含多类数学题)与规划类问题,但思维链仅带来轻微提升。结合过往实验中“思维链在问答格式的同类问题中有效”的结论,此处的效果缺失可能表明“提前规划不足以解锁大语言模型的推理能力”,这一猜想需后续研究验证。
思维链在知识推理、软推理与常识推理中的增益是否显著?
多数不显著,仅在MMLU、StrategyQA与MuSR中存在显著提升。
我们使用配对Bootstrap法,对知识推理、软推理、常识推理类的13个数据集进行显著性检验,并通过Bonferroni校正(将p值设为0.00027,以适配14个模型×13个数据集的多组比较):
- 仅约32%(59组)的对比中,思维链的提升具有显著性;
- 其中近一半(26组)来自MMLU与MMLU Pro——进一步分析发现,这两个数据集的性能增益主要来自其中的数学相关问题(详见附录G);
- StrategyQA与MuSR也在10个、6个模型上获得了稳定提升:StrategyQA是专门用于测试“问题分解类方法”的基准,思维链提升性能符合预期;MuSR包含多步骤复杂自然语言推理,因此也能从思维链中受益;
- 其余具有显著增益的情况则分散在不同数据集与模型中。
为何MMLU与MMLU Pro能从思维链中受益?
MMLU与MMLU Pro包含多种推理类型的问题,我们将其问题分为“数学相关”与“非数学相关”两类(通过检查问题文本或模型输出中是否包含“=”判断)。图4显示:这两个数据集的性能增益,主要来自其中的数学类问题(详见附录G)。
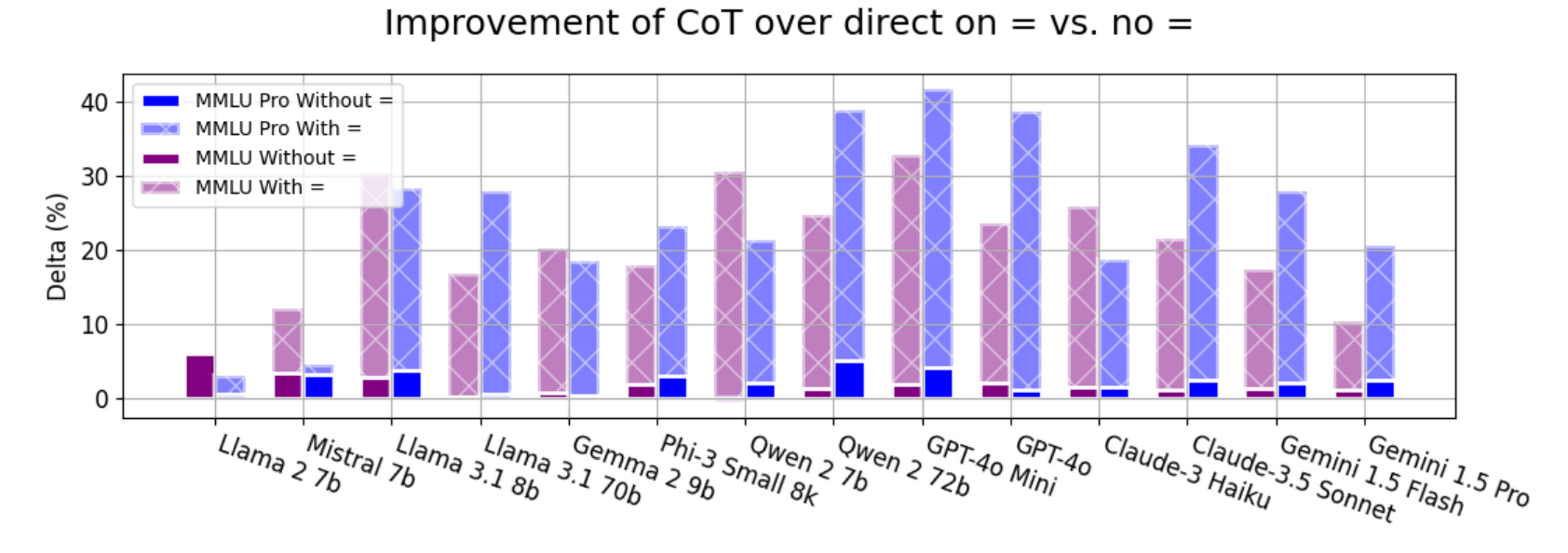
图4:当题目(问题)或模型生成的回答中包含“=”符号(With =)与不包含“=”符号(Without =)时,模型在MMLU和MMLU Pro两个基准测试上使用思维链提示前后的性能变化差值(CoT deltas)。我们过滤掉了那些未产生最终答案(如退化、无输出等)的问题。结果显示,思维链提示主要对包含“=”符号的题目和回答组合有显著帮助,这表明其提升主要集中在与数学相关的问题上。
总结
- 思维链的有效场景:仅在数学运算、符号/半符号逻辑推理类任务中显著提升性能(如MATH、GSM8K增益超40%);非符号推理类任务(常识、语言理解等)中无明显效果。
- 答案格式的影响:答案格式(选择题/简答题/开放式)对思维链的效果影响较小,开放式回答的BiGGen Bench中思维链仅带来轻微提升。
- 非符号推理的显著性:知识、软推理、常识类任务中,仅MMLU(数学子问题)、StrategyQA(问题分解类)、MuSR(多步骤推理)的思维链增益具有显著性。
- MMLU的增益来源:MMLU与MMLU Pro的性能提升,本质是其包含的数学类问题从思维链中受益,非数学问题无明显提升。
5 思维链技术在形式化推理中的优势与局限性
前文已证实思维链技术主要对符号推理任务有效,但尚未阐明背后的原因。
大量符号推理与半符号推理任务可被拆解为两个阶段(Ye et al., 2023; Pan et al., 2023; Jiang et al., 2024):
- 规划阶段:通过提示词给出的形式化或非形式化指令完成任务规划(Sun et al., 2024; Wang et al., 2023b);
- 执行阶段:利用大语言模型自身或外部求解器完成规划的执行。
本节将思维链在符号推理任务中的性能增益,归因于这两个阶段的协同作用。
对于一个需要符号推理的问题,我们将规划阶段定义为:从问题上下文提取所有变量,构建形式化规范,并定义变量间的关系。
执行阶段则是利用求解器,以规划结果为输入,按序执行推导得到最终答案。
结合第2节的符号体系,我们定义映射函数 f ( q ) = I p l a n n i n g ( q ) f(q)=I_{planning}(q) f(q)=Iplanning(q),将问题 q q q 转化为可被大语言模型或外部符号求解器执行的符号规划 S p l a n S_{plan} Splan,最终答案可表示为 a ^ = s o l v e ( S p l a n ) \hat{a}=solve(S_{plan}) a^=solve(Splan)。
通过拆分规划与执行两个阶段,我们可以对比三种场景的性能差异:仅提供规划、基于规划结合思维链执行、基于规划结合外部符号求解器执行。
给定由 I p l a n n i n g ( q ) I_{planning}(q) Iplanning(q) 生成的规划 S p l a n S_{plan} Splan,我们通过对比不同实验设置的性能,分析大语言模型在哪个阶段表现最优、在哪个阶段存在局限。
5.1 评估的实验设置
设置1与设置2:少样本直接回答与少样本思维链
我们将4.1节中使用的少样本直接回答提示词 I d i r e c t I_{direct} Idirect 与少样本思维链提示词 I c o t I_{cot} Icot 作为基准方法。图5展示了两种设置在GSM8K数据集上的示例。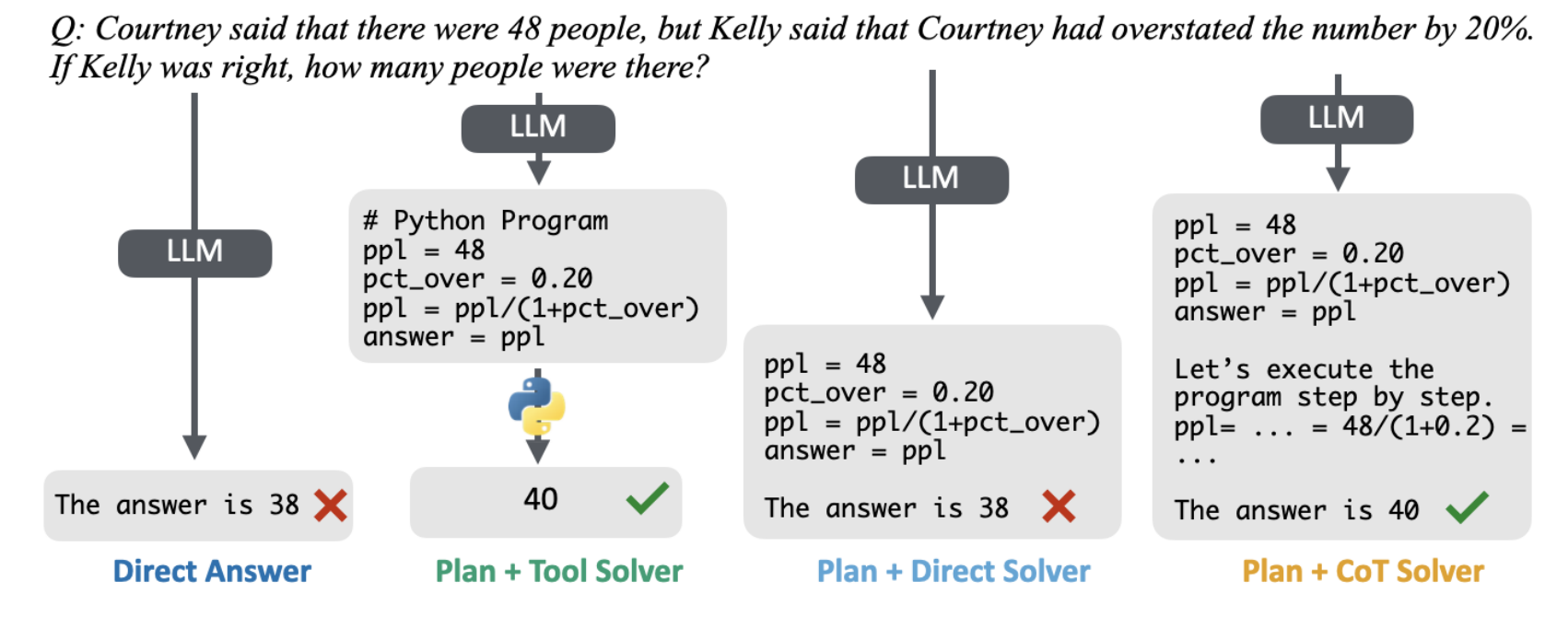
图5:展示了在GSM8K(数学应用题)数据集上,将“规划”与“执行”分离的几种提示词变体。除了“直接回答”和“思维链”方法(图中未展示)之外的所有变体,我们都采用少样本提示的方式,让大语言模型首先生成一个Python程序作为解决方案的“规划”。对于 “规划 + 直接求解” 变体,我们提示模型根据这个规划直接给出最终答案;对于 “规划 + 思维链求解” 变体,我们提示模型使用思维链对规划进行一步步求解,然后给出答案;对于 “规划 + 工具求解” 变体,我们将生成的规划直接输入到一个Python解释器中执行。
设置3与设置4:规划+直接求解器、规划+思维链求解器
这两种设置借鉴了Xu et al. (2024a)的思路,并采用Ye et al. (2023)的策略生成符号规划。
具体来说,我们使用少样本规划提示词 I p l a n n i n g I_{planning} Iplanning 生成可被符号求解器执行的形式化规范 S p l a n S_{plan} Splan;
同时引导大语言模型求解该规范并输出最终答案 y ~ ∼ p ( y ∣ I d a ( S p l a n ) ) \tilde{y}\sim p(y\mid I_{da}(S_{plan})) y~∼p(y∣Ida(Splan)),具体分为两种方式:
- 规划+直接求解器:生成规划后直接输出答案;
- 规划+思维链求解器:生成规划后,通过逐步解释与中间步骤追踪完成推导。
需要说明的是,针对数学数据集, S p l a n S_{plan} Splan 是一段Python程序;针对逻辑推理数据集, S p l a n S_{plan} Splan 是一组一阶逻辑规范。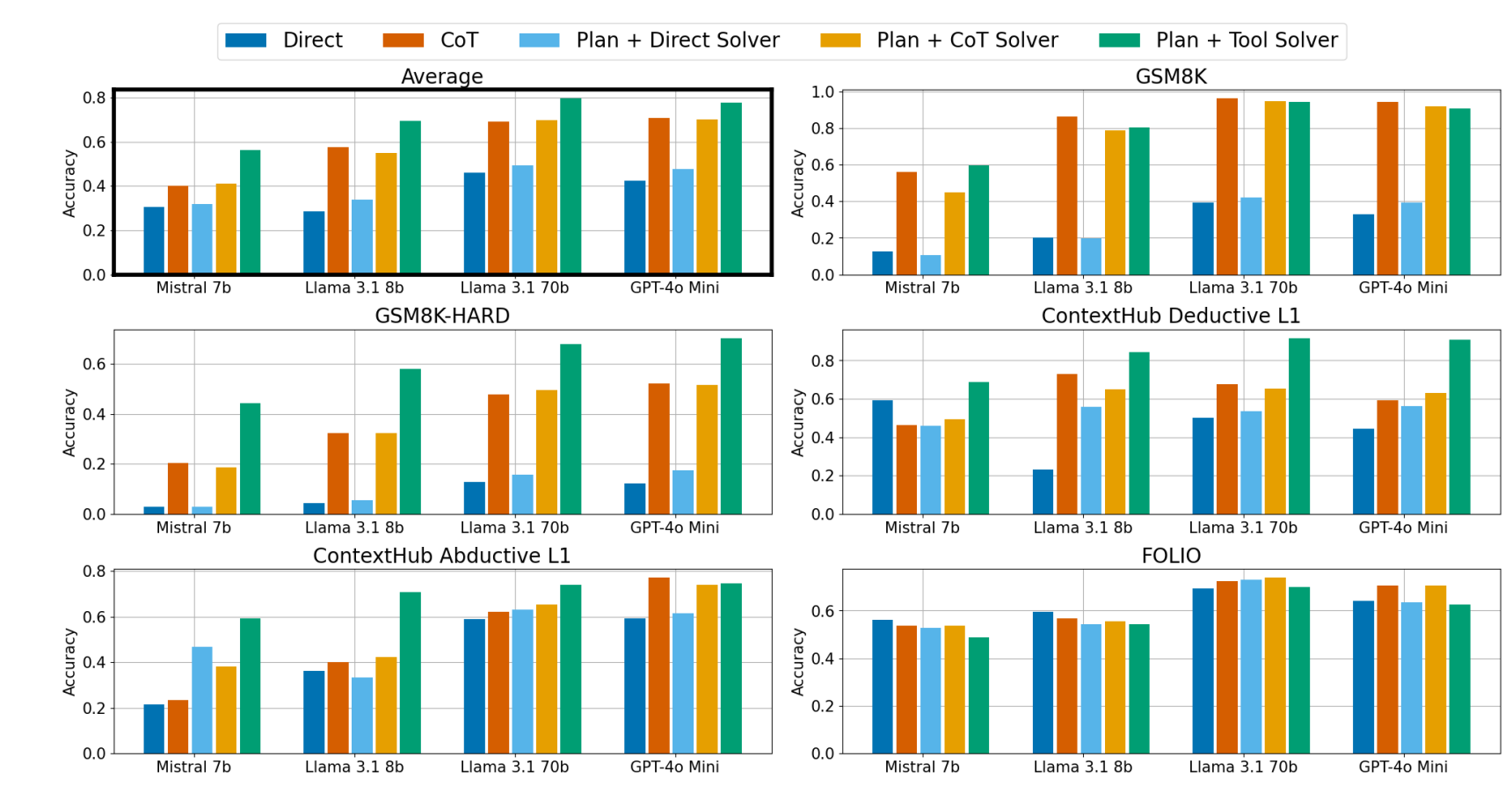
图6:展示了在数学和逻辑推理数据集上,采用“规划与执行分离”的各类提示词变体的性能表现。尽管在执行一个已制定的形式化规划并推导最终答案方面,思维链方法优于直接回答法,但它在执行符号计算方面仍然存在局限:在所有模型上的平均表现中,“规划 + 工具求解”方法相比“纯思维链”和“规划 + 思维链求解”方法,带来了大幅的性能提升。
设置5:规划+工具求解器
为对比思维链与外部符号求解器在符号计算中的效果,我们沿用“规划+思维链求解器”的规划生成方式得到 S p l a n S_{plan} Splan,但将其输入外部符号求解器(Python解释器或SMT求解器),最终答案同样表示为 a ^ = s o l v e ( S p l a n ) \hat{a}=solve(S_{plan}) a^=solve(Splan)。
该设置的设计参考了过往“为大语言模型配备工具以解决数学与逻辑问题”的相关研究(Ye et al., 2023; Pan et al., 2023; Gao et al., 2023; Chen et al., 2023)。
评估实验配置
我们在三类数据集上对比所有设置的性能:数学推理数据集(GSM8K)、逻辑推理数据集(ContextHub、FOLIO)。
同时,参考Gao et al. (2023)的方法引入GSM8K-Hard数据集——这是GSM8K的微调版本,通过替换原数据集中的数字为更大数值构建,用于排除“大语言模型因数据污染过拟合GSM8K”的可能性(Zhang et al., 2024)。
在“规划+直接求解器”与“规划+思维链求解器”设置中,我们使用Ye et al. (2023)提出的少样本提示词;
在“规划+工具求解器”设置中,我们采用当前最优的工具增强提示词技术:
- 针对GSM8K数据集,使用程序增强语言模型(PAL)(Gao et al., 2023),通过Python解释器执行大语言模型生成的规划;
- 针对逻辑推理数据集,使用可满足性增强语言模型(SatLM)(Ye et al., 2023),借助自动定理证明器Z3(De Moura & Bjørner, 2008)求解生成的逻辑规范。
若工具无法解析大语言模型生成的规划,对于选择题我们采用随机猜测策略,最终在一组有代表性的模型上完成全流程评估。
模型生成规划的解析失败率等详细数值结果,详见附录H。
实验结论
- 对比直接回答、规划+直接求解器、规划+思维链求解器三种设置可知:对于多数数据集与模型,仅依赖规划无法带来显著的性能增益;相较于直接回答,必须结合思维链(即规划+思维链求解器)才能实现高性能。通过思维链追踪执行步骤的方式,能最大程度提升准确率,在数学密集型数据集上效果尤为突出。
- 尽管思维链与规划+思维链求解器的性能优于直接回答与规划+直接求解器,但在多数场景下仍显著弱于规划+工具求解器。这表明,与专业符号求解器相比,大语言模型在执行步骤追踪与符号计算方面存在固有局限性。
- 上述结果解释了思维链技术对符号推理任务有效的核心原因:虽然所有任务理论上都能从“问题求解步骤描述(即本节定义的规划)”中受益,但只有当求解步骤需要大量追踪与计算时,思维链的性能才会超过直接回答。在此类场景下,符号求解器的性能优势十分明显,而思维链本质上是对专业求解器的一种性能欠佳但通用性强的近似方案。
- 核心建议:在解决符号推理任务时,若条件允许,应在推理阶段为大语言模型配备外部符号求解器,以获得远超直接回答与思维链技术的稳定性能提升。
总结
- 任务拆分逻辑:符号/半符号推理任务可拆分为“规划(提取变量、构建形式化规范)”与“执行(推导答案)”两个阶段,思维链的性能增益源于对两阶段的协同优化。
- 五种实验设置:设计少样本直接回答、少样本思维链、规划+直接求解器、规划+思维链求解器、规划+工具求解器五种设置,在数学与逻辑推理数据集上开展对比评估。
- 核心实验结论
- 仅靠规划无法显著提升性能,必须结合思维链追踪执行步骤才能发挥作用;
- 思维链的执行效果远弱于专业外部符号求解器;
- 思维链是符号求解器的“通用但低效”近似方案,符号推理任务优先选择“大语言模型+外部求解器”的组合。
6 讨论与相关工作
思维链技术在哪些场景有效?背后原因是什么?
本文实验显示,思维链技术在数学与逻辑推理任务上的性能提升,与早期针对大语言模型的思维链相关研究(如草稿本技术 Scratchpads(Nye et al., 2022))结论高度一致。随着思维链技术的普及,其应用范围逐渐扩展至本质上无需多步推理的任务——在这类任务中,思维链通常仅能带来小幅性能提升。
这一现象催生了当前学界的主流观点:任何涉及推理的任务,都能通过显式推理过程(如思维链)提升性能(即本文第2节提出的初始假设)。然而,我们的实验结果明确区分了思维链在非符号推理与符号推理任务中的性能差异。
若理论上所有问题都能从显式推理中受益,为何思维链仅对可通过符号操作解决的问题有效?第5节的实验结果给出了答案:思维链的核心优势在于其能够执行符号步骤并追踪中间输出。并非所有任务都具备这一特性:例如,常识问答数据集 CommonsenseQA 的问题几乎无法转化为可形式化、可执行的求解规划;像 StrategyQA 这类虽包含多步推理的数据集,其推理步骤的执行过程并不复杂,因此思维链带来的性能提升十分有限。
未来研究可进一步探索两个方向:一是能否通过向模型注入特定的推理模式(如选择题的排除法),提升思维链在非符号推理任务中的效果;二是当前思维链在非符号任务中的局限性,是否由模型预训练数据的固有缺陷导致。
能否进一步优化思维链技术?
本文的研究对象主要是不涉及多轮模型调用的基础思维链变体。现有研究表明,增加大语言模型的调用次数(如思路树 ToT(Yao et al., 2023)等方法(Du et al., 2023; Besta et al., 2023; Chen et al., 2024))能够提升性能,但这类方法的计算成本显著增加;且部分严谨的基准测试显示,简单的基础方法与复杂的迭代方法性能相当(Olausson et al., 2024)。
另一方面,过往的理论研究指出,思维链从本质上增强了Transformer模型的推理能力(Liu et al., 2023b; Merrill & Sabharwal, 2024)——这表明思维链技术的优化潜力不止于现有的提示词工程层面。此外,近期部分研究提出“内化思维链”的方法并取得了性能增益(Deng et al., 2024),这一现象暗示,显式生成中间推理令牌的传统思维链模式,其潜力尚未被完全挖掘。
研究局限性
本研究的实验未覆盖长程规划类任务(仅在 BiGGen Bench 数据集中有所涉及),但已有大量文献探讨了思维链在规划任务中的有效性。此外,本文未深入分析部分模型在实验数据集上存在的数据污染问题,我们通过引入多个模型、新旧混合的数据集,以及元分析等方式,尽可能降低了数据污染对实验结果的影响。关于长程规划与数据污染的更多讨论,详见附录I。
总结
- 思维链的有效场景与核心原因:思维链仅在符号推理任务中效果显著,核心优势是执行符号步骤并追踪中间输出;非符号任务(如常识问答)难以转化为形式化求解规划,因此思维链的提升效果有限。
- 思维链技术的优化方向:现有多轮调用类优化方法成本高且收益有限;理论研究表明思维链可从本质上增强Transformer能力,存在超越提示词工程的优化空间;“内化思维链”等新思路暗示传统显式推理模式有进一步挖掘的潜力。
- 研究局限性:未充分覆盖长程规划类任务,未深入分析数据污染问题,后续可结合附录I的内容拓展相关研究。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)