论文阅读:Training compute-optimal large language models
固定模型大小,变化训练序列长度 (与kaplan等人不同的是,针对每一次训练运行,都调整了学习率的 Cosine 衰减周期,使其与计划的训练 Token 数相匹配),得到给定计算量下的的最低损失,对于任意给定的计算预算C,找出能达到最低 Loss 的模型大小N和数据量D,并通过拟合幂律公式。使用IsoFLOP轮廓,选定了 9 个固定的计算预算训练了多种不同大小的模型(对于特定的预算,当模型变大时,
Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
引言
DeepMind 团队通过训练 400 多个模型(参数量从 7000 万到 160 亿,数据量从 50 亿到 5000 亿 Token),重新研究了模型大小与训练数据量的权衡。他们发现目前的许多大模型都严重训练不足(Undertrained)。对于计算最优的训练,模型大小和训练 Token 数量应该以相等的比例进行扩展。也就是说,每当模型大小翻倍时,训练数据量也应该翻倍。【注意,这同kaplan等人提出的“计算预算增加 10 倍时,模型大小应增加 5.5 倍,而训练数据量(Token 数)仅需增加 1.8 倍 ”的结论不同】
估计最优参数/训练Token分配
核心问题:给定固定的计算预算(FLOPs),应如何权衡模型大小(N)和训练 Token 数量(D)以最小化预训练损失。为此使用三种不同的实验和分析方法进行探索:
-
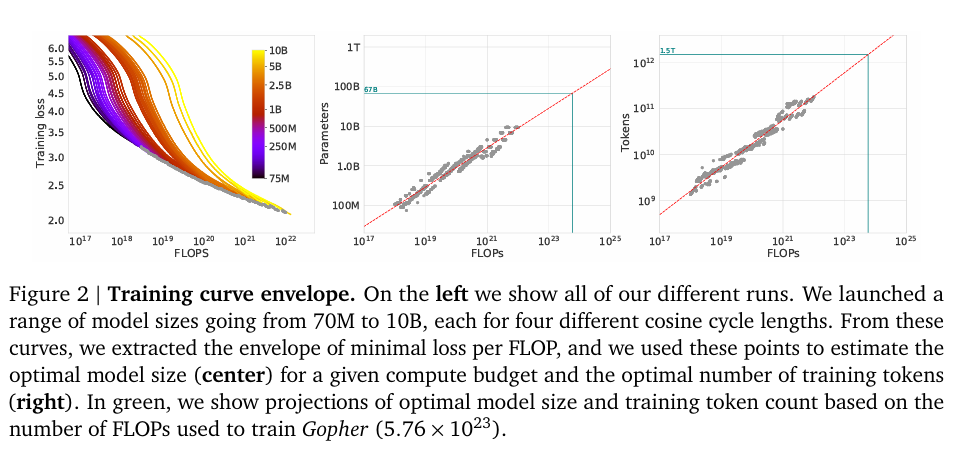
固定模型大小,变化训练序列长度 (与kaplan等人不同的是,针对每一次训练运行,都调整了学习率的 Cosine 衰减周期,使其与计划的训练 Token 数相匹配),得到给定计算量下的的最低损失,对于任意给定的计算预算C,找出能达到最低 Loss 的模型大小N和数据量D,并通过拟合幂律公式
和
,计算出系数a和b,结果a=b=0.5,这意味着计算量增加时,模型大小和数据量应同比例增加。
-
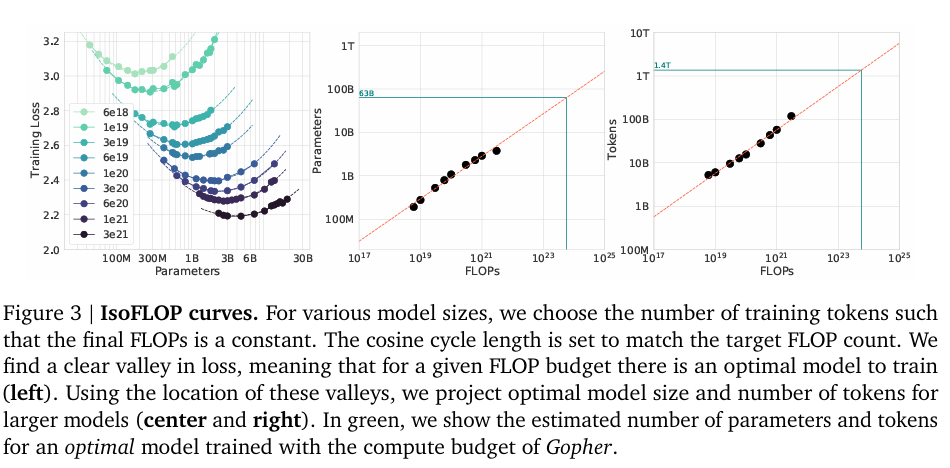
使用IsoFLOP轮廓,选定了 9 个固定的计算预算训练了多种不同大小的模型(对于特定的预算,当模型变大时,训练的 Token 数就相应减少),根据loss最小的位置再次拟合幂律关系,a=0.49,b=0.51
-
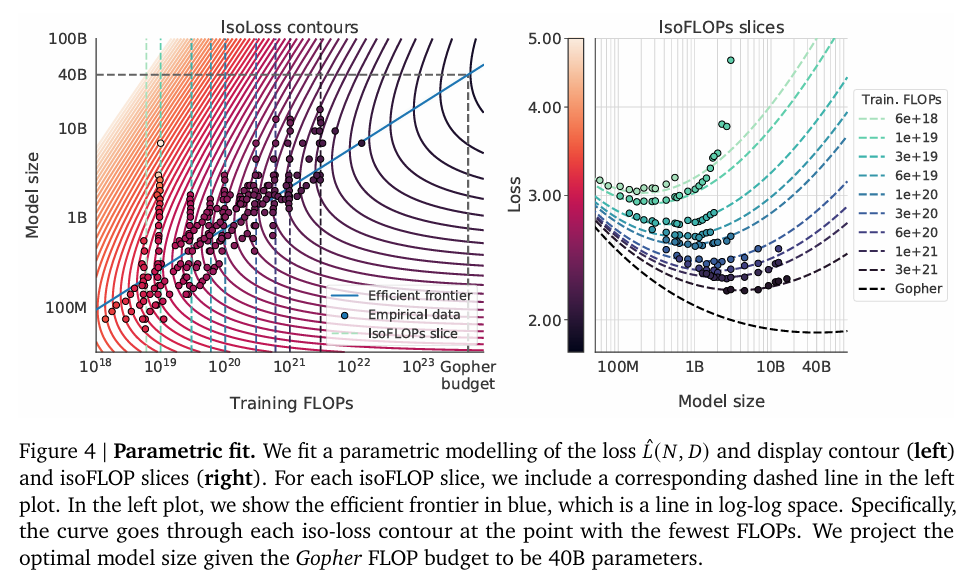
拟合参数化损失函数,基于风险分解提出了一个包含三个项的损失函数公式 :
,其中E是理想生成过程的损失,
是由于模型大小有限而导致的误差,
是由于训练数据量(优化步数)有限导致的误差,使用 L-BFGS 算法最小化预测损失与实际观察到的损失之间的差异并确定参数,得到a=0.46,b=0.54
得到了与Kaplan等人不同的结论,即为了保持计算最优,模型参数量和训练 Token 数量应该以大致相等的比例增长(Kaplan等人此前的结论导致人们过分追求大参数量而忽略了数据量),进一步得到了此前几个大模型应该具有的最优大小以及需要使用的数据量大小,特定参数模型对应的最优预训练预算以及需要的tokens数在下面
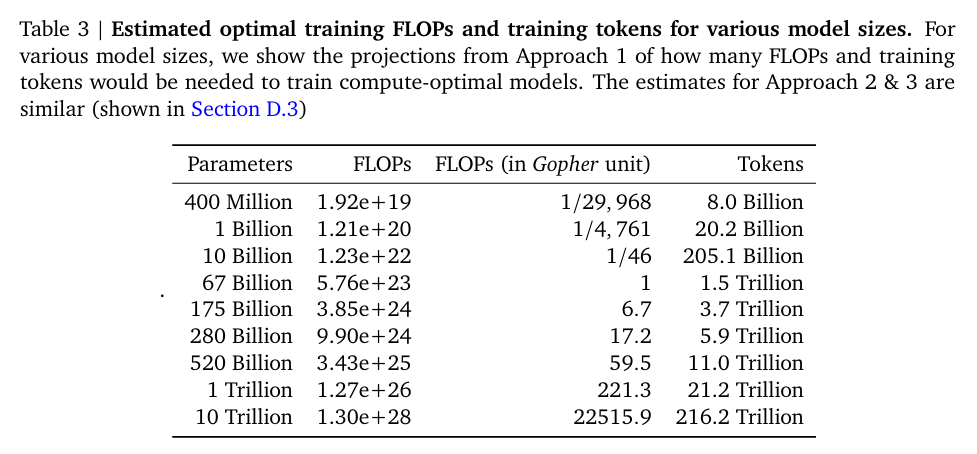
Chinchilla 模型
为了验证上述假设,DeepMind 训练了70B的Chinchilla 模型并使用了1.4T的训练tokens,Chinchilla 与 Gopher 使用了完全相同的计算预算(但Gopher 的参数量是 280B,而训练数据只有 3000亿 Token),结果是Chinchilla 在广泛的评估任务中表现优异,全面超越了 Gopher (280B)、GPT-3 (175B)、Jurassic-1 (178B) 和 Megatron-Turing NLG (530B),通过实证研究证明了对于给定的计算预算,一个参数较小但训练数据更多(训练时间更长)的模型,性能会优于参数巨大但训练不足的模型。
附录
主要提供了一些tricks:
-
AdamW 在大模型训练中不仅能获得更低的 Loss,而且在下游任务微调时效果更好,无论学习率调度如何,AdamW 训练出的模型都优于 Adam
-
Cosine 学习率衰减的周期必须与你计划训练的总步数(Token数)精确匹配,意味着你不能随意设定一个超长的 Schedule 然后中途早停,必须在训练开始前就定好“我要跑多少步”,并据此设定 Schedule
-
训练中会对高质量数据进行过采样以增加重复次数,而降低普通数据所占的权重

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)