【文献阅读】BiLLM Pushing the Limit of Post-Training Quantization for LLMs
本文提出BiLLM,一种针对预训练大语言模型(LLMs)的高效1位训练后量化方法。通过分析LLM权重的钟形分布和海森矩阵特性,BiLLM采用双路径策略:对显著权重进行结构化筛选与残差逼近二值化,最小化量化误差;对非显著权重通过最优分割搜索分组二值化,适应其分布特征。实验表明,BiLLM在OPT、LLaMA等模型家族上仅需1.08位平均权重比特宽度(如LLaMA2-70B困惑度8.41),显著优于现
https://arxiv.org/abs/2402.04291
https://github.com/Aaronhuang-778/BiLLM?tab=readme-ov-file
BiLLM:突破大语言模型训练后量化的极限
¹ 香港大学 ² 北京航空航天大学 ³ 苏黎世联邦理工学院
第 41 届国际机器学习大会论文集,奥地利维也纳,
PMLR 235
2024 年arXiv:2402.04291v2 [cs.LG]
2024 年 5 月 15 日
摘要
预训练大语言模型(LLMs)具备卓越的通用语言处理能力,但对内存和计算资源提出了极高要求。作为一种强大的压缩技术,二值化可将模型权重极致压缩至仅 1 位,大幅降低高昂的计算和内存开销。然而,现有量化技术在超低比特宽度下难以维持大语言模型的性能。针对这一挑战,我们提出 BiLLM—— 一种专为预训练大语言模型设计的突破性 1 位训练后量化方案。基于大语言模型的权重分布特征,BiLLM 首先识别并结构化筛选显著权重,通过有效的二值残差逼近策略最小化压缩损失。此外,考虑到非显著权重的钟形分布特性,我们提出最优分割搜索方法,对其进行精准分组和二值化。BiLLM 首次在多种大语言模型家族和评估指标中,以仅 1.08 位的权重实现了高精度推理(例如,在 LLaMA2-70B 上的困惑度为 8.41),显著优于当前最先进的大语言模型量化方法。同时,BiLLM 可在单块 GPU 上仅用 0.5 小时完成 70 亿参数大语言模型的二值化过程,展现出令人满意的时间效率。我们的代码已开源:https://github.com/Aaronhuang-778/BiLLM。
1. 引言
近年来,基于 Transformer(Vaswani 等人,2017)的大语言模型(LLMs)在自然语言处理领域备受关注。OPT(Zhang 等人,2022)和 LLaMA(Touvron 等人,2023a)等预训练大语言模型在各类评估基准中均表现出优异性能。然而,由于其庞大的参数规模和计算需求,大语言模型在内存受限设备上的部署面临巨大挑战。例如,广泛使用的 LLaMA2-70B(Touvron 等人,2023b)模型拥有 700 亿参数,在半精度(FP16)格式下需要 150GB 的存储空间,这意味着推理过程至少需要两块 80GB 显存的 A100 GPU。
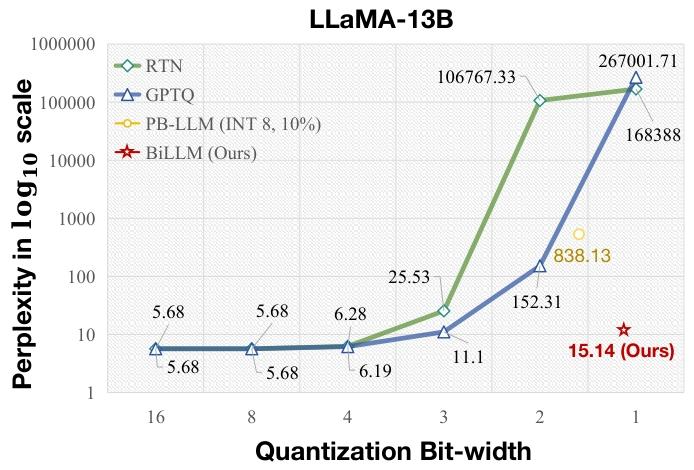
图 1:不同比特宽度下 LLaMA-13B 在 WikiText2 数据集上的困惑度。最近邻量化(RTN)、GPTQ 和 PB-LLM(10% 权重为 8 位整型)在超低比特下性能下降,困惑度急剧上升(↓)。BiLLM 在二值化情况下表现出卓越性能。
模型量化已成为压缩神经网络的高效技术,能够有效减小大语言模型的体积并大幅节省 GPU 内存消耗(Dettmers 等人,2022)。当前的量化技术主要分为量化感知训练(QAT)和训练后量化(PTQ)两类。量化感知训练在量化过程中涉及微调与重训练,而训练后量化通过省去反向传播步骤显著简化计算,量化速度更快,实用性更强(Frantar 等人,2022;Shang 等人,2023;Lin 等人,2023)。鉴于大语言模型结构深厚、参数众多,训练后量化凭借其快速量化的优势,在时间和资源受限的场景中尤为突出(Zhu 等人,2023)。
尽管此前的训练后量化方法在 8 位和 4 位量化中取得了成功(Dettmers 等人,2022;2023b;Frantar 等人,2022;Xiao 等人,2023;Frantar 和 Alistarh,2022),但大语言模型规模的持续扩大对更激进的量化方法提出了需求(Shang 等人,2023)。神经网络二值化将权重比特宽度缩减至仅 1 位,是一种极具潜力的方案(Helwegen 等人,2019;Qin 等人,2020;2023)。然而,如图 1 所示,当前先进的大语言模型训练后量化方法在超低比特(≤3 位)量化下会出现性能崩溃,这一现象源于量化权重与原始权重之间的巨大差异。即便是最新的大语言模型二值化训练后量化方法 PB-LLM(Shang 等人,2023),在平均权重为 1.7 位时,困惑度指标也仅能维持在 800 左右。这一现状凸显了现有训练后量化方法在推动大语言模型权重二值化方面面临的巨大挑战。
为实现这一目标,我们通过实证研究分析了预训练大语言模型的权重分布特征,相关发现详见附录 G,核心结论如下:
- 权重的二阶海森矩阵呈现出极长的长尾分布,该矩阵常被用于衡量神经网络中权重元素的重要性(LeCun 等人,1989;Dong 等人,2019)。如图 2 所示,少数权重元素具有极高的海森值,对层输出产生显著影响,而大多数海森值集中在 0 附近。
- 大语言模型中权重幅度的密度分布遵循钟形模式,其特征与高斯分布或拉普拉斯分布高度相似(Blundell 等人,2015)。图 2 显示,大多数权重值集中在零附近,呈现出非均匀的钟形分布。
上述发现表明:a)少数权重在大语言模型中发挥关键作用,而大多数权重具有冗余特征(Shang 等人,2023;Dettmers 等人,2023b);b)在大语言模型的钟形分布下,二值化作为比特宽度最激进的量化方式,会产生最严重的误差(Jacob 等人,2018)。
基于上述观察,我们提出一种新颖的大语言模型 1 位训练后量化框架 BiLLM,通过两项核心设计实现高精度权重二值化。首先,在海森矩阵指标的引导下,结构化筛选显著权重(图 3 右上部分),在精度与存储节省之间取得平衡,并通过残差逼近策略最大限度恢复动态范围较大的显著权重。其次,针对剩余的非显著权重(图 3 右下部分),设计最优分割二值化策略:通过细致的搜索过程确定权重分布的最优断点,然后对各分段分别进行二值化,以最小化二值化误差。此外,BiLLM 默认采用现有通用做法(Frantar 等人,2022;Shang 等人,2023),引入块级误差补偿,进一步降低量化误差。
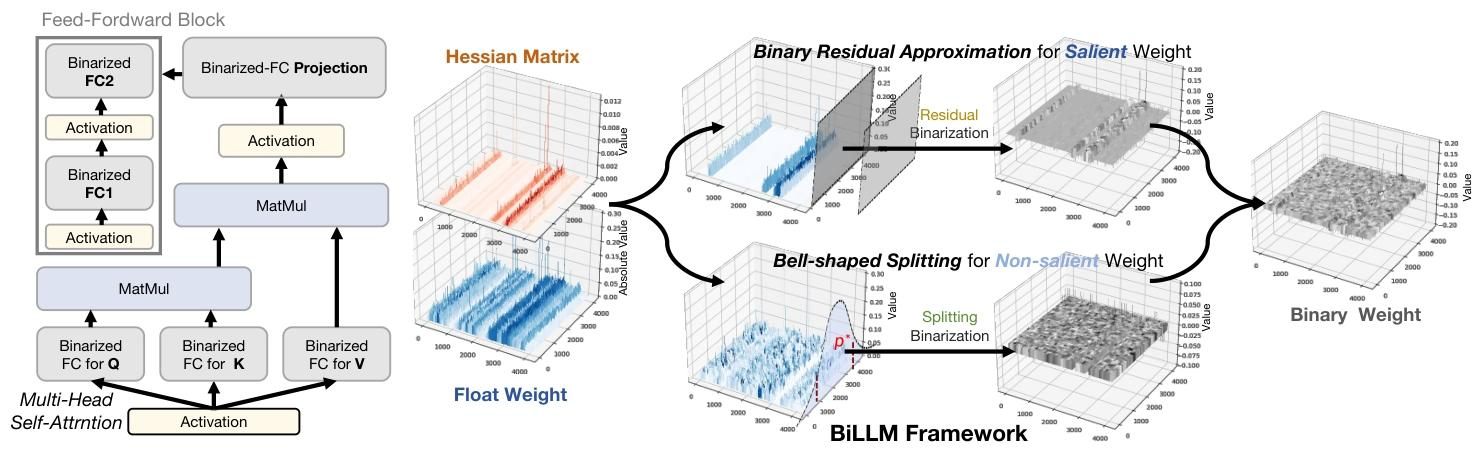
图 2:大语言模型中权重的海森矩阵指标(敏感性)和幅度(数值)。大语言模型不同层的权重具有钟形分布特征,同时存在少量显著值。
大量实验表明,BiLLM 在多个大语言模型家族的各类评估指标中均达到当前最先进(SOTA)性能,首次实现了平均比特宽度为 1.07~1.11 位的训练后量化二值化。例如,在 WikiText2(Merity 等人,2016)指标上,BiLLM 仅用 1.08 位权重,就在 LLaMA65B(Touvron 等人,2023a)和 LLaMA2-70B(Touvron 等人,2023b)上分别实现了 8.49 和 8.41 的困惑度,甚至超过了 FP16 精度下 OPT-66B(Zhang 等人,2022)9.34 的性能。
2. 相关工作
2.1. 大语言模型量化
量化将高精度参数映射到离散范围,该方法在不改变模型结构的前提下压缩参数,有效降低深度神经网络的存储和计算开销。近年来,量化感知训练和训练后量化已成功应用于大语言模型。量化感知训练通过量化感知重训练策略,能更好地保留量化模型的性能。LLMQAT(Liu 等人,2023)通过无数据蒸馏解决了量化感知训练中的数据壁垒问题。然而,对于参数规模极大的大语言模型,重训练的成本极高且效率低下。
因此,QLoRA(Dettmers 等人,2023a)等技术专注于参数高效微调(PEFT)方法来量化大语言模型,提升量化感知训练的效率。尽管如此,即便是这些高效的微调量化策略,也需要超过 24 小时的 GPU 运行时间。
因此,训练后量化已成为高效量化大语言模型的重要选择。BRECQ(Li 等人,2021)、ZerqQuant(Yao 等人)和 LLM.int8 ()(Dettmers 等人,2022)等工作通过为自定义量化块添加额外分组标签来提升量化精度。
其他研究采用特征分割策略,例如 PB-LLM(Shang 等人,2023)和 SpQR(Dettmers 等人,2023b),它们将异常特征或量化误差较高的特征的比特宽度保留为 FP16 或 INT8,以减轻量化导致的精度损失。GPTQ(Frantar 等人,2022)采用更精准的量化框架,通过基于海森矩阵的二阶误差补偿(Frantar 和 Alistarh,2022)降低大语言模型的块量化误差,在低比特(4 位)量化中取得了优异性能。Smoothquant(Xiao 等人,2023)引入权重和激活异常值缩放策略,简化量化过程。随后,AWQ(Lin 等人,2023)和 OWQ(Lee 等人,2023)也针对激活特征提出了更关键权重通道的缩放变换,以保留其信息表征能力。
2.2. 网络二值化
二值化压缩可将参数量化至仅1位,用±1表示。在前向传播中,通过符号函数对原始参数张量进行二值化:
\( W_{b}=\alpha \cdot sign\left(W_{f}\right) \quad(1) \)
\( sign(x)= \begin{cases}1 &{if x \geq 0, \\ -1 & others. \end{cases} \)
其中,\( W_{f} \in \mathbb{R}^{n ×m} \) 为全精度权重,\( w_{b} \in \mathbb{R}^{n ×m} \) 为二值化输出,n和m表示权重矩阵的尺寸,α为缩放因子(Courbariaux等人,2016)。二值化通常采用通道级缩放(Rastegari等人,2016;Qin等人,2023),因此\( \alpha \in \mathbb{R}^{n} \)。
此前的大多数二值化工作采用基于量化感知训练的量化框架(Qin等人,2023)。为解决符号函数导致的梯度消失问题,通常采用直通估计器(STE)(Bengio等人,2013)。二进制权重网络(BWN)(Rastegari等人,2016)最初提出通过二值化权重并使用全精度激活来执行神经网络计算,而XNOR-Net(Rastegari等人,2016)进一步扩展了这一方法,对权重和激活均进行二值化。这两种方法均通过动态搜索α来最小化量化误差。DoReFa-Net(Zhou等人,2016)在XNOR-Net的基础上进一步扩展,采用量化梯度加速网络训练。分组分割也被应用于二值化任务中,Syq(Faraone等人,2018)利用网络权重分组的小规模特性来最小化二值化误差。
基于二值化在Transformer(Wang等人,2023)和Bert(Qin等人,2022)中的成功应用,我们认为大语言模型的二值化具有巨大潜力。PB-LLM(Shang等人,2023)研究了二值化量化感知训练和训练后量化策略对大语言模型的影响,但需要保留相当比例(超过30%)的8位权重,才能使大语言模型产生合理的输出。由于存在大量INT8权重,大语言模型的平均比特宽度仍然较高。为解决这一问题,我们提出BiLLM,旨在突破大语言模型训练后量化二值化的极限。
3. 方法
为实现大语言模型的精准二值化,我们的思路是为显著权重和非显著权重设计差异化的二值化策略。3.1 节首先介绍显著权重的筛选规则及其二值化策略,3.2 节详细阐述基于分布的非显著权重二值化策略。
3.1. 大语言模型的显著权重二值化
在深度神经网络中,并非所有参数都具有同等重要性。仅依靠权重的幅度无法完全捕捉每个元素对模型性能的影响。海森矩阵指标是检测参数敏感性的常用基准(Dong等人,2019;Dettmers等人,2023b;2022)。因此,我们利用海森矩阵评估每个待二值化层中参数的显著程度。通过优化的计算过程推导权重敏感性,在不影响效率的前提下获取参数的重要性指标:
\( s_{i}=\frac {w_{i}^{2}}{\left[ H^{-1}\right] _{ii}^{2}} (3) \)
其中,H表示每层的海森矩阵,\( w_{i} \) 表示每个元素的原始值。在后续章节中,\( s_{i} \) 用作评估权重元素重要性的标准,并作为结构化筛选的特征指标。
结构化搜索筛选
非结构化筛选能够覆盖所有显著元素,但需要额外的1位位图索引(Chan和Ioannidis,1998),导致平均比特宽度增加。这种平衡方式效率低下,尤其是对于仅占总数1-5%的海森矩阵异常值权重(Yao等人,2023)。在分析大语言模型的敏感性分布时,我们发现大多数权重的敏感海森值主要集中在特定的列或行(附录G)。这一模式源于模型多头自注意力机制的收敛效应,进一步促使我们采用结构化方法筛选显著权重,以减少额外的位图开销。由于BiLLM采用通道级(或行级)二值化,我们通过对整个权重矩阵进行列级分割来确定显著程度。
我们将列显著度按降序排列,并引入优化搜索算法以最小化量化误差,进而确定显著组中的列数。为详细说明该方法,我们基于公式(1)定义二值化量化的目标:
\( \underset{\alpha, B}{arg min }\| W-\alpha B\| ^{2} \)
其中,\( B \in{-1,+1}^{n ×k} \),k为筛选出的列数。最优α和B的求解问题(Rastegari等人,2016)可简化为\( \alpha=\frac{\|w\|_{\ell 1}}{n ×k} \) 且 \( B=sign(W) \)。随后,筛选显著列的优化函数定义为:
\( \underset {W_{uns}}{arg \operatorname* {min}}\| W - (\alpha _{sal}\, sign(W_{sal})\cup \alpha _{uns}\, sign(W_{uns}))\| ^{2} (5) \)
其中,\( W_{sal } \) 表示原始权重的列级组合,\( W_{uns }\) 为剩余的非显著部分。显然 \( W=W_{sal } \cup W_{uns }\),因此唯一的变量参数是\( W_{sal }\) 中的列数。
二值残差逼近
显著权重数量有限,但聚合后呈现出较大的方差。若直接将这些权重保留为INT8或FP16格式,会增加平均权重比特数,削弱二值化的压缩优势。而传统的显著权重二值化方法会导致巨大的量化误差。为此,我们提出一种针对显著权重的残差逼近二值化方法。与对整个权重矩阵进行全面高阶量化(Li等人,2017)不同,我们仅对选定的显著权重子集进行二阶逼近,以最小化二值化误差。该方法在保证显著权重精度的同时,降低了比特宽度开销。如图4所示,该方法采用递归计算策略进行权重二值化补偿,对初始二值化后剩余的残差进行二次二值化处理。基于公式(4),我们为显著权重重新设计了残差逼近优化目标,定义如下:
\( \left\{ \begin{array} {ll}{\alpha _{o}^{*},B_{o}^{*}=\underset {\alpha _{o},B_{o}^{*}}{arg min }\left\| W-\alpha _{o}B_{o}\right\| ^{2}),}\\ {\alpha _{r}^{*},B_{r}^{*}=\underset {\alpha _{r},B_{r}}{arg min }\left\| \left( W-\alpha _{o}^{*}B_{o}^{*}\right) -\alpha _{r}B_{r}\| ^{2}\right) ,}\end{array} \right. (6) \)
其中,\( B_{0} \) 表示原始二值张量,\( B_{r} \) 表示与\( B_{o} \) 尺寸相同的残差二值化矩阵。我们采用与公式(4)相同的求解方法,高效求解两个二值化优化目标。
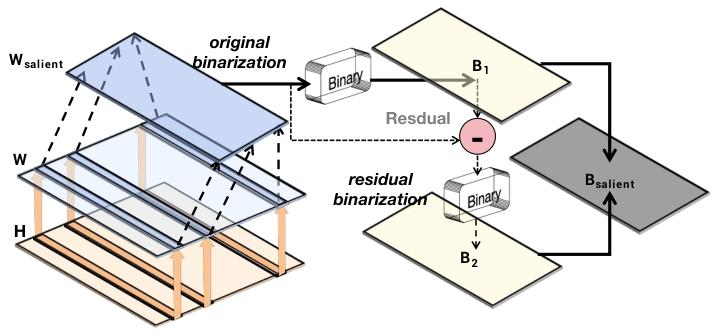
图4:显著权重二值化示意图。将显著权重二值化得到\( B_{1} \),与原始值构成残差后再次进行二值化,得到\( B_{2} \)。
最终,我们得到如下逼近结果:
\( W\approx \alpha _{o}^{*}B_{o}^{*}+\alpha _{r}^{*}B_{r}^{*} (7) \)
可以证明,公式(7)的残差逼近方法比公式(4)的直接二值化方法具有更低的量化误差。定义残差二值化误差E:
\( \mathcal {E}_{rb}=\left\| W-\alpha _{o}^{*} B_{o}^{*}-\alpha _{r}^{*} B_{r}^{*}\right\| ^{2} (8) \)
根据公式(4),原始二值化量化误差计算为\( \left\|W-\alpha_{o}^{*} B_{o}^{*}\right\|^{2} \),由公式(6)的第二个子公式可得,损失\( E_{r b} \leq \left\|W-\alpha_{o}^{*} B_{o}^{*}\right\|^{2} \)。因此,与将显著权重保留为8位或16位相比,通过残差逼近方法,我们能够在超低比特宽度存储的情况下,进一步降低显著权重的二值化量化误差。
3.2. 面向二值化的钟形分布分割
剔除显著权重后,剩余权重仍保持钟形分布,且排除显著权重的影响后更接近对称分布,如图5所示。二值化量化作为均匀量化的极端形式,在非均匀分布下会产生更大的损失。一种实用的方法是根据权重分布进行分组量化(Park等人,2018;Fang等人,2020;Jain等人,2019)。在量化精度与压缩效率之间取得平衡,我们在分布中确定一个断点。如图5所示,该分割将非显著的钟形分布分为两类:稀疏区域和集中区域。
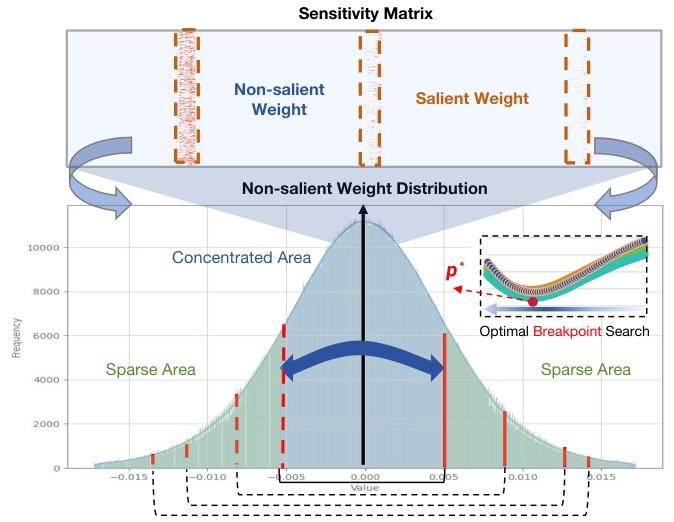
图5:LLaMA2-7B第4投影层的分布及分割示意图。海森矩阵元素中前5%的显著元素用橙色标注,最优断点将非显著权重分为稀疏区域和集中区域。
分割过程通过断点将非显著权重分为两组:集中权重\( A_{c}[-p, p] \) 和稀疏权重\( A_{s}[-m,-p] \cup[p, m] \),其中m表示非显著权重的最大值范围。随后,我们分别对集中区域(\( A_{c} \))和稀疏区域(\( A_{s} \))进行二值化。为确定最优断点\( p^{*} \),我们假设非显著权重在有界域\([-m, m]\) 上具有对称的概率密度函数(PDF)\( g(x) \),且满足\( g(x)=g(-x) \)。此时,二值化的均方量化误差定义为:
\( \theta_{q}^{2}=\int_{-m}^{0}(-\alpha-x)^{2} g(x) d x+\int_{0}^{m}(\alpha-x)^{2} g(x) d x (9) \)
由于\( g(x) \) 是对称函数,上述公式可简化为:
\( \theta_{q}^{2}=2 \int_{0}^{m}(\alpha-x)^{2} g(x) d x \)
随后,断点p将非显著权重分为两部分。根据公式(10),在不连续权重分布下,得到新的二值化量化误差:
\( \theta _{q,p}^{2}=||W_{s}-\alpha _{s}B_{s}||^{2}+||W_{c}-\alpha _{c}B_{c}||^{2} (11) \)
其中,\( w_{s} \) 和\( w_{c} \) 分别表示稀疏区域和集中区域的权重,\( B_{s} \) 和\( B_{c} \) 由公式(2)计算得出,\( \alpha_{s} \) 和\( \alpha_{c} \) 为二值化缩放因子,由公式(4)确定:
\( \alpha_{s}=\frac{1}{n_{s}}\left\| W_{s}\right\| _{\ell 1}, \alpha_{c}=\frac{1}{n_{c}}\left\| W_{c}\right\| _{\ell 1} (12) \)
其中,n表示每个区域中权重元素的数量。因此,问题函数仅与p相关,我们寻找最优\( p^{*} \) 的目标可定义为:
\( p^{*}=\underset{p}{arg min }\left(\theta_{q, p}^{2}\right) (13) \)
当剩余权重遵循理想高斯分布时,已有研究证明公式(11)是具有全局最小值的凸函数(Fang等人,2020;You,2010)。尽管如此,非显著权重的实际分布虽呈钟形,但与理想高斯模型存在差异。同时,我们保留了GPTQ(Frantar等人,2022)和OBC(Frantar和Alistarh,2022)的块级补偿策略以抵消量化误差,这可能会改变权重分布。对此,我们基于公式(13)的目标函数,采用百分位搜索方法确定最优断点。该百分位搜索策略高效简洁,仅需30分钟即可完成70亿参数大语言模型的二值化过程。此外,我们的研究结果表明,尽管非显著权重偏离理想高斯分布,搜索过程的误差曲线仍呈现凸函数特性(详见附录C),验证了找到最优断点的可行性。
3.3. BiLLM 的流程
如图 3 左侧所示,BiLLM 主要对 Transformer 块内的所有线性层权重进行二值化量化。本节将详细介绍 BiLLM 的流程。

图 3:大语言模型训练后量化二值化框架示意图。左侧为二值化后的 Transformer 块结构;右侧为 BiLLM 的二值化过程,包括显著权重的残差逼近和非显著权重的钟形分布分割两部分。
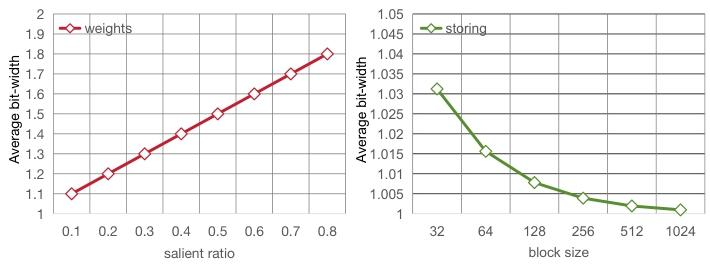
图 6:Llama-7B 的权重及硬件开销变化。左图展示计算参数随显著权重比例的变化;右图展示硬件开销随块大小的变化。
二值化工作流
首先,对显著列进行结构化搜索,并采用残差逼近二值化方法处理显著列。由于搜索比例和残差机制,显著列的处理会产生额外的权重比特数。表1列出了部分大语言模型(Zhang等人,2022;Touvron等人,2023a;b)产生的额外比特数,可见搜索和残差仅带来约0.1位的额外权重比特数。随后,针对这些非均匀分布的权重,采用分割二值化策略搜索最优\( p^{*} \),对集中区域和稀疏区域分别进行二值化。这一部分需要额外1位用于硬件分组标识,但计算参数仍被压缩至1位。通过仅保留块级补偿(Frantar等人,2022;Frantar和Alistarh,2022),省去列级量化误差补偿,进一步提升了训练后量化的效率,同时确保了分布探索的有效性。算法1展示了BiLLM的完整流程,详细实现细节见附录A。
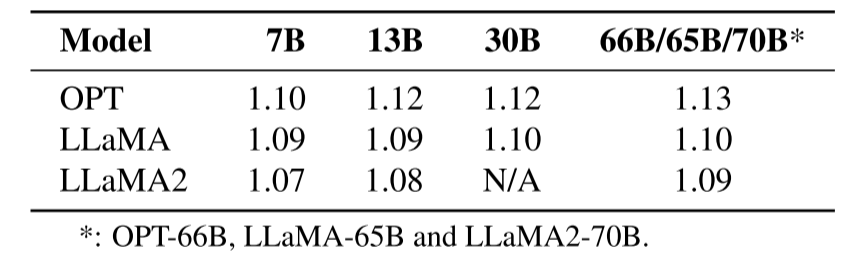
表1:OPT、LLaMA和LLaMA2通过结构化搜索和残差二值化后的平均比特数结果。
额外存储比特数
在BiLLM的二值化权重量化中,额外比特数处于可接受范围。权重参数和额外硬件开销如下:
\( \left\{\begin{array}{l} N_{param }=2 × r_{salient }+1 ×\left(1-r_{salient }\right), \\ N_{storing }=1+\frac{1}{b_{size }}, \end{array}\right. \)
其中,\( r_{salient }\) 表示显著权重的比例,\( b_{size }\) 表示OBC补偿中的块大小,分配1位用于标记非显著权重的分割。\( \frac{1}{b_{size }} \) 表示显著权重结构化列的标识位。例如,采用10%的结构化筛选和128大小的OBC补偿时,权重参数比特宽度为1.1位,硬件标识位宽度为1.008位。图6展示了不同比例和块大小下的权重开销。需要注意的是,标识权重不参与计算,实际计算仅使用参数权重,因此额外的硬件标识位不会影响二值化量化的加速效果。
算法 1:BiLLM 的主要框架:各函数的详细实现见算法 2
func BinaryLLM(W, X, β, λ)
输入:W ∈Rn×m - 权重矩阵
X ∈Rr×d - 校准数据
β - 块大小
λ - 海森矩阵正则化参数
输出:B - 二值化权重
1: H := 2XX⊤// ℓ2误差海森矩阵
2: Hc := Cholesky((H + λI)−1)
3: B := 0n×m
4: for b = 0, β, 2β, ..., N do
5: Wb := W:,b:b+β
6: rows{·} := salient(W:,b:b+β, Hc)
7: ˜B1 := res_approximation(Wb :,j∈{rows})
8: p∗:= seg_search(Wb i,j /∈{rows})
9: ˜B2 := binary(Wb |wi,j|≤p∗,j /∈{rows})
˜B3 := binary(Wb |wi,j|>p∗,j /∈{rows})
10:
11: B:,b:b+β := ˜B1 + ˜B2 + ˜B3
12: E := (W:,b:b+β −B:,b:b+β)/Hc bb:b+βb+β
13: W:,b+β: := W:,b+β:−E·Hc b:b+β,b+β: // 块级OBC
14: end for
15: return B

4. 实验
4.1. 实验设置
我们在 Pytorch(Paszke 等人,2019)和 Huggingface 库(Wolf 等人,2019)中部署 BiLLM。所有二值化过程和实验均在单块 80GB NVIDIA A100 GPU 上进行。由于 BiLLM 是高效的训练后量化框架,无需任何微调,仅通过单次量化过程即可完成。
模型与数据集
我们在 OPT(Zhang 等人,2022)和 LLaMA(Touvron 等人,2023a;b)系列模型上验证所提方法。此外,考虑到大语言模型通常需要通过指令微调以适应不同场景,我们还在 Vicuna(Chiang 等人,2023)上进行了实验。评估指标方面,我们主要关注大语言模型输出的困惑度,该指标被广泛认为是衡量大语言模型能力的重要且稳定的指标,尤其适用于网络压缩场景(Yao 等人;Frantar 等人,2022;Frantar 和 Alistarh,2023;Xiao 等人,2023)。我们采用 WikiText2(Merity 等人,2016)、PTB(Marcus 等人,1994)以及部分 C4(Raffel 等人,2020)数据进行测试。此外,我们还在 7 个零样本评估任务(PIQA(Bisk 等人,2020)、BoolQ(Clark 等人,2019)、OBQA(Mihaylov 等人,2018)、Winogrande(Sakaguchi 等人,2021)、ARC-e(Clark 等人,2018)、ARC-c(Clark 等人,2018)、Hellaswag(Zellers 等人,2019))中进行了实验(详见附录 D),进一步验证 BiLLM 对大语言模型二值化的鲁棒性。
基线方法
我们的主要基线方法是 PB-LLM(Shang 等人,2023)—— 最新的大语言模型二值化训练后量化方法。同时,我们还选择了 GPTQ(Frantar 等人,2022)和基础 RTN 作为基线。GPTQ 是当前训练后量化领域的先进技术,许多研究(Lin 等人,2023;Dettmers 等人,2023b;Shang 等人,2023)均将其作为基线。其他面向 8 位和 4 位量化的方法不适合二值化场景,因此未被纳入考虑。
4.2. 实验结果
对比结果
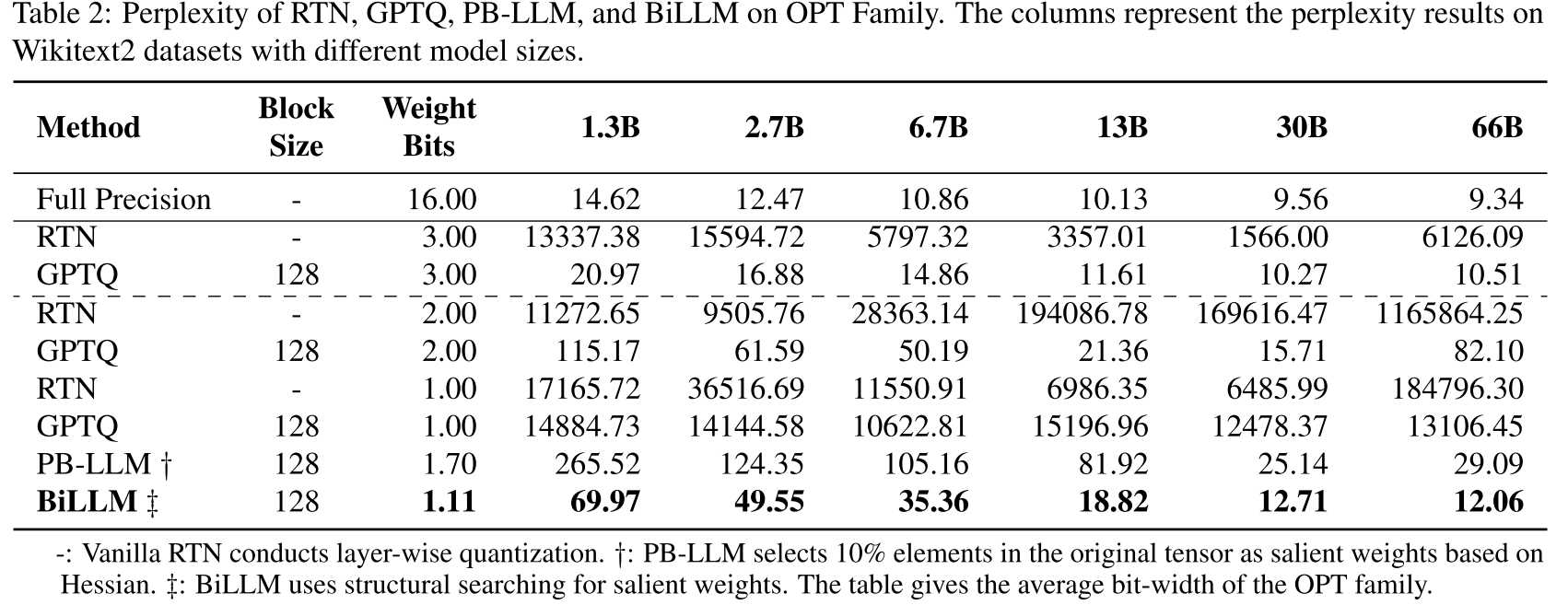
我们对不同规模大语言模型的二值化性能进行了细致对比。在块大小为 128 的条件下,将 BiLLM 应用于 OPT 模型(Zhang 等人,2022)。如表 2 所示,RTN 和 GPTQ 方法在 1 位权重下已出现输出崩溃,而 BiLLM 在平均权重为 1.1 位时仍能保持合理的语言输出能力。与 1.7 位的 PB-LLM 相比,我们的方法将权重比特宽度降低了 35%,同时使不同规模 OPT 模型的性能提升了 49.4% 至 77.0%。值得注意的是,当参数规模超过 300 亿时,BiLLM 的性能可接近 3 位量化的 GPTQ。
表 2:RTN、GPTQ、PB-LLM 和 BiLLM 在 OPT 系列模型上的困惑度。列表示不同模型规模在 WikiText2 数据集上的困惑度结果。
由于 LLaMA(Touvron 等人,2023a;b)系列模型的卓越性能,它们已成为许多开源模型的基础(Chiang 等人,2023)。如表 3 所示,我们评估了不同方法在 LLaMA 系列模型上的输出困惑度。结果表明,即使在超低权重比特宽度下,BiLLM 仍持续优于 2 位的 RTN 和 GPTQ 方法。此外,1.08 位的 BiLLM 在 LLaMA-65B 和 LLaMA2-70B 上的表现甚至超过了全精度 OPT-66B 模型,这证明了 LLaMA 家族具有更大的二值化潜力。我们将困惑度评估扩展到 PTB 和 C4 数据集,图 7 展示了 70 亿参数 LLaMA 系列模型和 67 亿参数 OPT 模型的性能,BiLLM 在与其他方法的对比中仍保持领先优势(更多对比结果见附录 D)。
表 3:RTN、GPTQ、PB-LLM 和 BiLLM 在 LLaMA 系列模型上的困惑度。列表示不同模型规模在 WikiText2 数据集上的困惑度结果。
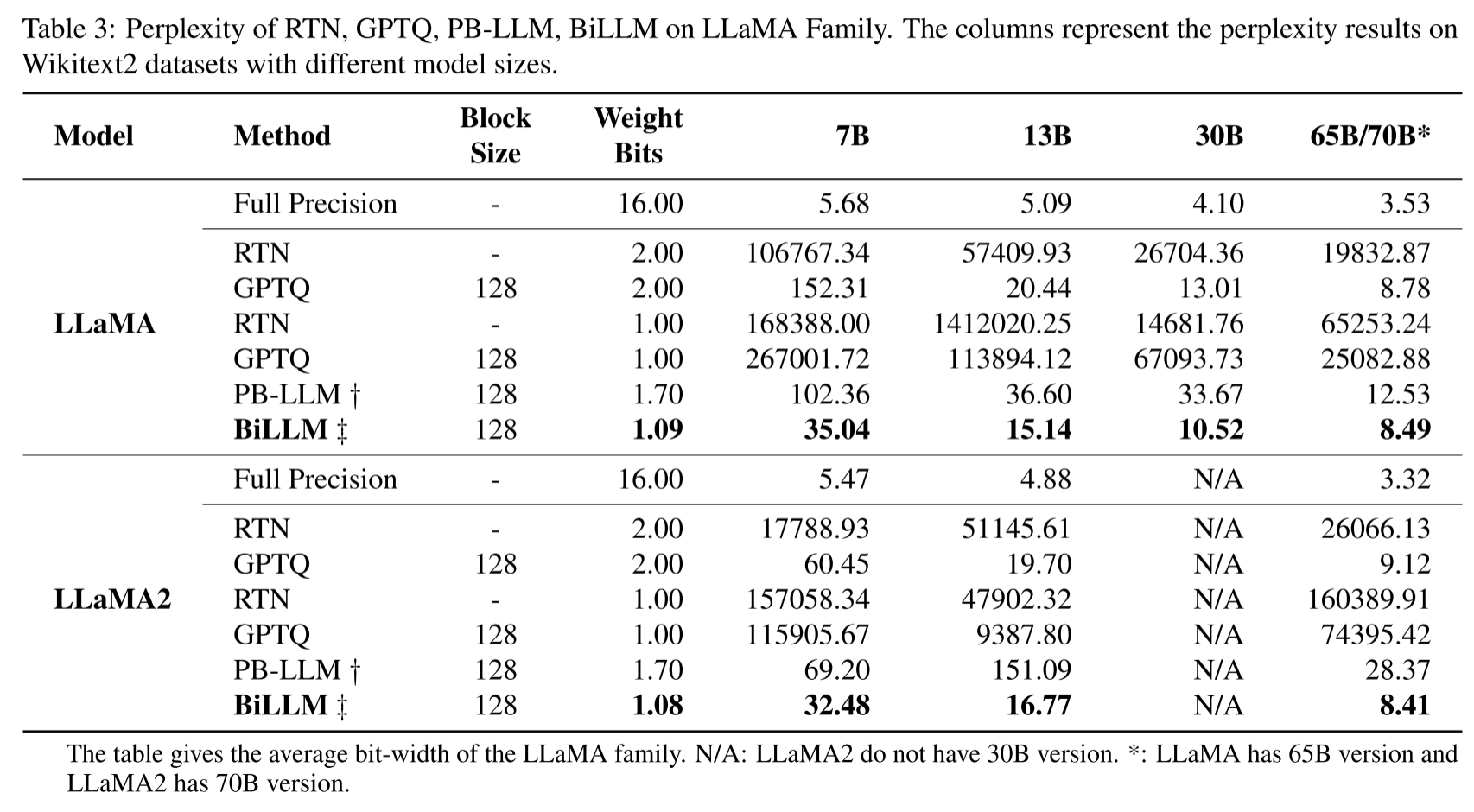
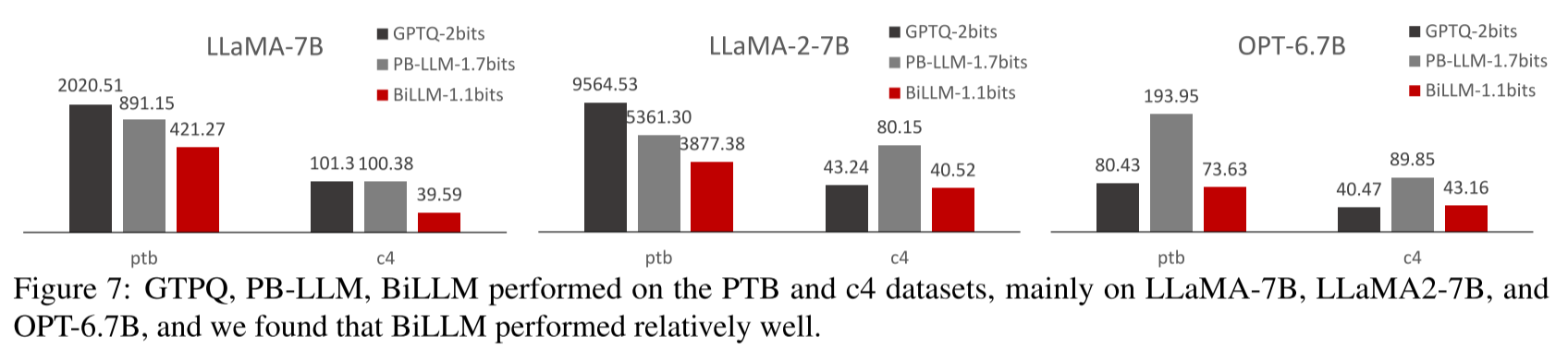
图 7:GPTQ、PB-LLM 和 BiLLM 在 PTB 和 C4 数据集上的表现,主要针对 LLaMA-7B、LLaMA2-7B 和 OPT-6.7B 模型,结果显示 BiLLM 表现相对更优。
指令微调模型实验
指令微调能显著提升模型的应用能力,已成为大语言模型在不同场景部署的必要流程(Wei 等人,2021;Sanh 等人,2021;Chiang 等人,2023)。我们还将 BiLLM 应用于近期热门的指令微调模型 Vicuna 进行基准测试。如表 4 所示,我们在 Vicuna-7B 和 Vicuna-13B 上对比了 GPTQ 和 PB-LLM 的困惑度性能。BiLLM 在平均权重为 1.08 位时仍能取得更优性能,进一步证明了其在大语言模型二值化中的通用性。附录 F 提供了二值化模型的对话示例。
表 4:BiLLM 在 Vicuna-7B 和 Vicuna-13B 上的困惑度。不同模型的列表示在 WikiText2、PTB 和 C4 数据集上的困惑度结果,块大小设置为 128。
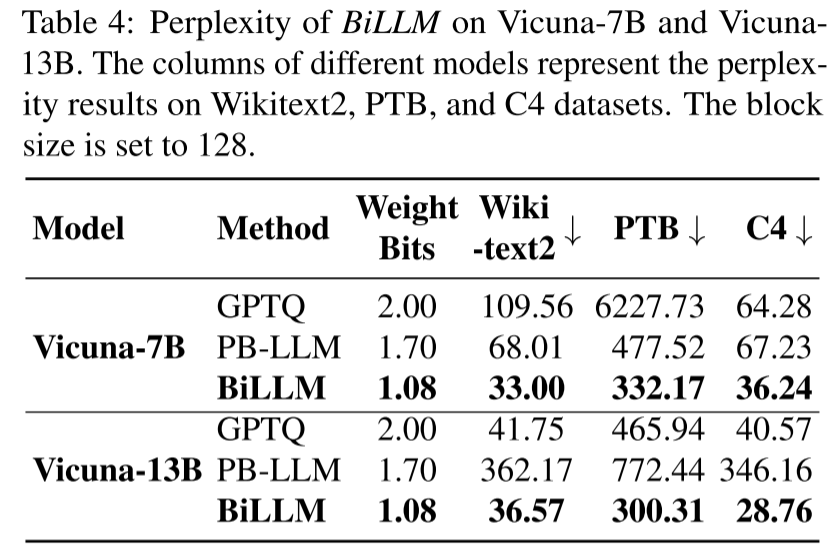
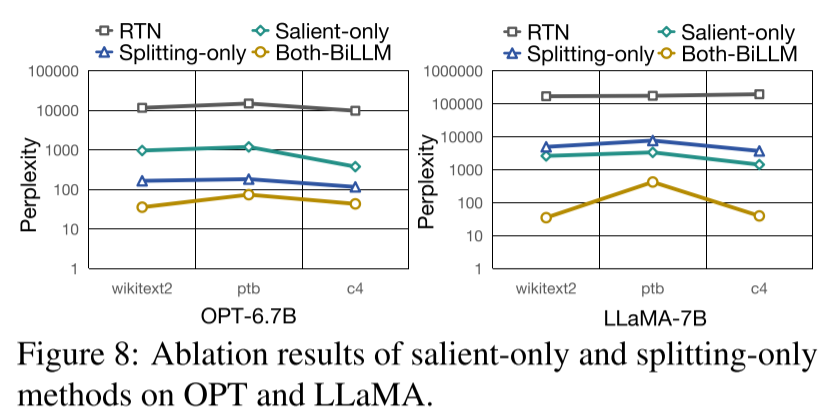
图 8:显著权重仅分割(Salient-only)和非显著权重仅分割(Splitting-only)方法在 OPT 和 LLaMA 上的消融实验结果。
零样本任务结果
为更全面地评估二值化大语言模型,我们将实验扩展到 7 个零样本数据集。附录 D 提供了我们的方法与现有方法在超低比特量化中的详细对比结果,进一步凸显了 BiLLM 的优越性。
消融实验结果
BiLLM 通过两项核心方法提升二值化精度:基于残差逼近的结构化显著权重二值化,以及基于最优分割的非显著权重二值化。为验证这些策略的效果,我们进行了分解实验。如图 8 所示,两种方法均能显著提升二值化性能。值得注意的是,OPT-6.7B 对非显著权重的分割更敏感(蓝线低于绿线),而 LLaMA-7B 对显著权重的残差逼近更敏感(绿线低于蓝线)。这一结果进一步表明,不同大语言模型对不同二值化优化策略的响应存在差异,同时也证明了 BiLLM 提出的两种二值化策略对各类大语言模型均有效。附录 E 详细讨论了块大小的消融实验结果。
模型规模
表 5 展示了 LLaMA-7B 至 65B 以及 LLaMA2-7B 至 70B 模型的 FP16 精度大小,以及经 BiLLM 压缩后的二值化模型大小。值得注意的是,BiLLM 对不同规模的大语言模型均实现了近 10 倍的权重压缩。
表 5:LLaMA 系列模型的规模对比。

GPU 内存占用
BiLLM 的设计初衷是突破训练后条件下大语言模型权重的比特宽度压缩极限,在最大限度保留精度的同时,减少大语言模型的存储和 GPU 内存占用,以提升实用性。尽管由于细粒度分组,二值化 GEMM(矩阵乘法)难以直接实现,但 BiLLM 的极端比特宽度压缩显著降低了 GPU 内存需求(大小和带宽)—— 这被认为是大语言模型推理中最关键的效率瓶颈之一(Gholami 等人,2024;Dettmers 等人;2023a;Xiao 等人,2023;Chee 等人,2024;Shang 等人,2023)。此处,我们通过详细的内存和性能对比来展示 BiLLM 的优势(如表 A.1 所示):对于 OPT-30B 模型,1.1 位的 BiLLM 相比 1.7 位的 PB-LLM 和 2 位的 GPTQ,内存压缩率分别提升了 41.57% 和 27.07%,同时精度分别提升了 49.44% 和 19.10%。表 7 进一步对比了不同规模大语言模型与 2 位 GPTQ 方法的内存使用情况,BiLLM 的内存占用仅为 2 位量化的约 69.9%,这表明极端比特宽度缩减带来了显著的内存节省优势,且在内存大幅节省的同时,我们仍实现了更高的精度。
表 6:OPT-30B 模型相对于 FP16 的内存占用率及相应精度。

表 7:OPT 模型相对于 FP16 的内存占用率对比。
5. 结论
本文提出一种新颖的训练后二值化量化方法 BiLLM,专为预训练大语言模型压缩设计。基于权重值和海森矩阵分布的特征,我们对结构化显著权重采用二值残差逼近策略,以在超低比特下保留其性能;对非显著权重采用最优分割策略进行分组二值化。实验结果表明,大语言模型可在超低比特下进行一次性权重量化,且不会出现显著精度损失。BiLLM 首次实现了在平均比特率接近 1 位的情况下保证大语言模型性能。我们在多个开源大语言模型家族中验证了 BiLLM 的二值化性能,并在微调指令模型上进行了泛化测试。BiLLM 突破了大语言模型的比特宽度量化边界,有望推动大语言模型在边缘场景和资源受限设备上的部署,并为大语言模型压缩领域的进一步探索提供了思路。
影响声明
本文的研究目标是推动机器学习领域的发展。我们的工作可能会产生多种社会影响,但在此无需特别强调。
附录
A. BiLLM 的实现
算法 2:BiLLM 的详细函数流程
plaintext
func salient (W, Hc)
1: S := W²/[Hc b:b+βb:b+β]² // 显著矩阵
2: rows{·} := topk(sum(abs(S)).(dim = 0))
3: e = inf // 搜索误差
4: n∗= 0 // 最优显著列数
5: for i = 1, 2, ..., len(rows) do
6: B1 := binary(W:,j, j∈rows[:i])
7: B2 := binary(W:,j, j /∈rows[:i])
8: if ||W −(B1 ∪B2)||² < e then
9: e := ||W −(B1 ∪B2)||²
10: n∗:= i
11: end if
12: end for
13: return rows{: n∗}
func res_approximation (W)
1: B1 := binary(W)
2: R := W −B1
3: B2 := binary(R)
4: B := B1 + B2
5: return B
func seg_search (W)
1: e = inf // 搜索误差
2: p∗= 0 // 最优断点
3: for i = 0.1, 0.2, 0.3, ..., 9 do
4: p := i · max(abs(W))
5: B1 := binary(W|wi,j|≤p)
6: B2 := binary(W|wi,j|>p)
7: if ||W −(B1 + B2)||² < e then
8: e := ||W −(B1 + B2)||²
9: p∗:= p
10: end if
11: end for
12: return p∗
func binary (W)
1: α := ||W||ℓ1 / m
2: B := α · sign(W)
3: return B

BiLLM 需要先结构化筛选显著行,然后通过残差逼近二值化对其进行量化。随后,将呈钟形分布的非显著权重分为稀疏区域和集中区域,通过最小化量化损失优化分割点p∗。最终,对非显著权重的两个区域分别进行二值化,得到大语言模型的最终二值化权重。上述函数的实现细节如算法 2 所示。
B. 量化误差
权重分布的量化误差定义
均匀量化器覆盖的数值范围为\([X_{min }, X_{max }]\),量化后的区间数量M通常等于\(2^{b}\),其中b表示目标量化比特宽度。因此,量化步长为:
\( \Delta=\frac{X_{max }-X_{min }}{M} (15) \)
边界可计算为:
\( b_{q}=X_{min }+\Delta \cdot l (16) \)
其中,\( l \in 0,1, ..., M \),在二值化情况下,\( b_{q} \in{-\alpha, 0, \alpha} \)。每个区间的均值为:
\( x_{q}=X_{min}+\Delta \cdot l-0.5\Delta (17) \)
其中,\( l \in 1, ..., M \)。在该量化方案中,根据(You,2010)可得到均方量化误差(MSQE):
\( \theta^{2}=\sum_{l=1}^{M} \int_{X_{min }+\Delta \cdot(l-1)}^{X_{min }+\Delta \cdot l}\left(X_{min }+\Delta \cdot l-0.5 \Delta-x\right)^{2} g(x) d x \)
令y替换\( X_{min }+\Delta \cdot l-0.5 \Delta-x \)部分,则公式(18)变为:
\( \theta^{2}=\sum_{l=1}^{M} \int_{-0.5 \Delta}^{0.5 \Delta} y^{2} f\left[X_{min }+\Delta \cdot l-(y+0.5 \Delta)\right]^{2} d x \)
结合公式(16)和(17),上述公式可简化为:
\( \theta^{2}=\sum_{l=1}^{M} \int_{-0.5 \Delta}^{0.5 \Delta} x^{2} f\left(x_{p}-x\right) d x \)
上述推理表明,均匀量化器的均方量化误差取决于概率密度函数(PDF)和量化比特宽度。根据此前对预训练大语言模型权重的观察,我们已剔除显著权重,剩余非显著权重的分布\( g(x) \) 并非均匀分布,而是类似于高斯分布。因此,在二值化中,将α代入公式(18),得到:
\( \begin{aligned} \theta^{2} & =\sum_{l=1}^{M} \int_{(l-1-0.5 M) \Delta}^{(l-0.5 M) \Delta}[(l-0.5-0.5 M) \Delta-x]^{2} g(x) d x \\ & =\int_{X_{min }}^{0}(-\alpha-x)^{2} g(x) d x+\int_{0}^{X_{max }}(\alpha-x)^{2} g(x) d x \end{aligned} \)
C. 显著列与非显著分布的搜索曲线
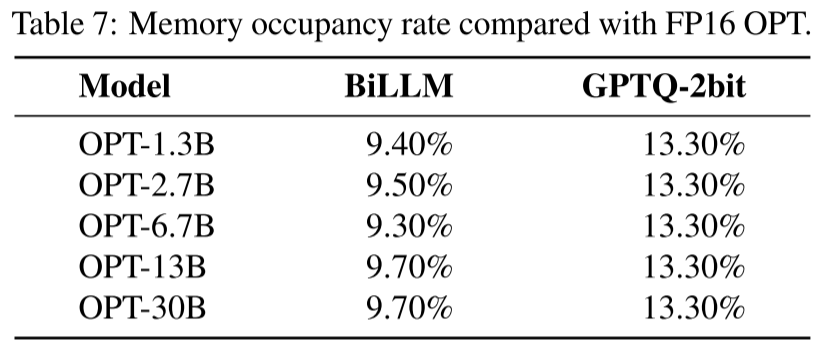
我们实现了列级分割,并基于公式(5)制定了最小误差列数搜索策略。最优显著列组数量的确定从显著度最高的列开始。为减少残差逼近导致的比特宽度增加,我们将搜索范围限制在 3 至 30 列之间。图 9 展示了 OPT-6.7B 模型第一个 Transformer 块的搜索曲线,该块包含 6 层算子(Q、K、V、输出投影层、FC1 和 FC2),每层均展示了前 5 个块的搜索曲线。图 15 阐明了显著权重的聚类特性,表明大多数层和块仅需少量显著列即可实现最小量化误差。
图 9:OPT-6.7B 中显著列的块级搜索曲线。大多数曲线表明,仅将少数列视为显著列,就能在块级实现最小量化误差。输出投影层的显著列数量较多,因此每个块的覆盖范围有所不同。全连接层(FC 层)的分布更为分散。经过优化搜索后,整体平均权重比特数仅为 1.1 位。
OBC(Frantar 和 Alistarh,2022)带来的块级权重分布变化会导致搜索曲线出现波动,但结构化筛选仍能覆盖大多数显著权重。在显著权重分布更分散的前馈层中,搜索曲线倾向于对更多列采用残差逼近。尽管如此,表 1 中不同大语言模型的平均权重比特数结果证实,该搜索策略有效将权重压缩维持在约 1.1 位。
图 10 展示了 OPT-6.7B 模型中非显著权重的非结构化搜索曲线,其构成与图 9 一致。横轴表示 p 与最大权重值的比值。尽管采用块级搜索,搜索曲线仍呈现凸函数特性,表明存在最优p∗。这一现象说明非显著权重的特征与理想高斯分布或拉普拉斯分布高度相似(You,2010;Fang 等人,2020)。
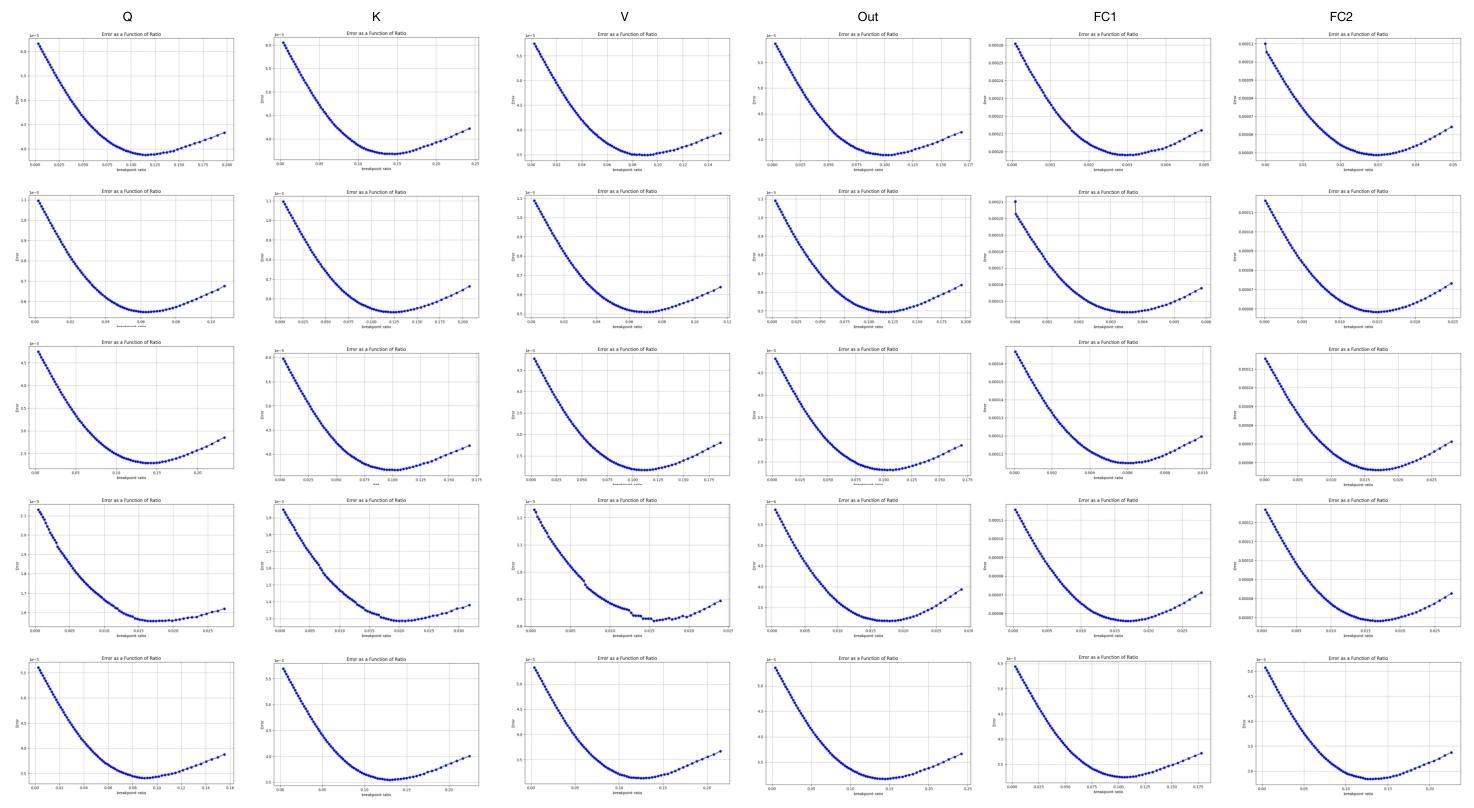
图 10:OPT-6.7B 中钟形分布的块级分割曲线。整体呈现凸函数特征,与理论最优值在理论基础上基本一致。
D. 多评估指标对比
PTB 和 C4 数据集上的困惑度结果
正文通过表格展示了 GPTQ、PB-LLM 和 BiLLM 三种方法在 WikiText2 数据集上的困惑度,并通过柱状图展示了 LLaMA-7B、LLaMA2-7B 和 OPT-6.7B 在 PTB 和 C4 数据集上的困惑度结果。附录中,我们通过更多图表展示了其他规模模型在 PTB 和 C4 数据集上的定量对比结果。
图 11:GPTQ、PB-LLM 和 BiLLM 在 PTB 和 C4 数据集上的表现,主要针对 LLaMA-13B、LLaMA2-13B、OPT-13B 等模型,结果显示 BiLLM 表现相对更优。
在图 11 中,我们发现尽管不同模型的困惑度结果存在差异,但大致遵循模型规模越大、困惑度越低的规律。在更低的比特宽度配置下,BiLLM 的困惑度总体上仍优于 GPTQ 和 PB-LLM,而 PB-LLM 和 GPTQ 的表现则互有高低,在极低比特下的结果稍逊一筹。
零样本任务结果
为保证测试的完整性,我们还测试并对比了 GPTQ、PB-LLM 和 BiLLM 在 PIQA、BoolQ 等数据集上的准确率等指标,均采用零样本(Zero-Shot)实验设置。从表 8 可以看出,尽管存在量化损失,但三种方法的横向对比显示 BiLLM 总体表现更优,在部分数据集上的测试结果高出一个等级,同时尽管存在一些随机扰动的影响,但并未全面拉低 BiLLM 的性能。这表明 BiLLM 的量化结果在极低比特下显著提升了性能,进一步验证了结论的有效性。
表 8:二值化 LLaMA、LLaMA2 和 OPT 在 7 个数据集上的准确率,对比 GPTQ、PB-LLM 和 BiLLM 的结果以验证量化效果。
E. 不同块大小的 BiLLM 消融实验
为探究不同块大小对 BiLLM 量化效果的影响,我们设置了 32 列、64 列直至 512 列的块大小,并对其进行量化实验。结果表明,块粒度越细,使用的比特数相对越少,整体困惑度越低。
我们认为这是因为块越小,数据表征越精细,使用的缩放因子越多,但在增加量化结果多样性的同时,也增加了权重开销。块大小为 128 时,能够更好地平衡比特宽度和量化效果。
表 9:不同块大小设置下,BiLLM 在 WikiText2、PTB 和 C4 数据集上的困惑度。
F. 对话示例
本节展示了二值化 LLaMA-13B 和 Vicuna-13B 的部分对话示例。
图 12:部分对话示例。选择 LLaMA-13B 和 Vicuna-13B 展示语言补全和问答能力,以 PB-LLM(8 位整型,10%)作为对比,通过颜色标注合理或不合理的响应。
G. 大语言模型的幅度与海森矩阵分布
图 2 展示了大语言模型中权重和海森矩阵的分布特征。本节提供更多示例,以阐明权重值的钟形分布和海森矩阵权重的长尾分布。图 13 展示了 OPT-1.3B 模型第一个 Transformer 块中 4 个线性层的分布,图 14 展示了 LLaMA-7B 模型第六个块中 7 个线性层的分布。选择这些特定块位置是为了证明这些分布特征在大语言模型中的普遍性。
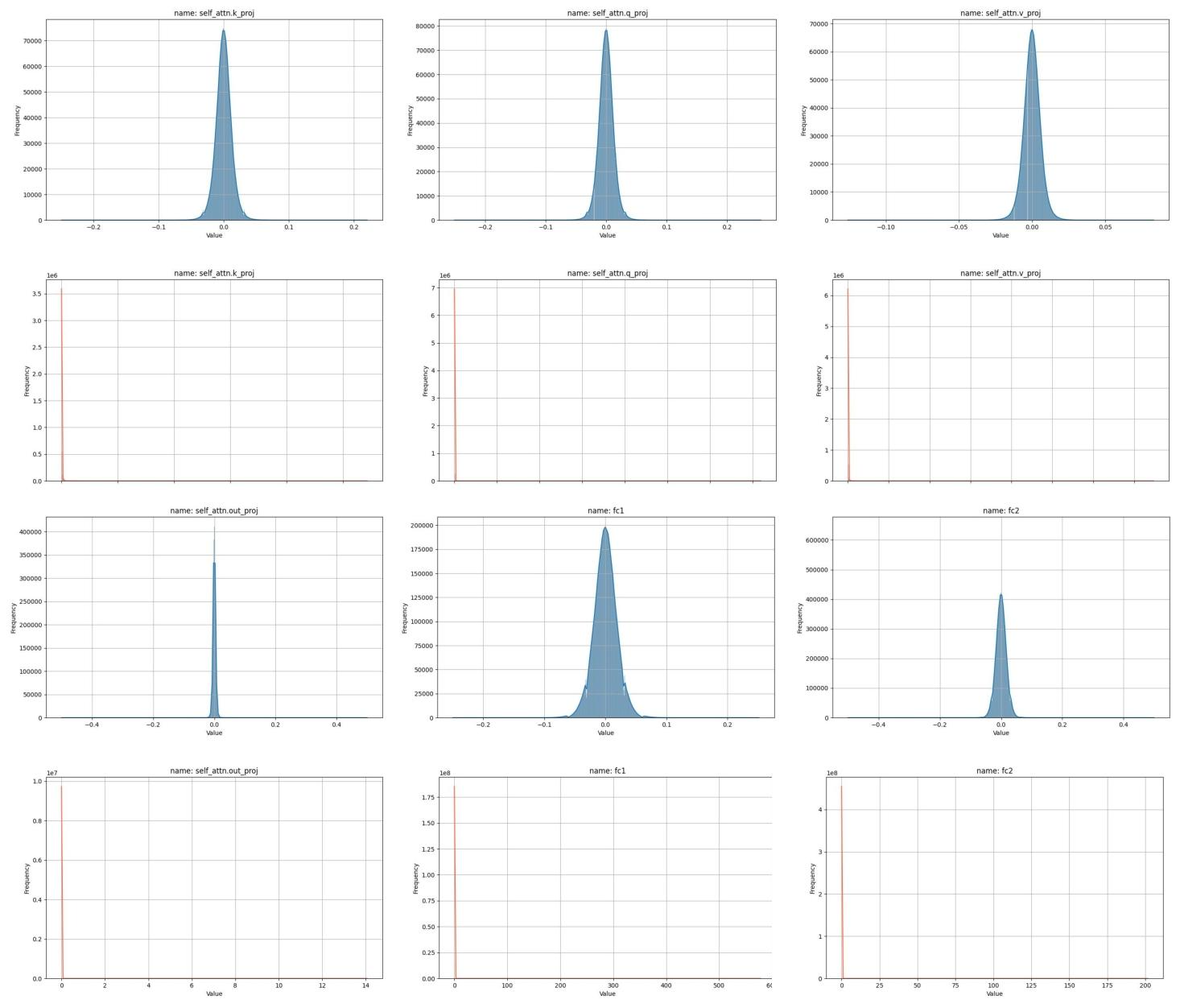
图 13:OPT-1.3B 模型第一个 Transformer 块不同层的权重密度分布(蓝色)和海森矩阵密度分布(橙色)。
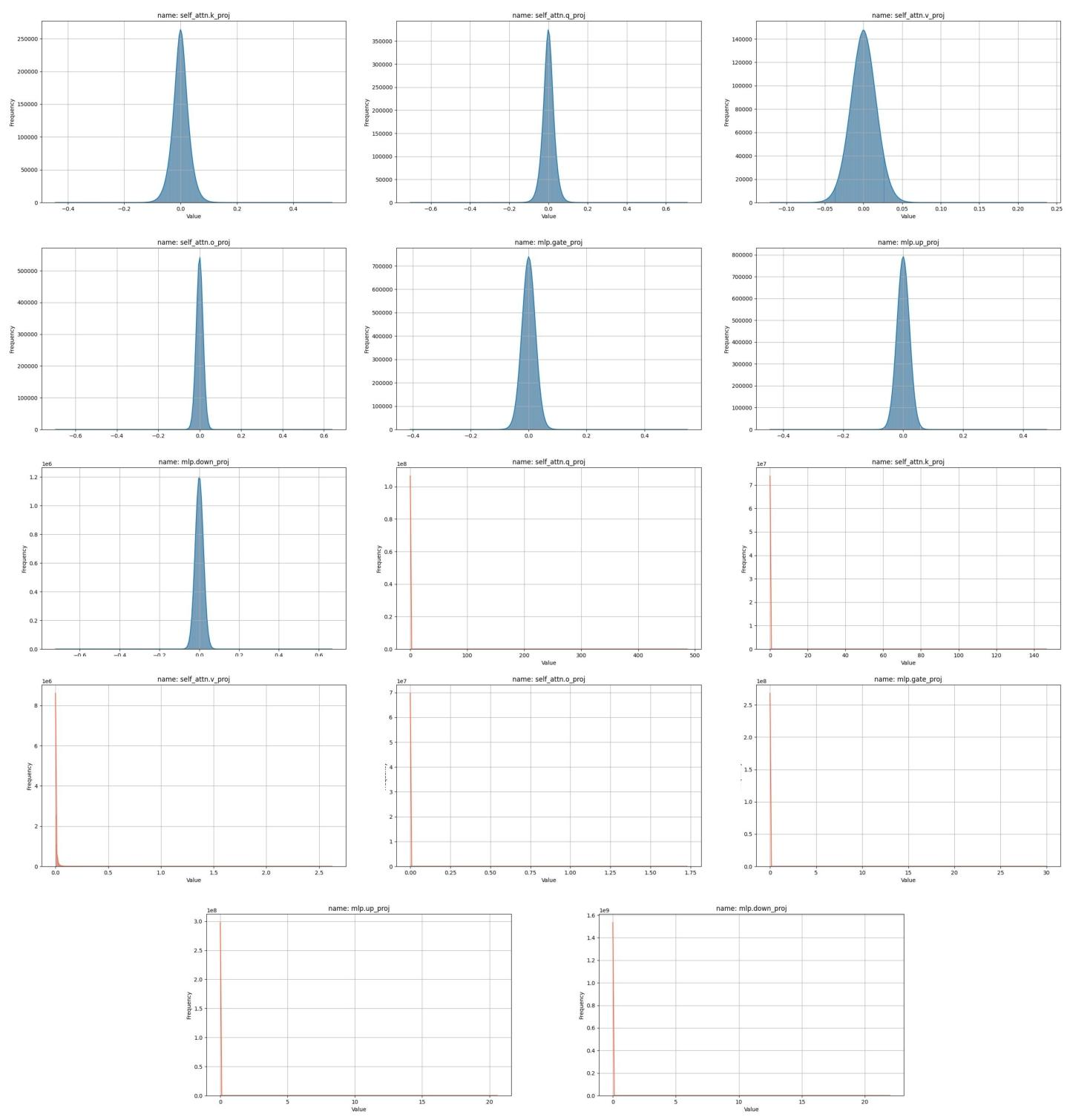
图 14:LLaMA-7B 模型第六个 Transformer 块不同层的权重密度分布(蓝色)和海森矩阵密度分布(橙色)。
图 15 展示了 OPT-1.3B 模型 5 个 Transformer 块中敏感权重的分布。我们呈现了注意力块和前馈块的海森矩阵分布结果,红色部分表示前 10% 最显著的权重分布。观察发现,OPT 家族中 Q、K、V 的显著权重倾向于集中在部分列或行。此外,多头自注意力块的输出投影层中,显著权重明显集中在特定列,这支持了正文中讨论的结构化筛选方法。相比之下,前馈层中显著权重的分布更为分散。基于这些观察,我们采用基于敏感性的结构化搜索方法来识别显著列。

图 15:海森矩阵中前 10% 显著元素的分布。OPT-1.3B 模型第一个至第五个 Transformer 块的分布情况。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)