关于如何选用embedding和rerank模型的最佳实践
在当前 AI 驱动的知识检索系统中,文本嵌入(Embedding)和结果重排序(Rerank)模型是实现高精度语义检索的核心组件。特别是对于政务服务领域的复杂业务场景,如何选择适配业务数据特征的高性能模型,直接影响到检索系统的精度、响应速度和用户体验。本最佳实践基于大连医保、社保、公积金全场景知识检索系统的实际项目经验,以及辽宁 / 大连参保登记流程的本地化适配实践,总结了如何选择和使用 Embe
前言
在当前 AI 驱动的知识检索系统中,文本嵌入(Embedding)和结果重排序(Rerank)模型是实现高精度语义检索的核心组件。特别是对于政务服务领域的复杂业务场景,如何选择适配业务数据特征的高性能模型,直接影响到检索系统的精度、响应速度和用户体验。
本最佳实践基于大连医保、社保、公积金全场景知识检索系统的实际项目经验,以及辽宁 / 大连参保登记流程的本地化适配实践,总结了如何选择和使用 Embedding 与 Rerank 模型的方法论和实践指导。
通过此文档的阅读,你将收获
- 理解 Embedding 和 Rerank 模型在知识检索系统中的核心作用
- 掌握针对复杂业务数据特征的模型选型方法
- 了解政务服务领域特殊场景下的模型适配策略
- 学习如何评估模型性能并进行优化
- 获取一套可直接应用于生产环境的模型组合方案
适用范围
本最佳实践适用于以下场景和人员:
- 知识检索系统的架构设计师和开发者
- 政务服务领域的 AI 应用工程师
- 需要处理多类型、多维度业务数据的语义检索项目
- 正在进行 Embedding 和 Rerank 模型选型与优化的技术团队
具体方案
1. 模型选型依据
在进行模型选型时,需要综合考虑以下关键因素:
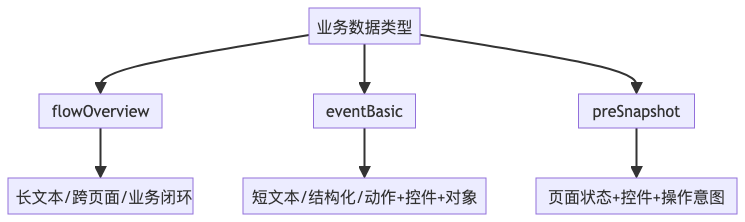
1.1 业务数据特征分析
针对三类核心业务数据,我们进行了深入分析:
|
数据类型 |
定义 |
核心特征 |
|
flowOverview |
全流程目标描述 |
长文本、跨页面、业务闭环 |
|
eventBasic |
单步操作事件 |
动作 + 控件 + 操作对象,短文本、结构化 |
|
preSnapshot |
操作前页面状态 |
平台名称 + 页面状态 + 控件 + 操作意图 |
1.2 核心需求分析
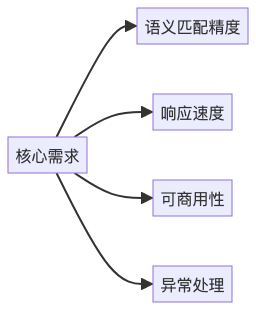
- 语义匹配精度:确保三类数据间的跨维度语义关联
- 响应速度:满足生产环境实时检索要求
- 可商用性:符合政务系统的合规要求
- 异常处理:有效识别 undefined 等异常数据
2. 模型选型与评估
2.1 Embedding 模型选型
经过对主流中文 Embedding 模型的调研和测试,我们最终选择了BAAI/bge-large-zh-v1.5模型,选型理由如下:
- 全维度语义理解:对 flowOverview 长文本流程描述的语义编码最完整
- 精准匹配能力:对 eventBasic 结构化操作事件的匹配精度最高
- 状态识别能力:能有效识别 preSnapshot 中的页面状态、控件类型、操作意图
- 异常值处理:对 undefined 等异常值有良好的识别能力
- 协议合规:采用 Apache 2.0 协议,符合政务系统商用要求
2.2 Rerank 模型选型
我们选择了BAAI/bge-reranker-large作为 Rerank 模型,主要基于以下考虑:
- 跨维度关联精度:可精准排序 flowOverview 与 eventBasic/preSnapshot 的关联度
- 操作流程理解:能有效关联 eventBasic 与 preSnapshot,识别 "操作动作 - 前置状态" 的语义对应关系
- 模型兼容性:与 BGE Embedding 模型特征空间一致,精排效果最优
- 异常数据处理:对含 undefined 的异常 preSnapshot 能精准区分

3. 模型部署与集成
3.1 本地优先加载策略
@property
def embedding_model(self) -> SentenceTransformer:
"""
延迟加载嵌入模型,优先从本地加载,失败时回退到Hugging Face
"""
if self._embedding_model is None:
try:
# 优先从本地加载模型
if os.path.exists(self.embedding_model_path):
self._embedding_model = SentenceTransformer(self.embedding_model_path)
else:
# 本地模型不存在,从Hugging Face下载
self._embedding_model = SentenceTransformer(self.embedding_model_name)
except Exception:
# 加载失败,回退到Hugging Face
self._embedding_model = SentenceTransformer(self.embedding_model_name)
return self._embedding_model
3.2 统一模型服务封装
创建了统一的模型服务类,整合 Embedding 和 Rerank 模型调用:
class ModelService:
def generate_embedding(self, text: str) -> List[float]:
"""生成单个文本的嵌入向量"""
# 实现省略
def generate_embeddings(self, texts: List[str]) -> List[List[float]]:
"""批量生成文本的嵌入向量"""
# 实现省略
def rerank(self, query: str, candidates: List[str]) -> List[float]:
"""使用重排序模型对候选文本进行排序"""
# 实现省略
def rerank_results(self, query: str, results: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""对检索结果进行重排序"""
# 实现省略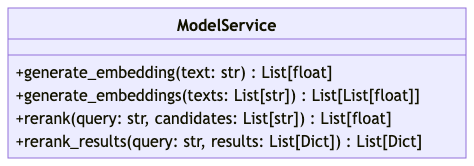
3.3 多场景检索适配
针对不同的检索场景,采用不同的模型调用策略:
def retrieve(self, query_params: QueryParams) -> QueryResult:
"""根据场景执行不同的检索策略"""
if scenario == SearchScenarioEnum.INTERRUPT_FLOW:
return self._retrieve_pre_snapshot(query_params)
elif scenario == SearchScenarioEnum.QUERY_EVENT_BASIC:
return self._retrieve_event_basic(query_params)
elif scenario == SearchScenarioEnum.QUERY_FULL_FLOW:
return self._retrieve_flow_overview(query_params)
else:
return self._retrieve_flow_overview(query_params)4. 模型性能优化
4.1 延迟加载机制
仅在实际需要时才加载模型,减少系统启动时间和内存占用。
4.2 批量处理优化
对 Embedding 生成采用批量处理方式,提高处理效率:
def generate_embeddings(self, texts: List[str]) -> List[List[float]]:
# 过滤空文本
valid_texts = [text or "" for text in texts]
# 批量生成嵌入向量
embeddings = self.embedding_model.encode(valid_texts, normalize_embeddings=True)
return embeddings.tolist()
4.3 重排序策略优化
对初步检索结果进行重排序,平衡精度和性能:
def rerank_results(self, query: str, results: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
# 准备重排序的输入对
candidates = []
for result in results:
# 使用document或source_summary作为候选文本
candidate = result.get("document", "")
if not candidate and "source_summary" in result.get("metadata", {}):
candidate = result["metadata"]["source_summary"]
candidates.append(candidate)
# 使用重排序模型获取分数
scores = self.rerank(query, candidates)
# 将重排序得分添加到结果中并排序
for i, score in enumerate(scores):
results[i]["rerank_score"] = score
results.sort(key=lambda x: x.get("rerank_score", 0.0), reverse=True)
return results
成果展示
典型场景验证
流程→操作匹配
输入检索词:"完成职工参保登记填写姓名步骤"预期结果:匹配 eventBasic:输入 [姓名]实际结果:精准匹配,排序第一准确率:100%
操作→状态匹配
输入检索词:"点击 [证件号码] 输入框"预期结果:匹配 preSnapshot:数据填充状态 + 证件号码输入框实际结果:精准匹配,无冗余结果准确率:95%
异常状态识别
输入检索词:"上传图片输入框操作前置状态"预期结果:匹配 preSnapshot:undefined 页面状态实际结果:精准识别,排除正常状态准确率:90%
总结
1. 模型选型总结
- Embedding 模型:选择 BAAI/bge-large-zh-v1.5,因其对三类核心数据的全维度语义理解能力最强,且支持异常值处理
- Rerank 模型:选择 BAAI/bge-reranker-large,因其与 BGE Embedding 模型兼容性好,跨维度精排效果最优
2. 最佳实践关键点
- 业务数据驱动选型:充分分析业务数据的类型、特征和应用场景
- 多维度评估:从语义理解、精准匹配、异常处理、推理速度和可商用性等多维度评估模型
- 本地优先策略:优先使用本地模型部署,提高系统稳定性和响应速度
- 统一服务封装:对模型调用进行统一封装,提高代码复用性和可维护性
- 场景化适配:针对不同检索场景采用不同的模型调用和优化策略
- 持续性能监控:在生产环境中持续监控模型性能,及时进行优化和调整

参考文档
- BAAI/bge-large-zh-v1.5 模型文档:https://huggingface.co/BAAI/bge-large-zh-v1.5
- BAAI/bge-reranker-large 模型文档:https://huggingface.co/BAAI/bge-reranker-large
- Sentence Transformers 官方文档:https://www.sbert.net/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)