大语言模型微调革命:LoRA技术揭秘,如何以极低算力实现高效微调!
今天我们来聊一下人工智能应用场景中大语言模型(LLM)微调技术 - LoRA。在大语言模型(LLM)席卷 AI 领域的今天,一个现实问题摆在所有开发者面前:如何在有限算力下高效微调百亿级模型? 全参数微调动辄需要数十张 A100、数百 GB 显存,成本高昂且难以落地。
今天我们来聊一下人工智能应用场景中大语言模型(LLM)微调技术 - LoRA。
在大语言模型(LLM)席卷 AI 领域的今天,一个现实问题摆在所有开发者面前:如何在有限算力下高效微调百亿级模型? 全参数微调动辄需要数十张 A100、数百 GB 显存,成本高昂且难以落地。
而 LoRA(Low-Rank Adaptation)技术的出现,彻底改变了这一局面——仅需调整原始模型不到 1% 的参数,即可达到接近全参微调的效果。本文将从架构痛点、数学本质、工程实现三个维度,深入解析 LoRA 为何能以“四两拨千斤”之力,撬动大模型微调的平民化革命……
一、 LoRA 到底解决了什么痛点 ?
纵所周知,传统全参数微调(Full-Parameter Fine-Tuning)往往要求更新整个模型的所有参数。以 Llama-3-8B 为例,其包含约 80 亿参数,若使用 FP16 精度,仅模型权重就需 16GB 显存。微调时还需存储优化器状态(如 Adam 需 3 倍参数量)、梯度、激活值,单卡根本无法承载,多卡训练成本极高。
因此,FPFT 虽然能使模型适应特定任务,但也面临着以下三大困境:
1、计算资源消耗巨大:随着 LLM 模型的规模不断增大,全参微调对计算资源的需求也呈指数增长。以 GPT-3 为例,其包含 1750 亿个参数,进行微调时需要极其庞大的计算能力,这对于大部分企业或研究机构来说几乎不可承受。
2、内存占用过大:每次进行微调时,整个模型的权重需要被加载到内存中,而 LLM 的庞大体积使得内存占用成为一大瓶颈,尤其是在 GPU 内存有限的情况下,往往无法顺利完成训练。
3、适应性较差:全参数微调需要大量标注数据才能完成任务适应。对于小规模数据集或资源有限的场景,全参数微调不仅效果有限,还可能导致模型的泛化能力下降。
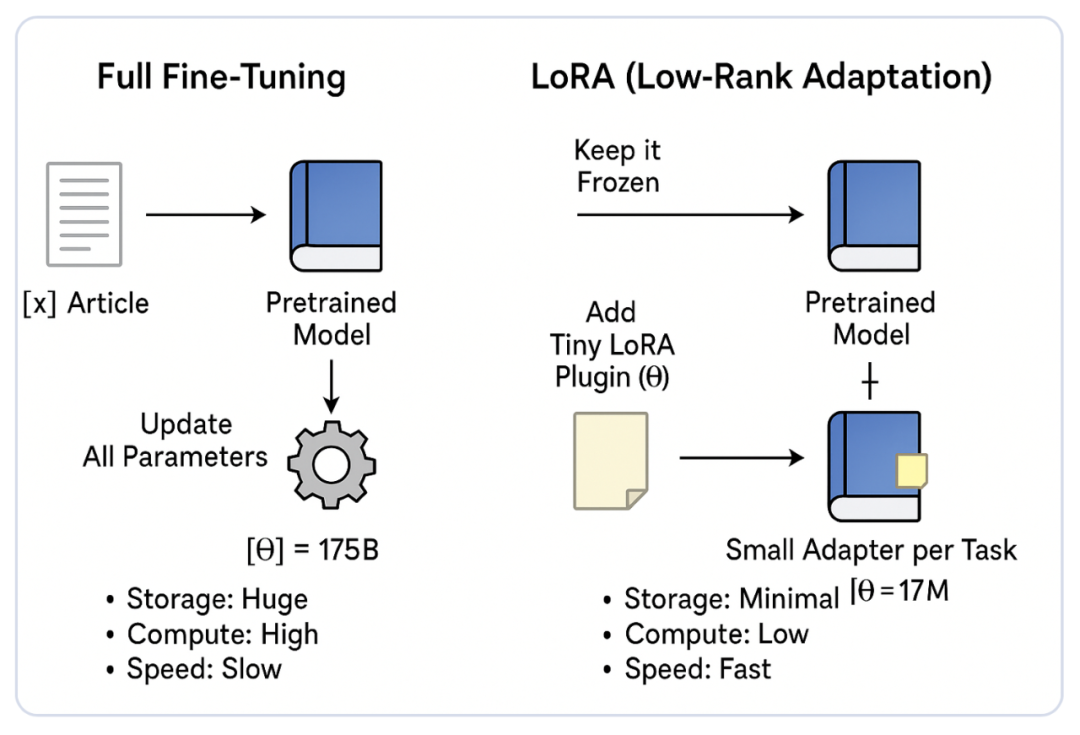
那么,该如何理解 LoRA(Low-Rank Adaptation)微调?
在百亿参数大模型成为基础设施的今天,如何在有限算力下高效适配下游任务,已成为工程落地的核心瓶颈。
LoRA(Low-Rank Adaptation)并非又一个“微调技巧”,而是一套基于权重更新低秩特性的架构设计范式——通过冻结原始模型、仅注入极小规模的可训练低秩模块,在几乎不损失性能的前提下,将微调成本压缩至原来的 1% 以下。
一言以蔽之:不重写知识,只微调“接口”。
从本质上来讲,LoRA的核心思想是“冻结”预训练模型的权重,只通过引入低秩矩阵来进行微调。这些低秩矩阵通常用 A 和 B 来表示:
-
矩阵 A 捕获了适应新任务所需的最小变化。
-
矩阵 B 将这些变化投影回到原始的参数空间。
通过这种方式,LoRA确保了原始模型的基础知识不会被破坏,同时在新任务的适应上做出了有效的调整。
二、LoRA 低秩适应的架构设计剖析
为什么是低秩 ?
大量实证研究表明:大模型在微调过程中,权重增量矩阵 ΔW 具有显著的低内在秩(low intrinsic rank)。这意味着,尽管 ΔW 是一个高维矩阵(例如 4096×4096),其有效信息却集中在少数几个主成分上。
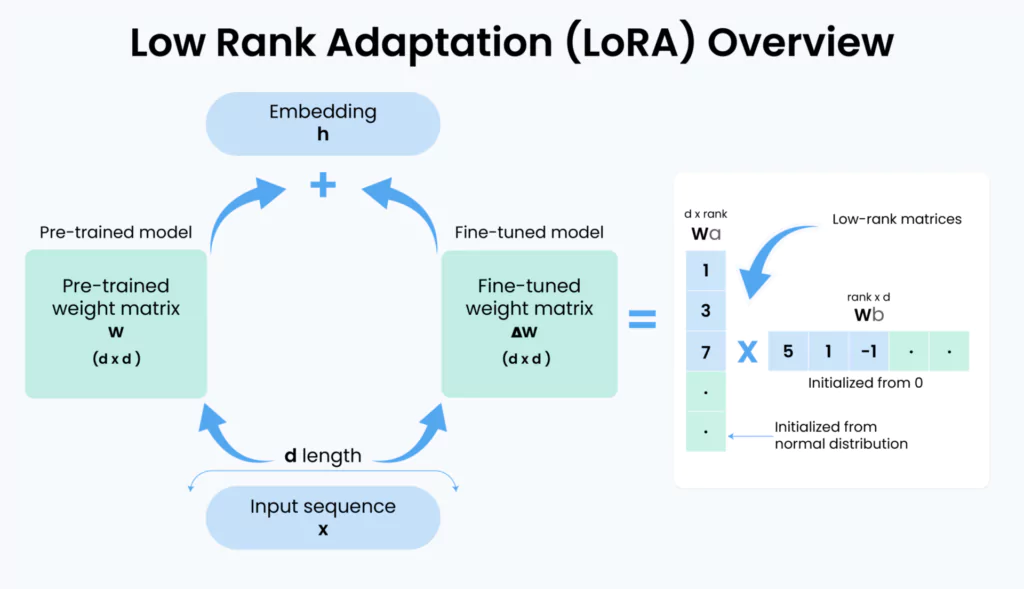
在 LoRA 中,矩阵 W 是模型的权重矩阵。而在传统的微调中,W 会直接进行调整,但在 LoRA 中,核心思想是将原始的权重矩阵 W 被分解为两个较小的低秩矩阵:A 和 B。这两个矩阵的乘积(A * B)就是对权重矩阵的调整部分:
ΔW = A × B
-
A 是一个较小的矩阵,表示模型需要进行的最小调整。
-
B 是另一个矩阵,将调整后的信息映射回原始权重空间。
通过这种低秩分解,LoRA 能够将微调过程中需要调整的参数数量大幅减少,同时保持原始模型的结构和基础知识不变。
为什么存在“秩®的选择”?
在 LoRA 中,秩® 的选择非常关键。秩表示矩阵的“维度”,它控制了低秩矩阵的参数数量。选择合适的秩是 LoRA 有效性的核心因素之一。
秩过大:如果选择的秩 r 太大,LoRA 的优势将被削弱,因为低秩矩阵的参数量仍然较大,无法有效减少计算和内存开销。
秩过小:如果秩选择过小,模型的拟合能力可能会下降,导致微调效果不佳。
在实际应用中,可以通过实验来选择最适合的秩值。通常,秩的大小会根据任务的复杂度和可用的计算资源进行调节。对于一般的应用场景,秩值通常设置在几到几十之间。
三、从 PyTorch 工程中看 LoRA 的实现逻辑
LoRA 的实现依赖于对 PyTorch 等深度学习框架的灵活使用,以下是如何在 PyTorch 中实现 LoRA 的基本代码和关键步骤。
首先,我们需要在原始模型的权重矩阵上添加低秩矩阵 A 和 B,并在前向传播时通过它们调整原始权重矩阵。具体如下所示:
import torch
import torch.nn as nn
class LoRALinear(nn.Module):
def __init__(self, in_features: int, out_features: int, r: int, lora_alpha: int = 16):
super().__init__()
self.r = r
self.lora_alpha = lora_alpha
self.scaling = lora_alpha / r # 核心缩放因子
# 冻结原始权重(通常从预训练模型加载)
self.weight = nn.Parameter(
torch.empty(out_features, in_features),
requires_grad=False
)
# 低秩分解矩阵
self.lora_A = nn.Parameter(torch.zeros(r, in_features)) # shape: (r, d_in)
self.lora_B = nn.Parameter(torch.zeros(out_features, r)) # shape: (d_out, r)
# 初始化:A ~ N(0, σ²), B = 0 → 初始 ΔW = 0
nn.init.normal_(self.lora_A, std=1/r)
nn.init.zeros_(self.lora_B)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 主干路径:冻结权重计算
base_out = torch.nn.functional.linear(x, self.weight)
# LoRA 路径:低秩扰动
lora_out = (x @ self.lora_A.T) @ self.lora_B.T
# 合并输出
return base_out + lora_out * self.scaling
在上述代码实现中,我们通过定义一个 LoRA 模块,为原始模型(如线性层)附加了两个低秩矩阵 A与 B。在前向传播阶段,模型会根据 A 和 B 的乘积对冻结的原始权重 W₀进行轻量级偏移,从而实现参数高效的微调。
从架构设计角度看,LoRA 在实现细节上有三个关键点:
1、矩阵 B 初始化为零(B = 0)
这是一项非常重要的架构决策。在训练初期,`ΔW = B @ A = 0`,意味着模型的行为与原始预训练模型 **保持完全一致,**这带来了两个优势:
- (1)安全启动(Safe Warm-up):不会因为随机初始化造成模型预测突变,破坏预训练知识体系。
- (2)快速收敛(Stable Convergence):从稳定基线开始学习,优化路径更平滑。
2、引入缩放因子 α / r(Scaling)
LoRA 在结构中使用了一个可调节的缩放因子:
ΔW=(B@A)×αrΔW=(B@A)×rα
其中:
-
r:低秩矩阵的秩(rank),决定可训练自由度
-
α:缩放系数,用于控制更新强度
这种设计的架构价值在于:
-
(1)统一学习率(LR Invariance):即使 r 发生变化,微调强度仍然稳定,不需要重新寻找学习率等超参数。
-
(2)提高鲁棒性与部署便捷度:不同任务、不同结构间迁移更容易。
3、无额外推理开销:参数合并(Weight Merging)
LoRA 的另一个工程亮点是推理阶段 **零额外额外计算**。训练完成后,可以把低秩更新合并回原始权重:
Wmerged=W0+(B@A)×αrWmerged=W0+(B@A)×rα
合并后:
-
模型不再需要 A、B,也不再计算矩阵乘法
-
推理路径 完全与原模型一致
-
延迟(latency)与吞吐(throughput)保持不变
这让 LoRA 在实际部署中极具性价比,非常适合用于边缘设备、本地模型运行以及大规模在线推理服务。
综上所述,LoRA 本质上是对大模型微调方式的一次“降维重构”:它利用了“大模型知识高度结构化”的事实,将任务适配压缩到更低维度的流形(Manifold)上,以最小扰动实现最大适应。
这一思路已逐渐越过 NLP 的边界,拓展至视觉(如 Stable Diffusion 的 LoRA)、语音、甚至强化学习。未来随着 DoRA、PiSSA 等方法的演进,我们可能会看到:高效微调不再是权宜之计,而是更优的模型演化路线。最终,我们从 LoRA 得到一个朴素但深刻的启示:
“最强大的适应,往往源自最小而精准的改变。”
四、如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

**

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 50
50 0
0- 0



 已为社区贡献180条内容
已为社区贡献180条内容

所有评论(0)