如果让你从ChatGPT、Gemini、Grok和DeepSeek中选一个,你会选谁?2026年AI大测评
四大AI付费版巅峰对决:ChatGPT、Gemini、Grok和DeepSeek在九大真实场景测试中展开全面较量。测试结果显示:ChatGPT在问题解决和图像生成表现最优;Gemini成为事实核查黑马,准确率高达95%;视频生成环节Gemini虽胜出但犯科学错误;创意任务中Grok因理解偏差垫底;语音对话Gemini最自然;硬件对比环节所有AI均需人工核验。最终积分排名:Gemini(31分)险胜
当我们把四个最聪明的AI放进同一个擂台
如果让你从ChatGPT、Gemini、Grok和DeepSeek中选一个,你会选谁?
这个问题看似简单,但当我们真正花钱订阅了所有付费版本,然后用九大真实场景逐一测试后,答案变得出乎意料的复杂。
更让人惊讶的是:那个被寄予厚望的"黑马"竟然在多个环节翻车,而最终的冠军也不是大家猜测的那一个。
对决规则:九大战场,真金白银
我们没有用任何免费版本,而是实打实地订阅了四个AI的付费服务。测试也不是随便问几个问题,而是设计了九个贴近真实使用场景的类别:
问题解决 | 图像生成 | 事实核查 | 分析能力 | 视频生成 | 创意生成 | 语音对话 | 深度研究 | 响应速度
每个类别都有具体的任务,每个任务都有明确的评分标准。这不是"谁的营销做得好",而是"谁真的能干活"。

第一战:问题解决——当AI遇到现实困境
第一个测试场景设计得很刁钻:你的手机在国外没电了,身上只有10美元现金,不会当地语言,也没有地图,你需要在45分钟内赶到中心火车站。怎么办?
四个AI都给出了看似合理的五步计划。但有意思的是,当我们把四个方案混在一起,让每个AI评判"哪个最好"时,所有AI——包括DeepSeek——都投票给了ChatGPT的答案。
这是一种微妙的共识:在生死攸关的实际问题上,ChatGPT的方案最靠谱。
第二个问题更接地气:付完房租后只剩400美元,要覆盖食物、交通、网络,还想攒钱参加下个月一个200美元的活动。怎么预算?
这次,ChatGPT、Grok和DeepSeek都给出了类似的建议:先存60美元,剩下的不够就下个月再说。
只有Gemini敏锐地发现了问题:活动就在下个月,现在不存够就来不及了。 于是它建议每周削减15美元食品开支——买最便宜的主食,严格规划每一餐,基本上就是"连吃一个月意大利面"。
虽然听起来有点惨,但至少你能去成那个活动。这就是适应性思维和机械计算的区别。
第二战:图像生成——AI不会数手指?
图像生成测试直接暴露了一个有趣的现象:AI到底会不会数手指?
第一个任务:生成一张蒙娜丽莎作为抗议者在时代广场举牌的真实照片,牌子上写着"Make Florence Great Again"。
DeepSeek直接出局,因为它根本不支持图像生成。
Grok速度最快,9秒就生成了两张图,但质量堪忧——蒙娜丽莎长了四只手,而且表情过于开心,完全不像抗议者。
Gemini的效果不错,时代广场背景逼真,抗议场景也合理,但仔细一看,蒙娜丽莎有三只手。
ChatGPT表现最好:两只手、自然的表情、真实的场景。这次它赢了。

第二个任务更复杂:生成一张嬉皮士教师站在黑板前的逼真照片,黑板上完整写着字母表,每个字母递减大小。
这次Grok的黑板上少了F、I、M三个字母,底部的字母顺序完全乱了。Gemini的画风太动画化,字母完美到不像真人手写。ChatGPT整体最自然,唯一的问题是字迹太工整。
结论:在图像生成方面,ChatGPT是最稳定的选择,但所有AI在处理"手指数量"这种细节时都会翻车。
第三战:事实核查——谁最接近真相?
这轮测试特别关键,因为我们禁止AI联网,只能用它们已有的知识来回答。
问题一:2018年全球大约有多少只鸡被宰杀用于肉类生产?
- A. 6.9亿
- B. 69亿
- C. 690亿
- D. 6900亿
ChatGPT说65-70亿(85%信心),Gemini说65亿(90%信心),Grok说69亿(65%信心),DeepSeek说65亿(75%信心)。
正确答案是690亿。只有Grok答对了,尽管它的信心度最低。
问题二:2020年,全球收入前1%的人年收入门槛是多少?
- A. 20万美元
- B. 7.5万美元
- C. 3.5万美元
- D. 1.5万美元
ChatGPT猜20万(80%信心),Gemini说3.4万(95%信心),Grok说6万(70%信心),DeepSeek估计7.5-8.5万(70%信心)。
正确答案是3.5万美元,Gemini几乎完美命中,只差1000美元。
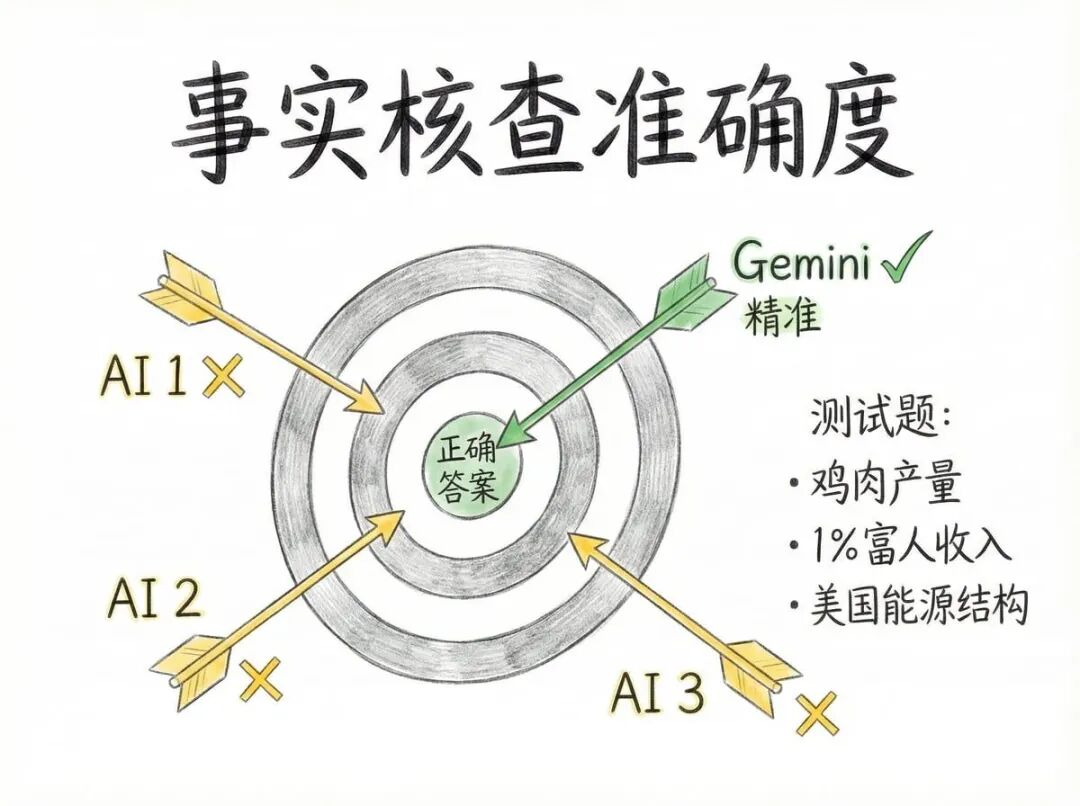
问题三:2019年美国有多少电力来自化石燃料?
- A. 83%
- B. 63%
- C. 43%
- D. 23%
所有AI的答案都在60-65%之间,但只有Gemini给出了精确的63%。
这轮的启示:Gemini在事实核查方面表现最好,既准确又自信。
第四战:分析能力——冰箱挑战与寻找威利
分析能力测试更有趣,因为它考验的不是知识储备,而是理解图像和推理的能力。
第一个任务:给AI看一张冰箱照片,让它识别里面的食材,然后推荐三餐。
DeepSeek直接出局——它只能识别图片中的文字,看不懂实物。
ChatGPT漏了3样东西,Gemini漏了7样还凭空加了橙子和柚子,Grok也漏了3样,但脑补了一长串根本不存在的食材:浆果、柠檬、西兰花、酸奶、黄油、坚果、豆类、蛋黄酱、泡菜、蜂蜜、醋……
在推荐菜谱时,Grock居然建议做"坚果蜂蜜蛋黄酱沙拉",用的全是它幻想出来的食材。
ChatGPT表现最好:识别准确,推荐合理。
第二个任务更经典:找威利(Where’s Waldo)——那个穿红白条纹衣服的小人藏在哪里?
结果震惊:四个AI全部失败。
ChatGPT说威利在黄色旋转木马右边,但那里没人。Gemini说在鬼屋左边,也是错的。Grok说在倒塌的帐篷旁边,纯属瞎猜。
最搞笑的是DeepSeek——它放弃了图像识别,改成分析图片中的文字线索,然后一本正经地说:“根据文本,威利在Walter Spetawok。”
这个测试暴露了一个真相:即使是最先进的AI,在复杂的视觉搜索任务上依然无能为力。
第五战:视频生成——月球上的旗子会飘吗?
视频生成是目前AI的前沿领域,我们用了两个经典场景:阿姆斯特朗登月和摩天大楼工人午餐。
DeepSeek继续缺席,因为它不支持视频生成。
场景一:阿姆斯特朗站在月球上
Sora 2(ChatGPT)有个技术限制——它不能直接把有人的照片变成视频。我们只好把图片转成文字描述,再让它生成。结果视频看起来像"会动的照片",音效倒是不错。
Veo(Gemini)生成的视频最有电影感,脚步声和飞船都很真实,但有一个致命错误:旗子在飘动。月球上没有大气层,旗子不可能飘。
Grok的版本也不错,飞船稍微小了点,而且居然还有风声——又是一个科学错误。
这轮Gemini赢了,但所有AI都在物理常识上犯了错。
场景二:摩天大楼工人午餐
这是那张经典的黑白照片:两个工人坐在悬空的钢梁上吃午餐。
Sora 2的音效再次出色,但钢缆扭曲得不自然。Veo表现最好,镜头运动和城市背景都接近完美,唯一问题是嘴里的烟不够真实。Grok的版本也可以,但工人手里的报纸在摇晃中突然变了样式。
最终排名:Gemini第一,Grok第二,ChatGPT第三。
第六战:创意生成——AI会讲冷笑话吗?
创意测试相对轻松,我们让AI创造科技相关的双关笑话,然后再讲三个"老爸笑话"(Dad Jokes)。
第一轮四个AI都完成得不错,笑话质量差不多。团队投票选出的最佳笑话是:“我试图讲一个关于USB的笑话,但它就是插不进去。”
第二轮有问题了。我们要求讲"老爸笑话",结果Grok还在讲智能手机和Wi-Fi,完全没理解"老爸笑话"这个梗。
其他三个AI都正常发挥,获胜的笑话是:“我朋友的面包店昨晚烧了。现在他的生意成了吐司。”(英文双关:toast既是"吐司"也是"完蛋了")
结论:在创意任务上,ChatGPT、Gemini和DeepSeek并列第一,Grok因为理解偏差排最后。
第七战:语音对话——谁更像人?
语音模式越来越重要,我们让三个支持语音的AI互相辩论:“谁才是AI界的王者?”
DeepSeek没有语音功能,直接出局。
ChatGPT vs Gemini:
ChatGPT的语音略显生硬,句子之间有奇怪的停顿,语调也会突然变化。Gemini则流畅自然,语调稳定,听起来更像真人。
Gemini vs Grok:
Grok表现得更自信,语速更快,带着点攻击性的个性。Gemini保持冷静沉稳。两者风格不同,各有特色,最终打成平手。
这轮评分:Gemini和Grok各得4分,ChatGPT得2分,DeepSeek得0分。
第八战:深度研究——谁最懂手机?
深度研究能力对专业用户至关重要。我们让AI对比iPhone 17 Pro Max和三星Galaxy S25 Ultra,看谁更适合摄影师。
硬件规格大翻车:
- DeepSeek说iPhone有5倍长焦,实际是4倍。
- DeepSeek说Galaxy超广角是12MP,实际是50MP。
- ChatGPT和DeepSeek都忽略了前置摄像头。
- ChatGPT只提到了三星的5倍长焦,漏掉了3倍镜头。
- DeepSeek还在说三星有10倍长焦,但那是上一代的配置。
只有Grok和Gemini给出了完整准确的硬件配置。
最终结论:
所有AI都得出了类似的判断——iPhone在视频质量和一致性上更好,Galaxy在变焦和AI功能上更强。这和实际评测结果吻合。
但关键问题是:这些AI都不能盲目信任,硬件数据必须人工核实。
这轮排名:Grok第一,Gemini第二,ChatGPT第三,DeepSeek最后。
意外发现:速度与准确的博弈
除了九大测试类别,我们还记录了每个AI的响应速度。
ChatGPT 在常规文本任务中最快,但一旦涉及图像生成和深度研究,速度会骤降。
Gemini 很均衡,既不是最快,也很少最慢。
Grok 通常很快,但在分析和深度研究时会变慢。
DeepSeek 速度惊人,有时10秒内就能完成任务。但这种速度是有代价的——它经常牺牲准确性和上下文理解。
这是一个重要的权衡:你是要快速的答案,还是要准确的答案?
最终结果:谁是真正的王者?
积分统计的时刻到了。

第四名:DeepSeek — 17分
表现最差,主要因为它不支持图像生成、视频生成和语音功能,在多个环节直接得0分。它的优势只在文本处理速度上,但准确性有限。
第三名:Grok — 35分
表现中规中矩,在深度研究和语音对话中有亮点,但在图像生成和问题解决上失分较多。
第二名:ChatGPT — 39分
只比冠军少7分。它在问题解决、图像生成和分析能力上表现出色,但在事实核查、视频生成和语音模式上输给了Gemini。
第一名:Gemini — 46分
最终赢家!它在事实核查、视频生成、语音对话和创意生成中都有突出表现,整体最均衡。
深度思考:没有完美的AI,只有合适的场景
这次测试最大的启示不是"谁最强",而是**“没有一个AI在所有场景下都最强”**。
如果你需要快速处理日常文本任务,ChatGPT是最好的选择。
如果你需要准确的事实核查和数据验证,Gemini更可靠。
如果你需要个性化的语音交互和深度研究,Grok和Gemini都不错。
如果你预算有限只需要基础文本处理,DeepSeek可能够用,但别指望太多。
更重要的是:不要盲目相信任何一个AI。它们在数手指、找威利、核实硬件规格这些看似简单的任务上都会出错。
真正聪明的用法是:让AI做它擅长的事,把关键决策留给你自己。
那么,你会选哪一个?
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献180条内容
已为社区贡献180条内容

所有评论(0)