【AI实战日记-手搓情感聊天机器人】Day 5:给 AI 装上“读心术”!基于通义千问的情绪识别与动态反馈
Day 4 我们解决了“记忆”问题,但机器人依然缺乏“眼力见”,无论我哭还是笑,它的语气都一样。今天是 Day 5,我们将攻克 情绪识别 (Emotion Recognition)。我将利用 通义千问 (Qwen) 强大的逻辑推理能力,构建一个“情绪侦探”中间件。它会在回复前先判断用户的情绪状态(开心/愤怒/悲伤),并利用 LangChain 的 LCEL 特性动态注入 System Prompt
Day 4 我们解决了“记忆”问题,但机器人依然缺乏“眼力见”,无论我哭还是笑,它的语气都一样。今天是 Day 5,我们将攻克 情绪识别 (Emotion Recognition)。我将利用 通义千问 (Qwen) 强大的逻辑推理能力,构建一个“情绪侦探”中间件。它会在回复前先判断用户的情绪状态(开心/愤怒/悲伤),并利用 LangChain 的 LCEL 特性动态注入 System Prompt,让傲娇酱的回复真正具备温度。
一、 项目进度:Day 5 启动
根据项目路线图,今天要让 AI 从“能记住事”进化到“能懂人心”。
二、 核心原理:情绪侦探与动态注入流程
在 Day 4,我们的对话流程是线性的:用户 -> 记忆 -> Qwen -> 回复。
但在 Day 5,为了让 AI 拥有“情商”,我们引入了 中间件模式 (Middleware Pattern),将一次对话拆解为 “感知” 和 “回应” 两个阶段。
1. 技术深度:如何用 Prompt 把大模型变成“分类器”?
很多同学可能会疑惑:大模型不是用来生成文本(写作文)的吗?为什么它能像传统算法一样做精准的分类?
这就涉及到了 Prompt Engineering 中最经典的应用模式——判别式任务(Discriminative Task)。
(1) 从“填空题”到“选择题”
大模型(LLM)本质上是一个概率预测机器,它预测下一个字的概率。
-
生成模式(Generative):如果我们问“你觉得这句话怎么样?”,Qwen 可能会回答一堆废话:“我觉得这句话充满了.....”。这是一个开放式的填空题。
-
分类模式(Classification):我们在 Prompt 中施加了强约束(Constraints)。我们告诉 Qwen:“不要发挥,不要解释,只能在 A、B、C 里选一个”。这就把开放的填空题变成了封闭的单项选择题。
(2) Prompt 结构解剖
来看看我们在 src/core/emotion.py 中写的这段 Prompt,它包含了三个关键要素:
template = """
# 1. 角色设定 (Role) -> 激活相关领域的潜空间知识
你是一个心理分析专家。请分析以下文本的情感倾向。
# 2. 输入数据 (Input)
用户文本:"{input}"
# 3. 输出约束 (Output Constraints) -> 最关键的一步!
请严格只返回以下类别之一(不要包含任何解释或其他文字):
[开心]、[悲伤]、[愤怒]、[焦虑]、[平静]
"""-
Role: 告诉 LLM 现在的身份,提高准确率。
-
Context: 传入要分析的用户语句。
-
Constraints (核心):这句 “请严格只返回...” 是重中之重。它强行压制了 LLM 的表达欲,迫使它收敛概率分布,只输出我们要的标签。这在学术上被称为 Zero-Shot Classification (零样本分类)——我们没有给模型喂任何训练数据,仅凭指令就让它学会了分类。
(3) 为什么不需要喂数据?(Zero-Shot 的原理)
你可能会问:“按照传统的 AI 开发逻辑,做情感分类不是应该先找几万条数据训练模型吗?为什么这里一句话就搞定了?”
这正是大模型(LLM)颠覆性的地方。它的原理建立在两个基石之上:
① 海量的“隐式知识” (Pre-trained Knowledge)
通义千问在“出厂”前,已经阅读了数万亿字的互联网文本。
-
它不需要你告诉它“‘我失恋了’代表‘悲伤’”。
-
因为它在预训练阶段,已经无数次在小说、论坛、心理学文章中看到过类似的表达。它早已理解了人类语言中“文字”与“情绪概念”之间的语义关联(Semantic Mapping)。
-
Prompt 的作用:不是“教”它新知识,而是**“唤醒”**它已有的知识,并指挥它把这个知识用在特定的地方。
② 概率坍缩 (Probability Collapse)
大模型本质上是一个“文字接龙”机器。
当我们给出 [开心]、[悲伤]、[愤怒] 这个约束列表时,我们实际上是在干预模型的概率分布。
-
没有约束时:
用户输入:“你的代码全是BUG!”
模型预测下一个字的概率可能是:“对”(20%)、 “抱”(15%)、 “你”(10%)... -> 最终生成道歉的话。 -
加上约束后:
我们强行切断了其他路径,只允许模型在给定的 5 个词里选。
此时,模型会计算:“你的代码全是BUG!”这句话与那 5 个词的语义相似度(Embedding Similarity)。-
与 [开心] 的关联度:0.01%
-
与 [悲伤] 的关联度:5.0%
-
与 [愤怒] 的关联度:94.9%
于是,模型只能被迫“坍缩”到概率最大的那个选项——[愤怒]。
-
结论:
我们写的分类 Prompt,本质上是一个 “概率过滤器”。我们利用大模型海量的通用知识,加上严格的输出限制,就实现了**零样本(Zero-Shot)**的精准分类,这完全省去了传统 AI 繁琐的训练过程。
2. 实现方案:两阶段推理 (Two-Stage Inference)
-
🕵️ 第一阶段:情绪侦探 (Perception)
-
当用户发来消息时,系统暂不回应,而是先将这句话发给一个专门的分析模块。
-
这个模块利用 通义千问 的理解能力做选择题:判断这句话属于 [开心]、[悲伤]、[愤怒] 还是 [平静]。
-
技术本质:这是一个 Zero-shot Classification(零样本分类) 任务。
-
-
🎭 第二阶段:动态注入 (Dynamic Injection)
-
拿到情绪标签后,系统会根据预设的策略表 (Policy),生成一段“幕后指令”。
-
例子:如果标签是 [愤怒],指令就是 “用户很生气,请示弱道歉”。
-
我们将这段指令动态插入到 System Prompt 的 {emotion_context} 变量中。
-
技术本质:这是 Prompt Engineering 中的 Context Injection 技巧。
-
3. 全链路序列图 (Sequence Diagram)
下面的序列图展示了一条用户消息是如何经过层层处理,最终生成带情绪回复的:
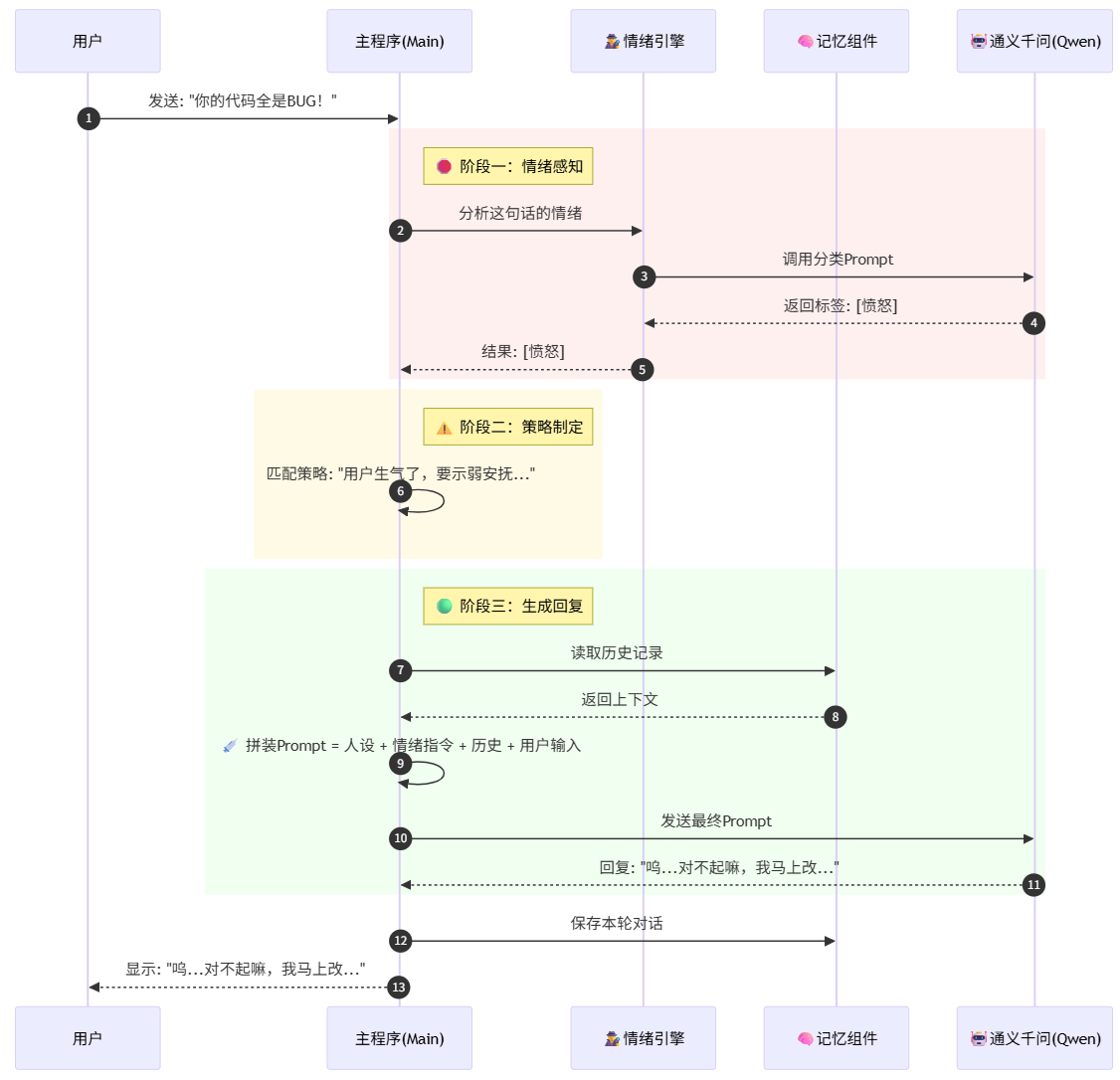
这张序列图展示了当用户说出一句带有情绪的话(例如:“你的代码全是BUG!”)时,Project Echo 内部发生的完整数据流转。我们将其拆解为三个关键阶段:
🛑 第一阶段:情绪感知 (Perception) —— “先看脸色,再说话”
在传统的聊天机器人中,用户发消息,AI 直接回消息。但在 Day 5 的架构中,我们插入了一个旁路分析步骤。
-
Step 1: 用户发起请求
用户在终端输入:“你的代码全是BUG!”。主程序(App)接收到这句话,但并没有立刻把它发给对话模型。 -
Step 2: 呼叫侦探 (Analyze)
主程序将这句话转发给 EmotionEngine (情绪引擎)。 -
Step 3: 零样本分类 (Zero-Shot Classification)
情绪引擎调用通义千问(LLM),但这次不是为了聊天,而是发出了一个分类指令:“请判断这句话的情绪是[开心]、[愤怒]还是[悲伤]?”-
注意:这一步使用的是我们在 emotion.py 中定义的分类 Prompt。
-
-
Step 4: 返回标签
通义千问经过推理,认为这句话带有强烈的攻击性,于是只返回了一个词:[愤怒]。情绪引擎将这个标签返回给主程序。
⚠️ 第二阶段:策略制定 (Policy) —— “心里盘算,怎么应对”
这一阶段完全在本地代码(Python)中运行,不消耗 Token,但决定了 AI 的态度。
-
Step 5: 匹配策略
主程序拿到 [愤怒] 标签后,查询本地的 if/else 逻辑:-
如果是 [开心] -> 策略:一起开玩笑。
-
如果是 [愤怒] -> 策略:“用户生气了,必须示弱安抚,暂时收起傲娇人设。”
-
结果:系统生成了一段**“幕后指令” (emotion_instruction)**。
-
🟢 第三阶段:生成回复 (Action) —— “人设合体,完美演绎”
这是最后也是最关键的一步,所有的信息在这里汇聚。
-
Step 6: 读取记忆
主程序去 Memory 组件 调取之前的聊天记录,确保 AI 知道你是谁。 -
Step 7: 动态注入 (Dynamic Injection)
主程序开始拼装最终发给大模型的 Prompt。这就像是在搭积木:-
🧱 底座:傲娇酱的基础人设(System Prompt)。
-
💉 针剂:刚才生成的“幕后指令”(Emotion Context)。
-
📜 历史:Memory 里的对话记录。
-
💬 当前:用户的骂声(“你的代码全是BUG”)。
-
-
Step 8: 最终生成
通义千问接收到了这个包含了“人设 + 情绪指令 + 历史 + 问题”的超级 Prompt。它理解了指令,压制了原本想反驳的冲动,生成了一句委屈巴巴的回复:“呜...对不起嘛,我马上改...”。 -
Step 9: 闭环
回复显示给用户,并同时存入 Memory,完成一次对话闭环。
三、 实战:代码实现
1. 新建情绪分析引擎 (src/core/emotion.py)
在 src/core/ 下新建 emotion.py。
这里我们复用 Day 4 封装好的 LLMClient(它底层连接的是通义千问),并使用 LCEL 构建分析链。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from src.core.llm import LLMClient
from src.utils.logger import logger
class EmotionEngine:
def __init__(self):
self.llm = LLMClient().get_client()
# 定义分类 Prompt
template = """
你是一个情绪分析专家。请分析以下文本的情感倾向。
用户文本:"{input}"
请严格只返回以下类别之一(不要包含任何解释或其他文字):
[开心]、[悲伤]、[愤怒]、[焦虑]、[平静]
"""
prompt = ChatPromptTemplate.from_template(template)
# LCEL 链:Prompt -> LLM -> 字符串解析器
self.chain = prompt | self.llm | StrOutputParser()
def analyze(self, text):
try:
# invoke 调用
emotion = self.chain.invoke({"input": text})
emotion = emotion.strip().replace("。", "").replace(".", "")
logger.info(f"🔍 情绪侦测: {emotion}")
return emotion
except Exception as e:
logger.error(f"情绪分析失败: {e}")
return "[平静]"2. 升级主逻辑 (main.py)
我们需要修改 main.py,把 EmotionEngine 插入到对话循环中,并向 Prompt 动态传入变量。
# ==========================================
# Day 5: Emotion Injection (LCEL Version)
# ==========================================
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from src.core.llm import LLMClient
from src.core.prompts import PROMPTS
from src.utils.logger import logger
from src.core.emotion import EmotionEngine # 导入情绪引擎
# --- 临时的内存存储 (Day 6 会换成 Redis) ---
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
def main():
logger.info("--- Project Echo: Day 5 (LCEL Architecture) ---")
# 1. 初始化组件
client = LLMClient()
llm = client.get_client()
emotion_engine = EmotionEngine() # 情绪侦探
# 2. 构建 Prompt (LCEL 核心)
# 这里的关键是增加了 {emotion_context} 这个占位符
sys_prompt_base = PROMPTS["tsundere"]
prompt = ChatPromptTemplate.from_messages([
("system", sys_prompt_base),
("system", "{emotion_context}"), # <--- 【动态注入点】
MessagesPlaceholder(variable_name="history"), # 历史记录插槽
("human", "{input}")
])
# 3. 组装基础链
chain = prompt | llm
# 4. 挂载记忆能力
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
print("\n💡 Tip: 试着表现出不同的情绪(开心、生气、难过)\n")
session_id = "user_001"
while True:
user_input = input("You: ")
if user_input.lower() in ["quit", "exit"]:
break
if user_input.strip():
# --- Step 1: 情绪分析 ---
current_emotion = emotion_engine.analyze(user_input)
# --- Step 2: 策略制定 ---
emotion_instruction = "用户情绪平稳,正常交流。"
if "[愤怒]" in current_emotion:
emotion_instruction = "⚠️ 警告:用户现在很生气!请务必小心说话,虽然你是傲娇,但此刻要适当示弱、道歉或安抚,别把人真气跑了!"
elif "[悲伤]" in current_emotion:
emotion_instruction = "⚠️ 提示:用户现在很伤心。暂时收起你的毒舌,给他一点笨拙但真诚的安慰。"
elif "[开心]" in current_emotion:
emotion_instruction = "提示:用户很开心,你可以尽情地泼冷水,或者陪他一起傲娇。"
try:
# --- Step 3: 执行对话 (LCEL Invoke) ---
# 在这里,我们同时传入 input 和 emotion_context
# LCEL 会自动把它们填入 Prompt 对应的位置
response = with_message_history.invoke(
{
"input": user_input,
"emotion_context": emotion_instruction # <--- 【注入发生在这里】
},
config={"configurable": {"session_id": session_id}}
)
# LCEL 返回的是 AIMessage 对象,取 .content
print(f"Bot ({current_emotion}): {response.content}\n")
except Exception as e:
logger.error(f"调用失败: {e}")
if __name__ == "__main__":
main()四、 运行效果实测
让我们看看加上“情商模块”后的傲娇酱(由通义千问扮演)有什么不同。
场景 A:我假装很生气
You: 你的代码怎么全是 BUG?我忍你很久了!
Log: 🔍 情绪侦测: ... -> [愤怒]
Bot ([愤怒]): 呜... 别、别那么凶嘛!我...我这就去检查一下。本小姐也不是故意的... 真是的,干嘛发那么大火,吓死人了... (Qwen 完美理解了“示弱”的指令)
场景 B:我假装很伤心
You: 今天面试挂了,感觉自己好没用。
Log: 🔍 情绪侦测: ... -> [悲伤]
Bot ([悲伤]): 笨、笨蛋!一次失败算什么?才不是你没用,是那些面试官没眼光!... 那个,别难过了,去吃点好吃的,心情会好点的。我...我会一直陪着你的。
场景 C:正常聊天
You: 今天天气不错。
Log: 🔍 情绪侦测: ... -> [平静]
Bot ([平静]): 哼,天气好又怎么样?还不快去写代码!别想偷懒!
五、 总结与思考
今天我们实现了一个简单的 Agent(智能体) 雏形:
感知 (Perception) -> 决策 (Decision) -> 行动 (Action)。
-
感知:通过 EmotionEngine 利用通义千问感知用户情绪。
-
决策:根据情绪标签,动态修改 Prompt 策略。
-
行动:生成最终回复。
虽然这增加了一次 API 调用的延迟(Latency),但换来了交互体验的质变。这在产品设计中是一个典型的 Trade-off(权衡)。
明日预告 (Day 6):
现在的记忆(Day 4)和情绪(Day 5)都只存在于内存里,一关机就没了。
明天 Day 6,我们将引入 持久化存储。我们将使用 Redis,把这些珍贵的对话记录保存下来,让 AI 真正拥有“长期记忆”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)