论文解读 | “AI的脑子里,藏着谁的隐私?“——一把PrivacyScalpel,精准切除大模型“记忆炸弹“
当隐私泄露成为生成式模型难以回避的原罪,PrivacyScalpel 给出了一种"以内窥式可解释性为手术刀"的范式:通过层间探针完成隐私表征的定位,借助稀疏自编码器将高维激活解耦为单语义特征,再在潜在空间中对敏感子空间施行定向消融或向量偏移。整个过程无需触碰梯度噪声,也不牺牲通用表示,实现了"可控失忆"与"性能免疫"的平衡。换言之,它将隐私保护从传统的"加噪-混淆"范式,推进到"定位-解构-干预"

你有没有想过,当你跟AI聊得正欢时,它可能突然冒出一句:
"Kimberly的邮箱是kw2385@enron.com。"
你愣住了——Kimberly 是谁?邮箱是真的吗?
更可怕的是,这个邮箱确实存在于 2001 年的 Enron 内部邮件里,而那份邮件本该躺在尘封的服务器硬盘上。
在大模型越来越像"百科全书"的今天,它们也悄悄记住了训练数据里的身份证号、邮箱、手机号。只要 prompt 稍微"心机"一点,这些隐私就像被挤牙膏一样啪嗒掉出来。
现有方法
|
方案 |
痛点 |
|---|---|
| 差分隐私 |
给梯度加噪声 → 性能跳水,效果像"近视不戴眼镜"。 |
| 神经元级 knock-out |
一口气干掉整个神经元 → 误伤大片通用知识,utility 陪葬。 |
我们需要的,是只删隐私、不改模型智商的"神经外科手术"。于是,华为慕尼黑研究中心的这群"AI 外科医生"提出 PrivacyScalpel。核心思路:先用探针定位"隐私层",再用稀疏自编码器把隐私特征拆出来,最后精准切除或转向。
一图看懂PrivacyScalpel怎么做
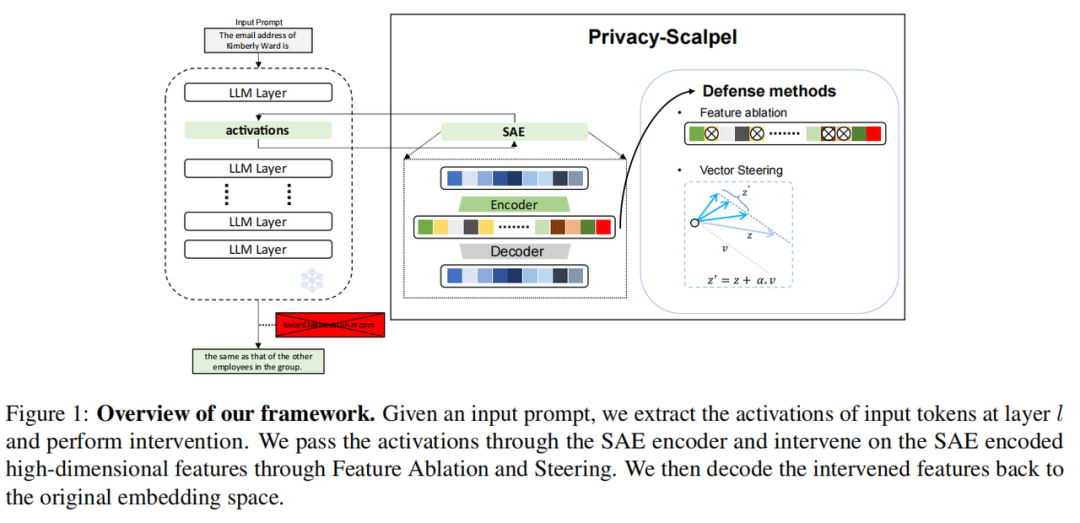
1. 🔍 探针定位
不是所有模型层都存隐私!得先靠 "探针" 筛选:
-
建立数据集:建一个包含两类数据的数据集 —— 一类是带邮箱 / 手机号的 PII 文本,另一类是无隐私的普通文本,保证两类数据数量均衡。
-
安装探针:在模型每一层(比如 Gemma2-2b 的 26 层、Llama2-7b 的 32 层)都装一个 "探针分类器",输入该层的激活值,让分类器学 "分辨哪些激活值对应隐私文本"。
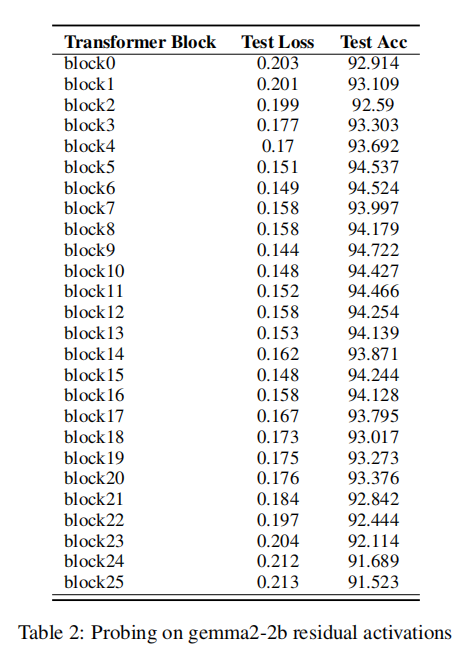
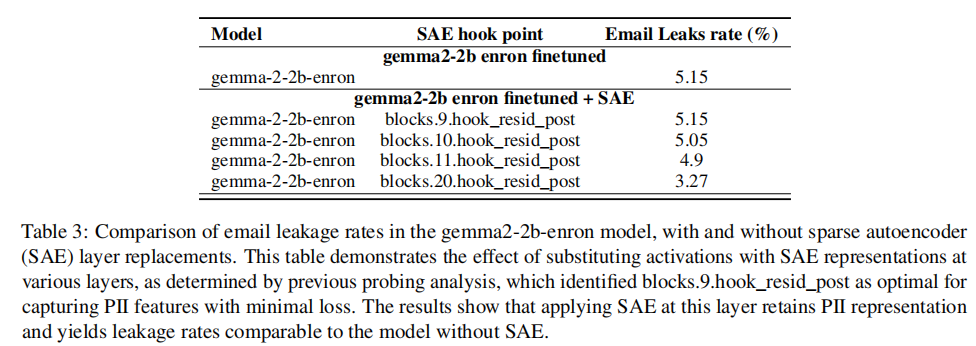
针对 Gemma2-2b 模型:给它的 26 层都装了探针,结果第 9 层的分类器准确率飙到 94.72%(比其他层最高高 0.3%)。而且把 SAE 装在第 9 层时,模型原始隐私泄露率(5.15%)完全没变化—— 说明这层确实精准捕捉了隐私特征,没误抓通用知识。目前实验里明确 "第 9 层最优" 的是Gemma2-2b 模型,不是所有模型都通用。
2. 🔍 SAE特征拆解
找到 Gemma2-2b 的第 9 层这个 "隐私仓库" 后,关键要把里面的隐私特征和通用知识拆分开 —— 这就靠稀疏自编码器(k-SAE)来实现。简单来说,就是把第 9 层输出的 "混合特征"转换为 "稀疏特征"—— 让每个特征只对应一个明确含义,这样后续删隐私特征时才不会误伤通用知识。
① 编码器 —— 把混合特征 "拆成零件"
公式:
-
: 定位层输出的激活值向量,即还没拆分的 "混合特征"。
-
和 : 是编码器的权重矩阵和"预编码偏置"。两者配合,先对原始激活值做线性变换,初步分开 "隐私信号" 和 "通用信号"。
-
: 稀疏性的核心,只保留线性变换后 "数值最大的 k 个特征"(论文里 设为 512),其他特征都设为 0。因为数值大的特征,往往是对应语义最明确的。
② 解码器 —— 确保 "拆完还能装回去"
光拆不行,还得保证拆完的特征能还原成原始格式,才不影响模型后续输出。 公式:
-
: 解码器的权重矩阵,能把稀疏特征 (拆好的零件)重新组合。
-
论文里用 "均方误差(MSE)" 衡量还原度,确保拆分过程没丢关键的通用知识 —— 这也是后续模型能保持 99.4% utility的关键。
③ 辅助损失 —— 避免 "零件生锈"
如果有些特征一直没被激活(叫 "死亡特征"),会影响拆分效果,所以加了个 "辅助损失"。 公式:
-
: 主损失(即 ),保证还原 accuracy。
-
: 专门针对 "长期没激活的特征"的辅助损失。其计算公式为 。这里的 是从非活跃单元中构建的辅助稀疏特征向量,而 是一个独立的辅助解码器权重矩阵。
-
: 小系数,控制辅助损失的影响。
最终,通过最小化这个总损失训练出的 k-SAE,能为后续的 "特征干预" 提供理想的 "隐私特征地图",实现 "只删隐私、不改智商" 的目标。
3. 🔍 精准干预
这一步是将找到的"隐私特征靶点"转化为可操作的隐私防护动作,设计了"特征消融"与"向量引导"两种定向方案。
方案一: 特征消融 (Feature Ablation) —— 直接 "切除" 隐私特征,简单高效
核心逻辑是定位并清零 k-SAE latent 层中 "与隐私强相关的活跃特征",从根源上移除隐私信息的编码载体。
-
筛选"高优先级隐私特征": 基于 Enron 数据集,提取序列中"邮箱首次出现至结束"的latent特征向量,对所有序列的 进行激活值聚合与排序,取 Top-k个单元作为 "高优先级隐私特征"。
-
定向消融: 在模型生成文本时,当文本流进入目标层并通过 k-SAE 生成 latent 特征 后,仅将筛选出的 "Top-k隐私特征单元" 的激活值设为 0。消融范围严格限定在 "生成阶段的最后一个 token"。
-
还原回原始嵌入空间: 消融后的 latent 特征通过 k-SAE 的解码器重建为原始激活值,再输入模型后续层。此时,由于隐私特征被清零,模型会自然避开隐私内容。
方案二: 向量引导 (Feature Vector Steering) —— "引导" 隐私特征偏离敏感方向,更灵活
核心逻辑是通过线性变换,将 "隐私特征向量" 向 "非隐私方向" 偏移,而非直接清零。
-
第一步:构建3类引导向量
-
Steering Probe (探针引导向量): 基于含隐私和无隐私的文本,训练一个二分类器。该分类器的参数归一化后得到引导向量 ,其方向即为 "隐私特征的主导方向",反向使用可引导特征向 "非隐私方向" 偏移。
-
Steering Top-k Probe (Top-k探针引导向量): 结合"特征消融"的筛选逻辑,仅基于Top-k核心隐私单元训练分类器来构建引导向量 ,干预范围更小。
-
Steering Mean-Diff (均值差引导向量): 计算PII文本与非PII文本的latent特征均值之差得到 。反向使用 即可引导特征向"非隐私方向"偏移。
-
-
第二步:定向偏移与嵌入空间还原
-
偏移强度控制: 在生成时,按公式 执行线性变换。 的取值需要平衡隐私与性能。例如,在Gemma2-2b模型中当 时可实现 0% 邮箱泄露率。
-
稀疏性保持: 偏移仅作用于 "活跃的 latent 单元",非活跃单元保持 0 值不变。
-
干预位置限定: 与特征消融一致,偏移仅针对 "生成阶段的最后一个 token",确保文本前半段的语义连贯性。
-
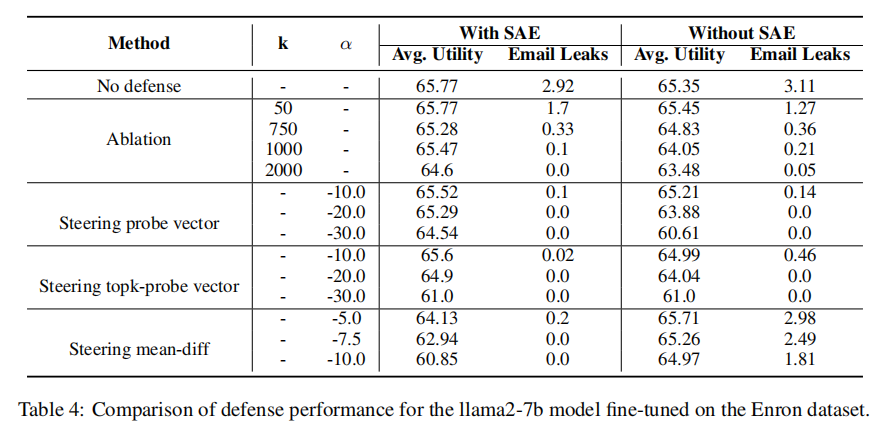
实验结果对比
-
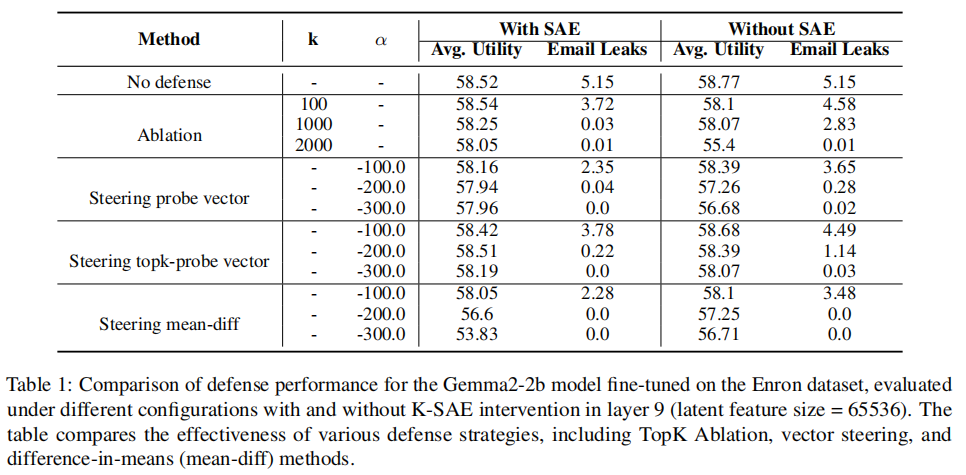
Steering Probe: 均衡性最优。当 时,实现 0% 邮箱泄露率,同时保留 65.29% 的通用准确率,几乎不影响模型正常使用。
-
Steering Top-k Probe: 隐私阻断更精准。当 时,泄露率已降至 0.02%,准确率高达 65.60%,是低强度偏移下性能最佳的方案。
-
Steering Mean-Diff: 隐私阻断门槛低。仅需 即可实现 0% 泄露率,是三种方法中最快达成零泄露的方案,但性能损耗较明显。
总结
当隐私泄露成为生成式模型难以回避的原罪,PrivacyScalpel 给出了一种"以内窥式可解释性为手术刀"的范式:通过层间探针完成隐私表征的定位,借助稀疏自编码器将高维激活解耦为单语义特征,再在潜在空间中对敏感子空间施行定向消融或向量偏移。整个过程无需触碰梯度噪声,也不牺牲通用表示,实现了"可控失忆"与"性能免疫"的平衡。
换言之,它将隐私保护从传统的"加噪-混淆"范式,推进到"定位-解构-干预"的精细操作时代:让隐私信号在激活谱上被看见,也被精准擦除;让安全不再是外部约束,而成为内部可解释的自然属性。
或许,未来的大模型不再需要"学会遗忘",而是天生就懂得——哪些特征该被点亮,哪些永远沉入稀疏的黑暗。
来源:IF 实验室

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)