打造真正的 Kubernetes Native GPU Cloud —— 英博云(ebcloud.com)架构实践与深度解析
在大模型与深度学习应用爆发的背景下,GPU 不再是实验室的加速卡,而是核心计算力。在这一趋势下,传统 GPU 云架构渐显短板:虚机绑定 GPU 粒度粗、资源浪费大与 Kubernetes 原生生态割裂弹性调度与混合负载调度能力不足为了让 GPU 资源真正成为云原生的平台级计算资源,我们在自主设计并落地了一套,本文将系统性地介绍其设计理念、核心组件与工程实现细节,帮助读者了解如何构建可观测、可调度、
在大模型与深度学习应用爆发的背景下,GPU 不再是实验室的加速卡,而是核心计算力。在这一趋势下,传统 GPU 云架构渐显短板:
-
虚机绑定 GPU 粒度粗、资源浪费大
-
与 Kubernetes 原生生态割裂
-
弹性调度与混合负载调度能力不足
为了让 GPU 资源真正成为云原生的平台级计算资源,我们在 英博云(ebcloud.com) 自主设计并落地了一套 Kubernetes Native GPU Cloud 架构,本文将系统性地介绍其设计理念、核心组件与工程实现细节,帮助读者了解如何构建可观测、可调度、可隔离、可扩展的 GPU 云服务。
🚀 背景与动机:为什么要做 Kubernetes Native GPU Cloud?
当前主流 GPU 云方案往往采用:
-
GPU 绑定到虚机(VM)
-
虚机作为最小资源单元
-
隔离依赖虚机边界
这种模式带来明显局限性:
| 问题 | 典型影响 |
|---|---|
| 粒度粗 | 推理任务无法高效共用资源 |
| GPU 片利用率低 | 导致成本高 |
| 隔离依赖虚机 | 启动慢、管理复杂 |
| 与 Kubernetes 融合度弱 | DevOps 自动化能力不足 |
相比之下,Kubernetes 本身具备:
-
声明式调度与弹性扩缩能力
-
原生支持容器生命周期管理
-
与 AI 上层生态(Kubeflow、MLFlow、KServe)天然契合
因此,我们追问一个核心问题:
GPU 是否能像 Pod/Service 一样,被 Kubernetes 原生调度与管理?
答案是肯定的 —— 只要设计得足够原生与高效。
🎯 英博云(ebcloud.com)目标定位
英博云的目标是:
构建一个真正 Native 的 GPU 云平台,让 GPU 成为 Kubernetes 的一等资源,服务 AI & 大模型计算场景;同时保障多租户隔离、弹性扩缩、资源高效利用。
与传统 GPU 云不同:
| 特性 | 传统 GPU 云 | 英博云(ebcloud.com) |
|---|---|---|
| GPU 调度单元 | 虚机粒度 | Pod 级别 |
| 多租户隔离 | VM 隔离 | Namespace + 控制面隔离 |
| 弹性扩缩 | 依赖 VM | Kubernetes 原生 HPA / VPA / Queue |
| 原生生态 | 弱 | 强(Kubeflow / KServe) |
| 资源利用率 | 低 | 高 |
📍 核心架构:控制面与算力面解耦
英博云采用 控制面与计算面分离 的架构,并在此基础上打造多租户与 GPU 原生调度能力:
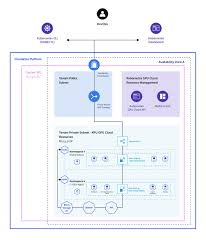
🧠 1. 控制面集群
控制面负责:
-
接入认证与统一入口(OAuth / SSO)
-
租户管理与权限隔离
-
API 控制面托管
-
资源配额与计费策略管理
-
全局调度策略下发
特点:
-
不承载重计算
-
高可用、稳定优先
-
类似公有云的 “Region 控制面”
🚀 2. 计算集群(GPU 负载计算面)
计算集群是真正执行训练/推理任务的地方:
-
GPU 节点池
-
CPU 节点池
-
RDMA / RoCE / 高速网络互联
-
高性能存储挂载支持
特点:
-
高性能优先
-
实现 GPU 资源的细粒度调度
-
与 Kubernetes 调度器深度集成
🌐 3. 网络 & 存储平面
为了支持大模型训练数据密集的访问模式,英博云构建了:
-
统一的 VPC 网络
-
支持 ENI / CNI 插件接入
-
块存储 / 对象存储 / 分布式文件系统
确保:
-
Pod 与 VM 均可访问 VPC
-
跨 AZ / 跨集群互联
-
数据吞吐与低延迟
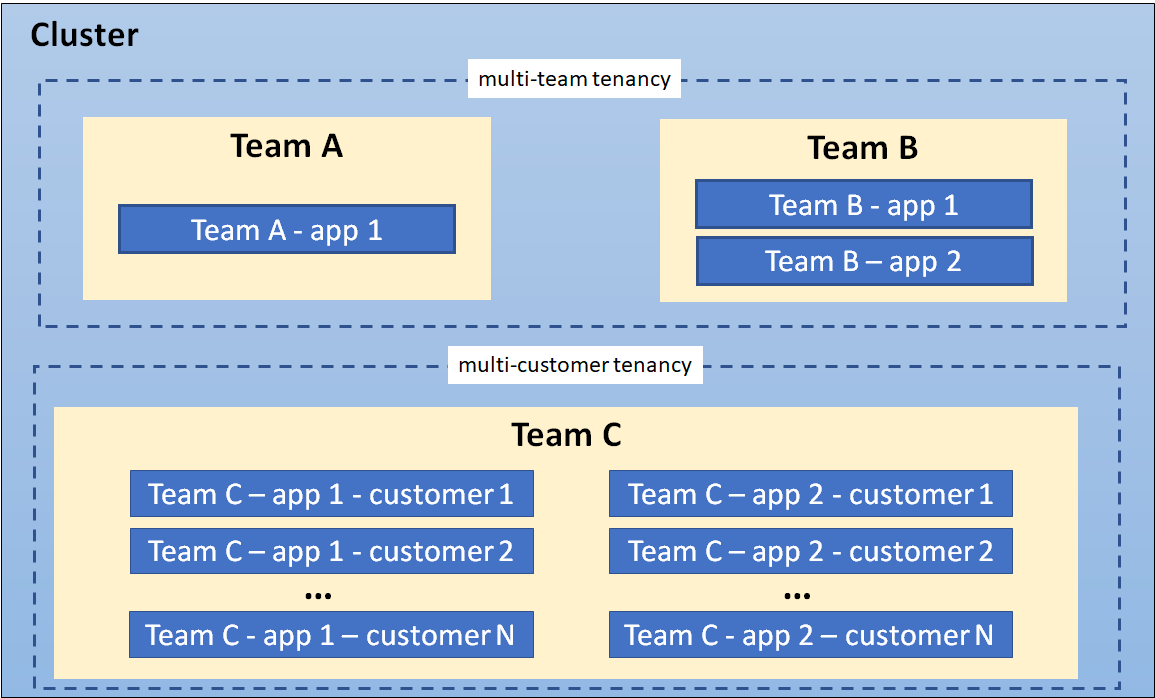
🛡️ 多租户隔离:不是 Namespace 就够了
在 GPU 多租户场景下,单一 Namespace 隔离显然不足以满足:
-
网络隔离
-
GPU 权限隔离
-
API 访问控制
-
计费与审计分离
英博云采用:
-
每个租户一个逻辑控制面
-
基于 RBAC + OPA/Gatekeeper 策略
-
Quota & LimitRange 定制 GPU 配额
这样每个租户拥有:
一个几乎完整独立的 Kubernetes 体验
同时平台侧统一托管、更新与配置策略。
🧠 GPU 原生调度:从设备到 Pod
在英博云,GPU 不再是 绑在虚机上孤立的资源,而是:
✔ 在 Kubernetes 中被识别为 可调度的本地资源
✔ 与 CPU / 内存 / 网络同等对待
✔ 支持:
-
GPU Sharing
-
GPU Preemption
-
GPU Queue 调度(支持训练 / 推理优先级)
通过自定义调度器或调度扩展:
GPU 调度成为 Kubernetes 调度策略的一等公民
🏗️ Serverless GPU:自动弹性更进一步
针对推理与异步小任务场景,引入 Serverless GPU 调度:
-
使用 Job Queue + 弹性 Pod Controller
-
按需扩缩 GPU Pod
-
任务完成自动释放资源
-
与 DevOps Workflow(CI/CD)集成
带来了:
-
更低的使用成本
-
更短的启动延迟
-
更佳的资源利用率
🔍 可观测性与工程实践
在英博云我们同时构建了完整的可观测体系:
📌 监控
Prometheus + Grafana:GPU 利用率、Pod 调度状态、事件告警
📌 日志聚合
ELK/EFK 或 Loki:统一日志查询与审计
📌 指标分析
结合 Metrics Server + Custom Metrics:GPU Utilization、Queue Length、延迟曲线
📌 计费埋点
任务级、租户级资源使用记录 → 精细计费
📈 小结:英博云 让 GPU 云更“云原生”
通过几年的设计与实践,英博云(ebcloud.com)实现了:
✅ Kubernetes Native GPU 调度与管理
✅ 多租户控制面隔离 + 自助式租户体验
✅ 弹性 Serverless GPU 调度
✅ 高效的资源利用与可观测体系
✅ 与 AI 上层生态深度融合
如果你正在构建 下一代 AI 计算平台 / GPU 云服务 / 多租户原生调度系统,欢迎在评论区交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)