AI大模型:基于python热门旅游景点数据分析系统+可视化 +Flask框架 穷游网数据 requests爬虫 Hadoop✅
AI大模型:基于python热门旅游景点数据分析系统+可视化 +Flask框架 穷游网数据 requests爬虫 Hadoop✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、穷游网数据、requests爬虫、Echarts可视化
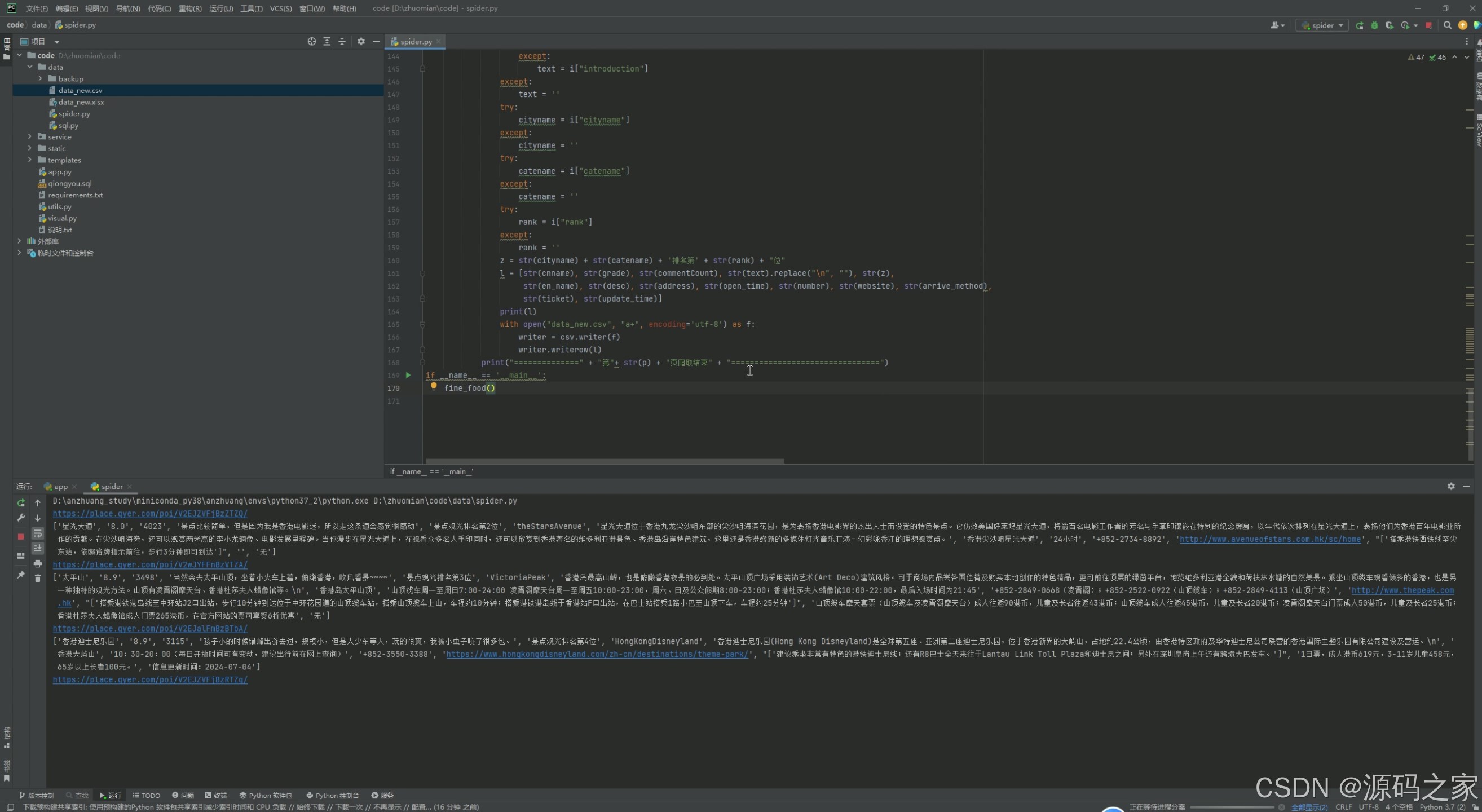
- 数据采集
功能描述:通过爬虫技术从穷游网等旅游相关网站采集景点的点评、评分、门票信息、到达方式、开放时间等数据。
技术实现:使用Python语言和requests库编写爬虫程序,模拟浏览器行为访问目标网站,提取所需数据并存储到本地数据库或文件中。
用户交互:管理员可以通过后台界面启动数据采集任务,系统会自动运行爬虫程序,并将采集到的数据存储起来,供后续分析使用。 - 景点评点分析
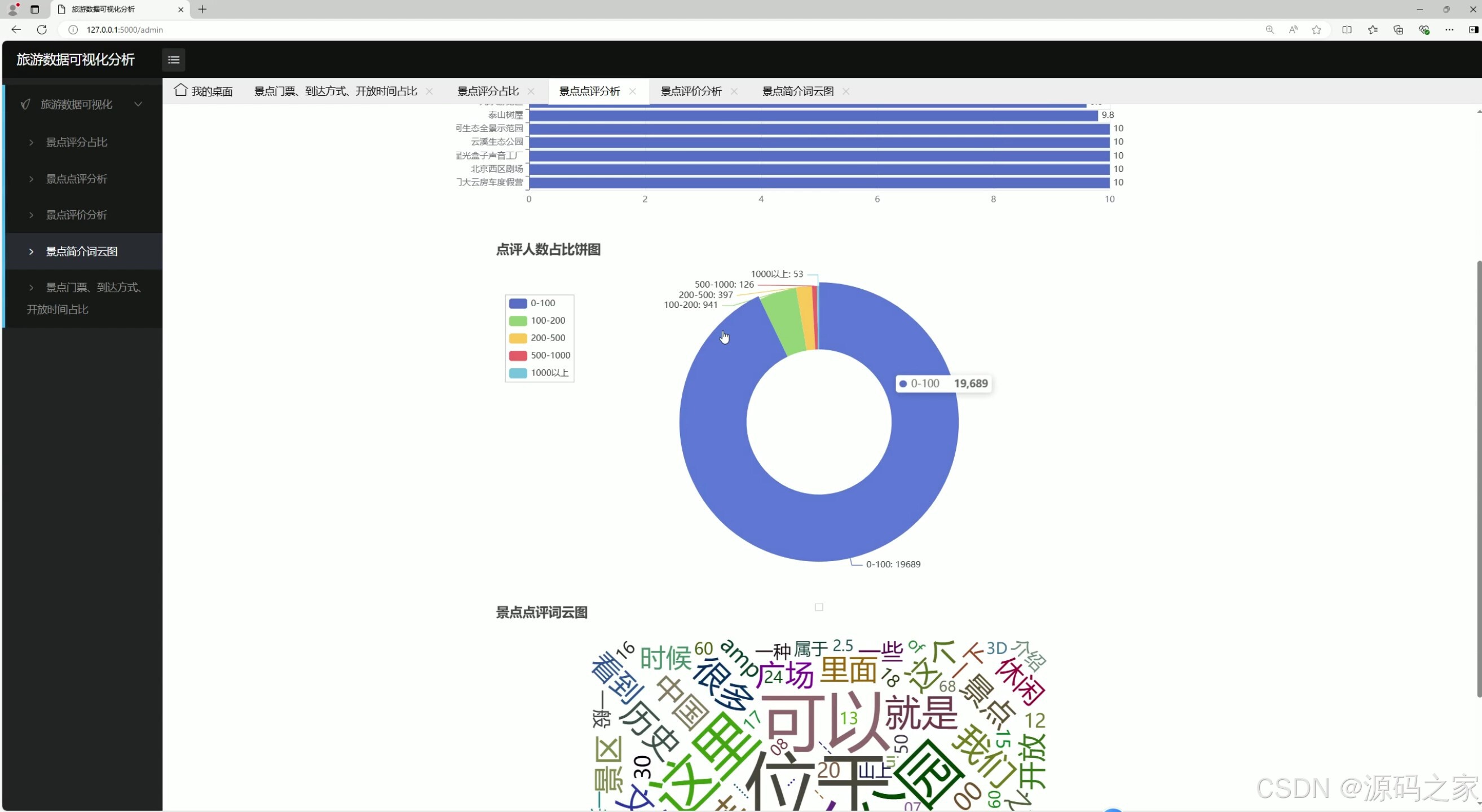
功能描述:对采集到的景点点评数据进行情感分析和主题提取,了解游客对景点的整体评价和关注点。
技术实现:使用自然语言处理技术,结合文本分析算法,对点评内容进行情感分类(正面、负面、中性),并提取关键词和主题。
用户交互:用户可以通过前端界面查看不同景点的点评情感分布,以及游客关注的热门话题,帮助用户快速了解景点的优缺点。 - 景点评价分析
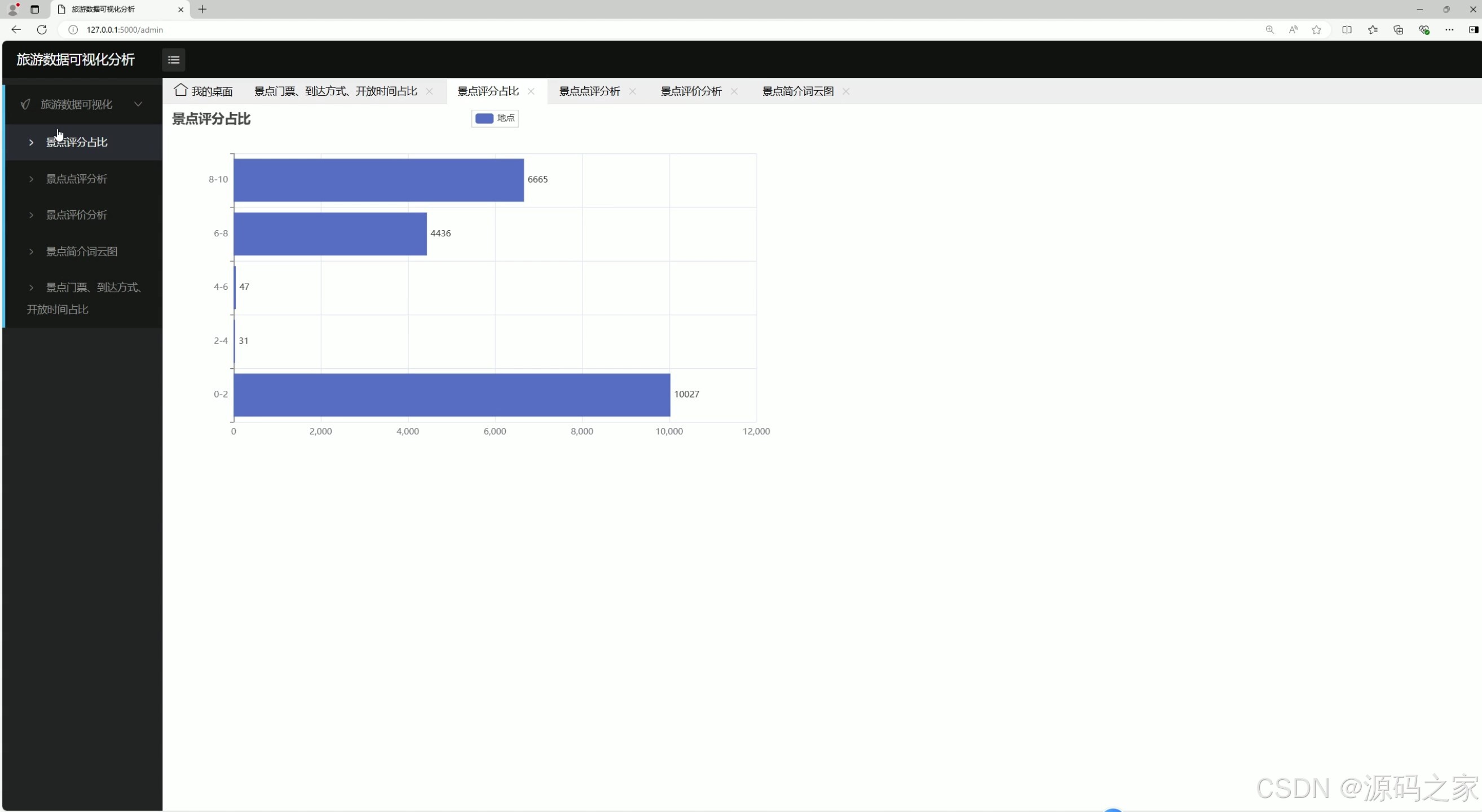
功能描述:对景点的总体评价进行量化分析,展示景点的综合评分、好评率、差评率等指标。
技术实现:通过统计分析方法,计算每个景点的评分分布和好评率,生成直观的图表展示结果。
用户交互:用户可以通过界面查看各景点的评价统计图表,快速对比不同景点的受欢迎程度。 - 景点评分分析
功能描述:分析景点评分随时间的变化趋势,了解景点在不同时间段的受欢迎程度。
技术实现:使用时间序列分析方法,对景点评分数据进行趋势分析,生成折线图展示评分变化趋势。
用户交互:用户可以选择特定景点,查看其评分随时间的变化曲线,帮助用户选择最佳旅游时间。 - 景点词云图分析
功能描述:通过词云图直观展示游客对景点的高频词汇,突出游客关注的热点和关键词。
技术实现:对点评文本进行分词处理,统计词频并生成词云图。
用户交互:用户可以通过界面查看景点的词云图,快速了解游客对景点的常见评价和关注点。 - 门票、到达方式、开放时间占比分析
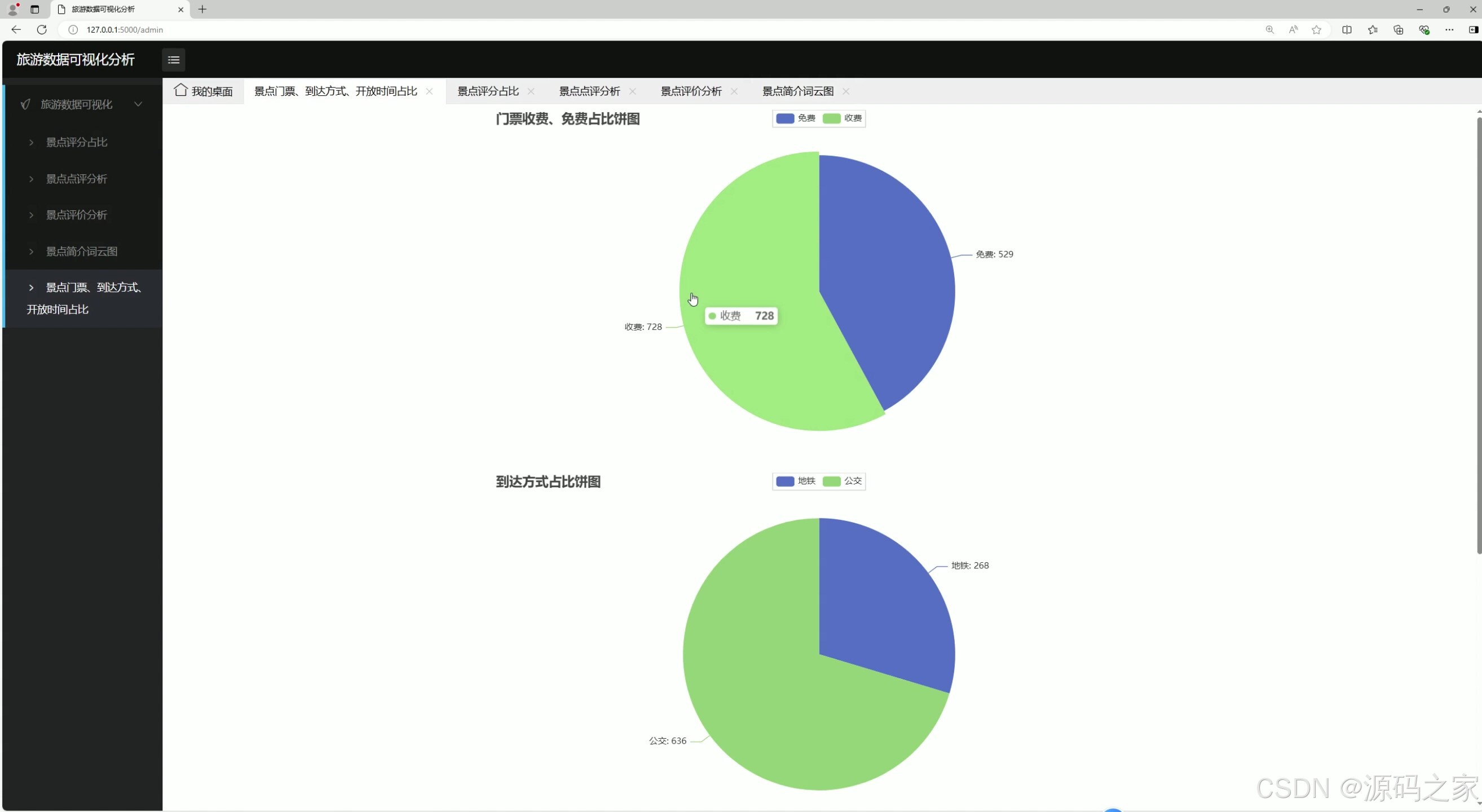
功能描述:分析景点门票价格、到达方式和开放时间的分布情况,为游客提供实用信息。
技术实现:对采集到的门票价格、到达方式和开放时间数据进行分类统计,生成饼图或柱状图展示占比情况。
用户交互:用户可以通过界面查看门票价格分布、不同到达方式的占比以及开放时间的统计信息,帮助游客提前规划行程。 - 注册登录
功能描述:提供用户注册和登录功能,方便用户保存个性化设置和查看历史记录。
技术实现:使用Flask框架实现用户认证功能,支持用户注册、登录、密码找回等操作。
用户交互:用户可以通过注册页面创建账号,通过登录页面进入系统,系统会根据用户权限提供相应的功能和服务。
2、项目界面
(1)景点点评分析
(2)景点评价分析
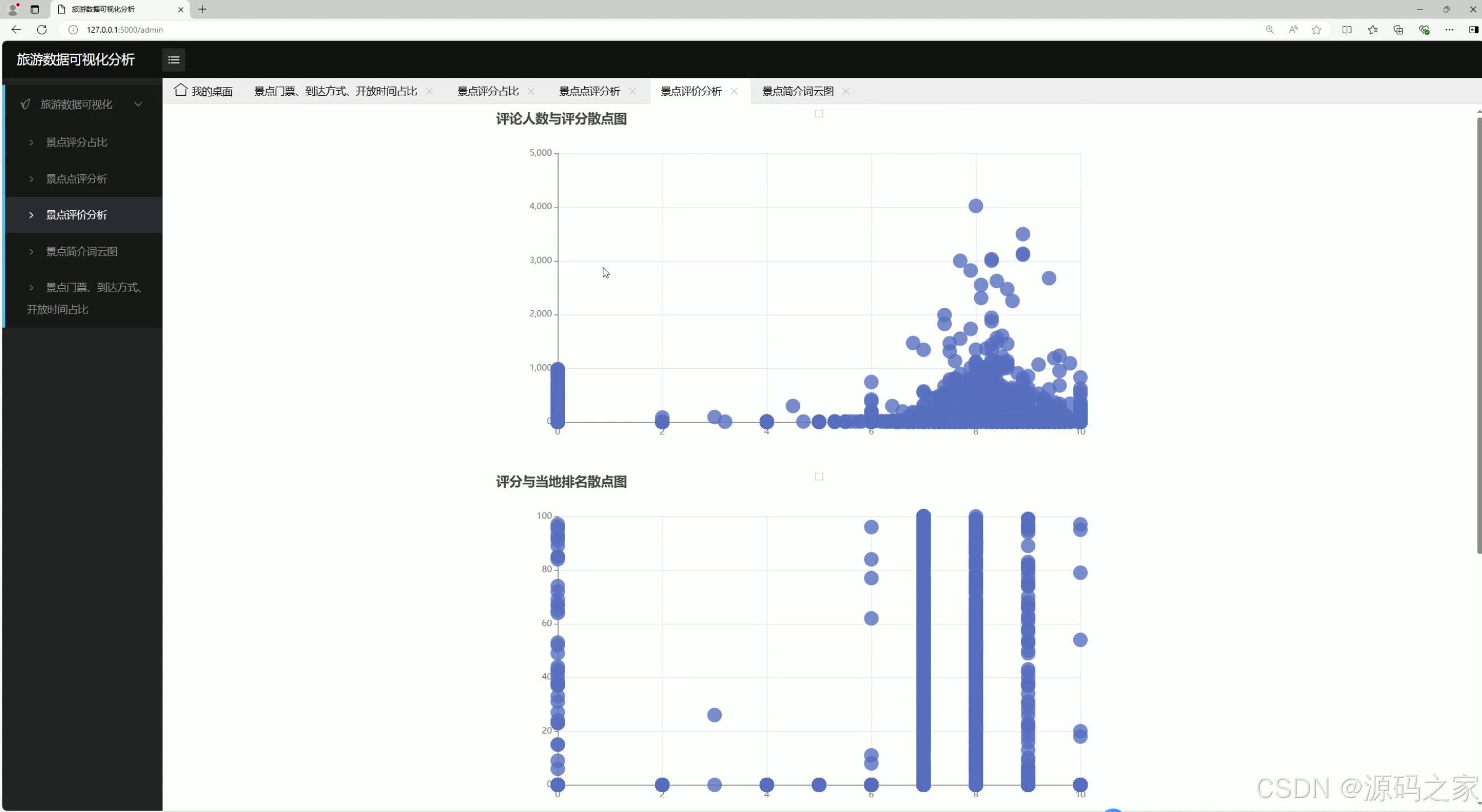
(3)景点评分分析
(4)景点词云图分析
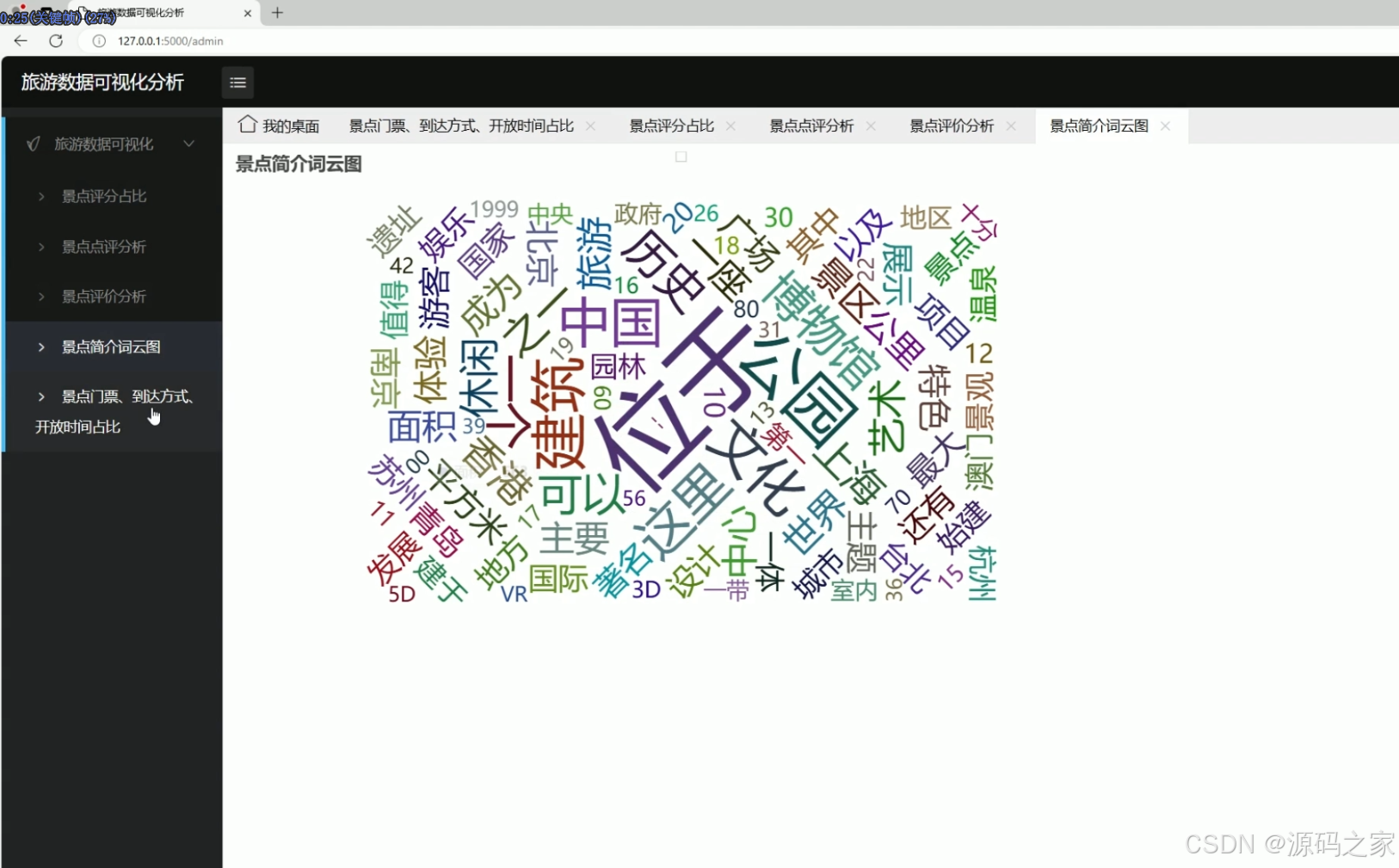
(5)门票、到达方式、开放时间占比分析
(6)注册登录
(7)数据采集
3、项目说明
- 数据采集
功能描述:通过爬虫技术从穷游网等旅游相关网站采集景点的点评、评分、门票信息、到达方式、开放时间等数据。
技术实现:使用Python语言和requests库编写爬虫程序,模拟浏览器行为访问目标网站,提取所需数据并存储到本地数据库或文件中。
用户交互:管理员可以通过后台界面启动数据采集任务,系统会自动运行爬虫程序,并将采集到的数据存储起来,供后续分析使用。 - 景点评点分析
功能描述:对采集到的景点点评数据进行情感分析和主题提取,了解游客对景点的整体评价和关注点。
技术实现:使用自然语言处理技术,结合文本分析算法,对点评内容进行情感分类(正面、负面、中性),并提取关键词和主题。
用户交互:用户可以通过前端界面查看不同景点的点评情感分布,以及游客关注的热门话题,帮助用户快速了解景点的优缺点。 - 景点评价分析
功能描述:对景点的总体评价进行量化分析,展示景点的综合评分、好评率、差评率等指标。
技术实现:通过统计分析方法,计算每个景点的评分分布和好评率,生成直观的图表展示结果。
用户交互:用户可以通过界面查看各景点的评价统计图表,快速对比不同景点的受欢迎程度。 - 景点评分分析
功能描述:分析景点评分随时间的变化趋势,了解景点在不同时间段的受欢迎程度。
技术实现:使用时间序列分析方法,对景点评分数据进行趋势分析,生成折线图展示评分变化趋势。
用户交互:用户可以选择特定景点,查看其评分随时间的变化曲线,帮助用户选择最佳旅游时间。 - 景点词云图分析
功能描述:通过词云图直观展示游客对景点的高频词汇,突出游客关注的热点和关键词。
技术实现:对点评文本进行分词处理,统计词频并生成词云图。
用户交互:用户可以通过界面查看景点的词云图,快速了解游客对景点的常见评价和关注点。 - 门票、到达方式、开放时间占比分析
功能描述:分析景点门票价格、到达方式和开放时间的分布情况,为游客提供实用信息。
技术实现:对采集到的门票价格、到达方式和开放时间数据进行分类统计,生成饼图或柱状图展示占比情况。
用户交互:用户可以通过界面查看门票价格分布、不同到达方式的占比以及开放时间的统计信息,帮助游客提前规划行程。 - 注册登录
功能描述:提供用户注册和登录功能,方便用户保存个性化设置和查看历史记录。
技术实现:使用Flask框架实现用户认证功能,支持用户注册、登录、密码找回等操作。
用户交互:用户可以通过注册页面创建账号,通过登录页面进入系统,系统会根据用户权限提供相应的功能和服务。
4、核心代码
from sqlalchemy import create_engine
import pandas as pd
from pyecharts.charts import Bar, Pie, WordCloud, Page, Scatter
from pyecharts import options as opts
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/qiongyou')
sql1 = "select * from data"
df1 = pd.read_sql_query(sql1, engine)
def bar():
count_dict = {"0-2": 0, "2-4": 0, "4-6": 0, "6-8": 0, "8-10": 0}
df_count = df1[["评分", "index"]]
count = []
for index, row in df_count.iterrows():
count.append(row["评分"])
for item in count:
if item < 2:
count_dict["0-2"] = count_dict["0-2"] + 1
elif 2 <= item < 4:
count_dict["2-4"] = count_dict["2-4"] + 1
elif 4 <= item < 6:
count_dict["4-6"] = count_dict["4-6"] + 1
elif 6 <= item < 8:
count_dict["6-8"] = count_dict["6-8"] + 1
else:
count_dict["8-10"] = count_dict["8-10"] + 1
x_data = list(count_dict.keys())
y_data = list(count_dict.values())
c = (
Bar()
.add_xaxis(x_data)
.add_yaxis("地点", y_data)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="景点评分占比"))
.render("templates/bar.html")
)
def pie():
df_ticket = df1["门票"]
data_dict = {"免费": 0, "收费": 0}
for item in df_ticket:
if item != None:
if "免费" in item:
data_dict["免费"] += 1
else:
data_dict["收费"] += 1
x_data = list(data_dict.keys())
y_data = list(data_dict.values())
c = (
Pie()
.add("", [list(z) for z in zip(x_data, y_data)])
.set_global_opts(title_opts=opts.TitleOpts(title="门票收费、免费占比饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie.html")
)
return c
def pie1():
data_dict = {"地铁": 0, "公交": 0, }
df_arr = df1["到达方式"]
for item in df_arr:
if item != None:
if "铁线" in item or "线" in item or "地铁" in item or "线" in item:
data_dict["公交"] += 1
elif "巴士" not in item and "公交" not in item and "大巴" not in item:
data_dict["地铁"] += 1
x_data = list(data_dict.keys())
y_data = list(data_dict.values())
c = (
Pie()
.add("", [list(z) for z in zip(x_data, y_data)])
.set_global_opts(title_opts=opts.TitleOpts(title="到达方式占比饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie.html")
)
return c
def pie3():
df_open = df1["开放时间"]
data_dict = {"全天开放": 0, "工作日开放": 0, "周末开放": 0}
for item in df_open:
if item != None:
if "24" in item or "全天" in item:
data_dict["全天开放"] += 1
elif "六" in item or "日" in item:
data_dict["周末开放"] += 1
else:
data_dict["工作日开放"] += 1
x_data = list(data_dict.keys())
y_data = list(data_dict.values())
c = (
Pie()
.add("", [list(z) for z in zip(x_data, y_data)])
.set_global_opts(title_opts=opts.TitleOpts(title="开放时间占比饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie.html")
)
return c
def page():
page = Page(layout=Page.SimplePageLayout)
page.add(
pie(),
pie1(),
pie3(),
)
page.render("templates/page.html")
def bar1() -> Bar:
df_rate = df1[["景点中文名", "评分"]]
df_rate = df_rate.sort_values(by="评分", ascending=False)
rate = []
for index, row in df_rate.iterrows():
rate.append([row["景点中文名"], float(row["评分"])])
rate.sort(key=lambda ele: ele[1], reverse=True)
x_data = []
y_data = []
for item in rate:
x_data.append(item[0])
y_data.append(item[1])
c = (
Bar(init_opts=opts.InitOpts(width="1000px"))
.add_xaxis(x_data[:3000:150])
.add_yaxis("地点", y_data[:3000:150])
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="景点评分排名"))
# .render("bar_reversal_axis.html")
)
return c
def pie2() -> Pie:
count_dict = {"0-100": 0, "100-200": 0, "200-500": 0, "500-1000": 0, "1000以上": 0}
df_count = df1[["评价人数", "index"]]
count = []
for index, row in df_count.iterrows():
count.append(row["评价人数"])
for item in count:
item = int(item)
if item < 100:
count_dict["0-100"] = count_dict["0-100"] + 1
elif 100 <= item < 200:
count_dict["100-200"] = count_dict["100-200"] + 1
elif 200 <= item < 500:
count_dict["200-500"] = count_dict["200-500"] + 1
elif 500 <= item < 1000:
count_dict["500-1000"] = count_dict["500-1000"] + 1
else:
count_dict["1000以上"] = count_dict["1000以上"] + 1
x1_data = list(count_dict.keys())
y1_data = list(count_dict.values())
c = (
Pie()
.add(
"",
[list(z) for z in zip(x1_data, y1_data)],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="点评人数占比饼图"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_radius.html")
)
return c
def wordCloud1() -> WordCloud:
df_commend = df1[["首页评价", "index"]]
commend = []
for index, row in df_commend.iterrows():
if row["首页评价"] != None:
commend.append(str(row["首页评价"]))
import jieba
dict = {}
for item in commend:
wordlist = jieba.cut(item)
for key in wordlist:
dict[str(key)] = dict.get(str(key), 0) + 1
words = list(dict.keys())
counts = list(dict.values())
data = []
for i in range(len(words)):
if len(words[i]) >= 2:
data.append((words[i], counts[i],))
else:
pass
c = (
WordCloud()
.add(
"",
data,
word_size_range=[20, 100],
textstyle_opts=opts.TextStyleOpts(font_family="cursive"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="景点点评词云图"))
# .render("评论词云图.html")
)
return c
def page1():
page = Page(layout=Page.SimplePageLayout)
page.add(
bar1(),
pie2(),
wordCloud1()
)
page.render("templates/page1.html")
def wordCloud2():
df_commend = df1[["景点简介", "index"]]
commend = []
for index, row in df_commend.iterrows():
if row["景点简介"] != None:
commend.append(str(row["景点简介"]))
import jieba
dict = {}
for item in commend:
wordlist = jieba.cut(item)
for key in wordlist:
dict[str(key)] = dict.get(str(key), 0) + 1
words = list(dict.keys())
counts = list(dict.values())
data = []
for i in range(len(words)):
if len(words[i]) >= 2:
data.append((words[i], counts[i],))
else:
pass
c = (
WordCloud()
.add(
"",
data,
word_size_range=[20, 100],
textstyle_opts=opts.TextStyleOpts(font_family="cursive"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="景点简介词云图"))
.render("templates/景点简介词云图.html")
)
return c
def scatter1():
df2 = df1[["评分", "评价人数"]]
data = []
for index, row in df2.iterrows():
data.append([row["评分"], row["评价人数"]])
data.sort(key=lambda x: x[0])
x_data = [d[0] for d in data]
y_data = [d[1] for d in data]
c = (
Scatter()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="",
y_axis=y_data,
symbol_size=20,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
title_opts=opts.TitleOpts(title="评论人数与评分散点图"),
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts(is_show=True)
),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
tooltip_opts=opts.TooltipOpts(is_show=False),
)
# .render("scatter.html")
)
return c
def scatter2():
df2 = df1[["评分", "当地景点排名"]]
data = []
for index, row in df2.iterrows():
data.append([row["评分"], row["当地景点排名"].split("第")[1].replace("位", "")])
data.sort(key=lambda x: x[0])
x_data = [int(d[0]) for d in data]
y_data = [int(d[1]) for d in data]
c = (
Scatter()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="",
y_axis=y_data,
symbol_size=20,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
title_opts=opts.TitleOpts(title="评分与当地排名散点图"),
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts(is_show=True)
),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
tooltip_opts=opts.TooltipOpts(is_show=False),
)
# .render("scatter.html")
)
return c
def scatter3():
df2 = df1[["评价人数", "当地景点排名"]]
data = []
for index, row in df2.iterrows():
data.append([row["评价人数"], row["当地景点排名"].split("第")[1].replace("位", "")])
data.sort(key=lambda x: x[0])
x_data = [int(d[1]) for d in data]
y_data = [int(d[0]) for d in data]
c = (
Scatter()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="",
y_axis=y_data,
symbol_size=20,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
title_opts=opts.TitleOpts(title="评价人数与当地排名散点图"),
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts(is_show=True)
),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
tooltip_opts=opts.TooltipOpts(is_show=False),
)
# .render("scatter.html")
)
return c
def page2():
page = Page(layout=Page.SimplePageLayout)
page.add(
scatter1(),
scatter2(),
scatter3(),
)
page.render("templates/page2.html")
bar()
page()
page1()
wordCloud2()
page2()
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式

🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)