我花1小时,用AI复现了中金的“动量因子”,结果有点意外……
目录
第二组:"反转组"(小市值 + 高波动 + 低流动性 + 反向动量)
写在前面
大家好,我是Browei(alpha版)
今天我要分享一个量化新人最关心的问题:如何从零开始,快速构建有效的量化因子?
相信很多想学量化的朋友,都有过类似的经历:看了一篇研报,感觉茅塞顿开,恨不得马上把它变成代码,在市场上赚到钱。
我也不例外。最近,我认真读了《中金公司:关于动量,你所希望了解的那些事》。里面有个核心观点特别吸引我:
动量效应,在大市值、低波动、高价值的股票里更明显;而反转效应(涨多了就跌),则在小市值、高波动、低流动性的股票里更显著。
听起来逻辑很顺,对吧?大机构抱团的票容易形成趋势,而小票容易情绪过热然后崩盘。
那么,这个结论到底对不对?具体怎么实现?
我决定动手验证一下。
我用 PandaAI平台,花了大概1小时,把这篇研报的核心思路复现了一遍。过程比想象中简单,但结果……却和我的预想有些出入,下面我就把每一步的操作和思考分享出来。
网站扔这里了:https://www.pandaai.online/
第一步:构建因子
在PandaAI中,构建因子最简单的方式就是使用AI助手和Python因子模板。平台已经把复杂的回测框架封装好,我们只需要关注因子逻辑本身。
一、市值因子
我的操作步骤:
-
在PandaAI助手中选择"Python因子模板"
-
设置回测参数:
-
回测区间:5年
-
调仓周期:周度调仓
-
股票池:全A股
-
-
在因子方向中选择"负向"(因为我们测试小市值策略)
-
平台自动生成以下代码:
class MarketCapFactor(Factor):
def calculate(self, factors):
#方法1:直接使用系统预计算的市值
market_cap = factors['market_cap']
#通常会对市值取对数处理
log_market_cap = L0G(market_cap)
return RANK(log_market_cap)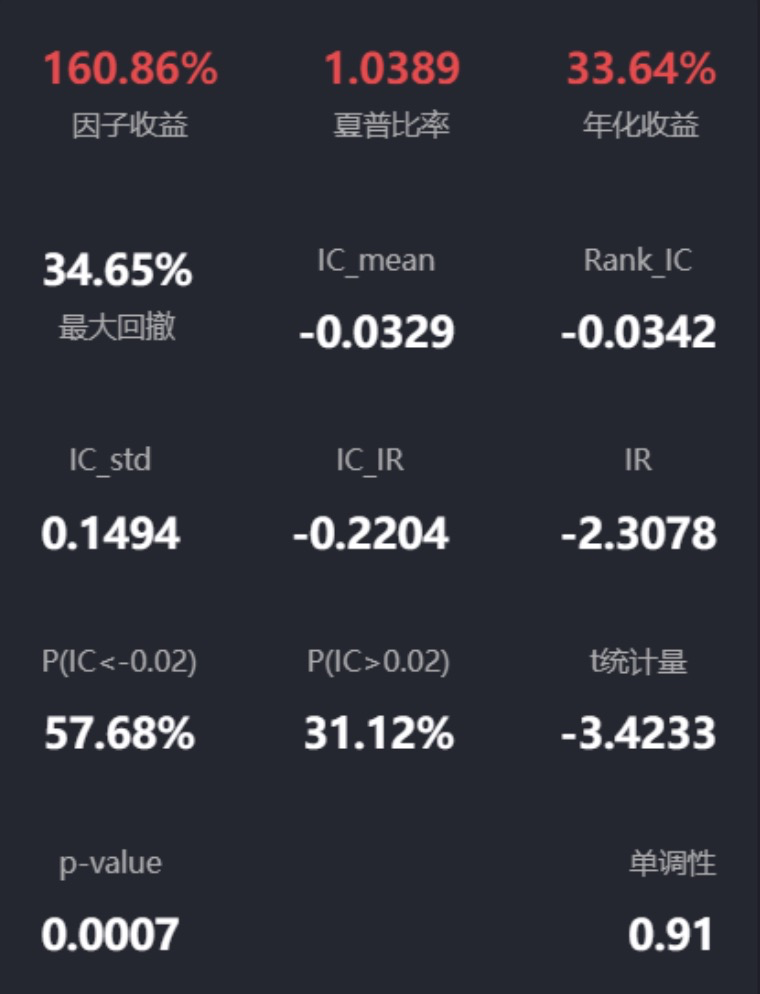
回测结果惊喜:
-
IC绝对值 > 0.03,证明有预测能力
-
但IC标准差较大,说明稳定性还需要提升
-
结论: 单纯的小市值在A股还能用,但不是"圣杯"
二、波动因子:控制风险的关键一步
研报强调要在"低波动"股票中寻找动量。那如何量化"波动"?
我的构建逻辑:
-
波动性越大 → 价格越不稳定 → 风险越高
-
波动性越小 → 价格走势平稳 → 风险较低
-
衡量方法: 过去20个交易日日收益率的标准差
代码如下:
class VolatilityFactor(Factor):
def calculate(self, factors):close = factors['close']
#计算每日收益率
daily_returns = RETURNS(close, period=1)
#计算20日滚动标准差
volatility = STDDEV(daily_returns, window=20)
#对波动率进行横截面排名
return RANK(volatility)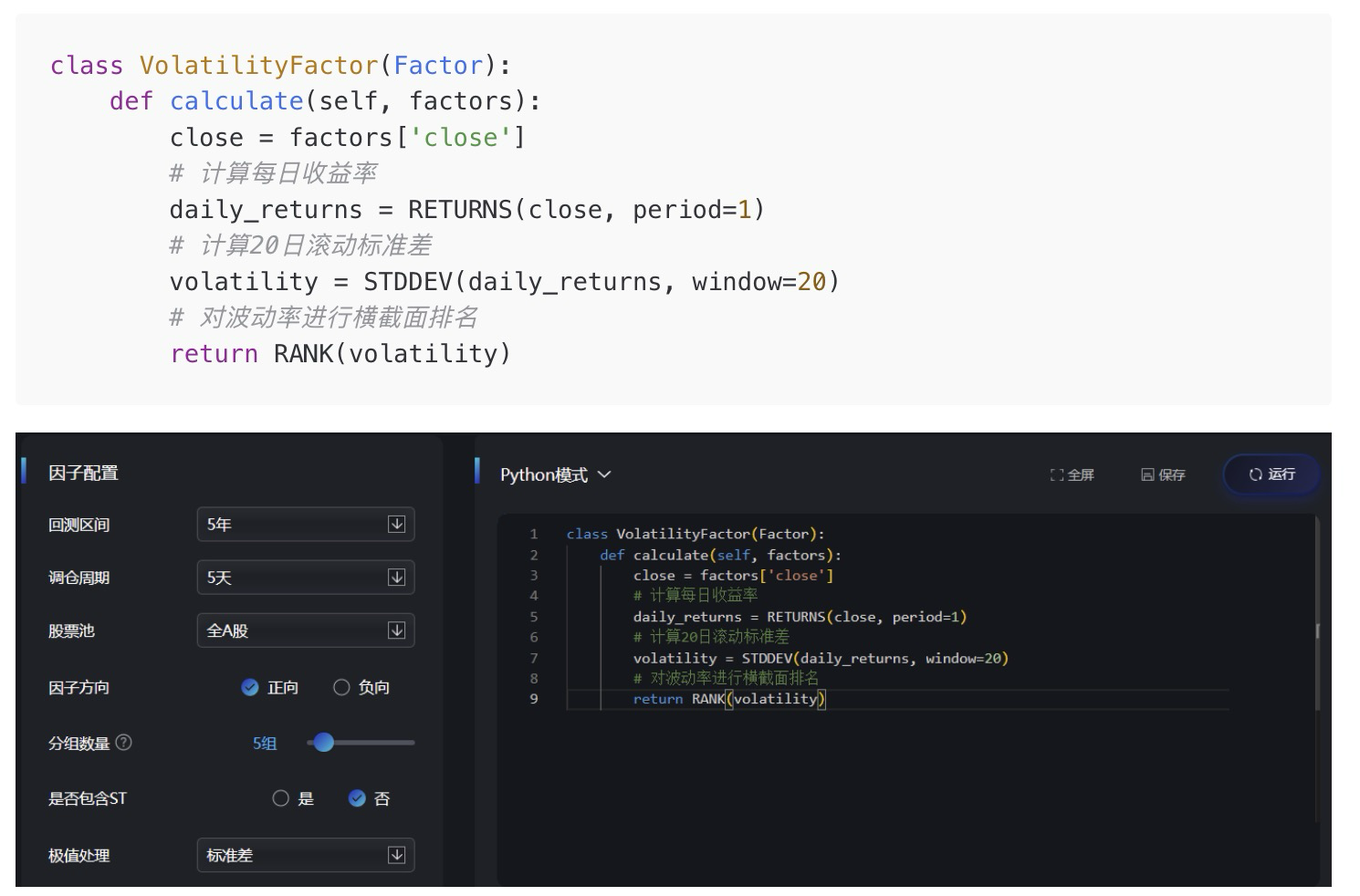
-
初次回测显示这是负向因子(高波动股票未来表现更差)
-
这很符合直觉:在A股,暴涨的股票往往随后暴跌
-
将因子方向调整为"负向"后,结果符合预期
三、流动性因子("低流动性"股票反转效应更明显)
我选择了最直接的代理指标:换手率
-
逻辑:换手率越高 → 流动性越好 → 交易成本越低
-
反之:换手率低 → 买卖困难 → 价格冲击大
class TurnoverLiquidityFactor(Factor):
def calculate(self, factors):
turnover = factors['turnover']
#换手率#计算换手率指标-使用过去20日的平均换手率
avg_turnover = TS_MEAN(turnover, window=20)
#进行横截面排序
return RANK(avg_turnover)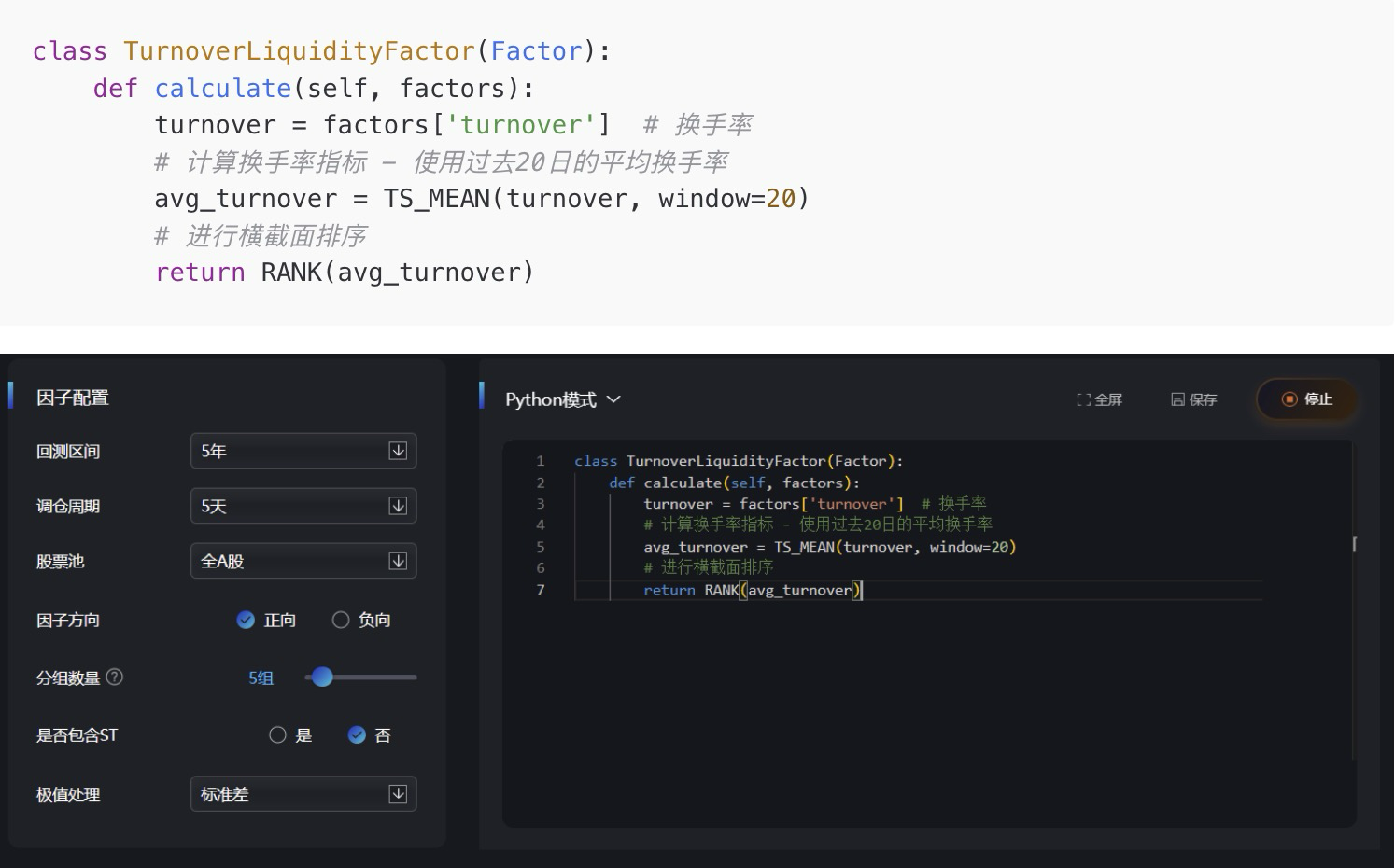
-
初次回测:该因子为强烈的负向指标
-
这反映了A股一个残酷现实:过度交易的散户往往亏损
-
反向测试后(即做空高换手率股票),效果明显改善
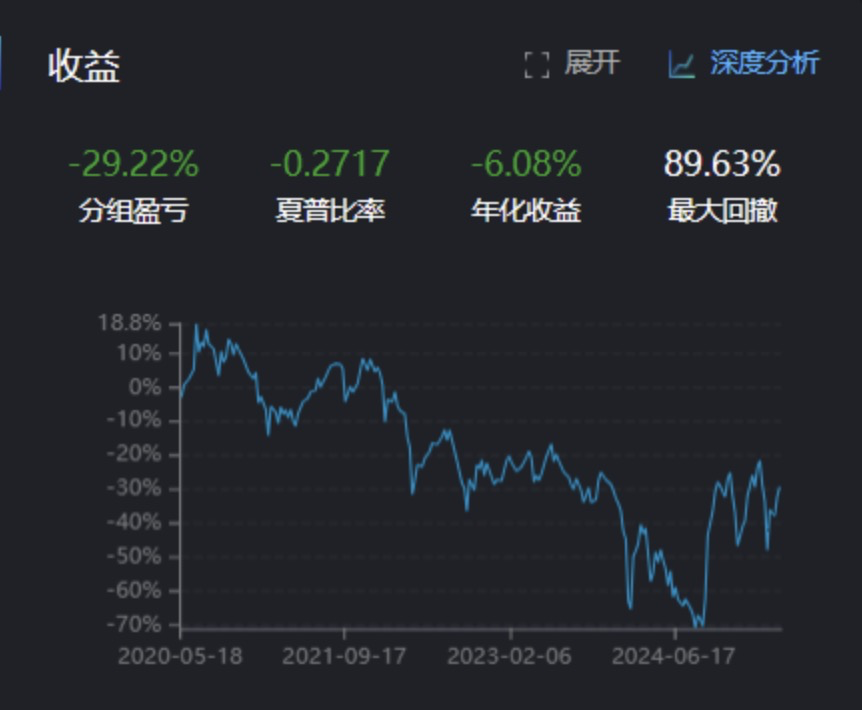
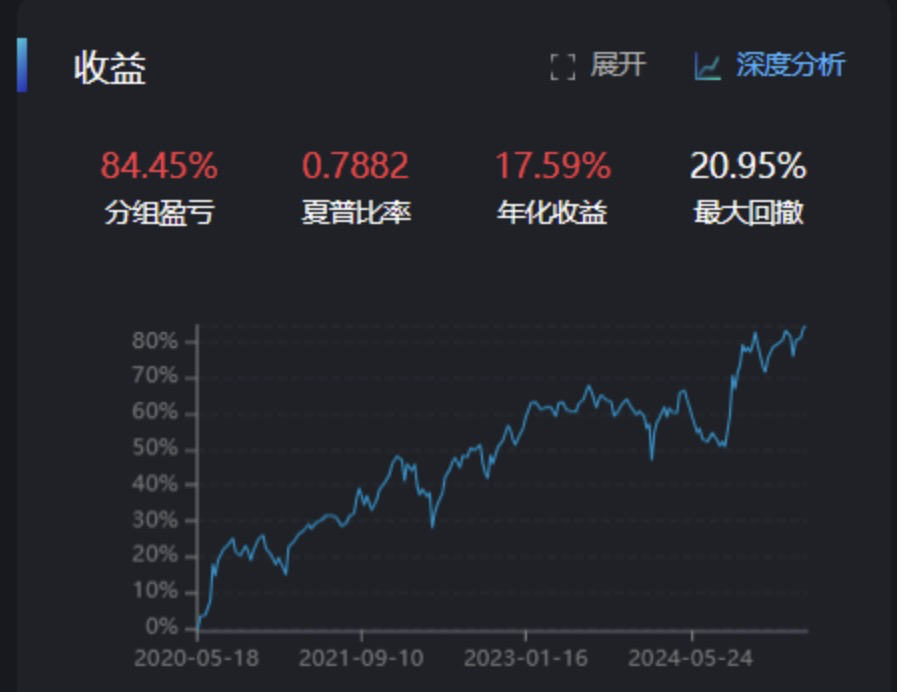
第二步:研报思路验证- "分域测试"
有了这三个基础因子,我按照研报的核心思路开始验证。
研报的核心观点:
"动量特征在高机构覆盖、大市值、低波动、高价值的股票池中更明显;而反转效果在低覆盖、小市值、高波动、低流动性、低价值的股票池内更为显著。"
我简化的测试方案:
第一组:"动量组"(大市值 + 低波动 + 正向动量)
-
预期: 在沪深300中应获得正向动量收益
class CompositeFactor(Factor):
def calculate(self, factors):
close = factors['close']
market_cap = factors['market_cap']
#1.大市值因子(直接使用市值)
size_factor = RANK(market_cap)
#2.低波动因子(波动率排名取反)
daily_returns = RETURNS(close, period=1)
volatility = STDDEV(daily_returns, window=20)
low_vol_factor= -RANK(volatility) #取负值表示低波动
#3.正向动量因子(20日收益率排名)
momentum_returns = RETURNS(close, period=20)
momentum_factor = RANK(momentum_returns)
#等权合成三个因子(标准化后相加)
composite = (SCALE(size factor) + SCALE(low vol_ factor) + SCALE(momentum factor)) /3
return composite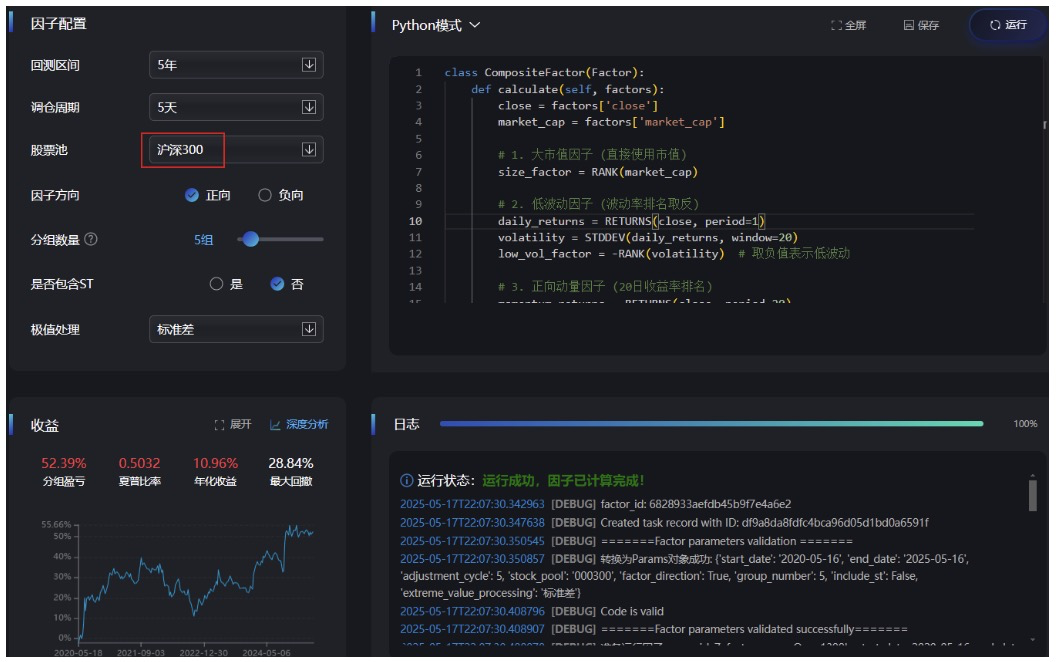
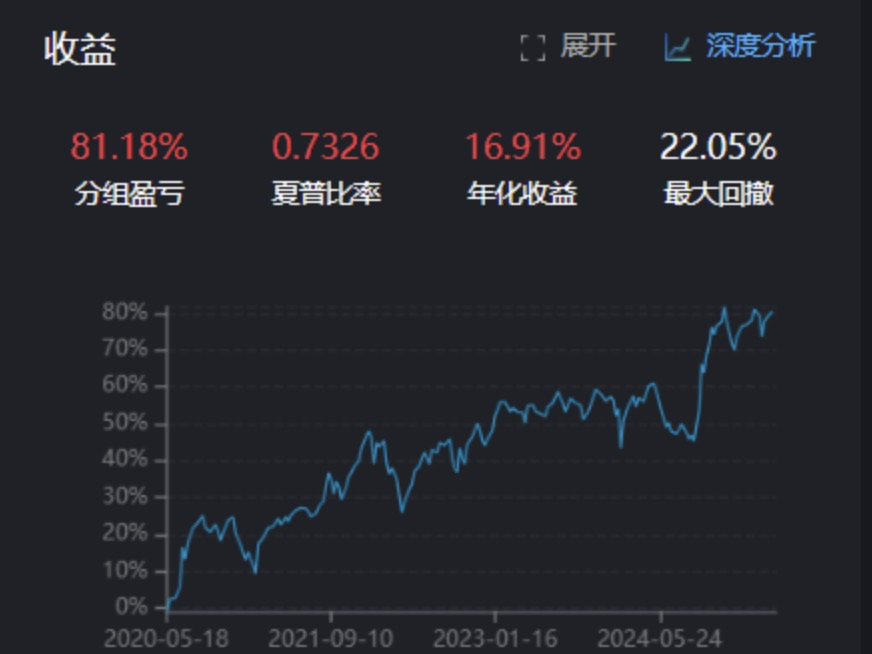
结果勉强合格,但不惊艳。可能缺少了研报中提到的“高价值”和“高机构覆盖”因子
第二组:"反转组"(小市值 + 高波动 + 低流动性 + 反向动量)
-
预期: 在全A股中捕捉反转效应
class CompositeFactor(Factor):
def calculate(self, factors):
close = factors['close']
turnover = factors['turnover']
market_cap = factors['market_cap']
#1.小市值因子(取负值表示小市值)
size_factor = -RANK(market_cap)
#2.高波动性因子
daily_returns = RETURNS(close,period=1)
volatility = STDDEV(daily_returns, window=20)
volatility_factor= RANK(volatility)
#3.低流动性因子(采用20天换手率平均值,取负值表示低流动性)
liquidity= TS_MEAN(turnover, window=20)
liquidity_factor= -RANK(liquidity)
#4.反向动量因子(取负的动量)
momentum = RETURNS(close,period=20)
reverse_momentum_factor = -RANK(momentum)
#等权合成四个因子
composite = (size_factor + volatility_factor + liquidity_factor + reverse_momentum_factor) / 4
return composite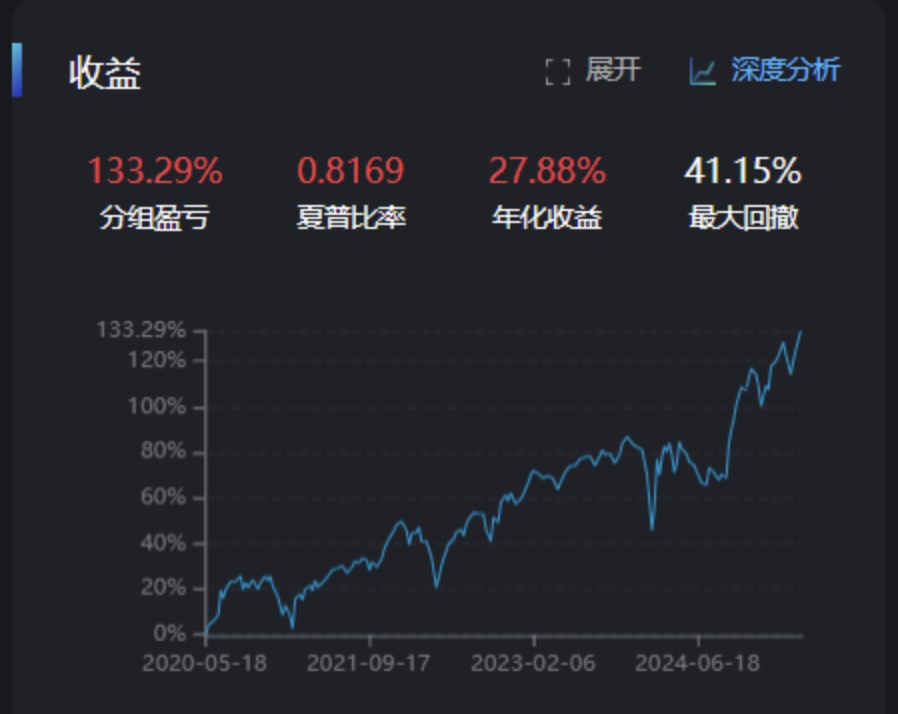
比较失望的是:这个四因子组合的表现,还不如单用一个小市值因子!后面我尝试将将计算波动性的天数减少,将波动性调整到3天
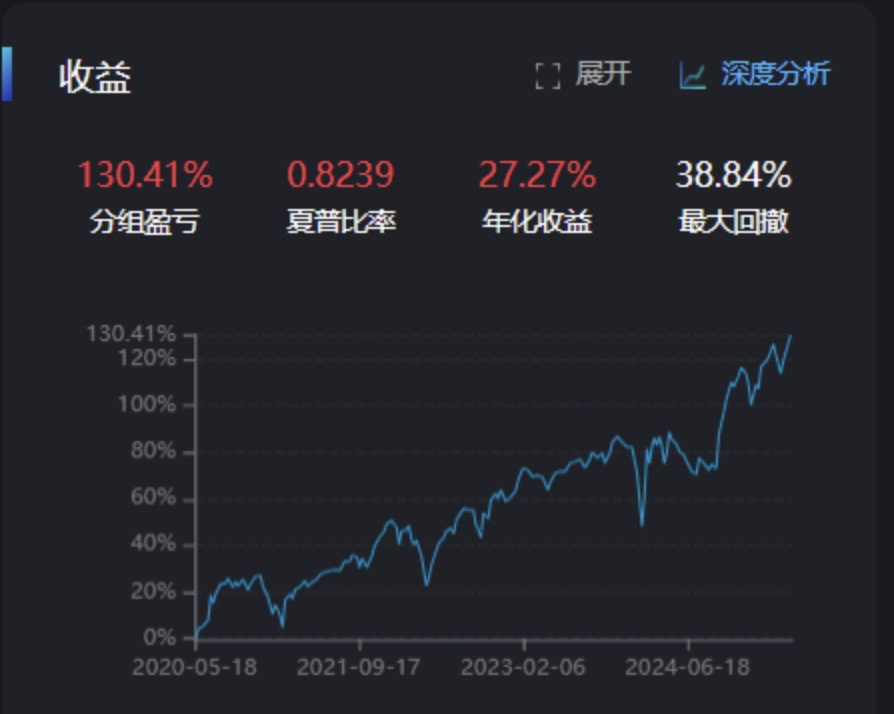
结果并没有多少改善,所以我干脆考虑将波动性因子改成负向的,再试试
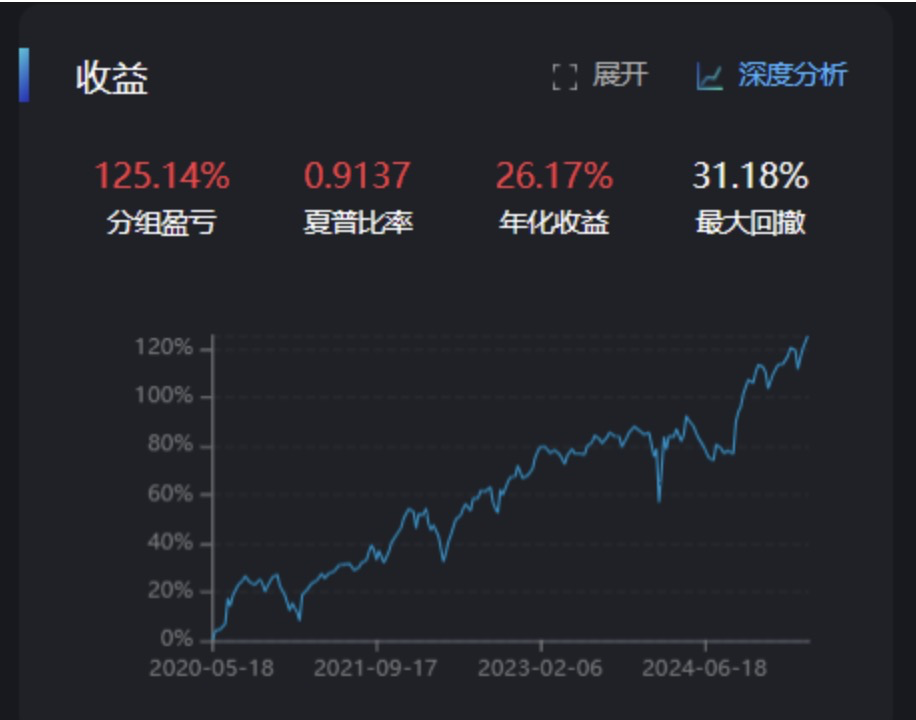
稍有改善,但是效果也一般,说明用换手率这个表达流动性可能不够,需要换其他的计算方式。
我的核心收获
-
研报复现 ≠ 简单抄作业
-
数据差异、参数设置、股票池选择都会影响结果
-
研报给的是思路,不是可复制粘贴的代码
-
-
因子组合的“1+1+1<3”现象
-
相关性高的因子组合,效果可能不如单个因子
-
需要寻找真正互补的因子
-
-
PandaAI的价值在于快速迭代
-
每个测试只需2-3分钟
-
能快速验证想法,排除无效路径
-
虽然这次复现没有完美成功,但我明确了下一步的方向:
-
补充缺失因子:寻找价值因子和机构覆盖度因子的替代指标
-
尝试非线性组合:用PandaAI的机器学习模块测试更复杂的组合方式
-
扩大因子库:测试更多与市值、波动、流动性相关性低的因子
最重要的是,整个探索过程在PandaAI上只花了我几个小时。在传统开发模式下,这可能需要几周时间。
如果你也想开始量化研究,我的建议是:不要等待完美方案,先动手构建第一个因子。 即使结果不理想,你也会学到比阅读十篇文章更多的东西。
我在PandaAI上公开了这个项目的所有代码和回测结果,欢迎大家去查看和复现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)