dify如何配置自定义模型,并添加本地或局域网内的模型(三种方法)
摘要:Dify支持通过Ollama、vLLM和Xinference三种方式接入本地/局域网模型。Ollama最简便,适合快速部署主流模型;vLLM提供高性能推理,支持OpenAI兼容API;Xinference适合多模型管理。配置时需确保网络可达,正确设置模型名称映射和API参数。常见问题包括网络连通性、参数匹配错误等,可通过测试端口连通性和检查日志排查。配置完成后,在Dify中启用模型即可创建应
·
Dify配置自定义模型并添加本地/局域网模型,核心是先在本地/内网启动模型API服务(如Ollama、vLLM、Xinference),再在Dify中通过“模型供应商”配置对应接入方式,确保网络可达与参数匹配。以下是分场景的完整可复用步骤与配置要点:
一、核心接入方案对比(快速选型)
| 接入方式 | 工具 | 适用场景 | 优点 | 典型端口 |
|---|---|---|---|---|
| Ollama | Ollama | 快速部署主流模型(Llama 3、Qwen等) | 轻量、一键部署、OpenAI兼容 | 11434 |
| OpenAI兼容API | vLLM、Text Generation Web UI | 本地/内网高性能推理 | 支持大模型、高并发 | 8000(vLLM) |
| Xinference | Xinference | 多模型统一管理、量化灵活 | 适配多框架、模型版本可控 | 9997 |
二、分场景详细配置步骤
场景1:用Ollama接入本地/局域网模型(最简便)
-
本地部署Ollama并启动模型
- 安装Ollama:官网下载安装包,或用命令行安装
- 拉取并运行模型:
ollama run qwen:7b(自动下载并启动,默认端口11434) - 局域网访问配置:Linux/macOS设置
OLLAMA_HOST=0.0.0.0,开放防火墙端口ufw allow 11434;Windows开放11434端口
-
Dify中配置Ollama供应商
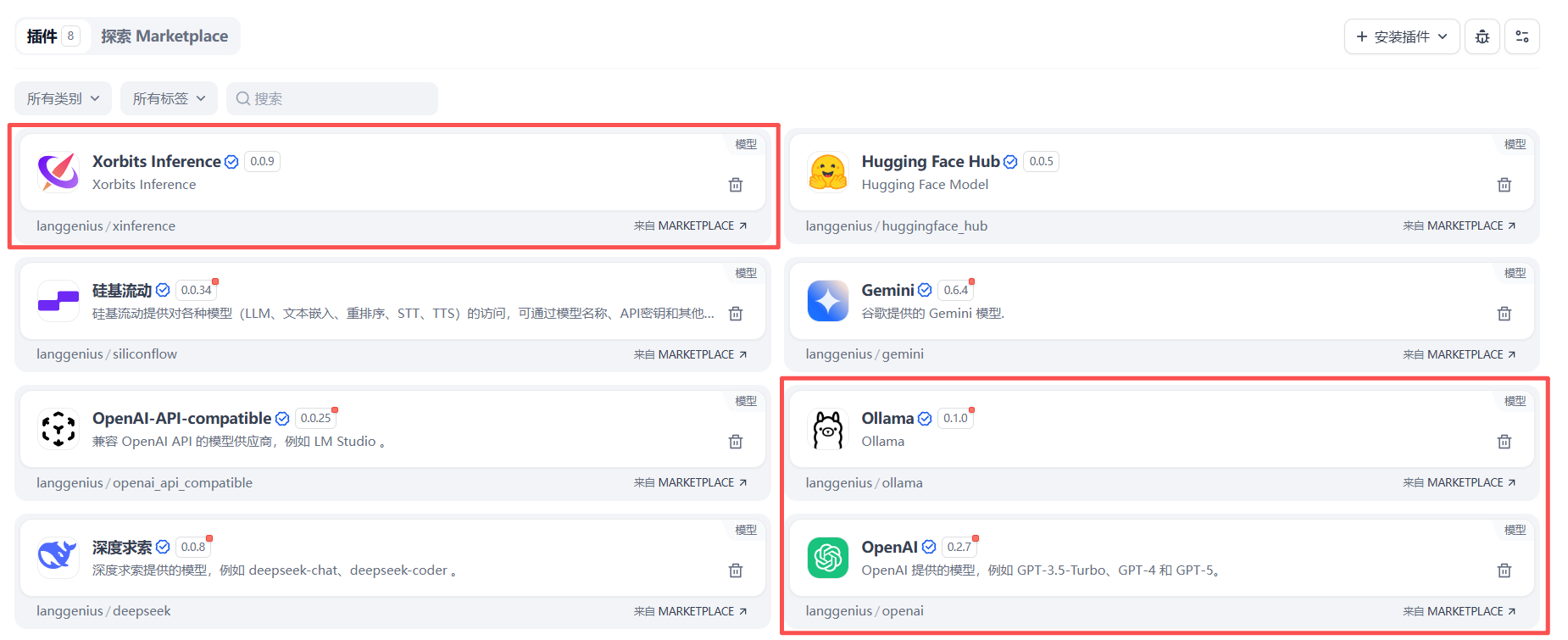
- 登录Dify → 设置 → 模型供应商 → 搜索“Ollama”并安装
- 进入Ollama供应商 → 添加模型
- 模型名称:自定义(如Qwen-7B-Local)
- 基础URL:本地
http://localhost:11434;Docker部署http://host.docker.internal:11434;局域网http://192.168.1.100:11434(替换为实际IP) - 模型名称映射:填写Ollama中的完整模型名(如
qwen:7b)
- 保存后,在“模型管理”中启用该模型,任务类型选“text-generation”
-
网络问题排查
- Docker中Dify无法访问本地Ollama:改用
host.docker.internal或宿主机内网IP,避免用localhost - 局域网访问失败:关闭防火墙或放行端口,确保设备在同一网段
- Docker中Dify无法访问本地Ollama:改用
场景2:用OpenAI兼容API接入本地模型(vLLM示例)
-
启动vLLM OpenAI兼容服务
docker run -d --gpus all -p 8000:8000 -v /path/to/models:/models \ vllm/vllm-openai:latest \ --model /models/Qwen-7B-Chat --api-key my-secret-key --tensor-parallel-size 1(参数说明:
--model指定本地模型路径,--api-key设置访问密钥,--tensor-parallel-size适配GPU数量)本地部署,下载docker镜像成功的详细命令
说明详见:win10 本地局域网内下载Qwen3Guard-Gen-8B模型并配置到dify的步骤文中说明
docker run --gpus all --shm-size 24g -p 0.0.0.0:8000:8000 `
-v "E:/AI_Model/Qwen/Qwen3Guard-Gen-8B":/mnt/d/models/Qwen3Guard-Gen-8B `
vllm/vllm-openai:latest `
--model /models/Qwen3Guard-Gen-8B `
--trust-remote-code `
--served-model-name qwen3guard-gen-8b `
--max-model-len 8192 `
--env LC_ALL=C.UTF-8 `
--gpu-memory-utilization 0.9 `
--api-key your_secure_key_123 # 可选,如果不设置,剔除该参数
- Dify中配置自定义模型(OpenAI兼容)
- 进入Dify → 设置 → 模型供应商 → 选择“OpenAI-API-compatible”
- 添加模型
- 模型名称:自定义(如vLLM-Qwen-7B)
- API端点:
http://192.168.1.100:8000/v1(替换为vLLM服务IP+端口) - API密钥:填写启动vLLM时设置的
my-secret-key - 模型名称映射:
Qwen-7B-Chat(与vLLM中--model参数一致)
- 保存并启用,测试调用
场景3:用Xinference接入本地/内网模型
-
启动Xinference服务并部署模型
- 安装:
pip install "xinference[all]" - 启动服务:
xinference -H 0.0.0.0(默认端口9997,允许局域网访问) - 部署模型:
xinference launch --model-name qwen-7b-chat --model-format pytorch --quantization 4bit,记录返回的model_uid
- 安装:
-
Dify中配置Xinference供应商
- 安装Xinference供应商插件
- 添加模型
- 服务器URL:
http://192.168.1.100:9997(替换为Xinference服务IP) - 模型UID:填写部署时返回的
model_uid - 模型名称:自定义,任务类型选“text-generation”
- 服务器URL:
- 保存并测试
三、通用配置要点与排错指南
-
网络可达性
- 本地Docker部署Dify:访问宿主机服务用
host.docker.internal;访问局域网用宿主机内网IP - 防火墙:放行模型服务端口(如11434、8000、9997)
- 测试连通性:在Dify服务器/容器中执行
curl http://模型服务IP:端口/v1/models,确认返回模型列表
- 本地Docker部署Dify:访问宿主机服务用
-
参数匹配规则
- 模型名称映射必须与服务端模型名完全一致(如Ollama的
qwen:7b、vLLM的Qwen-7B-Chat) - API密钥、基础URL等参数错误会导致“Credentials validation failed”或“404 Not Found”
- 模型名称映射必须与服务端模型名完全一致(如Ollama的
-
常见错误处理
- 400错误:模型名称映射不匹配,或API端点格式错误(如缺少
/v1) - 403错误:API密钥错误或未设置,检查服务端启动参数与Dify配置
- 503错误:模型服务未启动或端口未开放,确认服务状态与防火墙规则
- 400错误:模型名称映射不匹配,或API端点格式错误(如缺少
四、验证与使用
- 配置完成后,在Dify“模型管理”中确认模型状态为“可用”
- 创建应用时,选择已添加的本地模型作为推理引擎
- 测试对话,检查响应是否正常,若出现延迟高可调整模型量化等级或硬件配置
说明
全文使用的qwen-7b-chat模型仅为示意使用,请根据自身需要使用的模型名称替换。
Dify中下载的插件

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)